

mmap和sendfile
https://cloud.tencent.com/developer/article/1677841
假设需求是将一个磁盘文件发布到网络上。
1 总共需要2次CPU拷贝、2次DMA拷贝,4次上下文切换,其中read和write各占一半;
- 程序调用系统方法mmap(图上有误),使用DMA的方式将磁盘数据读取到内核缓冲区,然后通过内存映射的方式,将用户缓冲区映射到内核读缓冲区的内存地址,此处不再需要将内核空间的数据拷贝到用户空间;
- 依然调用write方法将用户空间的数据拷贝到socket buffer,同时使用DMA将数据拷贝到硬件;
2 mmap相比传统I/O减少了一次CPU拷贝,总共需要2次DMA拷贝,1次CPU拷贝,4次上下文切换。
- 程序调用sendfile方法(上图有误),使用DMA的方式将磁盘数据读取到内核缓冲区;
- CPU拷贝数据到socket buffer,然后使用DMA将数据拷贝到硬件。
3 sendfile相比mmap少了1次上下文切换系统调用,总共需要2次DMA拷贝,1次CPU拷贝,2次上下文切换。但是缺点也是很明显的,由于完全没有经过用户态,sendfile只能简单的传送数据而不能对其进行修改;
4 Linux2.4版本sendFile做了一些优化,避免了从内核缓冲区拷贝到socket buffer的操作,直接拷贝到协议栈,从而再一次减少数据拷贝。
总共需要2次DMA拷贝,近0次CPU拷贝,2次上下文切换。
mmap和sendFile的区别
- mmap适合小数据量读写,sendFile适合大文件传输;
- mmap需要4次上下文切换,3次数据拷贝;sendfile需要2次上下文切换,近2次数据拷贝;
- 使用mmap的时候,可以对数据做修改操作,而sendfile不行;
https://blog.csdn.net/m0_56116754/article/details/132251268
在没有DMA技术之前的I/O过程是这样的
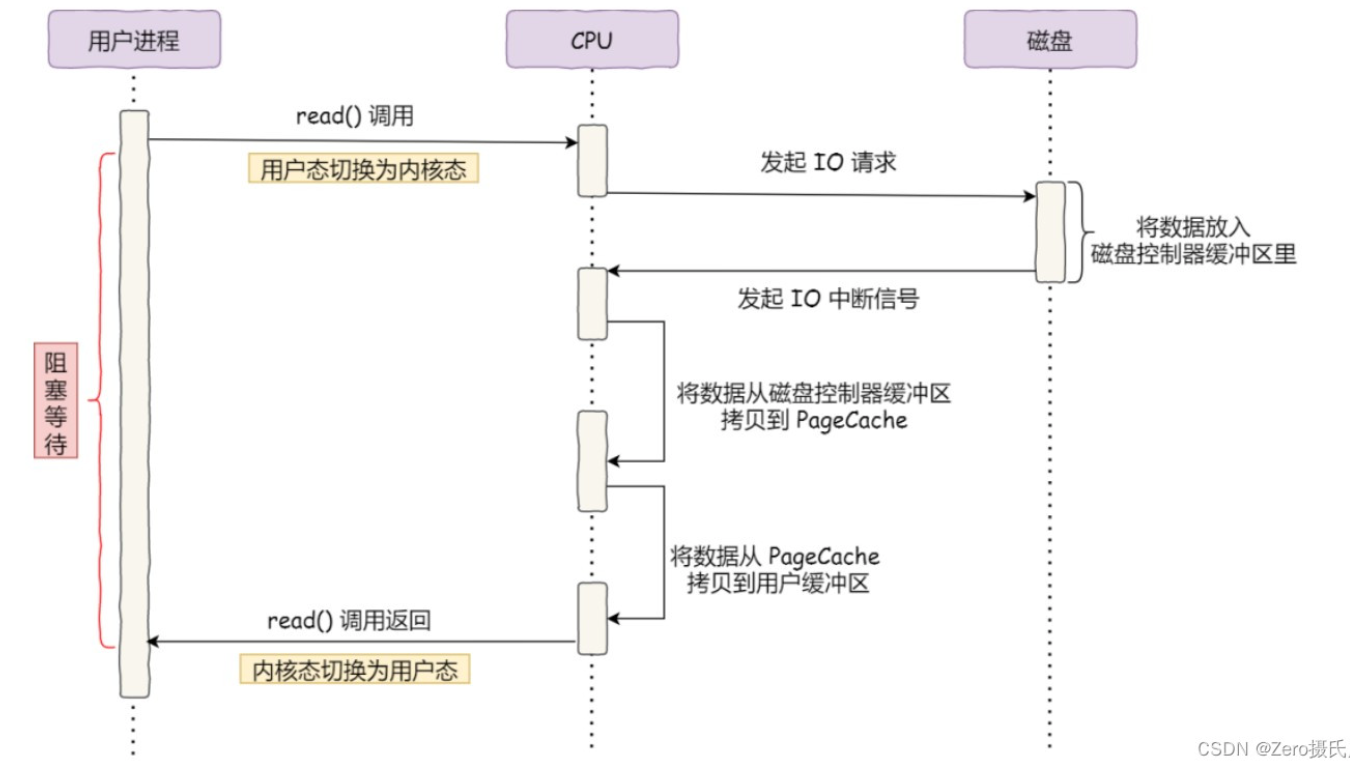
DMA:

- 当 DMA 读取了⾜够多的数据,就会发送中断信号给 CPU;
- CPU 收到 DMA 的信号,知道数据已经准备好,于是将数据从内核拷⻉到⽤户空间 ,系统调⽤返回
传统的文件传输

