基于MobileNet的人脸表情识别系统(MATLAB GUI版+原理详解)
 本篇博客介绍了基于MobileNet的人脸表情识别系统,支持图片识别、视频识别、摄像头识别等多种形式,通过GUI界面实现表情识别可视化展示。首先介绍了表情识别任务的背景与意义,总结近年来利用深度学习进行表情识别的相关技术和工作。在数据集选择上,本文选择了Fer2013和CK+两个数据集,并使用MATLAB对这些数据进行预处理和训练。最后通过调用已经训练好的MobileNet模型对图像中存在的人脸目标进行表情识别分类,详细介绍了实现过程中使用的代码和设计框架。本文旨在为相关领域的研究人员和新入门的朋友提供参考,完整代码资源文件请转至文末的下载链接。
本篇博客介绍了基于MobileNet的人脸表情识别系统,支持图片识别、视频识别、摄像头识别等多种形式,通过GUI界面实现表情识别可视化展示。首先介绍了表情识别任务的背景与意义,总结近年来利用深度学习进行表情识别的相关技术和工作。在数据集选择上,本文选择了Fer2013和CK+两个数据集,并使用MATLAB对这些数据进行预处理和训练。最后通过调用已经训练好的MobileNet模型对图像中存在的人脸目标进行表情识别分类,详细介绍了实现过程中使用的代码和设计框架。本文旨在为相关领域的研究人员和新入门的朋友提供参考,完整代码资源文件请转至文末的下载链接。
摘要:本篇博客介绍了基于MobileNet的人脸表情识别系统,支持图片识别、视频识别、摄像头识别等多种形式,通过GUI界面实现表情识别可视化展示。首先介绍了表情识别任务的背景与意义,总结近年来利用深度学习进行表情识别的相关技术和工作。在数据集选择上,本文选择了Fer2013和CK+两个数据集,并使用MATLAB对这些数据进行预处理和训练。最后通过调用已经训练好的MobileNet模型对图像中存在的人脸目标进行表情识别分类,详细介绍了实现过程中使用的代码和设计框架。本文旨在为相关领域的研究人员和新入门的朋友提供参考,完整代码资源文件请转至文末的下载链接。
完整代码下载:https://mbd.pub/o/bread/mbd-ZJiYlpdu
参考视频演示:https://www.bilibili.com/video/BV1ts4y1X71R/
引言
我此前在博客中设计了一款基于 Python 的人脸表情识别系统介绍,这是一个有趣好玩的Python项目,该博客受到了广泛的关注和反响。经过四年的持续更新和完善,现在向大家介绍人脸表情识别系统在 MATLAB 中的实现。本文旨在帮助更多人了解和学习表情识别技术,同时展现我对于技术创新的热忱和乐于分享的态度,很高兴我的博客能够给予入门的读者一点启发。现成的代码可以省去重复造轮子的时间,但也希望读者能真正读懂代码和实现思路,避免“拿来主义”,在此之上能够有自己的见地和思考。感谢各位读者的支持和关注,期待与大家共同探索这一有趣的领域。
随着人工智能技术的飞速发展,计算机视觉领域也得到了长足的进步。人脸表情识别作为计算机视觉的一个重要应用,具有广泛的应用前景,如人机交互、心理健康分析、虚拟现实等。本博客将介绍一种基于MobileNet的人脸表情识别系统,并使用MATLAB进行实现。本博客内容为博主原创,相关引用和参考文献我已在文中标注,考虑到可能会有相关研究人员莅临指导,博主的博客这里尽可能以学术期刊的格式撰写,如需参考可引用本博客格式如下:
[1] 思绪无限. 基于MobileNet的人脸表情识别系统(MATLAB GUI版+原理详解)[J/OL]. CSDN, 2023.05. http://wuxian.blog.csdn.net/article/details/130460275.
[2] Wu, S. (2023, May 2). MobileNet-based facial expression recognition system (MATLAB GUI version + detailed principles) [Blog post]. CSDN Blog. http://wuxian.blog.csdn.net/article/details/130460275
