文献阅读报告 - 3DOF Pedestrian Trajectory Prediction
文献
Sun L , Yan Z , Mellado S M , et al. 3DOF Pedestrian Trajectory Prediction Learned from Long-Term Autonomous Mobile Robot Deployment Data[J]. 2017.

概览
文章所提出的模型基于LSTM框架,旨在预测行人的姿态信息(位置坐标和朝向)。就模型本身而言,其结构基本与Vanilla LSTM保持一致,不具有共享LSTMs信息的池化层结构,但数据有所改变:数据为3DOF行人姿态的称作Pose-LSTM,数据为3DOF行人姿态+Time的称作T-Pose-LSTM,与此同时,文章在数据、训练等又有新的创新点。
创新点
- 自动标注:受益于当今更加先进的2D laser and RGB-D sensors 和 3D LiDAR,使得移动机器人准确测量成为可能,文章模型评估时所使用的数据正是由上述两种sensors感应和自动标注完成的。
- 新增行人姿态和时间日期信息:模型的输入和输出在原有世界坐标系下二维坐标的基础上,增加转向角(yaw)方向坐标,形成了3DOF数据,评价指标在ADE基础上增加AEDE(平均欧拉角度误差);并且输入了兼顾长时间和短时间的日-小时-分-秒信息,使模型关注长时间下环境的变化。
- 长时常数据和动态训练长度:文章评估模型时所使用数据库之一的STANDS具有约3192h的信息记录,相比UCY、ETH等小于1小时的数据库时间跨度大幅提升,更符合移动机器人实际环境下的应用;同时,在训练时模型并不指定统一的
seq_length,长度根据轨迹原有长度自动调整,只需定义最大长度并结合真值mask即可统计每条轨迹输出中的有效部分。
Future Work
- 扩展L-CAS数据库(现时长小于1h)至数周时长。
- 调研Pose-LSTM在真实环境下动态学习训练的可能性。
模型概述
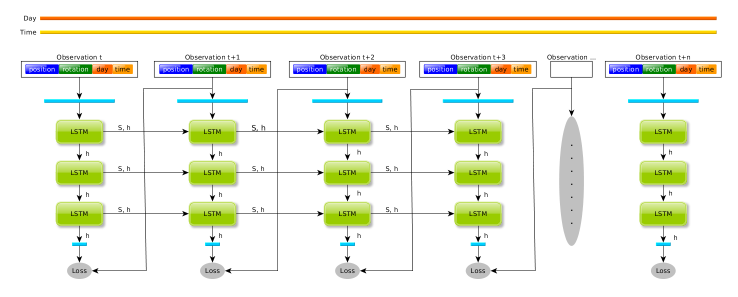
T-Pose-LSTM和Pose-LSTM仅在输入数据上有日期时间的差异,在介绍时以T-Pose-LSTM为中心。下图中我们可以看到T-Pose-LSTM的基本结构,其与轨迹预测的Vanilla LSTM基本模型是基本一致的:
- 默认具有三层的LSTM结构,但每层的LSTM Cell均共享一个权重系数以免增加权重。
- 场景中出现的每一条轨迹对应一个LSTM序列,但序列之间是完全独立的,没有池化层等信息交流的途径。
数据规范
给定已知随时间变化(间隔为\(\Delta t\))的轨迹信息\(O:\{o_t, ...,o_{t+n+1}\}\),模型实质为\(\{o_t, ..., o_{t+n}\}\)与\(\{o_{t+1},...,{o_{t+n+1}}\}\)之间的encoder-decoder。对于原始的\(o_t\)数据应为6DOF——六自由度数据:
但基于行人的水平面高度是固定的,只具有偏航(yaw)的角度自由度,因此\(o_t\)可以被简化为:
数据规范中的一个重点是6DOF格式数据,其是用于衡量刚体的姿态信息的数据规格,包括三个空间坐标和三个沿轴旋转的角度。对于三维空间中的角度变换,文章中的数据并没有熟悉的三维角度坐标\((\alpha,\beta,\gamma)\)表示,而是使用了**汉密尔顿四元数\((q_x,q_y,q_z,q_w)\) **,汉密尔顿四元数实际刻画四维空间的旋转,通常其用于表示特殊的旋转(三维空间中绕轴旋转):
-
给定三维轴向量\((x,y,z)\),对应四元数\(q=(cos({\theta\over2}),sin({\theta \over 2})*x,sin({ \theta \over 2})*y, sin({\theta \over 2}) * z)\)(其中\(\theta\)为旋转绕轴旋转角度)
-
四元数共轭为\(q^{-1}=(cos({\theta\over2}),-sin({\theta \over 2})*x,-sin({ \theta \over 2})*y, -sin({\theta \over 2}) * z)\)