实现零拷贝技术的方式通常有2种:
- mmap+write
- sendfile
read()系统调用的过程,会将内核缓冲区的数据拷贝到用户的缓冲区,为了减少这一步开销,我们可以用mmap()替换read()系统调用函数。、
mmap()系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样操作系统内核与用户空间就不需要再进行任何的数据拷贝操作
这样做会将内核的读缓冲区拷贝到用户缓冲区,再从用户缓冲区拷贝到socket的缓冲区 这两次拷贝变成内核缓冲区拷贝到socket缓冲区 这一次拷贝
但这并不是理想的零拷贝,因为仍然需要通过CPU把内核缓冲区的数据拷贝到socket缓冲区中,而且仍然需要4次上下文切换 (mmap write各两次)
内核版本2.1中,提供了一个专门发送文件的系统调用函数sendfile()。
- ⾸先,它可以替代前⾯的 read() 和 write() 这两个系统调⽤,这样就可以减少⼀次系统调⽤ ,也就减少了 2 次上下⽂切换的开销。
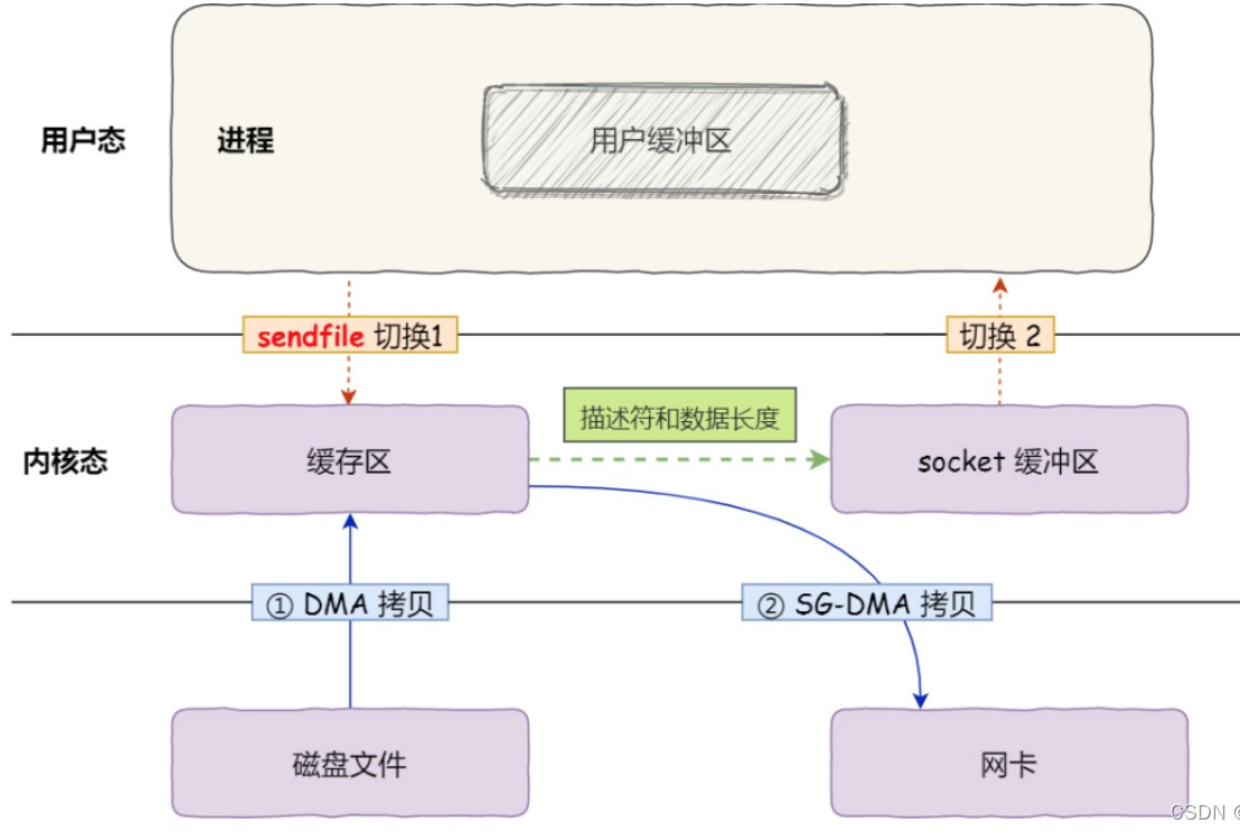
从 Linux 内核 2.4 版本开始起,对于⽀持⽹卡⽀持 SG-DMA 技术的情况下, sendfile() 系统,调⽤的过程发⽣了点变化,具体过程如下:
第⼀步,通过 DMA 将磁盘上的数据拷⻉到内核缓冲区⾥;(DMA拷贝)
第⼆步,缓冲区描述符和数据⻓度传到 socket 缓冲区,这样⽹卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷⻉到⽹卡的缓冲区⾥ ,此过程不需要将数据从操作系统内核缓冲区拷⻉到socket 缓冲区中,这样就减少了⼀次数据拷⻉;(SG-DMA拷贝)
这个过程之中,只进行了一次系统调用(sendfile(),进⾏了 2 次数据拷⻉(磁盘到内核,内核到网卡)
https://blog.51cto.com/u_16213616/12328798
当有Consumer订阅了相应的Topic消息,数据需要从磁盘中读取然后将数据写回到套接字中(Socket)。此动作看似只需较少的 CPU 活动,但它的效率非常低:首先内核读出全盘数据,然后将数据跨越内核用户推到应用程序,然后应用程序再次跨越内核用户将数据推回,写出到套接字。应用程序实际上在这里担当了一个不怎么高效的中介角色,将磁盘文件的数据转入套接字。
