基于图的神经网络资料阅读整理
基于图的神经网络资料阅读整理
近日在阅读文献Situation-Aware Pedestrian Trajectory Prediction with Spatio-Temporal Attention Model,其提出的模型用于解决在存在行人和静态物体的环境中,对行人轨迹进行预测的问题。文中的模型借用了许多已有经典模型,并对其进行应用和修饰,但由于缺乏对这些经典模型的了解,因此阅读此文存在一定困难。
根据此文重点参考的文献,有必要这些文献进一步了解,在此阅读了有关文献的阅读报告,为之后的阅读做一个背景铺垫。主要摘要内容如下:
- SRNN——Spatio-Temporal Attention Model的基本框架:Spatio-temporal graph(时空矩阵)、factor graph(因子图)定义与参数共享、nodeRNN&edgeRNN。
- Multi-Head Attention是模型注意力的具体实现方式:Self-Attention(自注意力机制定义与原理)、multi-head attention(多头注意力模型结构)。
- Graph Attention Network是将multi-head attention用在图结构上的具体实现:图上的卷积核、注意力系数的计算、多头注意力并行计算。
Model 1:Structural RNN(S-RNN)
参考
- 原文 - Structural-RNN: Deep Learning on Spatio-Temporal Graphs
- https://blog.csdn.net/UniSerj/article/details/81301363 文献报告
- https://en.wikipedia.org/wiki/Factor_graph Factor Graph 因子图概念定义
SRNN是“Spatio-Temporal Attention Model”模型的基础和整体框架,了解SRNN的基本定义与原理非常重要。SRNN模型是将Spatio-Temporal Graph(时空图)上图的两种组成成分——点和边加强和替换所得到的结果。
时空图向SRNN转换的过程
Spatio-Temporal Graph ---(factorize the graph)---> Factor Graph ---(replace fatcor with RNNs)-> S-RNN
Spatil-Temporal Graph
时空图(st-graph)是一种用于刻画多个物体之间在空间与时间维度上交互的图结构。
按照组成图结构的基本元素——点和边,st-graph中的点和边都会被赋予对应的特征值(向量)- Features,而st-graph的最终目的则是根据点和边的特征值(向量)预测每一步时间中点的标记的Labels。因此Input是features,而Output是label,features和labels在不同类型的任务下存在差异,并且含义可能相同也可能不相同。例如在文中提到,当研究人-物品交互时:
-
nodes的特征值可能是人或物品的姿态。
-
edges的特征值可能是之间的倾向关系。
-
nodes的labels可能是人的活动类型和物品可供性。
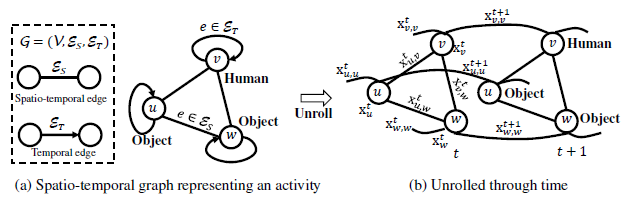
在st-graph中,连接Node之间的Edge被分类为2种,第一种是Spatio-Temporal Edge,其用于连接同一个时刻中不同物体之间以表示物体之间的相互影响情况,如\(x_{v,w}^t\);第二种是Temporal Edge,用于连接相邻时刻之间的同一个物体,如\(x_{w,w}^{t+1}\)。当st-edge和t-edge被转化为因子式后,受共享参数的影响,还需要在两类edges中再分子类,具体见下文。
Factor Graph
Factor Graph称作因子图,在维基百科定义中“将一个具有多变量的全局函数因子分解,得到几个局部函数的乘积,以此为基础得到的一个二分图叫做因子图。”
具体在此参考文献中,st-graph借助各个nodes和edges的features得到nodes的labels,st-graph可被看做是从features到了labels的全局函数,但此全局函数过于复杂,因此基于图的语义:图由点和边组成,将st-graph整个全局函数拆分成点因子函数和边因子函数。
Question:
按照因子图的定义:这些因子函数(factor function)作为二分图一侧的点,而原文的features作为二分图另一侧的点,只有异侧的点之间存在连线,最终合成的就是factor graph。
