

总结比较与排序类相关的可视化图像
1.柱状图
(1)柱状图的特点
- 直观清晰:能够以简单直接的方式展示不同类别数据之间的数量对比关系。通过柱子的高度或长度,我们可以迅速判断出各个类别数据值的大小差异。
- 易于理解:无论是专业人士还是普通大众,都能轻松理解柱状图所传达的信息,不需要复杂的解释和背景知识。
- 多种展示形式:可以是垂直柱状图(柱子垂直排列),也可以是水平柱状图(柱子水平排列);还能绘制分组柱状图和堆叠柱状图,以满足不同的数据对比需求。
(2)柱状图的应用场景
- 数据对比分析:在比较不同产品的销量、不同部门的业绩、不同地区的人口数量等方面有广泛应用。例如,分析不同季度的销售额,通过柱状图可以清晰看出各季度销售情况的差异。
- 展示分布情况:当数据按照一定类别进行分组时,柱状图可以展示每个组别的数据分布。比如,展示不同年龄段人群的消费金额分布。
- 趋势分析(短期):如果数据是按照时间顺序(如月份、年份)进行分类的,柱状图可以在一定程度上反映出短期的数据变化趋势。
(3)实验代码及结果
import matplotlib.pyplot as plt import numpy as np # 数据 labels = ['Group A', 'Group B', 'Group C', 'Group D'] men_means = [20, 35, 30, 35,] women_means = [25, 32, 34, 20] # 设置图形参数 x = np.arange(len(labels)) # 标签位置 width = 0.35 # 柱状图宽度 fig, ax = plt.subplots()# 创建图形和坐标轴 # 绘制男性数据的柱状图 rects1 = ax.bar(x - width/2, men_means, width, label='Men', color='red') # 绘制女性数据的柱状图 rects2 = ax.bar(x + width/2, women_means, width, label='Women', color='yellow') # 添加标题和标签 ax.set_ylabel('Scores') ax.set_title('Scores by group and gender') ax.set_xticks(x) ax.set_xticklabels(labels) ax.legend() # 定义添加数据标签的函数 def autolabel(rects): """在每个柱子上添加数据标签""" for rect in rects: height = rect.get_height() ax.annotate('{}'.format(height), xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), # 3 points vertical offset textcoords="offset points", ha='center', va='bottom') # 为男性和女性的柱状图添加数据标签 autolabel(rects1) autolabel(rects2) # 显示图形 fig.tight_layout() plt.show()
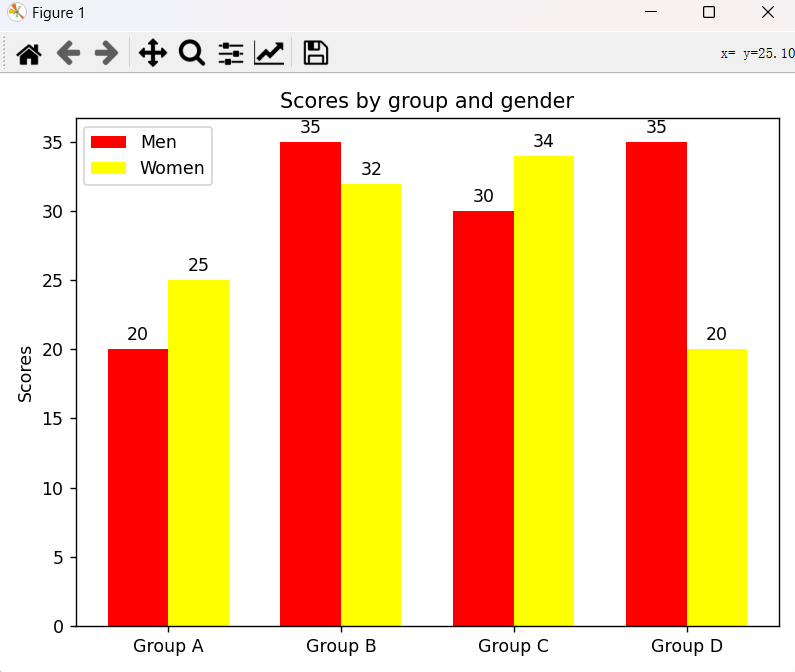
2.环形柱状图
(1)特点
- 节省空间:相较于传统的柱状图,环形柱状图将柱子排列成环形,能够在有限的空间内展示更多的数据信息,尤其适用于展示多组数据的对比情况。
- 视觉效果独特:环形的设计使图表看起来更加新颖和吸引人,能够在众多图表中脱颖而出,增强数据展示的吸引力。
- 可同时展示多组数据:可以通过不同颜色或样式的柱子来区分不同的数据系列,方便用户同时对比多组数据的大小和关系。 环形柱状图的应用场景
(2)应用场景
- 多指标对比:当需要同时对比多个相关指标的数据时,环形柱状图可以清晰地展示各指标之间的差异。例如,在分析一个公司不同部门的多项业绩指标(如销售额、利润、成本等)时,使用环形柱状图可以直观地看出各部门在不同指标上的表现。