数据每遍历用户内核一次,就要被拷贝一次,这会消耗 CPU 周期和内存带宽。
Java 类库通过 java.nio.channels.FileChannel 中的 transferTo() 方法来在 Linux 和 UNIX 系统上支持零拷贝。可以使用 transferTo() 方法直接将字节从它被调用的通道上传输到另外一个可写字节通道上,数据无需流经应用程序。
transferTo() 方法引发 DMA 引擎将文件内容拷贝到一个读取缓冲区。然后由内核将数据拷贝到与输出套接字相关联的内核缓冲区。
数据的第三次复制发生在 DMA 引擎将数据从内核套接字缓冲区传到协议引擎时。
改进的地方:我们将上下文切换的次数从四次减少到了两次,将数据复制的次数从四次减少到了三次(其中只有一次涉及到了 CPU)。但是这个代码尚未达到我们的零拷贝要求。如果底层网络接口卡支持收集操作 的话,那么我们就可以进一步减少内核的数据复制。在 Linux 内核 2.4 及后期版本中,套接字缓冲区描述符就做了相应调整,以满足该需求。这种方法不仅可以减少多个上下文切换,还可以消除需要涉及 CPU 的重复的数据拷贝。对于用户方面,用法还是一样的,但是内部操作已经发生了改变:
transferTo() 方法引发 DMA 引擎将文件内容拷贝到内核缓冲区。
数据未被拷贝到套接字缓冲区。取而代之的是,只有包含关于数据的位置和长度的信息的描述符被追加到了套接字缓冲区。DMA 引擎直接把数据从内核缓冲区传输到协议引擎,从而消除了剩下的最后一次 CPU 拷贝。
https://www.cnblogs.com/xiaohaigegede/p/17726369.html

nginx作为静态服务器时,采用sendfile()方式可以减少上下文切换和系统拷贝从而提高系统性能;但是nginx作为反向代理服务器时,就没有效果了,因为sendfile()的作用是发送文件,也就是接收数据的一段是文件句柄,发送数据的那一端是socket。而在做反向代理服务器的时候,两端都是socket,此时无法使用sendfile(),也就不存在性能提升这一说了。
mmap 用于文件共享,很少用于socket操作,sendfile用于发送文件.