但是,参考文献中的factor graph似乎并没有体现出edges的features,edge factor所连接的对象不是edge而是node。目前推测是由于实际实验中,edge的feature可由node的feature计算出来,因此所有的factor都直联node。
点因子函数:$$\Psi_v(y_v,x_v)$$
边因子函数:$$\Psi_e(y_{e(1)},y_{e(2)}, x_e)$$
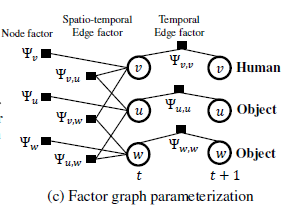
因子函数的参数共享化:提到将图因式化,那么每个因子函数的参数则需要进一步考虑。由于真实环境中的图与训练时的图往往不相同,只能保证图中所出现的物体和边的种类被完全考虑,因此因子函数的参数在同一类点/边中是共享一致的。将上文中的st-graph中nodes和edges的因子分类后得到下图这样的结果:
nodes的种类:human、object
edges的种类:human-human(self)、human-object、object-object(self)、object-object
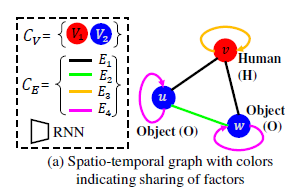
因子函数的相邻定义:在上文所建立的factor graph(二分图)中,如果两个因子函数的连接着同样一个node,那么就称这两个因子函数是相邻,这将决定接下来的RNNs间的连接情况。
S-RNN
S-RNN概述
S-RNN建立在Factor Graph上,实质上就是使用RNN神经序列模型充当具体的Factor Function,参考文献中在介绍S-RNN模型时有这么一段描述,我认为非常重要:
We derive our S-RNN architecture from the factor graph representation of the st-graph. The factors in the st-graph operate in a temporal manner, where at each time step the factors observe (node & edge) features and perform some computation on those features.
In S-RNN, we represent each factor with an RNN.We refer the RNNs obtained from the node factors as nodeRNNs and the RNNs obtained from the edge factors as edgeRNNs. The interactions represented by the st-graph are captured through connections between the nodeRNNs and the edgeRNNs.
这段话重点介绍了factor function在预测labels时实际行为和操作,以及如何使用RNN履行factors的功能。在使用RNN替代factor时,需要注意RNNs之间的连接关系由factors之间的连接关系决定,同时factors的参数共享规则对于RNNs的参数共享同样适用。
Factor Function到可传递的神经网络构建
在文章提出使用RNN之前,对于nodes和edges的factor function的描述是抽象的,也没有不同factors运算的层级关系,笔者没有发现如何具体地使用这些factor得出最终预测的nodes的labels。
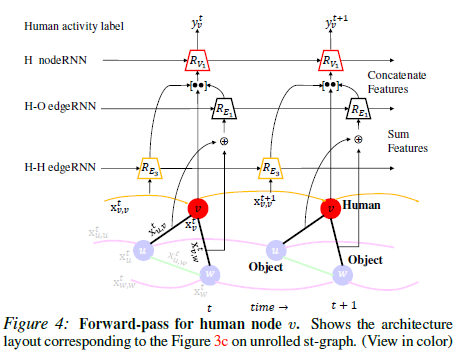
而在提出使用RNN充当factor function功能后,文章给出了预测labels的具体结构——二分图,左侧点是edgeRNNs,右侧点是nodeRNNs,图中所有的边均由左侧指向右侧,经右侧nodeRNNs计算后输出得到最终的labels,这样做的目的主要是使得RNNs组成的模型是一个前馈神经网络以便训练。

文中还特意针对Human可视化的训练过程,图中有以下特点,而这些特点也恰好是理解“Spatio-Temporal with Attention”模型的关键:
- edgeRNN和nodeRNN输入数据的组成部分。除了RNN上一步的Hidden States,nodeRNN输入还有edgeRNN输出和node的features;H-O edgeRNN需同时处理多条边输入(拼接、加和、平均等,视情况而定)。
- nodeRNN层次在edgeRNN之上。
Model 2 :Multi-Head Attention Mechanism
参考
- 原文 - Attention is All You Need.