-
对于三维坐标中的待旋转点\((w_x,w_y,w_z)\),生成其纯四元数\(q_w=(0,w_x,w_y,w_z)\),则其绕轴旋转后的四元数(也就是坐标)为:
\[(0,w_x',w_y',w_z') = q * q_w * q^{-1} \] -
结论:根据四元数\(q\)的定义方式,我们就可以知道为什么6DOF数据中\((q_x,q_y,q_z,q_w)\)在仅有偏航旋转(绕z轴旋转)的假设上变化为\((0,0,q_z,q_w)\)。
安利有关四元数的原理和应用的知乎回答,上文也摘编自其。
如何形象地理解四元数? - Yang Eninala的回答 - 知乎
https://www.zhihu.com/question/23005815/answer/33971127
模型公式
LSTM迭代公式:
模型预测输出格式:\((\mu_x,\mu_y,\sigma_x,\sigma_y,\rho, q_p^z,q_p^w)\):
- \((\mu_x,\mu_y,\sigma_x,\sigma_y,\rho )\)用于基于二维高斯分布求解二维坐标。
- \((q_p^z,q_p^w)\)合成为\((0,0,q_p^z,q_p^w)\)四元数,用于计算方向姿态。
损失函数
模型的损失函数由三部分组成:第一部分是二维坐标损失,其计算基于输出是二维高斯分布的假设,PDF-Gaussian Probabilistic-Density-Function 所求的其实就是\((x_{gt},y_{gt})\)在预测高斯分布下的概率密度;第二部分是角度偏向损失,使用欧拉角度距离;第三部分是L2正则化损失函数,防止神经网络过拟合。
之前提到过模型训练需支持动态序列长度,因此用于存储序列数据的向量长度并未和序列真实长度一致,因此需要使用mask去除无关的loss,\(1[.,.]\)是真值函数:
实验
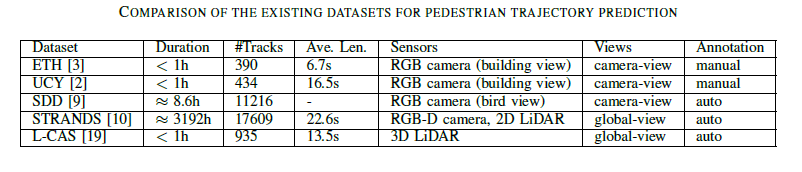
数据集
文章所用的均是新数据集-STRANDS、L-CAS,分别由装载在可移动机器人上的2D with depth sensor和3D LiDAR采集,并都将坐标转换到了世界坐标系下。
STRANDS
- 场景:关护中心的服务机器人,历时19周,行走距离87km。
- 技术:自动标注,对于行人检测,使用kinect检测上肢,2D-laser检测下肢,二者合成卡尔曼滤波追踪框架。
- 数据:共采集17609个轨迹,平均时长22.6s。
L-CAS
- 场景:林肯大学的大型室内空间-餐厅、咖啡店和休息区,包含挑战性轨迹如团队、小孩、手推车等。历时19分钟。
- 技术:Velodyne VLP-16 3D LiDAR
- 数据:共采集925个轨迹,平均时长13.5s。
评价
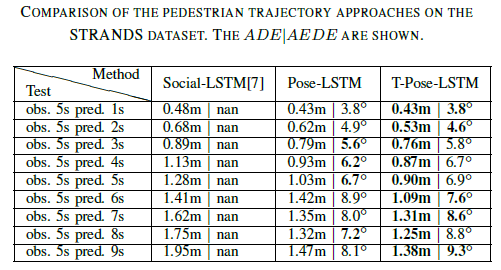
- 对比模型:Social LSTM、Pose-LSTM、T-Pose-LSTM
- ADE - Average Distance Error
- AEDE - Average Eulerian angle Difference Error \({1 \over {N*n}}\Sigma^N_i \Sigma^n_j min (|r_p^{i,j} - r_{gt}^{i,j}|,2\pi-|r_p^{i,j} - r_{gt}^{i,j}|)\)
- STRANDS:\(\Delta t =1s\),输入5s,预测后续的1-9秒。三分之二训练,其余预测。
- L-CAS:\(\Delta t = 0.4\),输入3.2秒,预测后续4.8秒。三分之二训练,其余预测。
High Lights
- STRANDS测试中,预测时间小于5秒时三种方法性能相近,5S后T-Pose-LSTM表现显著提升。
- STRANDS测试中,Pose-LSTM和Social-LSTM对比发现纵使没有提供时间信息,姿态信息也有助于提升位置判断的准确性。
- L-CAS测试中,Pose-LSTM的AEDE误差高达\(35^o\) ,这是因为使用贝叶斯追踪器自动标准静态人并不准确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号