mmap内存映射 页缓存 虚拟内存 swap buffer sendfile【重点】
1 mmap done
https://blog.csdn.net/QuillChen/article/details/120380507
第一种方式需要预先分配好物理内存,内核才能将页高速缓冲中的文件数据拷贝到用户进程指定的内存空间中。(DMA从磁盘-》内核,CPU负责内核-〉用户)
https://www.cnblogs.com/huxiao-tee/p/4660352.html
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝(dma从磁盘拷贝到内核空间,完了发起一次中断给CPU)
总结来说,常规文件操作为了提高读写效率和保护磁盘,使用了页缓存机制。这样造成读文件时需要先将文件页从磁盘拷贝到页缓存中,由于页缓存处在内核空间,不能被用户进程直接寻址,所以还需要将页缓存中数据页再次拷贝到内存对应的用户空间中。
使用mmap操作文件中,创建新的虚拟内存区域和建立文件磁盘地址和虚拟内存区域映射这两步,没有任何文件拷贝操作。而之后访问数据时发现内存中并无数据而发起的缺页异常过程,可以通过已经建立好的映射关系,只使用一次数据拷贝,就从磁盘中将数据传入内存的用户空间中,供进程使用。
常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程。说白了,mmap的关键点是实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程。因此mmap效率更高。
实现了用户空间和内核空间的高效交互方式。两空间的各自修改操作可以直接反映在映射的区域内,从而被对方空间及时捕捉。
可用于实现高效的大规模数据传输。内存空间不足,是制约大数据操作的一个方面,解决方案往往是借助硬盘空间协助操作,补充内存的不足。但是进一步会造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好的解决。换句话说,但凡是需要用磁盘空间代替内存的时候,mmap都可以发挥其功效。
使用mmap需要注意的一个关键点是,mmap映射区域大小必须是物理页大小(page_size)的整倍数(32位系统中通常是4k字节)。原因是,内存的最小粒度是页,而进程虚拟地址空间和内存的映射也是以页为单位。为了匹配内存的操作,mmap从磁盘到虚拟地址空间的映射也必须是页。
映射建立之后,即使文件关闭,映射依然存在。因为映射的是磁盘的地址,不是文件本身,和文件句柄(文件描述符)无关。
RocketMQ主要通过MappedByteBuffer对文件进行读写操作。其中,利用了NIO中的FileChannel模型将磁盘上的物理文件直接映射到用户态的内存地址中(这种Mmap的方式减少了传统IO将磁盘文件数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销),将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率(正因为需要使用内存映射机制,故RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存)。
2 页缓存 done
它是操作系统中使用的一种缓存机制,用于加速对磁盘数据的访问。当数据被访问并缓存后,后续对该数据的访问可以直接从缓存中获取,而不必再次访问磁盘。
https://blog.csdn.net/qq_25518029/article/details/119927007
Buffers 是内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers 值。
Cache 是内核页缓存和 Slab 用到的内存,对应的是 /proc/meminfo 中的 Cached 与 SReclaimable 之和。