人脸表情识别研究的现状已经取得了一定的成果,但仍然面临诸多挑战,如不同光照条件、姿态变化、表情类别定义等。近年来,深度学习在计算机视觉任务中取得了巨大成功,尤其是卷积神经网络(CNN)在图像识别领域的表现尤为突出。本博客将采用MobileNet作为基础架构,以其轻量级、高效的特点,实现一个实时的人脸表情识别系统。本博客的贡献点主要包括以下几个方面:
- 详细介绍了基于MobileNet的人脸表情识别系统的实现过程;
- 使用MATLAB实现了系统,使得开发者能够更方便地进行调试和优化;
- 提供了多种表情识别场景,如图片识别、视频识别和摄像头识别;
- 结合了两个公开的表情识别数据集,Fer2013和CK+,进行模型训练和评估;
- 设计了一个简洁的GUI界面,方便用户进行实时表情识别。
1. 相关工作
随着深度学习在计算机视觉领域的广泛应用,许多研究者开始尝试利用深度学习技术对人脸表情进行识别。在本节中,我们将回顾近年来深度学习在表情识别领域的发展,涉及不同的网络结构、优化技术以及数据增强方法等。(本部分参考文献见文末)
首先,我们来回顾一下基于深度学习的表情识别的一些基础工作。Goodfellow et al. [1] 提出了一种名为深度信念网络(DBN)的表情识别方法,并在Fer2013数据集上进行了测试。Lopes et al. [2] 利用卷积神经网络(CNN)进行表情识别,实现了较高的识别准确率。这些工作为后续基于深度学习的表情识别研究奠定了基础。随后,研究者们开始尝试使用不同的网络结构和优化方法来提高表情识别的性能。例如,Kahou et al. [3] 提出了一种融合卷积神经网络和循环神经网络(RNN)的多模态表情识别方法。Mollahosseini et al. [4] 使用Inception模块构建了一个名为FECNet的深度表情识别网络,取得了显著的性能提升。此外,还有研究者尝试利用迁移学习技术,如Zhang et al. [5] 利用VGG-Face预训练模型进行表情识别任务,有效地提高了识别性能。
数据增强方法在深度学习中具有重要的作用,尤其是对于数据不足的情况。Khorrami et al. [6] 提出了一种基于生成对抗网络(GAN)的数据增强方法,以提高表情识别性能。Kaya et al. [7] 将分数融合和数据增强方法应用于表情识别任务,实现了较大的性能提升。此外,还有研究者通过多任务学习来进行表情识别,如Liu et al. [8] 提出了一种多任务学习的表情识别方法,同时学习面部属性和表情识别任务。
近年来,轻量级神经网络在表情识别任务中也得到了广泛关注,这些轻量级网络具有较低的计算复杂性和内存需求,使得它们更适用于移动设备和实时应用。Howard et al. [9] 提出了MobileNet网络,通过引入深度可分离卷积(depthwise separable convolution)减少参数数量和计算量。Sandler et al. [10] 提出了MobileNetV2,引入了线性瓶颈和逆残差结构,进一步提高了计算效率。基于MobileNet的表情识别方法也取得了显著的成果,例如,Hu et al. [11] 提出了一种基于MobileNetV2的轻量级表情识别网络,实现了较高的识别准确率和实时性能。
通过以上文献综述,我们可以看到深度学习在人脸表情识别领域的广泛应用和发展。在本博客中,我们将基于MobileNet架构,结合Fer2013和CK+48数据集,实现一个基于MATLAB的实时人脸表情识别系统,同时提供多种表情识别场景,如图片识别、视频识别和摄像头识别,以及设计一个简洁的GUI界面,方便用户进行实时表情识别。
2. 系统界面演示效果
在本节中,我们将展示基于MobileNet的人脸表情识别系统的界面效果。系统提供了三种识别场景:图片识别、视频识别和摄像头识别。为了使用户更好地体验系统,我们设计了一个简洁易用的GUI界面。
