
STM32深度学习实战
STM32深度学习实战
1. 前言
本文主要记录基于 tensorflow 的简单模型在 stm32 上运行测试的调试记录,开发人员应对深度学习基础理论和 tensorflow 框架基础操作有一定了解,对深度学习在微控制器上的实现评估提供一定的参考方向。
本文实战基于温控主控板硬件及其基础工程进行测试。
总体思想:
- 在PC的 tensorflow 虚拟环境中进行模型的装配、训练、保存及测试;
- 通过 X-CUBE-AI 拓展软件包从预先训练的神经网络模型生成 STM32 优化库;
- 编写测试程序验证神经网络模型。
2. 开发环境准备
-
tensorflow 开发环境已按照《Win10环境安装Anaconda(3-2021.05)+Tensorflow(2.5)》进行部署完成;
-
STM32CubeMX 6.0.1(安装 X-CUBE-AI 拓展软件包);
-
温控主控板精简工程(其他项目操作类似);
-
模型开发过程中需要的 python 插件(autopep8、flake8、jupyter、notebook、Keras、matplotlib、numpy、pandas),反正就是缺什么安装什么;
X-CUBE-AI 简介
X-CUBE-AI 是 STM32Cube 扩展包的一部分 STM32Cube.AI,通过自动转换预先训练的神经网络并将生成的优化库集成到用户的项目中,扩展 STM32CubeMX 功能。
- 从预先训练的神经网络模型生成 STM32 优化库;
- 本地支持各种深度学习框架,如 Keras 和 TensorFlow™ 精简版,以及支持所有可以导出到 ONNX 标准格式的框架,如 PyTorch™、微软认知工具包、MATLAB 等®®;
- 支持 Keras 网络和 TensorFlow 的 8 位量化™精简量化网络;
- 允许使用较大的网络,将参数(权重矩阵)存储在外部闪存中,激活缓冲运行在外部 RAM 中;
- 通过 STM32Cube 集成,可轻松跨不同 STM32 微控制器系列;
- 使用 TensorFlow ™ 精简神经网络,使用 STM32Cube.AI 运行环境 或 用于微控制器的 TensorFlow™ Lite 原生运行环境;
- 免费、用户友好的许可证条款
3. 模型创建
本文以最简单的电压等级模型为例。
3.1 电压等级模型
新建模型训练文件 level_check.py 训练 epochs 20000次
# level_check.py
'''
电源等级检测测试
训练模型阈值
一级 -> v>=8.0
二级 -> 7.8<=v<8.0
三级 -> v<7.8
输入层 -> 隐藏层 -> 输出层
'''
# 导入工具包
import os
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import (Sequential, datasets, layers, losses, metrics, optimizers)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
print(tf.__version__)