- 时间序列数据对比:对于按时间顺序排列的数据,如不同年份或季度的各项数据指标,环形柱状图可以有效地展示数据随时间的变化趋势以及不同时间点之间的对比情况。
- 市场份额分析:在分析不同品牌或产品在市场中的份额占比时,环形柱状图可以将各品牌或产品的份额以直观的方式呈现出来,便于比较和分析。
(3)实验代码及结果
import matplotlib.pyplot as plt import numpy as np # 定义数据 categories = ['A', 'B', 'C', 'D', 'E'] num_categories = len(categories) # 多个数据系列 data_series1 = [20, 30, 25, 15, 22] data_series2 = [15, 25, 20, 10, 18] data_series3 = [12, 22, 18, 8, 15] # 计算每个柱子的角度和宽度 angles = np.linspace(0, 2 * np.pi, num_categories, endpoint=False) width = 2 * np.pi / num_categories # 创建极坐标图 fig, ax = plt.subplots(figsize=(8, 8), subplot_kw={'projection': 'polar'}) # 绘制第一个数据系列 bars1 = ax.bar(angles, data_series1, width=width, bottom=0, label='Series 1', color='blue', alpha=0.7) # 绘制第二个数据系列 bars2 = ax.bar(angles, data_series2, width=width, bottom=data_series1, label='Series 2', color='green', alpha=0.7) # 绘制第三个数据系列 bars3 = ax.bar(angles, data_series3, width=width, bottom=[i + j for i, j in zip(data_series1, data_series2)], label='Series 3', color='orange', alpha=0.7) # 设置坐标轴标签和标题 ax.set_xticks(angles) ax.set_xticklabels(categories) ax.set_title('Complex Circular Bar Chart', pad=20) # 添加图例 ax.legend(loc='upper right', bbox_to_anchor=(1.3, 1.1)) # 显示数据标签 def add_labels(bars, bottom_values, color): for bar, bottom in zip(bars, bottom_values): height = bar.get_height() angle = bar.get_x() + bar.get_width() / 2 value = height ax.text(angle, bottom + height / 2, str(value), ha='center', va='center', color=color, fontsize=10) # 为每个数据系列添加数据标签 add_labels(bars1, [0] * num_categories, 'white') add_labels(bars2, data_series1, 'white') add_labels(bars3, [i + j for i, j in zip(data_series1, data_series2)], 'white') # 显示图形 plt.show()
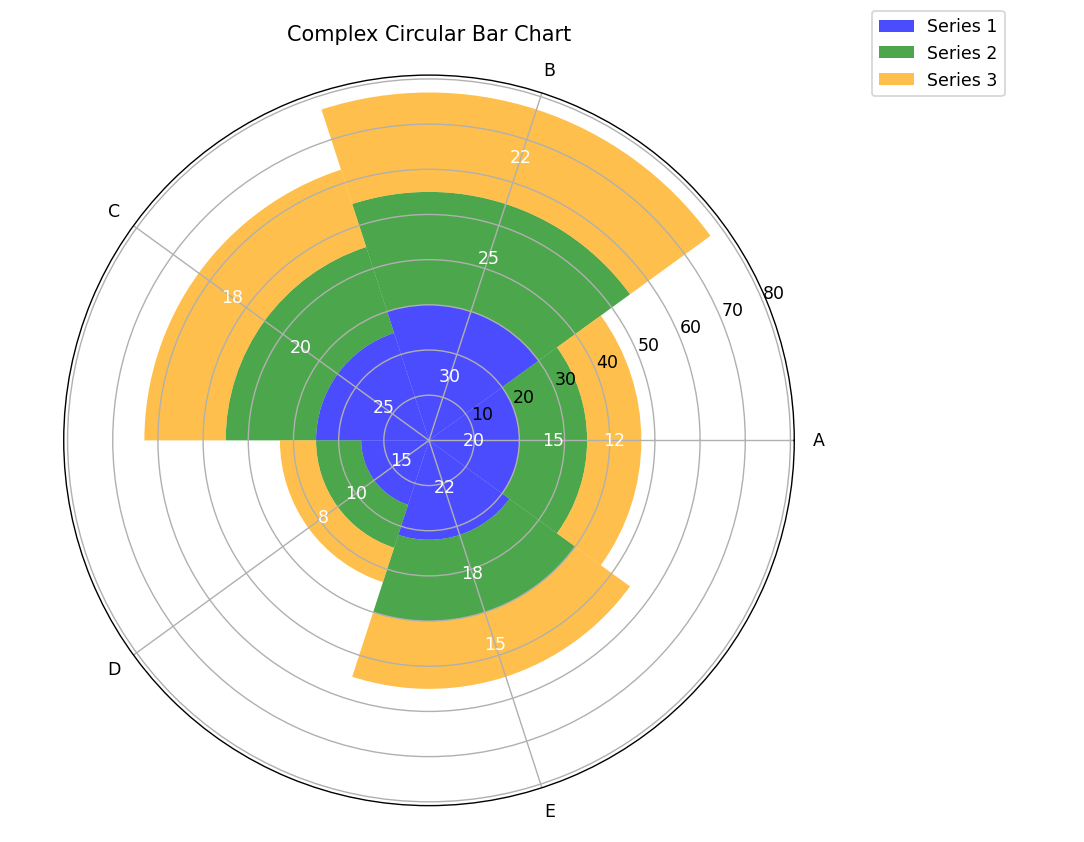
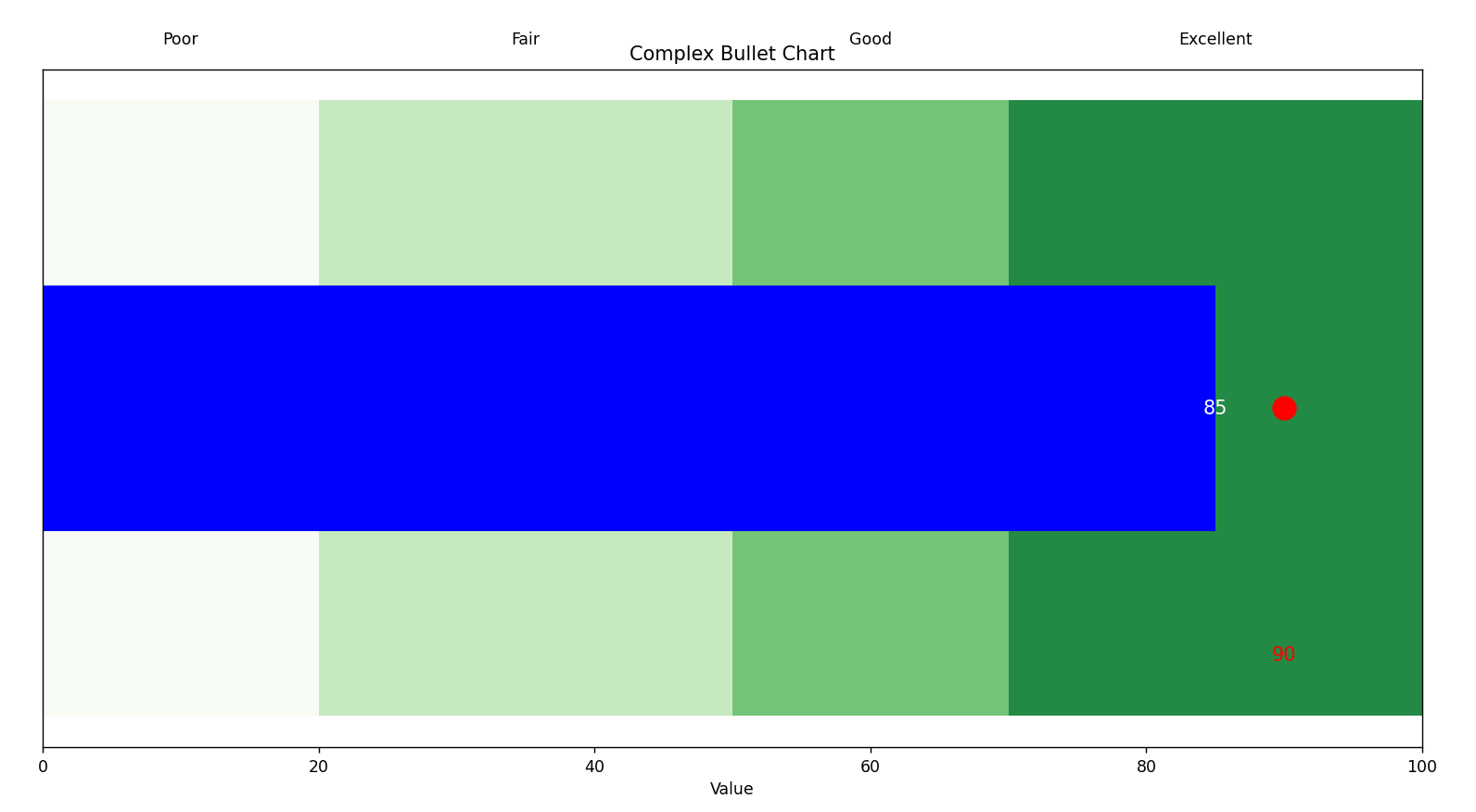
3.子弹图
(1)特点
- 子弹图的特点 简洁直观:能够以一种紧凑的方式展示大量信息,用一根柱子和一些标记就可以呈现出目标值、实际值以及不同的区间范围,让读者快速理解数据的表现情况。