- https://www.cnblogs.com/robert-dlut/p/8638283.html,更宏观和有深度观点
- https://www.jianshu.com/p/25fc600de9fb,细致地介绍文献的模型实现。
Multi-Head Attention是由谷歌科学家所提出的,其提出时的背景问题是机器翻译,但不同于流行的Seq2Seq模型,其编码器、解码器并不是由RNN所组成,取而代之的是用具有多头注意力机制的Transformer所组成。
1 注意力机制
大体来说,注意力模型的本质可被描述为从Query到(Value-Key)的映射,通过计算Query和Key之间的相似度关系(点积、拼接、感知机等),而后使用Softmax将相似度关系归一化为权重,最终对Value加权平均得到发送Query的主体对一系列(Value-Key)的关注度。其中,Query-Value-Key在实际应用中并不完全不同,甚至可能完全相同,具体稍后讨论。
在“Attention is All You Need”文章中,Attention机制的K-Q-V关系不相同,但是用于计算Q-K相似度的方式相同,为点积,具体网络模型如下:
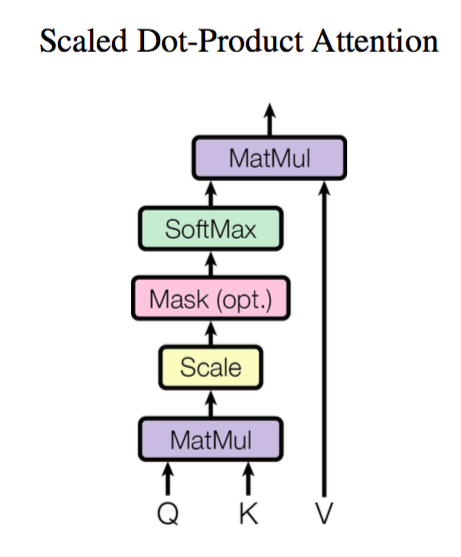
而Multi-Head Attention则是在Scaled Dot-Product Attention网络的基础上叠加而成,将K-Q-V用不同的矩阵线性映射h次,每组(K-Q-V)独立地通过SDPA注意力层,将每层的输出的矩阵进行拼接即得到输出。
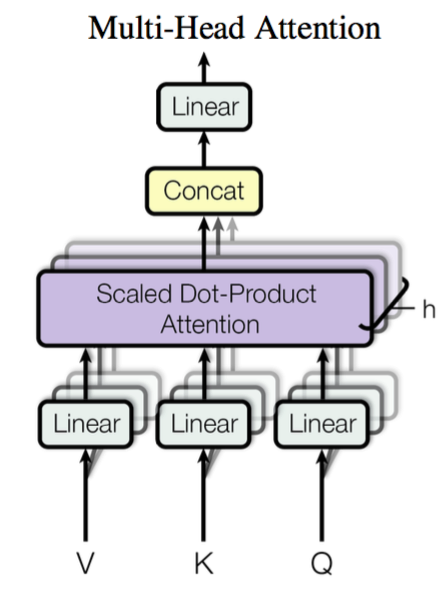
2 自注意力机制与注意力机制
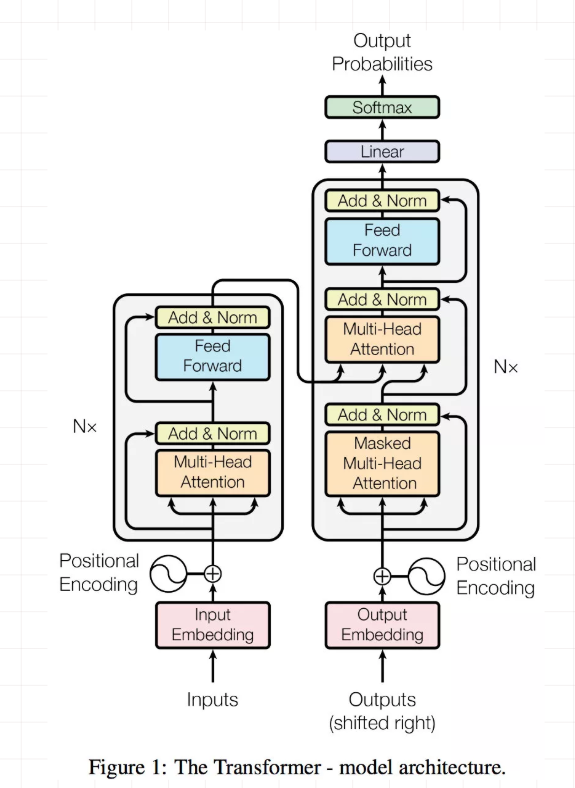
下图为文献构造模型的整体结构,左右两边分别为编码器和解码器,皆由多层结构重复堆叠而成,编码器与解码器之间的连接渠道为最后一个编码器的输出至每层解码器。在这里需要提醒的是,使用此网络实现文本翻译时与RNN结构就存在很大不同,其输入向量维数是有限的因而也限制了句子序列的长度。
单元有关模型其他具体细节在此不再赘述,具体讲一下Multi-Head Attention的不同使用场景:
- Self-Attetion(自注意力层):编码器和解码器中皆有\(K=Q=V\)的multi-head attention操作,目的是挖掘在输入的一组数据中挖掘各个数据之间的关系(以句子翻译为例,即单词之间的联系情况),因而所谓"自"注意力机制。
- 编码器与解码器之间的Attention:在这\(K = V\),来自于编码器最后一层的输出,而\(Q\)来自于编码器。
3 模型特点
- 不同于RNN,可并行计算(句子翻译任务与RNN模式有所不同,如有必要请阅读文献报告)。
- 可捕捉长距离依赖。
- 网络复杂型减小。
Model 3:Graph Attention Network
参考
- 原文 - Graph Attention Network
- https://www.jianshu.com/p/8078bf1711e7
- https://www.jiqizhixin.com/articles/2019-03-29-10
