K-means聚类
K均值(K-Means)算法是一种无监督的聚类学习算法,他尝试找到样本数据的自然类别,分类是K由用户自己定义,K均值在不需要任何其他先验知识的情况下,依据算法的迭代规则,把样本划分为K类。K均值是最常用的聚类技术之一,通过不断迭代和移动质心来完成分类,与均值漂移算法的原理很相似。
K均值算法的实现过程:
- 对于一组未知分类的数据集合,指定其分类数K;
- 随机分配K个类别的中心点位置,分配的原则是各个类别的中心点距离彼此越远越好。
3.将数据集中的每一个点进行类别划分,划分的距离N个初始的类别中心点中哪一个的距离最近,就划入哪一类;
4.根据上一步中初步划分的N个类别,分别计算当前每一类的样品中心,并移动初始中心点到当前集合所在的中心。
5.去除数据集合中每个点的归类属性,依据上边产生的中心点,转到第3步,迭代执行,直到中心点收敛。
K均值的核心就是不断移动类别划分的中心点,直到该点稳定下来或者达到所设置的最大迭代次数,这时当前中心点所划分的类别就是最终的K均值对样本数据的聚类。
下图是对K-Means迭代过程的简单演示。假设有n 个数据样本需要进行分类,这里k取值 为2:

(a)初始数据集合
(b)随机选取两个点作为初始聚类中心
(c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去
(d)计算每个聚类中所有点的坐标平均值,并将这个平均值 作为新的聚类中心
(e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去
(f) 重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心,直到满足迭代条件。

虽然K-Means算法原理简单,也有自身的缺陷:
1.K值的选择需要用户指定,实际中K值 的估计很难做到准确,并且不同的K值得到的结果可能差别很大。
2.初始的聚类中心点的设定对结果影响较大。不同的初始聚类中心可能导致完全不同的聚类结果,并且不能保证K-Means算法收敛于全局最优解,极端情况下有可能达到局部收敛。
3.时间复杂度高0(nkt),其中n是对象总数,k是簇数,t是迭代次数。数据库较大的时候,收敛会比较慢。
1) 聚类簇数K没有明确的选取准则,但是在实际应用中K一般不会设置很大,可以通过枚举法,比如令K从2到10。其实很多经典方法的参数都没有明确的选取准则,如PCA的主元个数,可以通过多次实验或者采取一些小技巧来选择,一般都会达到很好的效果。
2) 从Kmeans算法框架可以看出,该算法的每一次迭代都要遍历所有样本,计算每个样本到所有聚类中心的距离,因此当样本规模非常大时,算法的时间开销是非常大的。
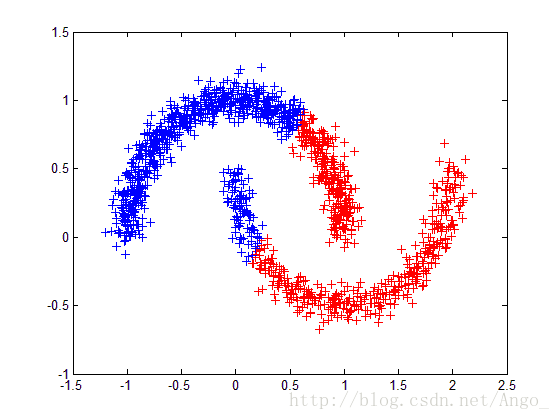
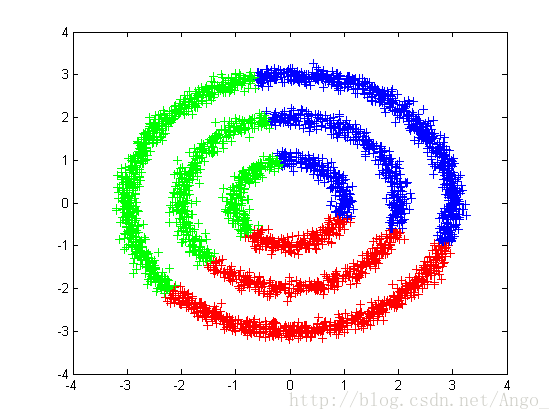
3) Kmeans算法是基于距离的划分方法,只适用于分布为凸形的数据集,不适合聚类非凸形状的类簇,如图3所示。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号