- 突出对比:清晰地对比实际值与目标值之间的差异,还能展示实际值在不同绩效区间(如差、中、好)的位置,有助于快速评估绩效。
- 可定制性强:可以根据具体需求调整区间的划分、颜色的设置以及标记的样式,以适应不同的业务场景和数据展示重点。
(2)应用场景
- 子弹图的应用场景 业务绩效评估:常用于展示销售业绩、项目进度、生产指标等业务数据与目标值的对比,帮助管理者快速了解业务的完成情况和绩效水平。
- 关键指标监控:在仪表盘等可视化界面中,用于实时监控关键指标,如网站流量、用户活跃度等,让决策者及时掌握业务动态。
- 预算与实际支出对比:对比预算金额和实际支出金额,同时可以划分不同的支出区间(如未超预算、轻度超预算、严重超预算),直观反映预算执行情况。
(3)实验代码及结果
import matplotlib.pyplot as plt import numpy as np # 定义数据 measure = 85 # 实际测量值 markers = [90] # 目标值 ranges = [20, 50, 70, 100] # 不同区间的边界值 labels = ['Poor', 'Fair', 'Good', 'Excellent'] # 区间标签 # 创建图形和坐标轴 fig, ax = plt.subplots(figsize=(10, 2)) # 绘制区间背景 for i in range(len(ranges)): if i == 0: left = 0 else: left = ranges[i - 1] right = ranges[i] color = plt.cm.Greens(i / len(ranges)) # 根据区间设置不同的颜色 ax.barh([0], right - left, left=left, color=color, height=0.5) # 绘制实际测量值柱子 ax.barh([0], measure, color='blue', height=0.2) # 绘制目标值标记 for marker in markers: ax.scatter(marker, 0, color='red', s=200, zorder=10) # 设置坐标轴和标签 ax.set_xlim(0, max(ranges)) ax.set_yticks([]) ax.set_xlabel('Value') ax.set_title('Complex Bullet Chart') # 添加区间标签 for i in range(len(ranges)): if i == 0: mid = ranges[i] / 2 else: mid = (ranges[i - 1] + ranges[i]) / 2 ax.text(mid, 0.3, labels[i], ha='center', va='center', fontsize=10) # 添加数据标签 ax.text(measure, 0, f'{measure}', ha='center', va='center', color='white', fontsize=12) for marker in markers: ax.text(marker, -0.2, f'{marker}', ha='center', va='center', color='red', fontsize=12) plt.show()
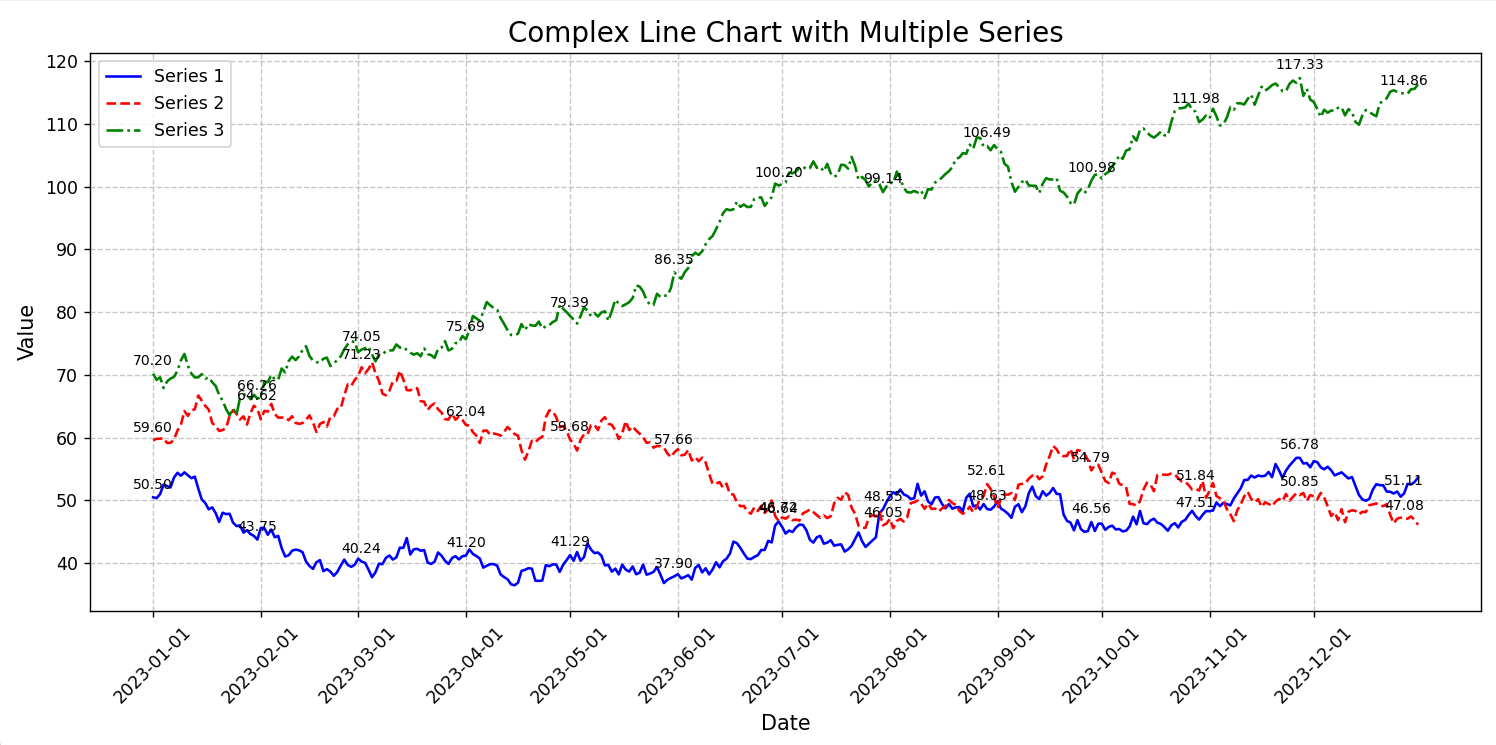
4.折线图
(1)特点
- 趋势展示:能够清晰地展示数据随时间或其他变量的变化趋势。
- 多系列对比:可以同时展示多个数据系列,便于比较不同组之间的变化趋势。
- 连续性:通过线条连接数据点,强调数据的连续性。
- 灵活性:可以添加标记、注释、网格线等元素,增强可读性。
- 易于理解:折线图是最直观的图表之一,适合大多数受众。
(2)应用场景
- 时间序列分析:展示数据随时间的变化,例如股票价格、气温变化、销售数据等。
- 多组数据比较:比较不同组之间的趋势,例如不同产品的销售趋势、不同地区的经济增长趋势。
- 性能监控:展示系统性能指标随时间的变化,例如服务器响应时间、CPU 使用率等。