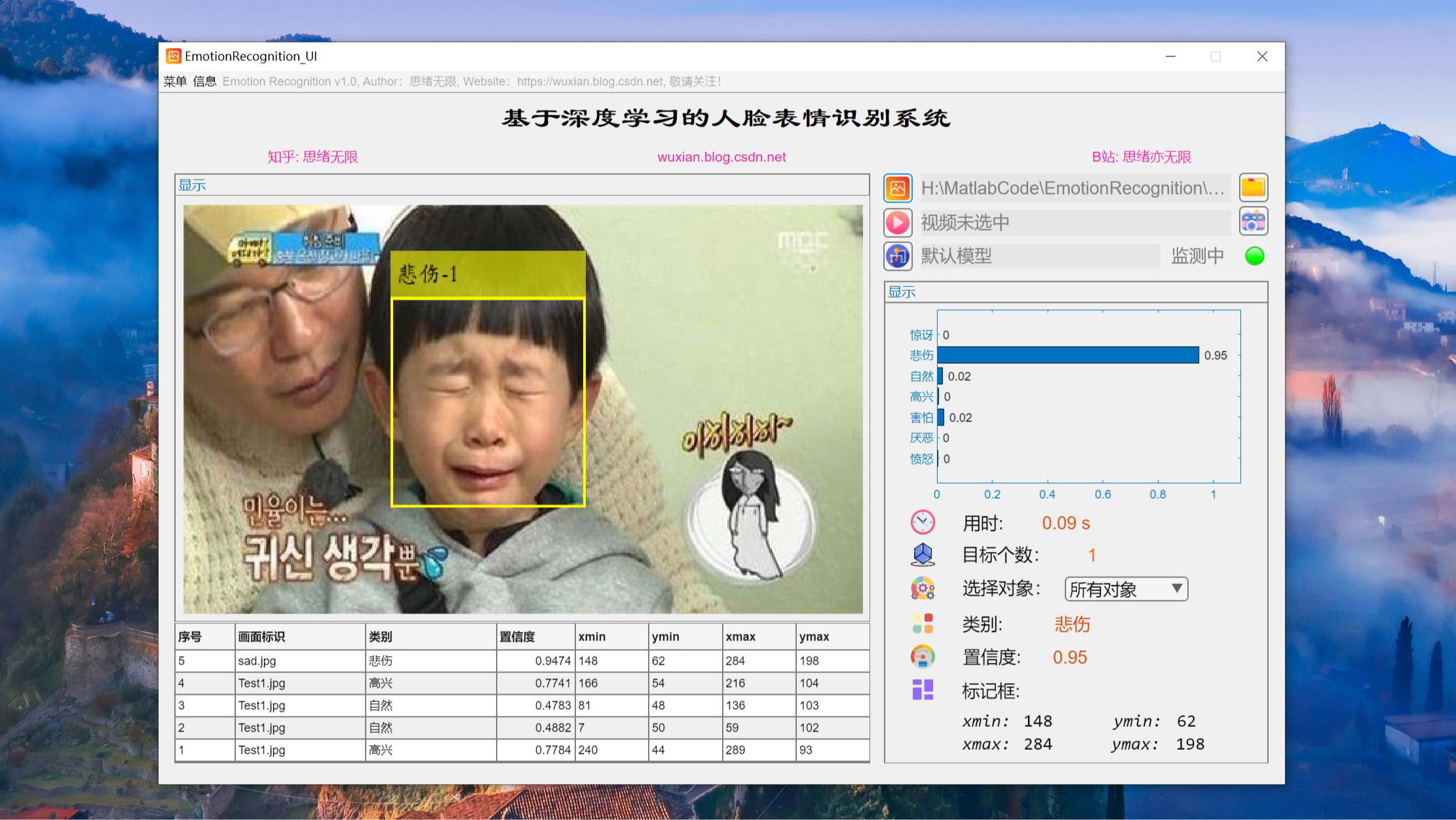
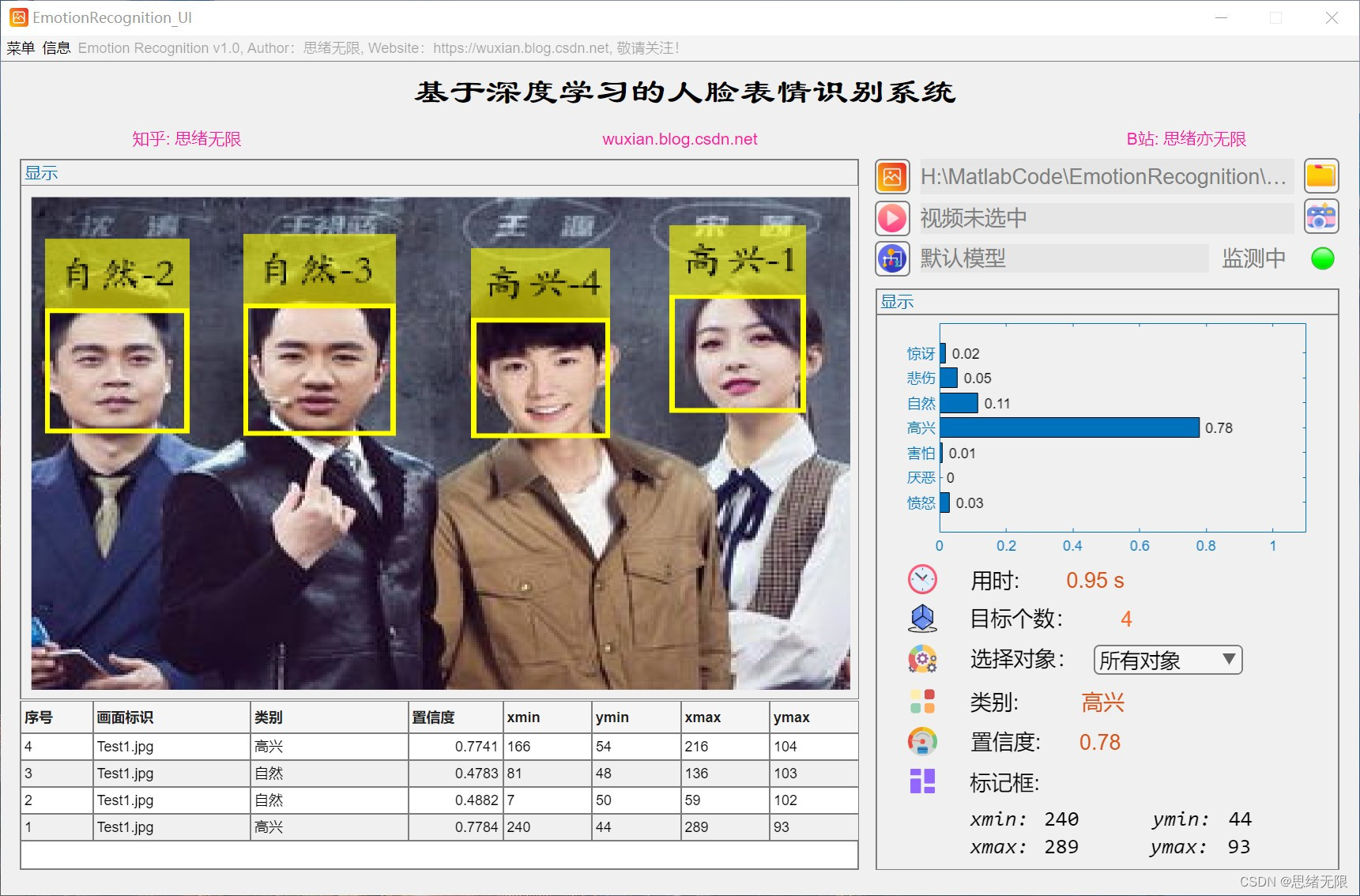
(1)图片识别:用户可以选择一张包含人脸表情的图片,系统将识别并显示图片中的表情。在GUI界面上,用户可以点击“选择图片”按钮,选择本地的一张图片,然后系统将自动识别图片中的表情,并在图片旁边显示识别结果。
(2)批量图片识别:用户可以选择图片文件夹实现批量图片识别,系统将识别并显示图片中的表情。
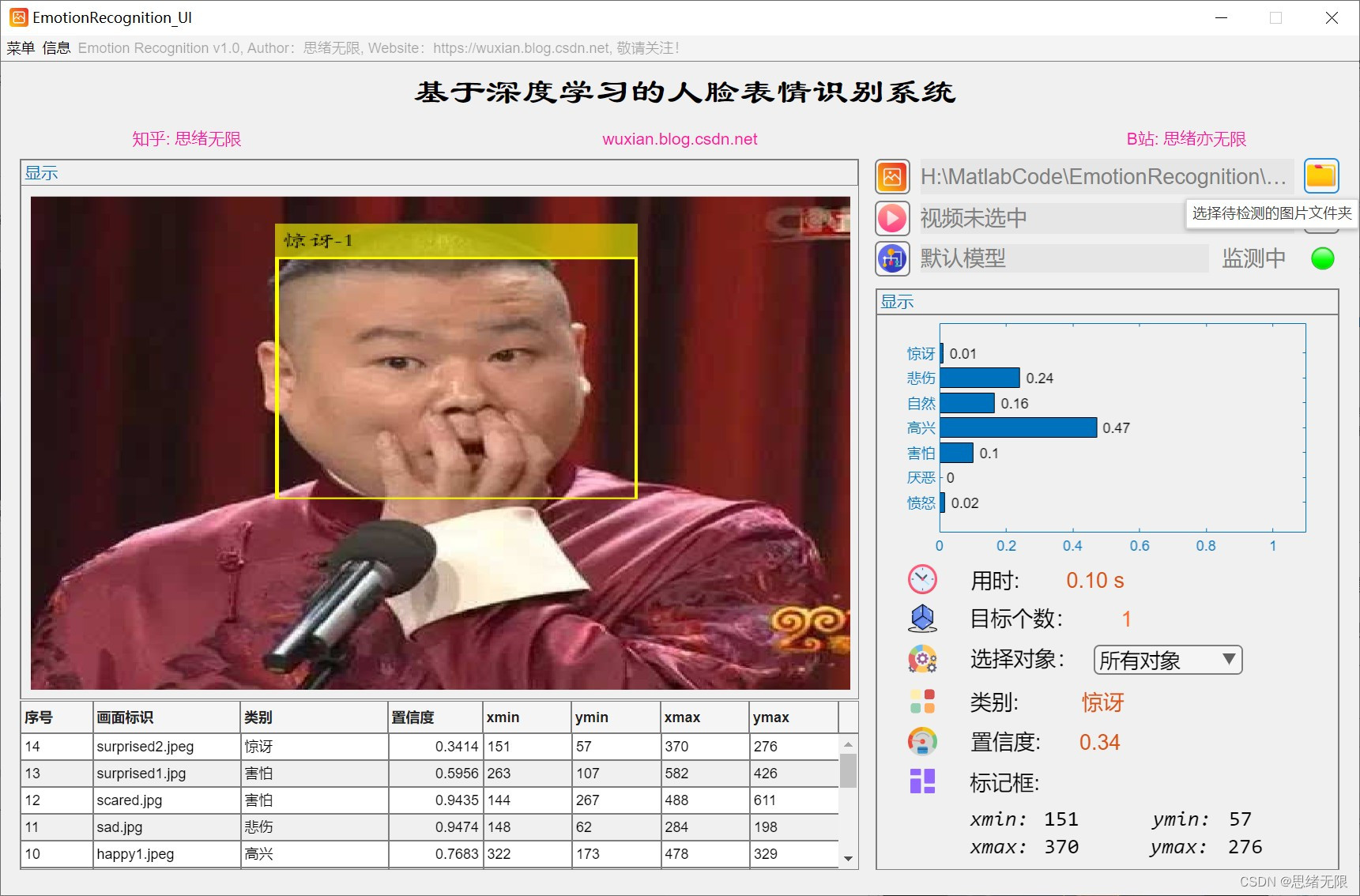
(3)视频识别:用户可以选择一个包含人脸表情的视频文件,系统将实时识别并显示视频中的表情。在GUI界面上,用户可以点击“选择视频”按钮,选择本地的一个视频文件,然后系统将自动播放视频并实时识别视频中的表情,同时在视频画面上显示识别结果。

(4)摄像头识别:用户可以通过电脑摄像头进行实时表情识别。在GUI界面上,用户可以点击“摄像头识别”按钮,系统将打开摄像头并实时识别用户的表情,同时在摄像头画面上显示识别结果。
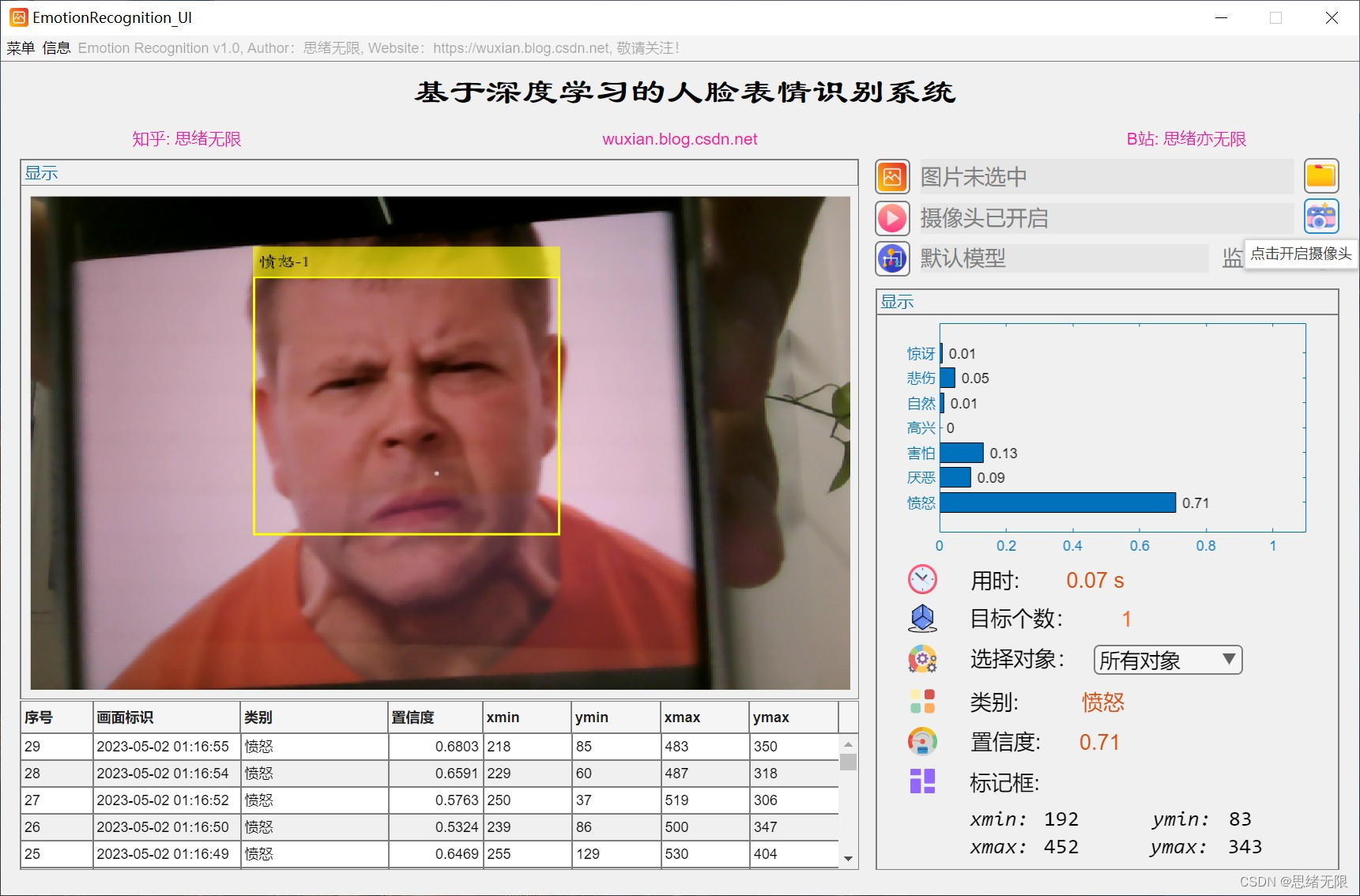
(5)更换模型和修改文字图标:用户可以点击右侧的模型选择按钮更换不同的模型,对于界面中的文字和图标的修改请在APP设计工具中修改。
3. 表情识别数据集
为了训练和评估所设计的人脸表情识别系统,我们需要使用表情识别相关的数据集。在本节中,我们介绍几个公开的表情识别数据集,并给出我们最终选择的数据集Fer2013和CK+48。
JAFFE (Japanese Female Facial Expression) 数据集:JAFFE数据集是日本女性面部表情数据集,包含了213张由10名日本女性演员表演的7种基本面部表情(愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性)的灰度图像。每种表情都有3个不同的程度。此数据集较小,但具有较高的标注准确率。官网链接:http://www.kasrl.org/jaffe.html
KDEF (Karolinska Directed Emotional Faces) 数据集:KDEF数据集包含了4900张由70名瑞典模特表演的7种基本面部表情(愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性)的彩色图像。每张图像均以五个不同的角度拍摄。这个数据集具有较大的样本量和多角度表情图片。官网链接:https://kdef.se/

AffectNet 数据集:AffectNet是一个大规模的面部表情数据集,包含约42万张面部表情图像。每张图像都标注了表情类别和面部活动单元(AU)信息。AffectNet适合训练和评估深度学习模型,尤其是用于自然环境中的面部表情识别。官网链接:http://mohammadmahoor.com/affectnet/
FERG (Facial Expression Research Group) 数据集:FERG数据集是一个包含人工生成面部表情的数据集,包括6个虚拟角色的6种表情(愤怒、厌恶、恐惧、快乐、悲伤和惊讶)的图像。此数据集的优点是可以通过渲染技术生成大量样本,但它的局限性在于不包含真实人脸图像。官网链接:https://grail.cs.washington.edu/projects/deepexpr/ferg-db.html
Fer2013:这是一个广泛使用的表情识别数据集,由Goodfellow等人于2013年发布[1]。Fer2013包含约35,000张灰度图像,涵盖了7种不同的表情类别,包括愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性。Fer2013数据集具有多样性和较大规模的优点,适合训练深度学习模型。官网链接:https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data

