3D物体检测论文笔记
3D物体检测论文笔记
原文:Mousavian A, Anguelov D, Flynn J, et al. 3d bounding box estimation using deep learning and geometry[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 7074-7082.
Summary
3D物体框预测是一个6DoF问题(3维位置+3维尺寸+3维朝向),在2D目标检测比较成熟的情况下,准确地做到3D物体框的检测依然存在很多困难。此前,对于3D物体框的检测手段有匹配物体关键点的和基于渲染的3D模型的,但是在硬件计算量和3D物体框属性完整性上存在问题。
本文基于CNN网络及VGG架构,提出了一个轻量级的、可搭载的可预测3D物体框所有属性的模型:模型从相机投影公式出发,在2D物体框的每一条边至少存在一个3D物体框拐角在图像上的投影的假设下,使用模型预测期望准确性较高的属性,再根据相机投影公式的约束将余下的不便预测的属性求解出。
- 2D物体框由模型预测,其4条边参与的约束公式能给出4条约束。
- 3D尺寸和3D朝向由模型预测,其能够将原问题的9自由度降低至3自由度。
- 1中的4条约束用于求解2中剩余的3个自由度,多出来的约束用于选择误差最小的”3D顶点落在2D边框“的配置。
文章研究领域的任务类型区分(可能分类存在问题):
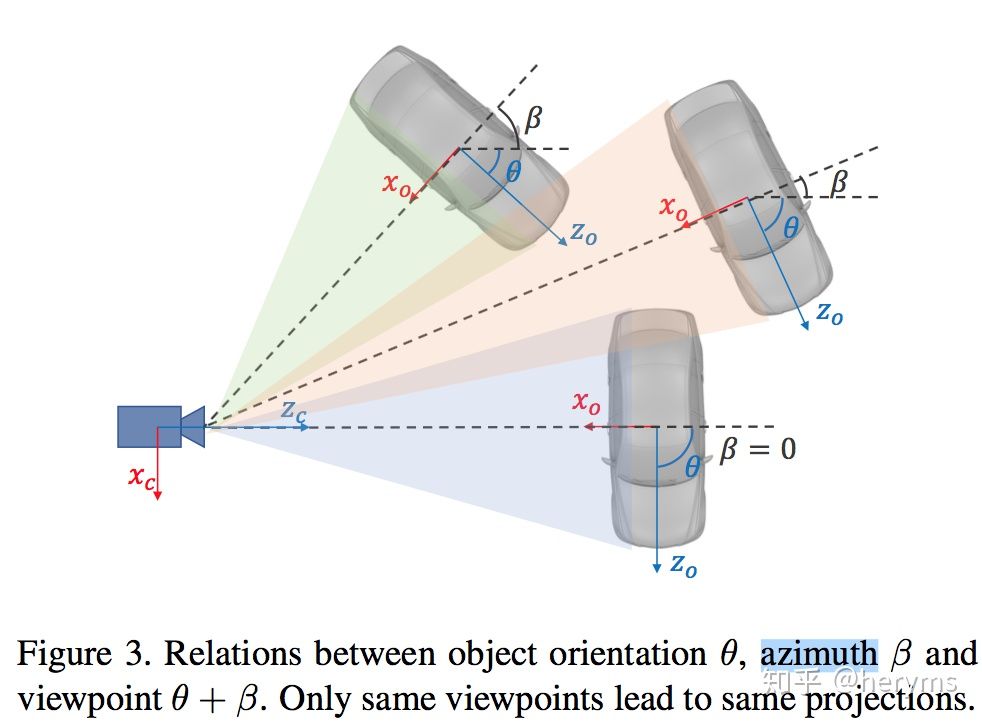
- viewpoint estimation:视角检测是一个与相机位置有关的概念,其表示物体相对相机坐标系下的朝向情况。(一般朝向都指代在世界坐标下的角度情况,即orientation)
- viewpoint与orientation、azimuth关系为\(viewpoint = orientation + azimuth\),orientation是物体在世界坐标下的朝向,azimuth是物体相对相机的方向。
- 当物体在世界坐标系下保持静止不动时,若相机发生移动则viewpoint可能变化。
- orientation estimation:物体在世界坐标系下的朝向。
- object dimension estimation:物体的尺寸,length + width + height。
- position estimation: 预测某点在3D位移坐标下的位置。
- 3D pose estimation:The combination of position and orientation is referred to as the pose of an object 。
注:
-
本文研究的3D物体框预测问题 = 3D pose + dimension = orientation + position + dimension。
-
在本文中,viewpoint可以被称作局部朝向(local orientation),而orientation则被称作全局朝向(globla orientation)。
图示:
Highlights
1 约束设计和预测属性选择
原理公式
在理想相机环境下,给定相机固有矩阵\(K\),物体的姿态(pose)\((R, T) \in SE(3)\) 和 某点在物体坐标系下的坐标 \(\pmb{X_o} = [X, Y, Z, 1]^T\),其投影在图像上的位置为$$\pmb{x} = [x, y, 1]^T$$,而投影运算可以计算为
上述公式的右侧可以进一步地拆分为
其中\(L = [X,Y,Z]\)), 可解释为在\(x\)的坐标是物体坐标系的中心在世界坐标下的位移\(T\),再加上\(X_o\)坐标经过旋转矫正与世界坐标无旋度差异的坐标,最后再经过相机矩阵\(K\)所得到的。
约束设计
模型假设:在正确标注出的2D物体框与3D物体框之间,对于2D物体框在图像上的每一条边,必定包含3D图像框的一个顶点在图像上的投影。