- 实验数据记录:记录实验过程中的数据变化,例如化学反应的温度变化、生物实验的生长曲线。
- 预测与分析:展示预测模型的结果,例如未来几天的天气预测、未来几年的市场趋势预测。
(3)实验代码及结果
import matplotlib.pyplot as plt import numpy as np import pandas as pd # 生成示例数据 np.random.seed(42) date_rng = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D') data1 = np.random.randn(len(date_rng)).cumsum() + 50 data2 = np.random.randn(len(date_rng)).cumsum() + 60 data3 = np.random.randn(len(date_rng)).cumsum() + 70 # 创建 DataFrame df = pd.DataFrame({'date': date_rng, 'Series 1': data1, 'Series 2': data2, 'Series 3': data3}) # 设置图形大小 plt.figure(figsize=(12, 6)) # 绘制三条折线图 plt.plot(df['date'], df['Series 1'], label='Series 1', color='blue', linestyle='-', linewidth=1.5) plt.plot(df['date'], df['Series 2'], label='Series 2', color='red', linestyle='--', linewidth=1.5) plt.plot(df['date'], df['Series 3'], label='Series 3', color='green', linestyle='-.', linewidth=1.5) # 添加标题和标签 plt.title('Complex Line Chart with Multiple Series', fontsize=16) plt.xlabel('Date', fontsize=12) plt.ylabel('Value', fontsize=12) # 设置 x 轴刻度间隔为每月 plt.xticks(pd.date_range(start='2023-01-01', end='2023-12-31', freq='MS'), rotation=45) # 添加网格线 plt.grid(True, linestyle='--', alpha=0.7) # 添加图例 plt.legend(loc='upper left', fontsize=10) # 添加数据标签(每隔 30 天) for i in range(0, len(df), 30): plt.annotate(f'{df["Series 1"][i]:.2f}', (df['date'][i], df['Series 1'][i]), textcoords='offset points', xytext=(0, 5), ha='center', fontsize=8) plt.annotate(f'{df["Series 2"][i]:.2f}', (df['date'][i], df['Series 2'][i]), textcoords='offset points', xytext=(0, 5), ha='center', fontsize=8) plt.annotate(f'{df["Series 3"][i]:.2f}', (df['date'][i], df['Series 3'][i]), textcoords='offset points', xytext=(0, 5), ha='center', fontsize=8) # 显示图形 plt.tight_layout() plt.show()
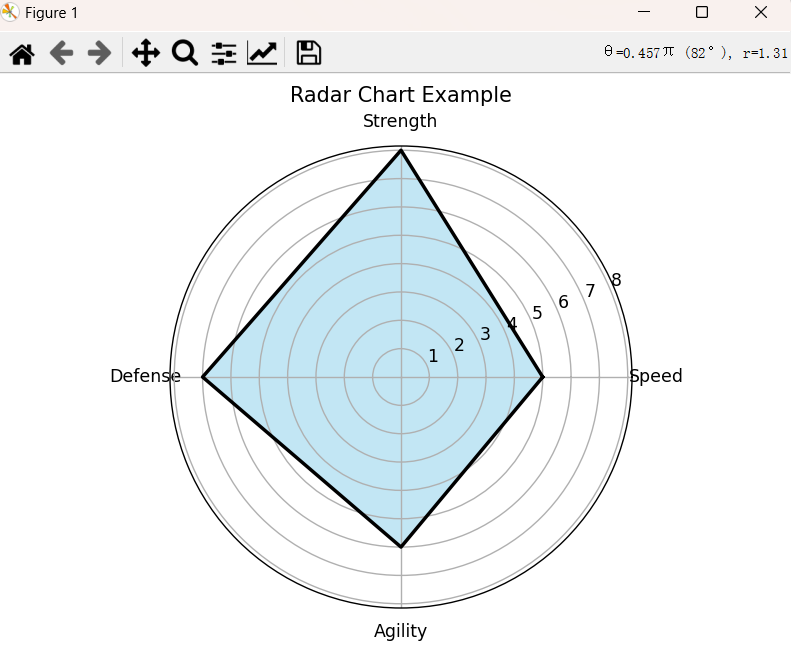