CK+:CK+(Cohn-Kanade+)数据集是由Lucey等人于2010年发布的一个面部表情数据集。CK+数据集包含了593个视频序列,涵盖了8种不同的表情类别,包括愤怒、厌恶、恐惧、快乐、悲伤、惊讶、中性和轻蔑。CK+数据集具有较高的标注准确率,提供了动态表情信息。链接:https://paperswithcode.com/dataset/ck
我们选择Fer2013和CK+作为我们的数据集,原因如下:首先,Fer2013具有较大规模和多样性,有利于训练出泛化能力较强的模型;其次,CK+数据集虽然样本量相对较小,但提供了动态表情信息和较高的标注准确率,可以作为补充数据集,提高模型的表现。我们将结合这两个数据集进行神经网络的训练和评估。
4. 网络训练与评估
在本节中,我们将通过训练一个神经网络来实现表情识别任务。实际上,表情识别可以被视为一个分类任务,我们需要在给定的人脸图像中识别出一种表情。为了简化数据处理过程,我们将Fer2013数据集原本的csv文件转换成图片格式,并将它们存放在train、test、val文件夹下。
首先,我们需要清除当前环境并设置随机数种子以保证结果的一致性:
clear
clc
rng default % 保证结果运行一致
接着,我们读取训练、验证和测试图像文件夹,创建ImageDatastore对象:
trainDir = fullfile("./train/");
valDir = fullfile("./val/");
testDir = fullfile("./test/");
imdsTrain = imageDatastore(trainDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
imdsValid = imageDatastore(valDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
imdsTest = imageDatastore(testDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
确定分类类别数量:
numClasses = numel(categories(imdsTrain.Labels))
% > numClasses = 7
在这里,我们选择使用MobileNetV2作为我们的基本神经网络模型。首先,我们创建一个MobileNetV2实例,并获取其层和输入尺寸:
net = mobilenetv2;
layers = net.Layers
inputSize = net.Layers(1).InputSize % 网络输入尺寸
此时打印网络的结构如下所示:
layers =
具有以下层的 154×1 Layer 数组:
1 'input_1' 图像输入 224×224×3 图像: 'zscore' 归一化
2 'Conv1' 卷积 32 3×3×3 卷积: 步幅 [2 2],填充 'same'
3 'bn_Conv1' 批量归一化 批量归一化: 32 个通道
4 'Conv1_relu' Clipped ReLU Clipped ReLU: 上限 6
5 'expanded_conv_depthwise' 分组卷积 32 groups of 1 3×3×1 卷积: 步幅 [1 1],填充 'same'
6 'expanded_conv_depthwise_BN' 批量归一化 批量归一化: 32 个通道
7 'expanded_conv_depthwise_relu' Clipped ReLU Clipped ReLU: 上限 6
8 'expanded_conv_project' 卷积 16 1×1×32 卷积: 步幅 [1 1],填充 'same'
9 'expanded_conv_project_BN' 批量归一化 批量归一化: 16 个通道