# %% 读取数据
data = pd.read_csv('data/voltage.csv', sep=',', header=None)
voltage = data.iloc[:, 0] # 取第一列所有数据
level = data.iloc[:, 1:]
level.astype(int)
# print(voltage)
# print(level)
# %% 建立模型
'''
model = Sequential([layers.Dense(20, activation='relu'),
layers.Dense(10, activation='relu'),
layers.Dense(3, activation='softmax')])
model.build(input_shape=(4, 1))
model.summary()
'''
# '''
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(units=20, activation='relu', input_shape=(1,)))
model.add(tf.keras.layers.Dense(units=10, activation='relu'))
model.add(tf.keras.layers.Dense(units=3, activation='softmax'))
model.summary()
# '''
# %%
model.compile(optimizer=optimizers.Adam(learning_rate=0.001),
loss=losses.categorical_crossentropy,
metrics=[metrics.mse])
history = model.fit(x=voltage, y=level, epochs=20000)
print(model.evaluate(voltage, level))
# 保存模型
model.save('level_check.h5')
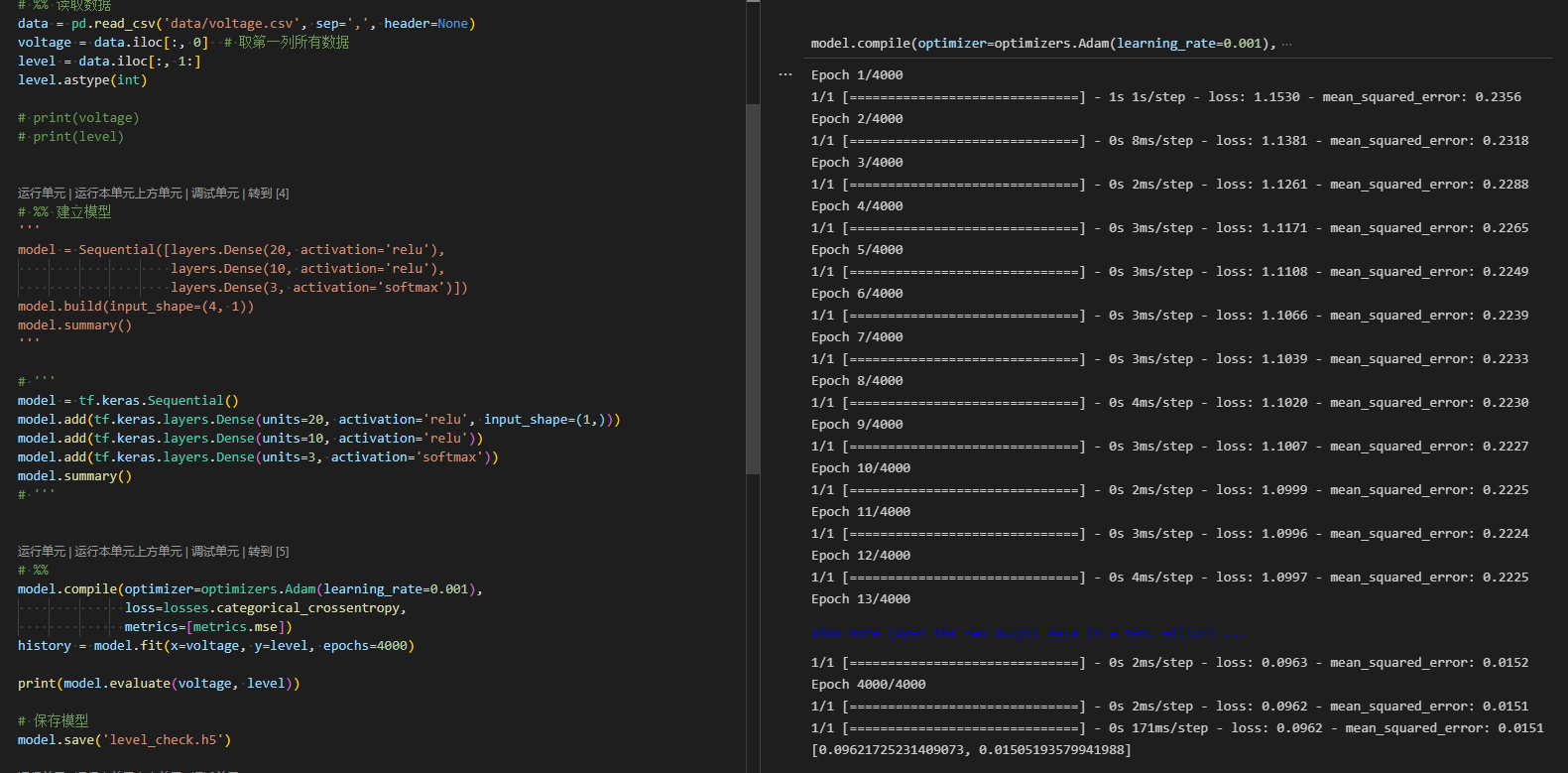
运行如下图:
训练数据 voltage.csv
7.61,0,0,1
7.62,0,0,1
7.63,0,0,1
7.64,0,0,1
7.65,0,0,1
7.66,0,0,1
7.75,0,0,1
7.78,0,0,1
7.71,0,0,1
7.72,0,0,1
7.8,0,1,0
7.83,0,1,0
7.92,0,1,0
7.85,0,1,0
7.81,0,1,0
7.81,0,1,0
7.84,0,1,0
7.89,0,1,0
7.98,0,1,0
7.88,0,1,0
8.02,1,0,0
8.12,1,0,0
8.05,1,0,0
8.15,1,0,0
8.11,1,0,0
8.01,1,0,0
8.22,1,0,0
8.12,1,0,0
8.14,1,0,0
8.07,1,0,0
模型的载入与测试,并且将模型转换为TF lite格式(ps:如果直接使用.h5文件也是可以的,在CubeMX里输入模型类别选Keras,不知什么原因模型转换不成功,使用 .h5模型即可),代码如下:
# 导入工具包
import sys, os
import datetime
import time
import numpy as np
import tensorflow as tf
# 输出函数 输出更加直观
def level_output(level):
for i in range(level.shape[1]):
if level[0, i] == 1.0:
return i+1
# 测试电压
test_v = 7.78
t1 = time.time()
# %%导入模型计算
load_model = tf.keras.models.load_model('level_check.h5')
out = load_model.predict([test_v])
print(out)
cal_level = np.around(out).astype(int)
print(cal_level)
t2 = time.time()
# %%输出能源等级
level = level_output(cal_level)
print(level)
print((int(t2*1000)-int(t1*1000)))
# %% 转换模型为tf lite格式 不量化
# converter = tf.lite.TFLiteConverter.from_keras_model(load_model)
# tflite_model = converter.convert()
# open("level_check.tflite", "wb").write(tflite_model) # 保存到磁盘
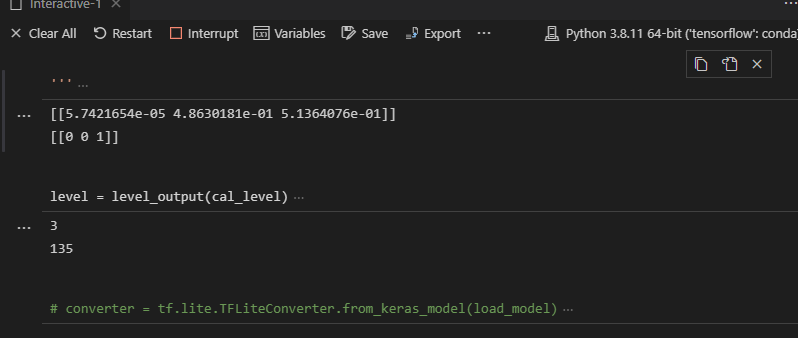
运行如下图:
4. stm32深度学习
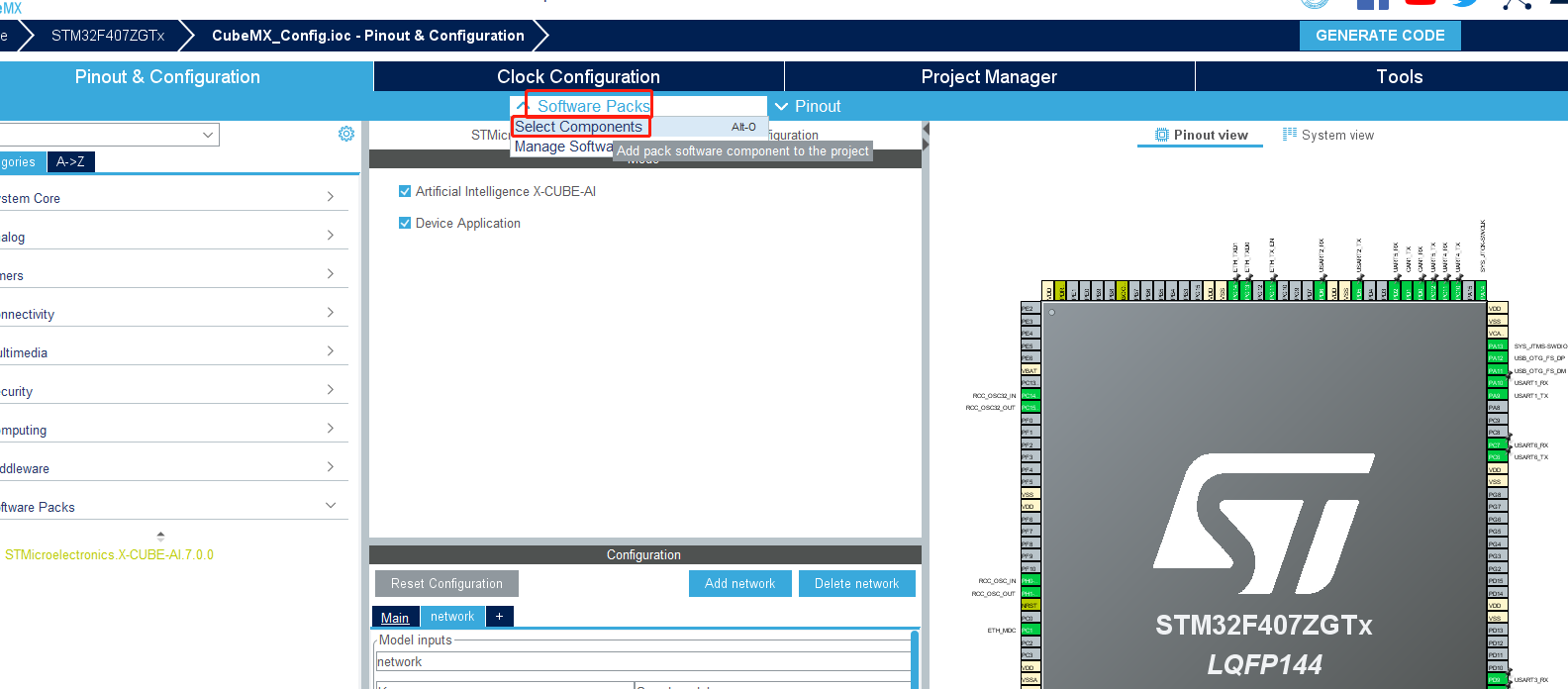
基于温控主控板精简工程,打开 CubeMX_Config.ioc 工程,添加 X-CUBE-AI 支持;
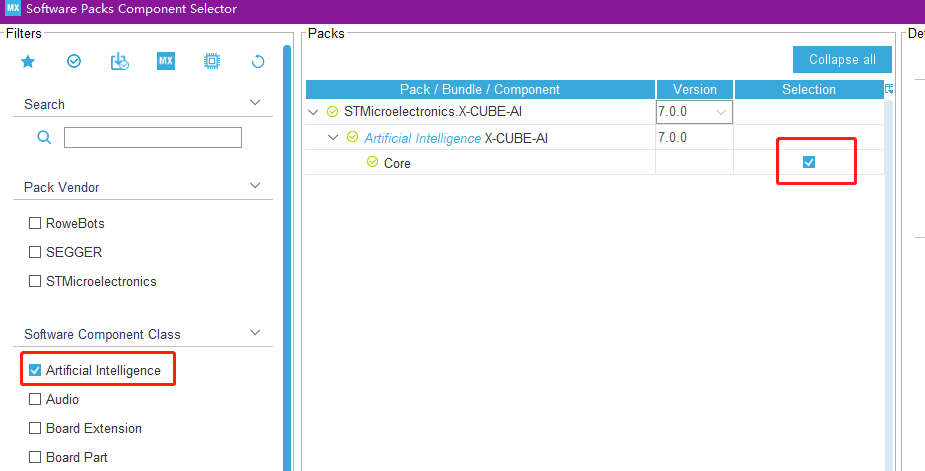
- 添加 X-CUBE-AI 拓展包
2. 添加模型,点击 Analyze 进行分析,会计算出模型的复杂度及其所需资源 FLASH + RAM。

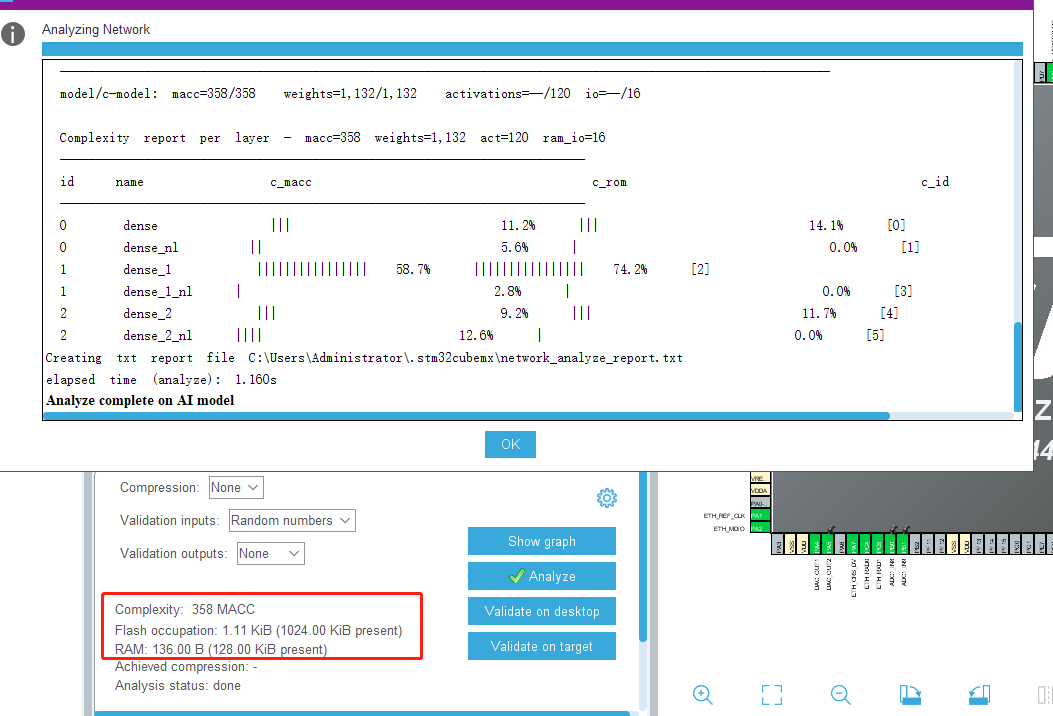
-
生成所需代码,并移植到工程中
-
移植测试
-
复制AI库 board\CubeMX_Config\Middlewares\ST\AI 到 board\CubeAI,并添加如下 SConscript
import os, sys import rtconfig from building import * cwd = GetCurrentDir() CPPPATH = [cwd + '/Inc'] LIBPATH = [cwd + '/Lib'] lib_file_path = os.listdir(LIBPATH[0]) lib_files = list() for i in range(len(lib_file_path)): stem = os.path.splitext(lib_file_path[i])[0] lib_files.append(stem) # EXEC_PATH is the compiler execute path, for example, CodeSourcery, Keil MDK, IAR for item in lib_files: if "GCC" in item and rtconfig.CROSS_TOOL == 'gcc': LIBS = [item[3:]] elif "Keil" in item and rtconfig.CROSS_TOOL == 'keil': LIBS = [item] elif "IAR" in item and rtconfig.CROSS_TOOL == 'iar': LIBS = [item] src = [] group = DefineGroup('CubeAI', src, depend = [''], CPPPATH = CPPPATH, LIBS = LIBS, LIBPATH = LIBPATH) Return('group') -
提取生成的 board\CubeMX_Config\Src 和 Inc 目录下的 模型C代码到应用
network_config.h
network.h
network.c
network_data.h
network_data.c添加 app_ai.c
#include <rtthread.h> #include <stdlib.h> #include <string.h> #include <math.h> #include "network.h" #include "network_data.h" #define DBG_SECTION_NAME "AI" #define DBG_LEVEL DBG_LOG #include <rtdbg.h> static ai_handle network = AI_HANDLE_NULL; static ai_network_report network_info; AI_ALIGNED(4) static ai_u8 activations[AI_NETWORK_DATA_ACTIVATIONS_SIZE]; #if !defined(AI_NETWORK_INPUTS_IN_ACTIVATIONS) AI_ALIGNED(4) static ai_u8 in_data_s[AI_NETWORK_IN_1_SIZE_BYTES]; #endif #if !defined(AI_NETWORK_OUTPUTS_IN_ACTIVATIONS) AI_ALIGNED(4) static ai_u8 out_data_s[AI_NETWORK_OUT_1_SIZE_BYTES]; #endif static void ai_log_err(const ai_error err, const char *fct) { if (fct) LOG_RAW("TEMPLATE - Error (%s) - type=0x%02x