百度百科
page cache的大小为一页,通常为4K。在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。
3 swap done
Swap(交换空间)是实现虚拟内存(Virtual Memory)的核心技术之一,但二者并非等同概念—— 虚拟内存是一套 “内存管理思想”,而 Swap 是这套思想在硬件 / 系统层面的 “具体实现组件”,二者是 “战略” 与 “战术” 的关系。
虚拟内存是操作系统(OS)为解决 “物理内存不足” 而设计的内存管理机制,核心思想是:
“把程序需要的内存(虚拟地址空间)拆分成小块,只把当前正在使用的部分加载到物理内存(内存条)中,暂时用不到的部分则存到速度较慢但容量更大的磁盘上”。
Swap 不是虚拟内存,而是虚拟内存机制的 “核心实现载体”—— 没有 Swap,虚拟内存的 “内存换入换出” 逻辑就无法落地;但虚拟内存的范畴远大于 Swap(还包括地址映射、内存分页等技术)。
swapin性能差
swap和mmap都是虚拟内存发生的场景,但前者侧重容量,后者侧重性能
4 sendfile会经过页缓存吗?停电有没有影响?done
1)发送-DMA从网卡拷贝到内核(页缓存),2)调用sendfile由磁盘DMA从内核拷贝到磁盘,全程无CPU参与
那么kafka的ack什么时候给的?结论:1)后面给的,不过发送端是主从强一致性ack,主从所有节点停电而还没来得及将页缓存数据刷到磁盘,则丢
https://blog.csdn.net/Trouvailless/article/details/124203320
1)首先我们要知道一点就是 Producer 端是直接与 Broker 中的 Leader Partition 交互的,所以在 Producer 端初始化中就需要通过 Partitioner 分区器从 Kafka 集群中获取到相关 Topic 对应的 Leader Partition 的元数据 。
2)待获取到 Leader Partition 的元数据后直接将消息发送过去。
3)Kafka Broker 对应的 Leader Partition 收到消息会先写入 Page Cache,定时刷盘进行持久化(顺序写入磁盘)。
4) Follower Partition 拉取 Leader Partition 的消息并保持同 Leader Partition 数据一致,待消息拉取完毕后需要给 Leader Partition 回复 ACK 确认消息。
5)待 Kafka Leader 与 Follower Partition 同步完数据并收到所有 ISR 中的 Replica 副本的 ACK 后,Leader Partition 会给 Producer 回复 ACK 确认消息。
- 由于 Kafka 中并没有提供 「 同步刷盘 」 的方式,所以说从单个 Broker 来看还是很有可能丢失数据的。
- kafka 通过 「 多 Partition (分区)多 Replica(副本)机制 」 已经可以最大限度的保证数据不丢失
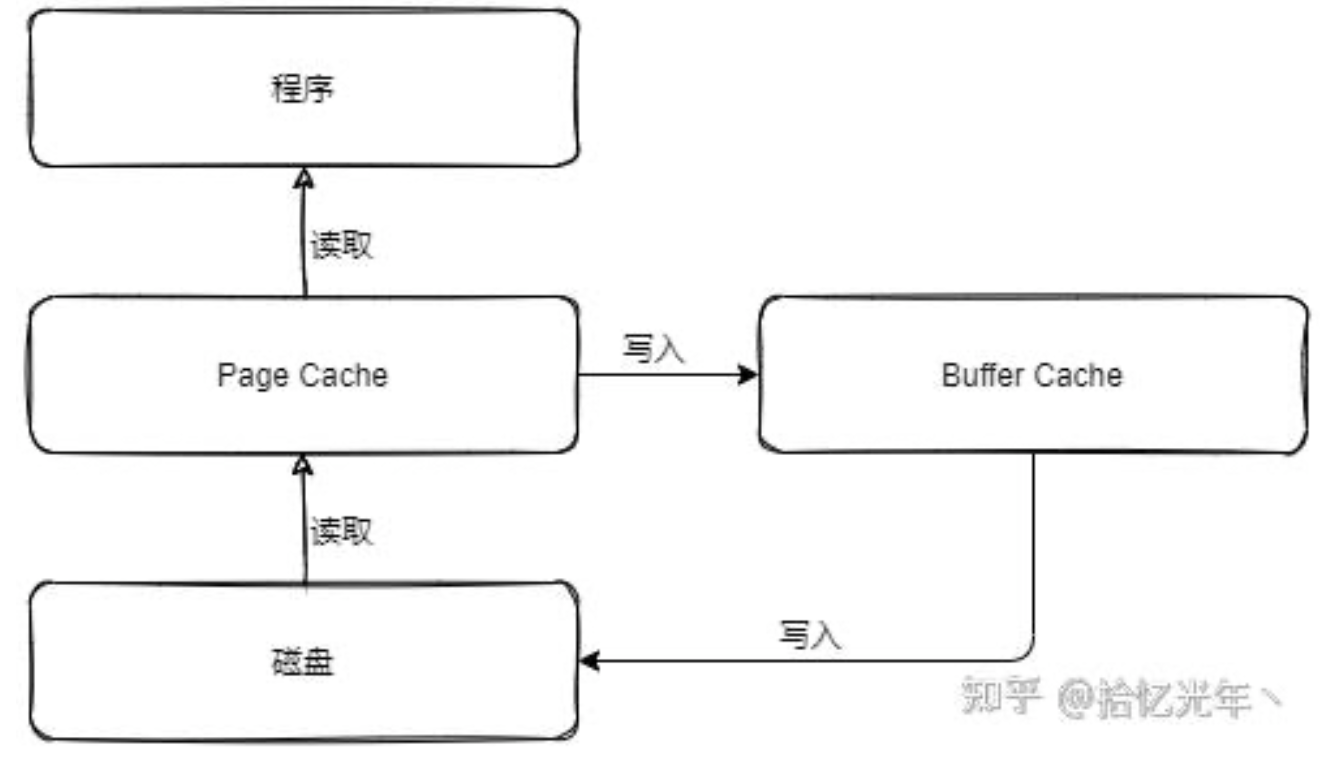
5 buffer cache和page cache
https://zhuanlan.zhihu.com/p/405929922
当Page Cache中的数据需要刷新时,Page Cache中的数据会交给Buffer Cache,而Buffer Cache中的数据会定时刷新到磁盘中,也可通过sync命令将缓冲区里的数据写入磁盘。如果突然断电,Buffer Cache没来得及写入到磁盘中,那么就会发生数据丢失。
cat /proc/meminfo | grep Dirty - 脏页

 浙公网安备 33010602011771号
浙公网安备 33010602011771号