

C# Job System
概述
设计目的:简单安全地使用多线程,随便就能写出高性能代码
收益:FPS更高,电池消耗更低(Burst编译器)
并行性:C# Job System和Unity Native Job System共享工作线程worker threads,也就是它们不会创建超过CPU cores数量的线程,也就不会导致CPU资源抢占问题。
什么是多线程
单线程:一次执行一条指令,产生一个结果
多线程:利用CPU的多核,多条指令同时执行,其他线程执行完成后会将结果同步给主线程。
多线程好的实践:几个运行时间很长的任务。
游戏代码的特点:大量小而短的任务。
解决方案:线程池。
context switching:线程上下文切换,性能敏感的,要尽量避免。
当激活的线程数超过CPU cores时,就会导致CPU资源争夺,从而触发频繁的context switching。
过程:先saving执行了一部分的当前线程,然后执行另外的线程,切回来的时候再reconstructing之前的线程再继续执行。
什么是Job System
简化多线程:job system通过创建jobs来实现多线程,而不是直接创建thread。
job概念:完成特定任务的一个小的工作单元。job接收参数并操作数据,类似于函数调用。job之间可以有依赖关系,也就是一个job可以等另一个job完成之后再执行。
job system管理一组worker threads,并且保证一个logical CPU core一个worker thread,避免context switching。
job system将jobs放在一个job queue里面,worker threads从job queue里面获取job然后执行。
job依赖性:job system管理job依赖关系,并保证执行时序的正确性。
C# Job System的Safety System
Race conditions:竞争条件,一个输出结果依赖于不受控制的事件出现的顺序或时机。
在写多线程代码时,race conditions是一个很大的挑战。race conditions不是bug,但它会导致不确定性行为。并且一旦出现,就很难定位,也很难调试,因为它依赖时机,打断点和加log本身都会改变各个独立线程执行的时机。
Safety system:为了写出更安全的多线程代码,C# Job System会检查所有的潜在的race conditions并保护代码不受可能会产生的bug的影响(这句话有点模糊......)。
解决办法:数据拷贝,每个job操作来自主线程数据的副本,而不是操作原数据。这样数据独立,就不会产生race conditions了。
blittable data types:job只能访问blittable的数据,这些数据在托管代码和native代码之间拷贝的时候,不需要做额外的类型转换。
拷贝方式:memcpy
NativeContainer
NativeContainer实际上是native memory的一个wrapper,包含一个指向非托管内存的指针。
不需要拷贝:使用NativeContainer可以让一个job和main thread共享数据,而不用拷贝。(copy虽然能保证Safety System,但每个job的计算结果也是分开的)。
可使用的C#类型定义:
| 数据结构 | 说明 | 来源 |
| NativeArray | 数组 | Unity |
| NativeSlice | 可以访问一个NativeArray的某一部分 | Unity |
| NativeList | 一个可变长的NativeArray | ECS |
| NativeHashMap | key value pairs | ECS |
| NativeMultiHashMap | 一个key对应多个values | ECS |
| NativeQueue | FIFO的queue | ECS |
Safety System安全策略:
Safety System内置于所有的NativeContainer,会自动跟踪NativeContainer的读写状态。
注意:所有的safety checkes都只在Editor和PlayMode模式下生效:bounds checks、deallocation checks、race condition checks。
还有一部分安全策略:
DisposeSentinel:自动检测memory leak并报错。依赖宏定义ENABLE_UNITY_COLLECTIONS_CHECKS。
AtomicSafetyHandle:用来转移NativeContainer的控制权。比如当2个jobs同时写一个NativeContainer,Safety System就会抛出一个error,并描述如何解决。异常会在产生冲突的job调度时抛出。依赖宏定义ENABLE_UNITY_COLLECTIONS_CHECKS。
这种情况下,可以使用job依赖,让其中一个job依赖另外一个job的完成。
规则:Safety System允许多个job同时read同一块数据。
规则:Safety System不允许一个job正在writing数据时,调度激活另一个“拥有write权限”的job(不是不让同时write)。
规则:手动指定job对数据的只读:(默认是可读写,会影响性能)
[ReadOnly]
public NativeArray<int> input;
注意:job对static data的访问没有Safety System安全保护,所以使用不当可能造成crash。
NativeContainer Allocator分配器:
(1)Allocator.Temp
最快,维持1 frame,job不能用,需要手动Dispose(),比如可以在native层的callback调用时使用。
(2)Allocator.TempJbo
稍微慢一点,最多维持4 frames,thread-safe,如果4 frames内没有Dispose(),会有warning。大多数small jobs都会使用这个类型的分配器.