10 'block_1_expand' 卷积 96 1×1×16 卷积: 步幅 [1 1],填充 'same'
...
接下来,我们需要对网络进行微调,以便将其应用于我们的表情识别任务。我们首先使用全连接层替换原始网络中的Logits层,并为其设置权重和偏置的学习率因子:
newLearnableLayer = fullyConnectedLayer(numClasses, ...
'Name','new_fc', ...
'WeightLearnRateFactor',10, ...
'BiasLearnRateFactor',10);
lgraph = replaceLayer(lgraph,'Logits',newLearnableLayer);
然后,我们将分类层替换为一个新的分类层:
newClassLayer = classificationLayer('Name','new_classoutput');
lgraph = replaceLayer(lgraph,'ClassificationLayer_Logits',newClassLayer);
接下来,我们设置数据增强选项,并创建增强后的ImageDatastore对象:
pixelRange = [-30 30];
imageAugmenter = imageDataAugmenter( ...
'RandXReflection',true, ...
'RandXTranslation',pixelRange, ...
'RandYTranslation',pixelRange);
augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain, ...
'DataAugmentation',imageAugmenter, 'ColorPreprocessing','gray2rgb');
augimdsValidation = augmentedImageDatastore(inputSize(1:2), imdsValid, 'ColorPreprocessing','gray2rgb');
augimdsTest = augmentedImageDatastore(inputSize(1:2), imdsTest, 'ColorPreprocessing','gray2rgb');
我们选择使用随机梯度下降优化器(SGDM)作为我们的训练优化器,并设置训练选项,包括MiniBatchSize、MaxEpochs、InitialLearnRate等。我们还设置验证数据和验证频率,以便在训练过程中评估网络性能:
options = trainingOptions('sgdm', ...
'MiniBatchSize',64, ...
'MaxEpochs',300, ...
'InitialLearnRate',1e-4, ...
'Shuffle','every-epoch', ...
'ValidationData',augimdsValidation, ...
'ValidationFrequency',60, ...
'Verbose', true, ...
'Plots','training-progress', ...
'OutputNetwork', 'best-validation-loss');
现在我们已经准备好训练我们的神经网络了。使用以下代码进行训练:
model = trainNetwork(augimdsTrain,lgraph,options);
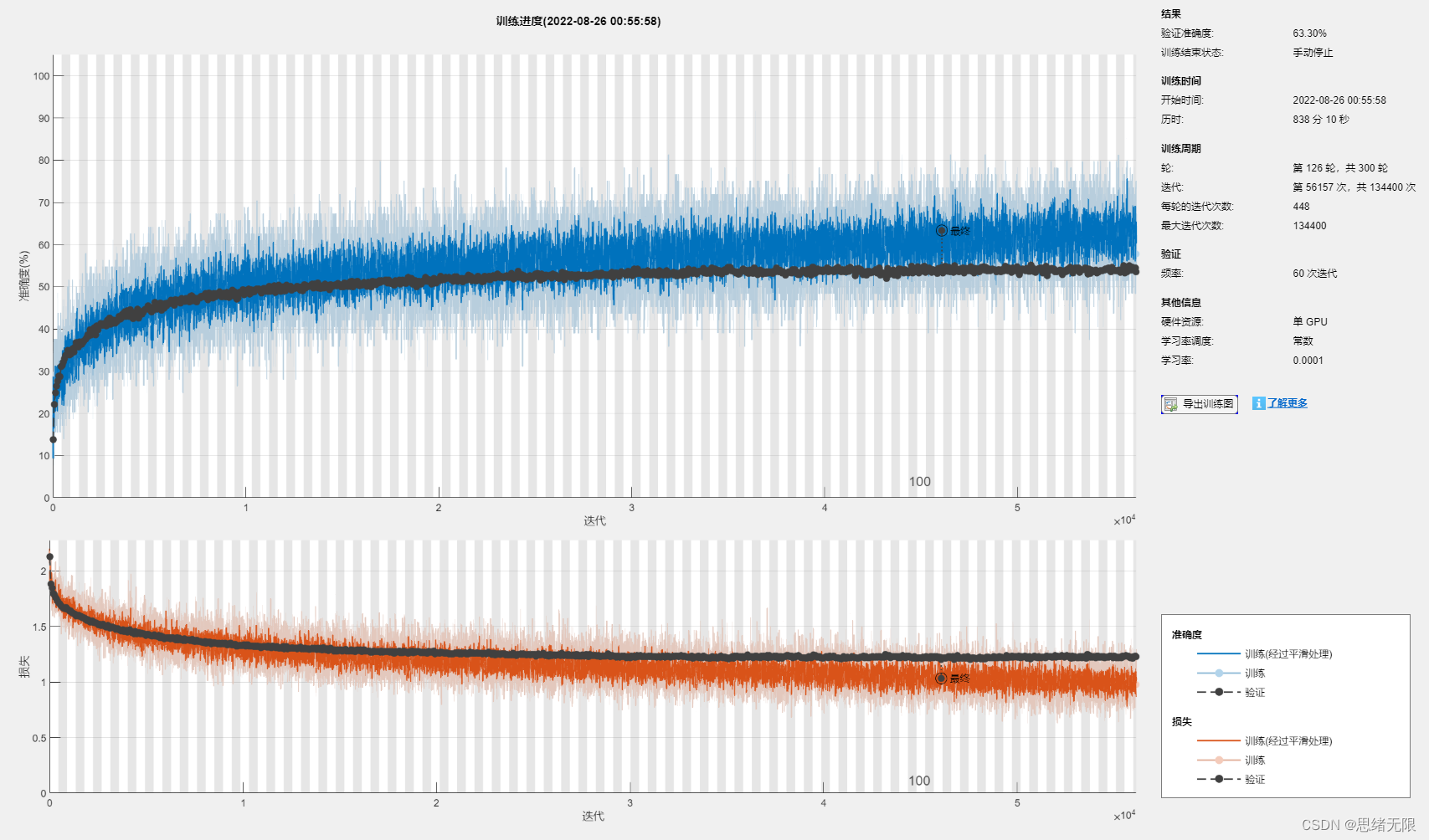
训练过程中的输出如下:
在单 GPU 上训练。
正在初始化输入数据归一化。
|=============================================================================|