5.雷达图
(1)特点
- 多变量展示:能够在一个二维平面上同时展示多个变量的数据,方便对多个指标进行综合分析。每个变量对应一个坐标轴,从中心向外辐射,数据点连接形成多边形,可直观呈现各变量的数值大小和相互关系。
- 整体性评估:有助于从整体上把握研究对象在多个维度的表现,快速判断其优势和劣势所在。通过观察多边形的形状和大小,可以对数据的整体特征有一个直观的认识。
- 可视化效果好:图形形状独特,具有较强的视觉冲击力,能够吸引观众的注意力,使数据更加生动形象。
(2)应用场景
- 综合评价:常用于对个人、产品、项目等进行综合评价。例如,评估员工在多个能力维度(如沟通能力、团队协作能力、专业技能等)的表现;比较不同产品在多个性能指标(如外观、性能、价格、易用性等)的优劣。
- 市场分析:在市场调研中,分析不同品牌在多个市场因素(如市场份额、品牌知名度、客户满意度等)的表现,帮助企业了解自身在市场中的地位和竞争态势。
- 战略规划:企业在制定战略时,可以使用雷达图分析自身在不同业务领域的优势和劣势,为战略决策提供依据。
(3)实验代码及结果
import matplotlib.pyplot as plt import numpy as np labels = ['Speed', 'Strength', 'Defense', 'Agility'] values = [5, 8, 7, 6] angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False).tolist() values += values[:1] # Close the loop angles += angles[:1] fig, ax = plt.subplots(subplot_kw=dict(polar=True)) ax.fill(angles, values, color='skyblue', alpha=0.5) ax.plot(angles, values, color='black', linewidth=2) ax.set_xticks(angles[:-1]) ax.set_xticklabels(labels) plt.title('Radar Chart Example') plt.show()
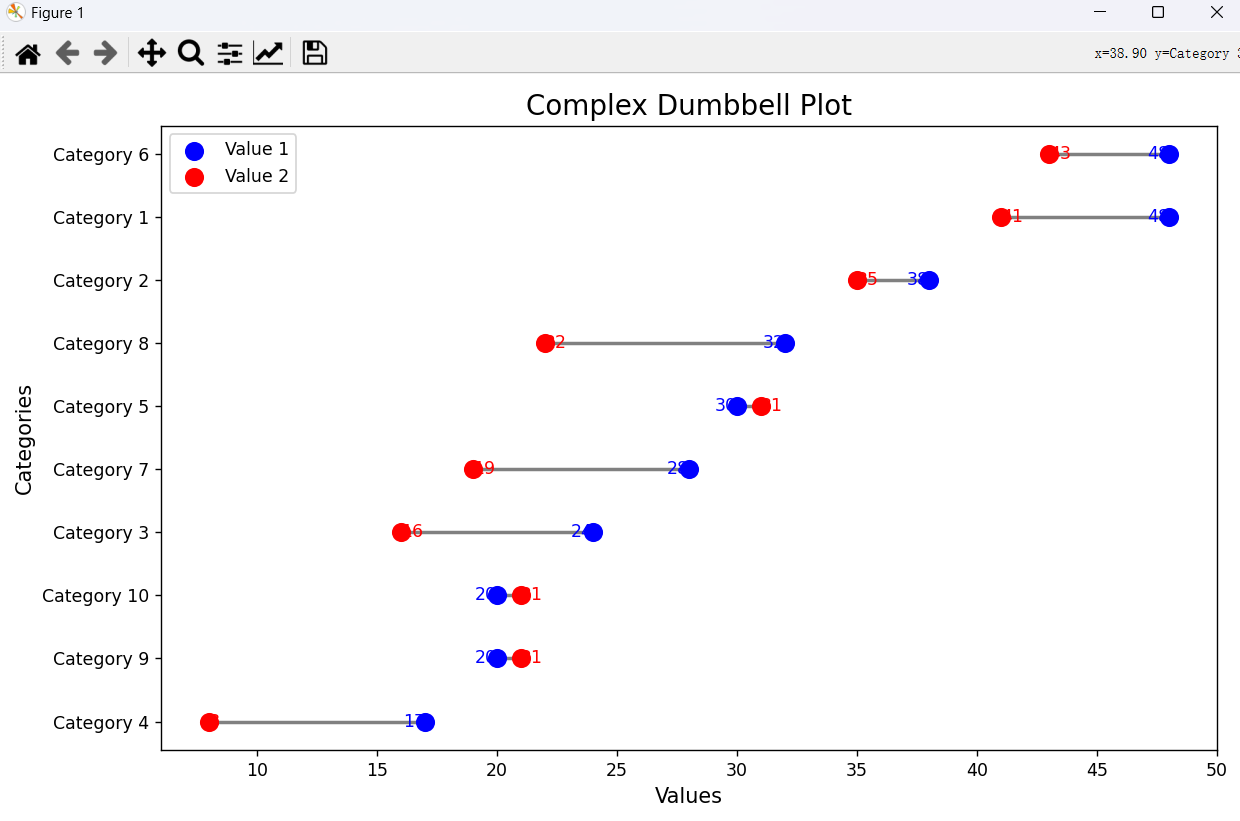
6.哑铃图
(1)特点
- 直观对比:哑铃图通过线段连接两个数据点,能清晰展示两个相关数据点之间的差异,让人一眼看出数据的变化情况,如数值的增减、高低对比等。
- 强调关联性:明确体现出两个数据之间的关联,适合用于展示同一对象在不同时间点、不同条件下的状态变化,或者两个相关对象的对应数据差异。
- 简洁清晰:图形简洁,没有过多复杂的元素,数据表达直接,即使是不熟悉数据分析的人也能快速理解图表所传达的信息。
(2)应用场景
- 时间序列对比:分析同一指标在不同时间点的数值变化,如不同年份的销售额、不同季度的利润等,帮助观察数据随时间的演变趋势。
- 对比不同方案或组别:比较两个不同方案、组别之间的相关指标,例如对比两种产品的各项性能指标、两个团队的工作绩效等,辅助决策制定。
- 展示差异程度:突出显示数据之间的差异程度,例如不同地区的贫富差距、不同年龄段的健康指标差异等。
(3)实验代码及结果
import matplotlib.pyplot as plt import pandas as pd import numpy as np # 生成示例数据 np.random.seed(42) categories = [f'Category {i}' for i in range(1, 11)] value1 = np.random.randint(10, 50, 10) value2 = value1 + np.random.randint(-10, 10, 10) data = { 'Category': categories, 'Value1': value1, 'Value2': value2 } df = pd.DataFrame(data) # 按 Value1 排序 df = df.sort_values(by='Value1') # 