code=0x%02x\r\n", fct, err.type, err.code); else LOG_RAW("TEMPLATE - Error - type=0x%02x code=0x%02x\r\n", err.type, err.code); } static int ai_boostrap(ai_handle w_addr, ai_handle act_addr) { ai_error err; /* 1 - Create an instance of the model */ err = ai_network_create(&network, AI_NETWORK_DATA_CONFIG); if (err.type != AI_ERROR_NONE) { ai_log_err(err, "ai_network_create"); return -1; } /* 2 - Initialize the instance */ const ai_network_params params = AI_NETWORK_PARAMS_INIT( AI_NETWORK_DATA_WEIGHTS(w_addr), AI_NETWORK_DATA_ACTIVATIONS(act_addr)); if (!ai_network_init(network, ¶ms)) { err = ai_network_get_error(network); ai_log_err(err, "ai_network_init"); return -1; } /* 3 - Retrieve the network info of the created instance */ if (!ai_network_get_info(network, &network_info)) { err = ai_network_get_error(network); ai_log_err(err, "ai_network_get_error"); ai_network_destroy(network); network = AI_HANDLE_NULL; return -3; } return 0; } static int ai_run(void *data_in, void *data_out) { ai_i32 batch; ai_buffer *ai_input = network_info.inputs; ai_buffer *ai_output = network_info.outputs; ai_input[0].data = AI_HANDLE_PTR(data_in); ai_output[0].data = AI_HANDLE_PTR(data_out); batch = ai_network_run(network, ai_input, ai_output); if (batch != 1) { ai_log_err(ai_network_get_error(network), "ai_network_run"); return -1; } return 0; } #include "stm32f4xx_hal.h" void