| 轮 | 迭代 | 经过的时间 | 小批量准确度 | 验证准确度 | 小批量损失 | 验证损失 | 基础学习率 |
| | | (hh:mm:ss) | | | | | |
|=============================================================================|
| 1 | 1 | 00:00:15 | 9.38% | 13.74% | 2.1997 | 2.1275 | 1.0000e-04 |
| 1 | 50 | 00:00:57 | 18.75% | | 1.8871 | | 1.0000e-04 |
| 1 | 60 | 00:01:16 | 25.00% | 22.12% | 1.9477 | 1.8843 | 1.0000e-04 |
| 1 | 100 | 00:01:50 | 23.44% | | 1.8143 | | 1.0000e-04 |
| 1 | 120 | 00:02:12 | 31.25% | 24.85% | 1.6894 | 1.8497 | 1.0000e-04 |
...
训练完成后,我们将训练好的模型保存到一个名为MobileNet_emotion.mat的文件中:
save('MobileNet_emotion.mat', 'model');
接下来,我们使用测试数据集评估模型的性能:
[YPred,scores] = classify(model, augimdsTest);
随机选择4个测试图像并显示它们的预测结果:
idx = randperm(numel(imdsTest.Files),4);
figure
for i = 1:4
subplot(2,2,i)
I = readimage(imdsTest,idx(i));
imshow(I)
label = YPred(idx(i));
title(string(label));
end

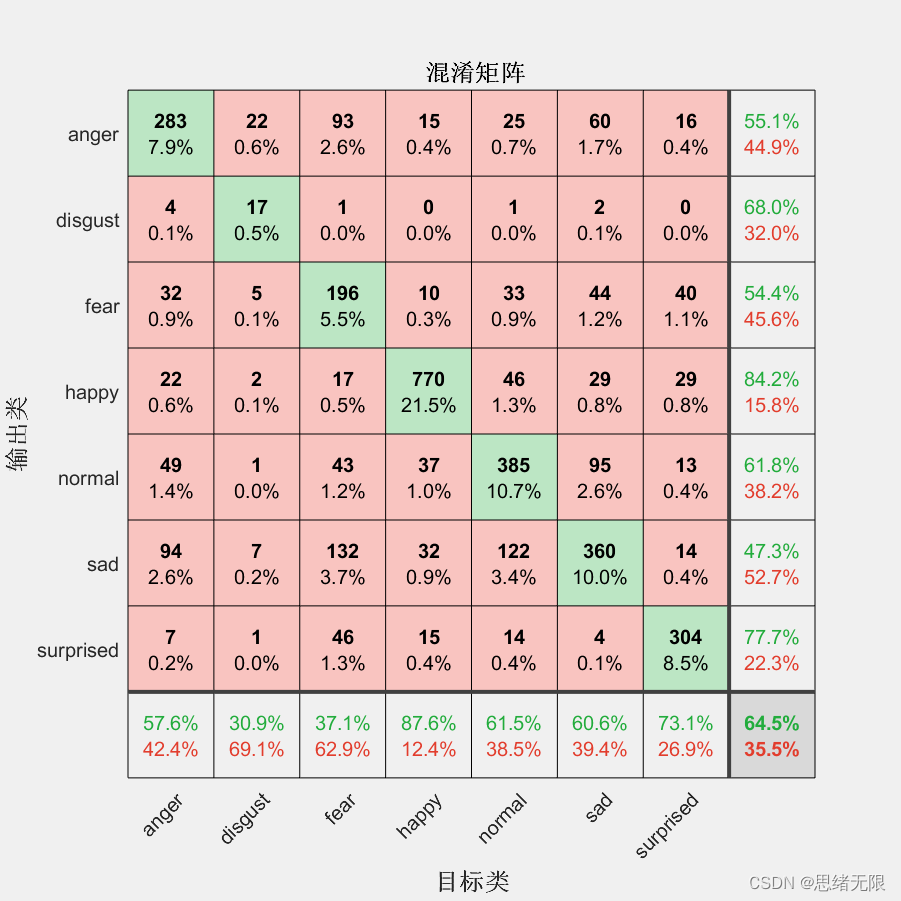
计算模型在测试集上的准确率:
YTest = imdsTest.Labels;
accuracy = mean(YPred == YTest)
% > accuracy = 0.6450
最后,绘制混淆矩阵以直观地展示模型的分类性能:
figure
plotconfusion(imdsTest.Labels, YPred); % 绘制混淆矩阵图
至此,我们已经成功地训练了一个基于MobileNetV2的表情识别神经网络,并对其进行了性能评估。在下一节中,我们将介绍如何将这个模型整合到一个完整的系统中。
5. 系统实现
在本节中,我们将介绍如何将已训练好的模型整合到一个完整的表情识别系统中。首先,我们将展示如何使用训练好的模型对摄像头画面进行实时检测并标注表情,然后结合GUI界面设计框架和实现。
值得注意的是,表情识别模型只对人脸部分进行表情分类。因此,在处理摄像头捕获的实时画面之前,我们需要先检测画面中的人脸。为此,我们使用了vision.CascadeObjectDetector()函数来实现人脸检测。该函数创建了一个级联对象检测器,用于检测图像中的人脸。
% 由于表情识别模型只对人脸部分进行表情分类,我们需要先检测画面中的人脸。
% 使用vision.CascadeObjectDetector()函数创建一个级联对象检测器,用于检测图像中的人脸。
faceDetector = vision.CascadeObjectDetector();
首先,我们加载所需的依赖项和模型,并获取模型的输入尺寸和定义类别名称:
load('MobileNet_emotion.mat', 'model');
inputSize = model.Layers(1).InputSize;
class_name = {'anger', 'disgust', 'fear', 'happy','normal', 'sad', 'surprised';...