绘制哑铃图 plt.figure(figsize=(10, 6)) # 绘制线段 for i, row in df.iterrows(): plt.hlines(y=row['Category'], xmin=row['Value1'], xmax=row['Value2'], color='gray', linewidth=2) # 绘制起始点 plt.scatter(df['Value1'], df['Category'], color='blue', s=100, label='Value 1', zorder=2) # 绘制结束点 plt.scatter(df['Value2'], df['Category'], color='red', s=100, label='Value 2', zorder=2) # 添加数据标签 for i, row in df.iterrows(): plt.text(row['Value1'], row['Category'], str(row['Value1']), ha='right', va='center', fontsize=10, color='blue') plt.text(row['Value2'], row['Category'], str(row['Value2']), ha='left', va='center', fontsize=10, color='red') # 添加标题和标签 plt.title('Complex Dumbbell Plot', fontsize=16) plt.xlabel('Values', fontsize=12) plt.ylabel('Categories', fontsize=12) # 添加图例 plt.legend() # 调整布局 plt.tight_layout() # 显示图形 plt.show()
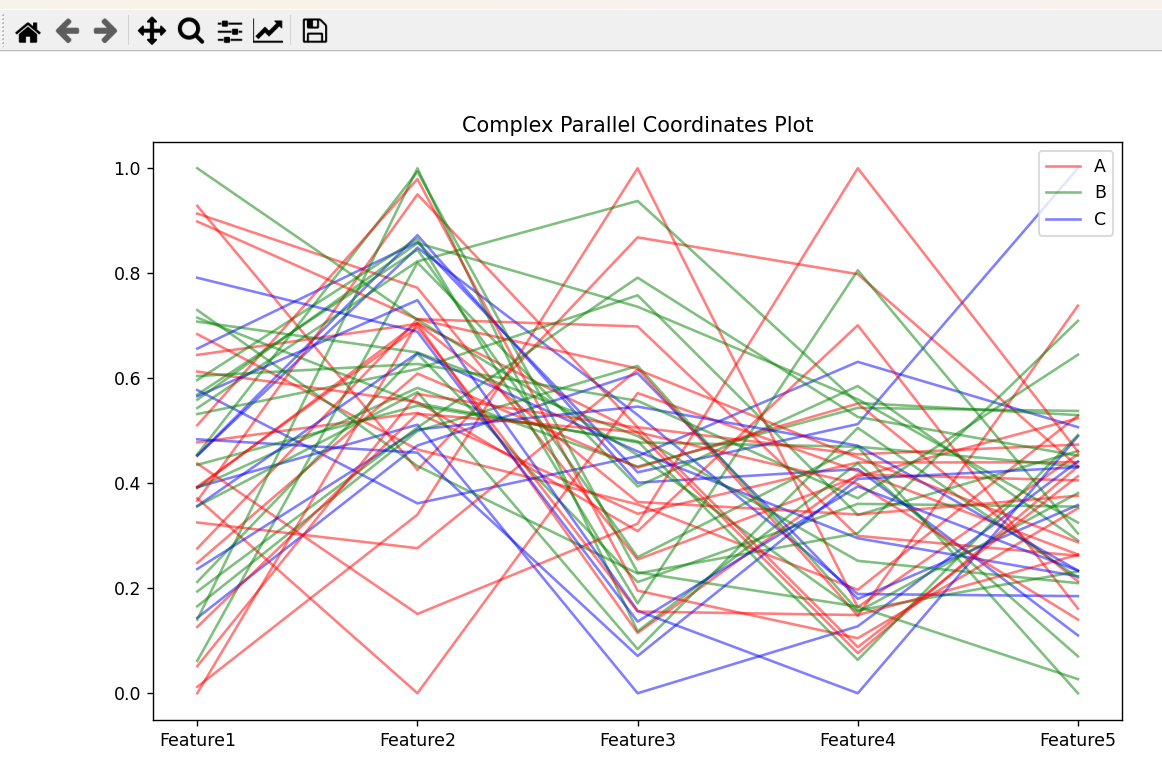
7.平行坐标图
(1)特点
优点
- 高维数据可视化:平行坐标图是一种非常有效的高维数据可视化工具。它可以同时展示多个变量(维度)的数据,突破了传统二维或三维可视化的限制,让用户能够直观地观察到高维数据中的模式、趋势和关系。
- 发现数据关联:通过观察折线在不同坐标轴上的走势和交叉情况,能够快速发现变量之间的相关性。例如,如果两条折线在多个坐标轴上的走势相似,说明对应的两个变量可能存在较强的正相关关系。
- 易于理解:其基本原理简单易懂,即使对于不具备专业数据分析知识的用户,也能通过观察折线的形状和位置,对数据有一个初步的认识和理解。
缺点
- 数据重叠问题:当数据量较大时,折线会相互重叠,导致图形变得复杂和混乱,难以清晰地分辨每条折线所代表的数据。
- 坐标轴顺序影响:坐标轴的排列顺序会对用户的视觉感知和数据解读产生影响。不同的坐标轴顺序可能会使数据呈现出不同的特征和模式。
(2)应用场景
- 多变量数据分析:在金融领域,用于分析股票的多个指标(如开盘价、收盘价、成交量、市盈率等),帮助投资者发现不同股票之间的差异和相似性;在医疗领域,可用于分析患者的多项生理指标(如血压、心率、血糖等),辅助医生进行疾病诊断和治疗方案制定。
- 数据聚类和分类:通过观察平行坐标图中折线的分布情况,可以初步判断数据是否存在聚类现象,为后续的聚类分析和分类任务提供参考。
- 过程监控:在工业生产过程中,实时监测多个生产参数(如温度、压力、流量等)的变化情况,及时发现生产过程中的异常和波动。
(3)实验代码及结果