mmap 适合小数据量读写,sendFile 适合大文件传输。
mmap 每次读入都是1页即4k,所以少于4k会造成大量内存碎片. 但是通过read,write也是这样的。
优点:即使频繁调用,使用小文件块传输,效率也很高
缺点:不能很好的利用DMA方式,会比sendfile多消耗CPU资源,内存安全性控制复杂,需要避免JVM Crash问题
rocketMQ 在消费消息时,使用了 mmap,因为小块数据传输比sendFile好。kafka 使用了 sendFile。
https://juejin.cn/post/7292657229298221056
Linux中的零拷贝技术
- mmap+write
- sendfile


首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。
紧接着,如果网卡还支持SG-DMA的技术,则不仅会放弃使用CPU进行拷贝而且可以直接从内存缓冲区直接拷贝至网卡当中。在网络这一方面,又减少了一次拷贝,总共只需要两次拷贝、两次用户态内核态切换,性能又一步提升!当然,这项技术的前提都需要Linux内核2.1 2.4以上的版本!
MMap 的缺点:
- 内存消耗: MMap 可能会占用大量内存,特别是在处理大文件时。这可能导致系统内存资源受限。
- 适用范围有限: MMap 更适用于随机访问文件,不如 SendFile 适用于顺序读取大型文件。
为什么RocketMQ选择mmap?
- 跨平台性: MMap 提供了一种跨平台的文件映射机制,可以在不同操作系统上使用相同的代码实现文件映射,而不需要根据操作系统进行不同的优化。这有助于确保 RocketMQ 在多种操作系统上的兼容性。
为什么Kafka选择SendFile?
- 性能和效率: SendFile 提供了高性能的文件传输机制,特别适合大文件的顺序传输。它可以通过将文件内容直接传输到网络套接字来实现高效的消息传输,而不需要将整个文件加载到内存中。
https://zhuanlan.zhihu.com/p/713261131?share_code=e5t7NNPttEgR&utm_psn=1923175763257041908
Kafka 的性能比 RocketMQ 快 50%左右。然而,RocketMQ 依然能每秒处理 10 万条消息,这表明它在性能上依然非常强大。
RocketMQ 的一些功能需要了解具体这个消息内容,方便二次投递等,比如将消费失败的消息重新投递到死信队列中。如果 RocketMQ 使用 sendfile,那根本没机会获取到消息内容长什么样子,也就没办法实现一些好用的功能了。而 Kafka 却没有这些功能特性,追求极致性能,正好可以使用 sendfile。
2. 结构差异
- Kafka在存储结构上采用分区机制(Partition),每个Topic可拆分为多个分区,每个分区对应一个独立的日志文件,写入时按分区路由(如轮询、hash key、业务自定义分区键)决定写入哪个分区。由于各分区独立,Kafka支持多线程并行写入,底层顺序追加,避免磁盘随机IO。Broker内部每个分区由单独线程负责写盘和刷盘,配合操作系统页缓存与零拷贝机制,极大提升写入吞吐。
- RocketMQ则采用全局单一CommitLog文件,所有Topic和Queue的消息统一串行写入,通过内存队列映射逻辑队列位置,写入需加锁或通过GroupCommit批量控制,写入并发度远低于Kafka。Kafka用分区换并发,RocketMQ用统一日志做顺序一致性,设计取舍不同。
https://blog.csdn.net/weixin_44519337/article/details/145556968
1 io
2 rocket队列只存offset
3 kafka多topic随机写multi segment
rocketmq写一个文件,多topic仍然顺序写
4 rocketmq可过滤消费
5 事务,两阶段提交
6 延时消费
8 死信队列
9 nameserver vs zk
10 kafka异步刷盘只操作页缓存就返回(可设置刷盘频率walkaround),rocketmq可直接设置同步刷盘