'愤怒', '厌恶', '害怕', '高兴', '自然', '悲伤', '惊讶'};
然后,我们创建一个摄像头对象、一个用于显示实时视频的窗口以及一个用于保存带标签的视频的VideoWriter对象:
cap = webcam();
player = vision.DeployableVideoPlayer();
image = cap.snapshot();
step(player, image);
writer = VideoWriter('labeled_camera.avi'); % 要输出的视频
open(writer);
figure
在循环中,我们不断从摄像头捕获图像,然后使用emoRec函数对图像中的人脸进行表情识别。接着,我们将识别到的表情标签添加到图像上,并将结果显示在窗口中:
while player.isOpen()
Img = cap.snapshot();
Img = imresize(Img, [500, 700]);
[bboxes, scores, labels] = emoRec(faceDetector, model, Img);
num = size(bboxes, 1);
if num >= 1
label_text = cell(num, 1);
labels = cellstr(labels);
for i = 1: num
for cls_n=1:size(class_name, 2)
if strcmp(class_name{1, cls_n}, labels(i))
score = round(max(scores(i, :) * 100), 2);
label_text{i, 1} = [class_name{2, cls_n}, ' - ' , num2str(score), '%'];
break;
end
end
end
Img = insertObjectAnnotation(Img,'rectangle',bboxes, cellstr(label_text), ...
'LineWidth',2, 'Font','华文楷体','FontSize',16);
end
imshow(Img)
writeVideo(writer, Img); % 写入文件
end
最后,在用户关闭视频窗口时,我们关闭视频写入、释放视频窗口并删除摄像头对象:
close(writer); % 关闭文件写入
release(player); % 释放画面窗口
delete(cap); % 关闭相机
这样,我们就成功地将训练好的表情识别模型整合到一个实时的人脸表情识别系统中。系统将不断捕获摄像头画面,对画面中的人脸进行表情识别,并实时显示识别结果。演示的效果如下:

接下来,我们将设计一个基于MATLAB App Designer的GUI界面,以便用户可以更方便地使用我们的表情识别系统。以下是一个简单的设计框架:创建一个新的MATLAB App Designer项目。在设计界面中,添加以下组件:
- 选择图片按钮:用户可以通过单击此按钮来选择要进行表情识别的图片文件。
- 播放视频按钮:用户可以通过单击此按钮来播放要进行表情识别的视频文件。
- 摄像头开启按钮:用户可以通过单击此按钮来开启计算机上的摄像头,并开始进行实时的表情识别。
- 选择识别模型:用户可以通过此选项选择要使用的表情识别模型(例如,我们可以提供MobileNet和EfficientNet等不同的模型)。
- 显示结果:此处显示表情识别的结果,例如识别出的表情类别、置信度等信息。
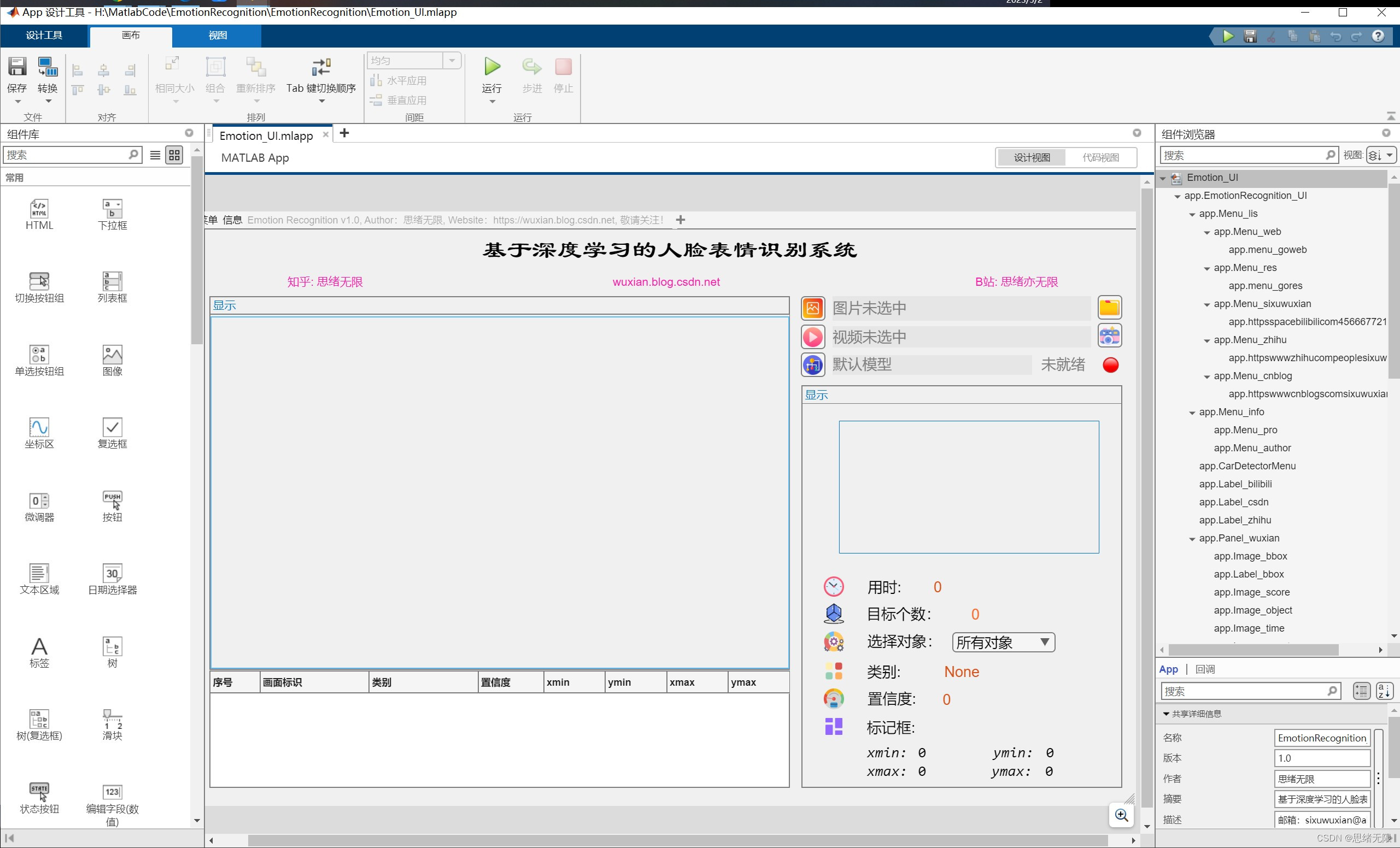
分别为打开图片、视频、摄像头、模型的按钮添加一个回调函数,以便在用户单击该按钮时执行相应的操作。在此回调函数中,可以使用上面提供的代码片段进行图片读取、预处理、表情识别和结果显示。至此,我们已经成功地将训练好的表情识别模型整合到一个完整的系统中。用户可以通过GUI界面选择图片,然后系统将对图片中的人脸进行表情识别,并显示识别结果。
下载链接
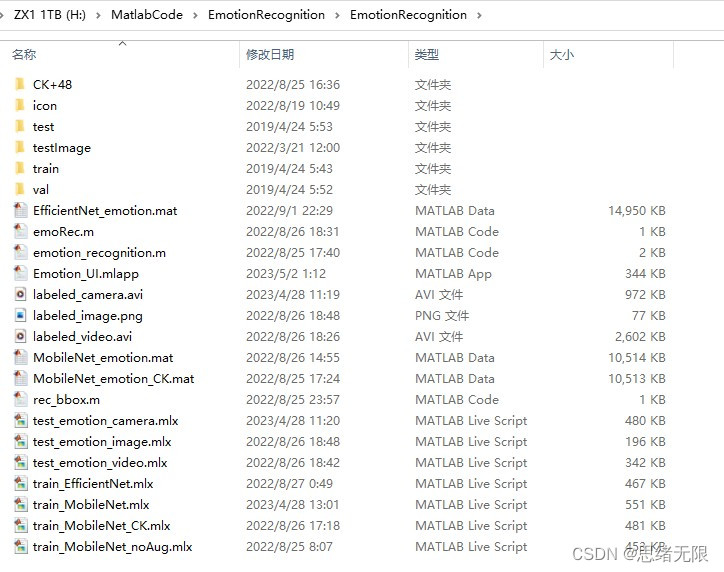
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,mlx, mlapp文件等,如下图),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
在文件夹下的资源显示如下图所示:
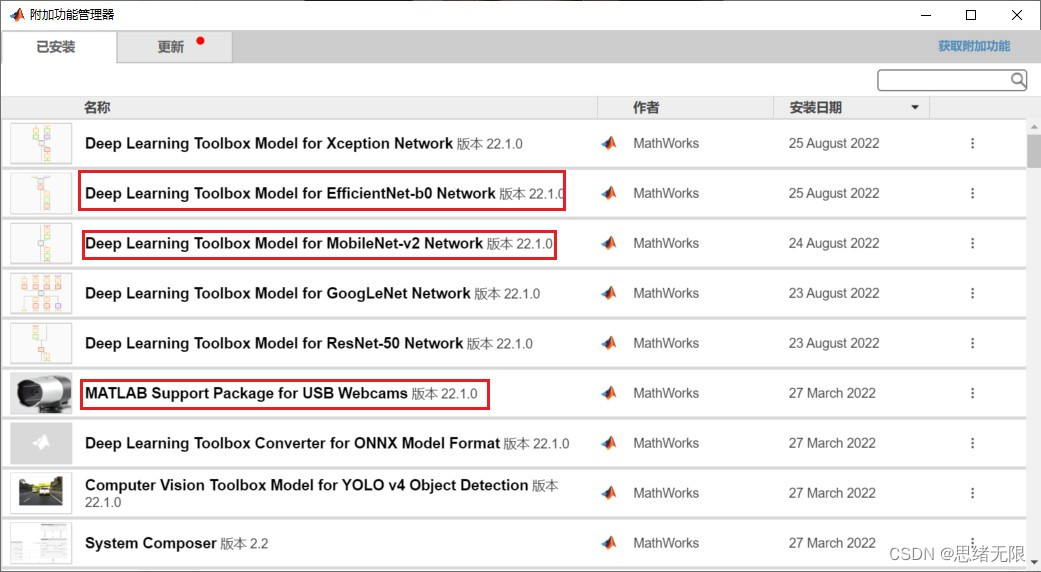
注意:该代码采用MATLAB R2022a开发,经过测试能成功运行,运行界面的主程序为Emotion_UI.mlapp,测试视频脚本可运行test_emotion_video.py,测试摄像头脚本可运行test_emotion_camera.mlx。为确保程序顺利运行,请使用MATLAB2022a运行并在“附加功能管理器”(MATLAB的上方菜单栏->主页->附加功能->管理附加功能)中添加有以下工具。
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见参考博客文章里面,或参考视频的简介处给出:➷➷➷