import matplotlib.pyplot as plt import pandas as pd import numpy as np from sklearn.preprocessing import MinMaxScaler # 生成示例数据 np.random.seed(42) n_samples = 50 data = { 'Feature1': np.random.randn(n_samples), 'Feature2': np.random.randn(n_samples) + 2, 'Feature3': np.random.randn(n_samples) - 1, 'Feature4': np.random.randn(n_samples) + 1, 'Feature5': np.random.randn(n_samples) - 2, 'Class': np.random.choice(['A', 'B', 'C'], n_samples) } df = pd.DataFrame(data) # 对数值特征进行归一化处理 scaler = MinMaxScaler() numerical_columns = df.select_dtypes(include=[np.number]).columns df[numerical_columns] = scaler.fit_transform(df[numerical_columns]) # 定义颜色映射 color_map = {'A': 'red', 'B': 'green', 'C': 'blue'} # 创建图形和坐标轴 fig, ax = plt.subplots(figsize=(10, 6)) # 绘制平行坐标图 for index, row in df.iterrows(): class_label = row['Class'] values = row.drop('Class').values x = np.arange(len(values)) ax.plot(x, values, color=color_map[class_label], alpha=0.5) # 设置坐标轴标签 ax.set_xticks(np.arange(len(numerical_columns))) ax.set_xticklabels(numerical_columns) # 添加图例 legend_handles = [] for class_label, color in color_map.items(): line = plt.Line2D([0], [0], color=color, label=class_label, alpha=0.5) legend_handles.append(line) ax.legend(handles=legend_handles, loc='upper right') # 设置标题 ax.set_title('Complex Parallel Coordinates Plot') # 显示图形 plt.show()
8.词云图
(1)特点
- 直观展示关键词:词云图通过将文本中出现频率较高的关键词以较大的字体呈现,能够让读者迅速抓住文本的核心主题和关键信息,无需阅读大量文字内容。
- 视觉效果突出:独特的图形展示方式具有很强的视觉冲击力,相较于传统的文本呈现,更能吸引观众的注意力,使信息传达更加生动形象。
- 灵活性高:可以根据不同的需求自定义词云的形状、颜色、字体等,以适应不同的主题和风格要求,增强视觉效果和个性化。
- 数据概括性强:能够对大量文本数据进行有效的概括和提炼,将复杂的文本信息以简洁的图形形式呈现,帮助用户快速了解文本的整体内容和重点。
(2)应用场景
- 文本内容分析:在新闻媒体、社交媒体等领域,用于分析新闻报道、用户评论等文本内容的主题和热点,了解公众关注的焦点话题。
- 市场调研:分析消费者对产品或服务的反馈意见,找出消费者关注的优点和不足,为企业的产品改进和营销策略制定提供参考。
- 学术研究:在学术论文、研究报告等文本中,通过词云图可以快速了解研究的主要方向和关键概念,辅助学术研究和文献综述。
- 广告宣传:在广告设计中,使用词云图突出产品的特点和优势,吸引消费者的注意力,提高广告的传播效果。
(3)实验代码及结果