11 运维角度,kafka要先安装zk,最新版不用
zookeeper在Kafka架构中会和broker通信,维护Kafka信息,一个新的broker加入后,其他broker会立马感知它的加入。
分布式协调服务
zookeeper不仅可用于服务注册和发现,还可以用于分布式锁管理,配置管理等场景。
使用nameServer,用更轻量的方式管理消息队列的集群信息。
后来Kafka也发现了zookeeper过重的问题,从2.8.0版本移除zookeeper,通过broker之间加入一致性算法Raft实现同样的效果。
kafka的partition中会存入完整消息,但是RocketMQ的queue中只存入一些简要信息,比如消息偏移offset,而消息的完整信息放到commitLog里
在RocketMQ中,消费者需要先从queue中读到offset的值,再跑到commitLog上将完整的数据读取出来,也就是读取了两次
Kafka下有partition,每个partition是由多个segment组成的,生产者发送数据也就是在往segment中写入数据,就是往磁盘做写入,磁盘的顺序写入会比随机写入快很多,性能差距很大,可高达几十倍。
为了提升性能,Kafka对于每个segment的写入也都是顺序写。
但是当topic变多了,Kafka下的partition也会增多,对应的segment文件也会变多,同时写多个topic下的partition就相当于写多个文件,不同的topic下的文件存放在磁盘的不同地方,这样的话即使segment内部是顺序写,但是针对于不同topic下的文件是随机写。
为了缓解同时写多个文件带来的随机写的问题,RocketMQ将单个broker地下的多个topic数据,全部写到“一个”逻辑文件CommitLog上,这就消除了写多个文件的随机写问题,将所有写操作变成了顺序写,提升了RocketMQ在多topic场景下的写性能。
kafka需要消费topic为用户数据的所有消息,再将vip6的用户过滤出来。
RocketMQ支持给用户数据打tag,消费者根据tag过滤所需要的数据,消费者就可以只消费这部分数据,就剩下了消费者过滤数据的资源消耗。
Kafka支持事务,保证发送的一批消息同时成功或者同时失败,
但是我们写业务代码的时候,希望执行一些自定义逻辑和生产者发送消息这两件事要么同时成功要么同时失败,这是RocketMQ支持的事务能力
当我们希望消息被投递出去之后,消费者不是立马消费而是过一段时间再去消费,也就是所谓的延时消息,这就要用到RocketMQ的延时队列,而Kafka就需要程序员自己实现类似的功能。
消费消息是有可能失败的,失败后一般可以设置重试,如果多次重试失败,RocketMQ会将消息放在一个专门的队列中,方便我们单独做处理,这种专门存放失败消息的队列就是死信队列,kafka不支持,
https://blog.csdn.net/winterPassing/article/details/148279762

kafka
- 组件:Producer、Broker、Consumer Group、ZooKeeper。
- 分区(Partition)为并行单位,同一分区内消息严格有序。
rocket
- 组件:Producer、Broker、Consumer、NameServer。
- 消息存储采用 CommitLog + ConsumeQueue 分离结构,提升写入性能(避免多topic随机写iO)。
1. Kafka 适用场景
日志采集与聚合:如 Flink、ELK 集成。
流式计算:配合 Kafka Streams、Spark Streaming 实时处理数据。
大数据管道:作为数据源或中间存储,对接 Hadoop、数据仓库等。
2. RocketMQ 适用场景
金融交易:需严格事务和可靠性的支付、订单系统(同步刷盘/事务)。
异步解耦:电商系统削峰填谷,保障核心流程稳定性。
定时任务:延迟消息触发活动开始、订单超时关闭等(延时队列)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号