完整代码下载:https://mbd.pub/o/bread/mbd-ZJiYlpdu
参考视频演示:https://www.bilibili.com/video/BV1ts4y1X71R/
6. 总结与展望
本文详细介绍了基于MobileNet的人脸表情识别系统的设计与实现,包括数据集的选择、模型训练、GUI界面的设计等方面。通过本文的介绍,我们可以了解到如何使用深度学习技术实现人脸表情识别,以及如何构建一个GUI界面来实现人脸表情的实时检测。同时,本文也提供了详细的代码实现和资源文件,为相关领域的研究人员和新入门者提供了一个参考。未来的研究可以进一步改进模型的准确性和鲁棒性,并应用于更广泛的领域和应用场景中。
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
参考文献
[1] Goodfellow, I., et al. "Challenges in Representation Learning: A report on three machine learning contests." Neural Networks 64 (2015): 59-63.
[2] Lopes, A. T., et al. "Facial expression recognition with convolutional neural networks: coping with few data and the training sample order." Pattern Recognition 61 (2017): 610-628.
[3] Kahou, S. E., et al. "EmoNets: Multimodal deep learning approaches for emotion recognition in video." Journal on Multimodal User Interfaces 10.2 (2016): 99-111.
[4] Mollahosseini, A., et al. "AffectNet: A database for facial expression, valence, and arousal computing in the wild." IEEE Transactions on Affective Computing 10.1 (2019): 18-31.
[5] Zhang, K., et al. "Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks." IEEE Signal Processing Letters 23.10 (2016): 1499-1503.
[6] Khorrami, P., et al. "Do deep neural networks learn facial action units when doing expression recognition?" Proceedings of the IEEE International Conference on Computer Vision Workshops (2015): 19-27.
[7] Kaya H, Gürpınar F, Salah A A. Video-based emotion recognition in the wild using deep transfer learning and score fusion[J]. Image and Vision Computing, 2017, 65: 66-75.
[8] Liu, Z., et al. "Joint face detection and alignment using multitask cascaded convolutional networks." IEEE Signal Processing Letters 23.10 (2016): 1499-1503.
[9] Howard, A. G., et al. "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications." arXiv preprint arXiv:1704.04861 (2017).
[10] Sandler, M., et al. "MobileNetV2: Inverted Residuals and Linear Bottlenecks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018): 4510-4520.
[11] Hu L, Ge Q. Automatic facial expression recognition based on MobileNetV2 in Real-time[C]//Journal of Physics: Conference Series. IOP Publishing, 2020, 1549(2): 022136.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号