若以2D物体框在x方向的最小坐标为例,并且3D框的\(\pmb{X_0}=[d_x/2, -d_y/2, d_x/2]^T\)对应2D框在x方向的下界,则可以写作:
注:\(()_x\)表示仅取结果x方向上的值。
下面分析3D物体框求解任务中的自由度:
- K:相机固有属性,已知
- R:旋转倾向矩阵(世界坐标),在3D物体框预测任务中占有3个自由度(3个未知数)。
- T:位移矩阵(世界坐标),在……任务重占有3个自由度(3个未知数)。
- \(X_i\):3D框的顶点(物体坐标),等价于3D框的尺寸,在……任务重占有3个自由度(3个未知数)。
💡在利用上述的约束公式由于2D框有4条边,因此能够提供4个约束,显然无法直接求解。
因此方法使用SOTA模型求解出了2D物体框,并选择了旋转矩阵R和尺寸信息\(X_0, X_1, ..., X_7\)共6个自由度用模型预测。剩余的3个自由度(物体位移)用4个约束是能够解出的。
但同时,还存在一个潜在自由度——模型假设中的边框与顶点的对应关系是不一定的(该自由度取值数量有限,根据公式真实情况应该是\(8^4=4096\)中的至少一个),因此4个约束恰好求解。在求解时,可以有限遍历所有对应关系,使用3个约束求解物体位移,再使用1个约束用以验证对应关系的正确性,最终选择验证时误差最小的作为解答。

2 朝向预测的目标函数
图像信息比较直观地显示了物体相对相机的朝向(viewpoint),在结合物体相对相机所在的方位信息(azimuth),利用公式\(orientation = viewpoint - azimuth\)才能够求解世界坐标下的绝对朝向,因此3D物体框的朝向信息是模型的输出再经过角度运算得到的。
下图展示了物体在不动情况下,视角运动造成的viewpoint、azimuth变化。
⚠️ 注:为了方便表述,将viewpoint表示为局部朝向(local orientation),将orientation表示为全局朝向(global orientation)。

损失函数设计
常用损失函数:Mean Square Error,表现不佳。其鼓励模型预测各类连续分布情景下的平均状态,导致陷入平均状态,推理结果四不像。
借鉴anchor box的方位角损失函数设计:
在目标识别领域,锚框技术是常用的一种技术。通过在目标区域人为预先设定锚框的位置和尺寸,模型的任务转变为对于每个锚框,预测其中的物体类别(包括背景类型)以及物体真实框相对设定锚框的位置偏移和尺寸偏移。
本模型在预测时借鉴了这类思想,首先将3D的局部朝向可能的区域人为划分为多个区域(区域之间允许有重叠),模型的任务转变为预测局部朝向落在各区域的概率(分类任务)和局部朝向相对每个区域中心的偏移量(回归任务)。
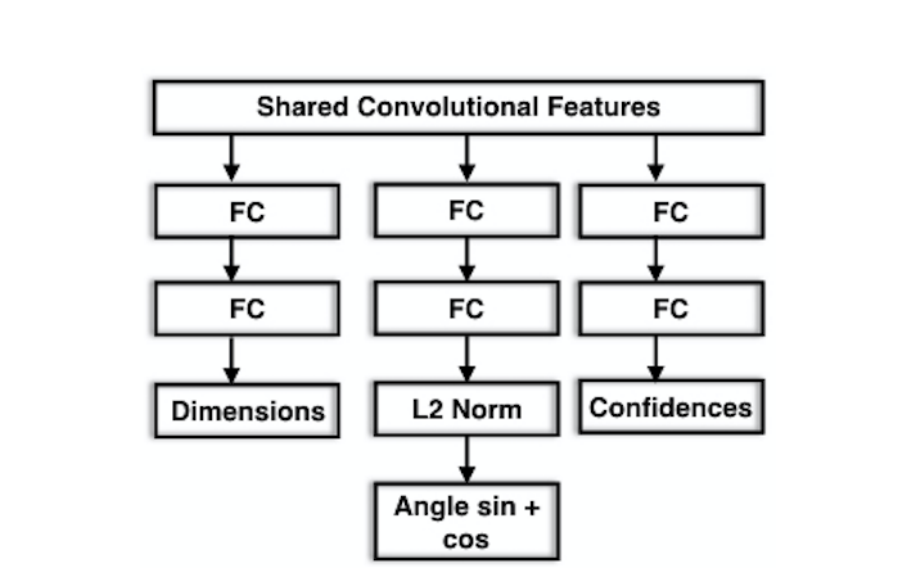
- \(L_{conf}\)表示分类任务的目标函数。
- \(L_{loc} = -\frac{1}{n_\theta*}\Sigma cos(\theta^* - c_i - \Delta\theta_i)\),\(n_{\theta^*}\)表示划分区域数量。
物体尺寸估计的损失函数设计:
和方位角不同,在应用场景下物体的尺寸差异较大,不易产生平均模式的问题,因此使用MSE作为目标函数。
对于模型最终结构和输出如下图所示:
实验操作
- 对于KITTI数据集的数据增强:
- 所有输入的图像块resize到224x224.
- 随机的色彩失真
- 随机的镜像变换
- 限制总训练实例的数量,并重复将汽车数据用于训练。
- 疑问
- 从论文来看,3D物体框的尺寸和朝向预测仅使用了局部的2D物体框信息,实验结果显示模型是利用物体的某些关键部件(如轮胎)用以判断的,这对被resize的图像进行尺寸预测是否可行呢?(仅拼接视觉效果人工都很难做到,一种猜测是根据某些尺寸一定的部件进行估计)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号