import wordcloud import jieba import matplotlib.pyplot as plt import numpy as np from PIL import Image # 图像处理 #打开背景图片 pic = Image.open("葡萄.png") # 提取图片的轮廓 shape = np.array(pic) # mask为图片背景,font_path为字体,若不设置可能乱码 wc = wordcloud.WordCloud(mask=shape, font_path="simkai.ttf", background_color="white", contour_color='purple',contour_width=3, max_font_size=100) #读取要分词的文本文件 try: # 先尝试用utf - 8读取 with open(r'C:/Users/Administrator/Desktop/画扇面.txt', "r", encoding='UTF-8') as file: text = file.read() except UnicodeDecodeError: # 如果utf - 8读取失败,尝试用gbk读取 with open(r'C:/Users/Administrator/Desktop/画扇面.txt', "r", encoding='GBK') as file: text = file.read() #结巴分词 cut_text = jieba.cut(text) result = " ".join(cut_text) #生成词云图 wc.generate(result) #保存词云图 wc.to_file("cloud.jpg") # 以图片的形式显示词云 plt.imshow(wc, interpolation="bilinear") # 不显示图像坐标系 plt.axis("off") # 显示图像 plt.show()

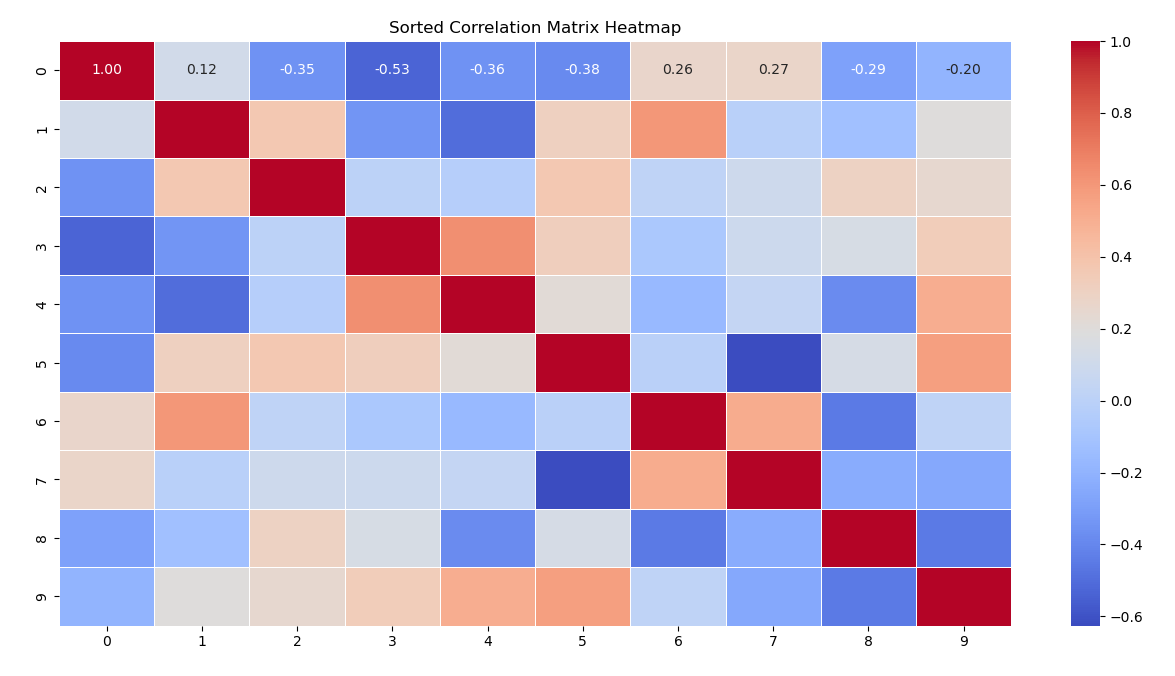
9.热力图
(1)特点
- 直观性强:通过颜色的深浅或冷暖变化,直观地展示数据的高低分布。
- 适合矩阵数据:特别适合展示二维矩阵数据,如相关性矩阵、距离矩阵等。
- 可排序性:可以通过对行或列的排序,展示数据的分布模式或趋势。
- 颜色编码:通过颜色编码,可以区分不同的数据范围,增强视觉效果。
- 灵活性高:可以结合注释、网格线等元素,丰富信息展示。
(2)应用场景
- 数据相关性分析:展示变量之间的相关性矩阵,帮助识别哪些变量之间存在强相关性。
- 时间序列分析:展示不同时间点的数据变化,例如每日或每月的销售数据。
- 用户行为分析:展示用户在不同页面或功能上的行为频率,帮助优化用户体验。
- 基因表达分析:在生物信息学中,展示基因在不同样本中的表达水平。
- 地理数据可视化:展示地理区域的热度,例如人口密度、犯罪率等
(3)实验代码及结果
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # 生成随机数据 np.random.seed(0) data = np.random.rand(10, 10) # 生成10x10的随机矩阵 # 计算相关性矩阵 corr_matrix = np.corrcoef(data) # 对相关性矩阵进行排序 # 使用谱聚类方法对行和列进行排序 from sklearn.cluster import SpectralClustering # 谱聚类 sc = SpectralClustering(n_clusters=3, affinity='nearest_neighbors', random_state=0) clusters = sc.fit_predict(corr_matrix) # 按照聚类结果对行和列进行排序 sorted_indices = np.argsort(clusters) sorted_corr_matrix = corr_matrix[sorted_indices, :][:, sorted_indices] # 绘制热力图 plt.figure(figsize=(10, 8)) sns.heatmap(sorted_corr_matrix, annot=True, cmap='coolwarm', fmt=".2f", linewidths=.5) plt.title('Sorted Correlation Matrix Heatmap') plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号