MX_X_CUBE_AI_Init(void) { LOG_RAW("\r\nTEMPLATE - initialization\r\n"); CRC_HandleTypeDef hcrc; hcrc.Instance = CRC; HAL_CRC_Init(&hcrc); ai_boostrap(ai_network_data_weights_get(), activations); } INIT_APP_EXPORT(MX_X_CUBE_AI_Init); /* 自定义网络查询及配置命令行接口 */ static void ai_test(int argc, char *argv[]) { if (argc != 2) { LOG_RAW("use ai <float>\r\n"); return; } float test_data = atof(argv[1]); if (network == AI_HANDLE_NULL) { ai_error err = {AI_ERROR_INVALID_HANDLE, AI_ERROR_CODE_NETWORK}; ai_log_err(err, "network not init ok"); return; } if ((network_info.n_inputs != 1) || (network_info.n_outputs != 1)) { ai_error err = {AI_ERROR_INVALID_PARAM, AI_ERROR_CODE_OUT_OF_RANGE}; ai_log_err(err, "template code should be updated\r\n to support a model with multiple IO"); return; } int ret = ai_run(&test_data, out_data_s); LOG_RAW("input data %.2f\r\n", test_data); LOG_RAW("output data [%.2f %.2f %.2f]\r\n", *((float *)&out_data_s[0]), *((float *)&out_data_s[4]), *((float *)&out_data_s[8])); LOG_RAW("output data [%d %d %d]\r\n", (uint8_t)round(*((float *)&out_data_s[0])), (uint8_t)round(*((float *)&out_data_s[4])), (uint8_t)round(*((float *)&out_data_s[8]))); } MSH_CMD_EXPORT_ALIAS(ai_test, ai, ai_test sample); -
编译烧录,输入指令 ai
测试 
-
-
实战工程 https://10.199.101.2/svn/FILNK/Code/ac_product/ac_control/branches/ai_test

 浙公网安备 33010602011771号
浙公网安备 33010602011771号