GAT称作图注意力网络,其在图结构上定义一个图卷积核,并使得图中一个结点更新时能够兼顾注意到相邻结点的值,并且使用了Multi-Head Attention(多头注意力)机制。
GAT所探讨的问题相较于SRNN更加细致,如果放在SRNN模型中,GAT就是探讨RNNs的input features如何产生的问题。
频谱型和非频谱型(了解)
卷积核用作处理图相关问题时,通过区别是否将卷积核直接定义在图上从而分为频谱型和非频谱型,频谱型例如将图进行拉普拉斯分解,并将卷积核定义在傅里叶域中;而非频谱型则直接定义在原图上,此类方法的挑战是如何对于有着不同邻居数目的点进行操作,同时还保持卷积核的参数共享特性。
GAT采用非频谱型卷积核。
图注意力机制
如上文所述,图注意力机制旨在更新某结点的值\(h_i\)时,兼顾相邻结点值对其的影响,下图展示了相邻结点\(2-6\)参与结点\(1\)的值更新,其本质是使用了\(\alpha_{1j}(1 <= j <=6)\)的注意力系数(权重系数)来求出加权平均,并采用multi-head attention机制平行独立地进行三次同样的操作(绿、蓝、紫三色),最终于形成\(h_1'\)时拼接或求均值。
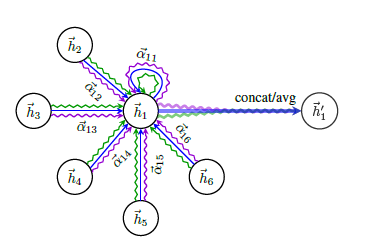
现在重点转移至如何计算出\(a_{ij}\),下图给出了详细步骤:映射 -> 注意力系数计算 -> LeakyRelu -> softmax
-
利用映射矩阵\(W\)将维度为\(F\)的\(h_i,h_j\)投射到更高维度\(F'\)上:
\[h_i' = Wh_i, h_j' = Wh_j, W \in \R^{F' \times F} \] -
使用注意力机制\(a\),将\(h_i',h_j'\)作为输入得到注意力系数,对于此处的\(a\)需要注意:
- 其为一个抽象概念,根据实际情况有多种计算方式,例如点乘。
- \(a\)的实现机制中若有参数,则参数应共享。
\[e_{ij} = a(h_i', h_j'), a : \R^{F'} \times \R^{F'} \to \R \] -
将注意力系数通过LeakyRelu:
\[a_{ij} = LeakyRelu(e_{ij}) \] -
固定\(j\),在算出所有的\(a_{ij}\)后,使用softmax归一化以方便比较,得到最终的\(a_{ij}\):
\[a_{ij} = softmax_j(e_{ij}) = {exp(e_{ij}) \over \Sigma_{k \in N_i} exp(e_{kj})} \]

图注意力机制有效性的一些看法:在有的文献阅读报告中,认为图注意力机制与图卷积的结合之所以在实现上取得良好结果,是因为注意力机制强化了图的结构性特点:愈加稀疏的图往往能够提供更丰富的信息,但对于根据输入数据而得来的图数据,无法控制图的稀疏密集程度,要达到将图稀疏化的效果,可以让结点学习究竟和哪些结点保持相联的关系,此为注意力机制。
其他资料
基于CNN的Seq2Seq模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号