(3)Allocator.Persistent
最慢,但是可持久存在,就是malloc的wrapper。Longer jobs使用这个类型,但在性能敏感的地方不应该使用。
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
创建Job
三要素:
(1)创建一个struct实现接口IJob;
(2)添加数据成员:要么是blittable类型, 要么是NativeContainer;
(3)添加Execute()方法实现。
执行job时,job.Execute()方法会在一个cpu core上执行一次。
注意:job操作数据是基于拷贝的,除非是NativeContainer类型。那么,一个job访问main thread数据的唯一方式就是使用NativeContainer。
public struct TestJob : IJob
{
public float a;
public float b;
public NativeArray<float> result;
public void Execute()
{
result[0] = a + b;
}
}
调度Job
三要素:
(1)实例化job;
(2)设置数据;
(3)调用job.Schedule()方法。
调用Schedule方法会将job放到job queue里面等待执行。一旦开始schedule,就没法中断job了。(疑问:这个once scheduled,是job.Schedule方法,还是从job queue里面拿出来开始执行?)
private void TestScheduleJob()
{
// Create a native array of a single float to store the result. This example waits for the job to complete for illustration purposes
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
// Set up the job data
MyJob jobData = new MyJob();
jobData.a = 10;
jobData.b = 10;
jobData.result = result;
// Schedule the job
JobHandle handle = jobData.Schedule();
// Wait for the job to complete
handle.Complete();
// All copies of the NativeArray point to the same memory, you can access the result in "your" copy of the NativeArray
float aPlusB = result[0];
// Free the memory allocated by the result array
result.Dispose();
}
JobHandle和Job依赖
设置job依赖关系:
JobHandle firstJobHandle = firstJob.Schedule();
secondJob.Schedule(firstJobHandle);
secondJob依赖firstJob的结果。
组合依赖项:
NativeArray<JobHandle> handles = new NativeArray<JobHandle>(numJobs, Allocator.TempJob);
// Populate `handles` with `JobHandles` from multiple scheduled jobs...
JobHandle jh = JobHandle.CombineDependencies(handles);
在main thread中等待jobs执行完成:
flush job:使用JobHandle.Complete()来等待job执行完成。
job只有Schedule之后才会执行,如果你想在main thread中访问job的正在使用的数据,你可以调用JohHandle.Comlete()。该方法flush job,并开始执行,然后将NativeContainer的数据权限返回给main thread。
如果你不需要访问数据,也可以调用统一static flush函数:JobHandle.ScheduleBatchedJobs(),当然该方法会影响到性能。
public struct MyJob : IJob
{
public float a;
public float b;
public NativeArray<float> result;
public void Execute()
{
result[0] = a + b;
}
}
public struct AddOneJob : IJob
{
public NativeArray<float> result;
public void Execute()
{
result[0] = result[0] + 1;
}
}
private void TestScheduleJob()
{
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
MyJob jobData = new MyJob();
jobData.a = 10;
jobData.b = 10;
jobData.result = result;
JobHandle firstHandle = jobData.Schedule();
AddOneJob incJobData = new AddOneJob();
incJobData.result = result;
JobHandle secondHandle = incJobData.Schedule(firstHandle);
secondHandle.Complete();
float aPlusB = result[0];
result.Dispose();
}
ParallelFor jobs 并行job
IJob只能一次一个job执行一个任务,但游戏开发中经常需要重复执行某个动作很多次,这时候就可以用到并行任务IJobParallelFor。
ParallelFor jobs使用NativeArray作为数据源,并且运行在多个core上,还是一个job一个core,只是每个job只负责处理完整数据的一个子集。
Execute(idx)方法对于数据源NativeArray中的每个item都调用一次。
调度:
需要手动指定执行次数,表示需要分多少次独立Execute来执行,一般直接取NativeArray的数组长度作为执行次数,一次处理一个数据。
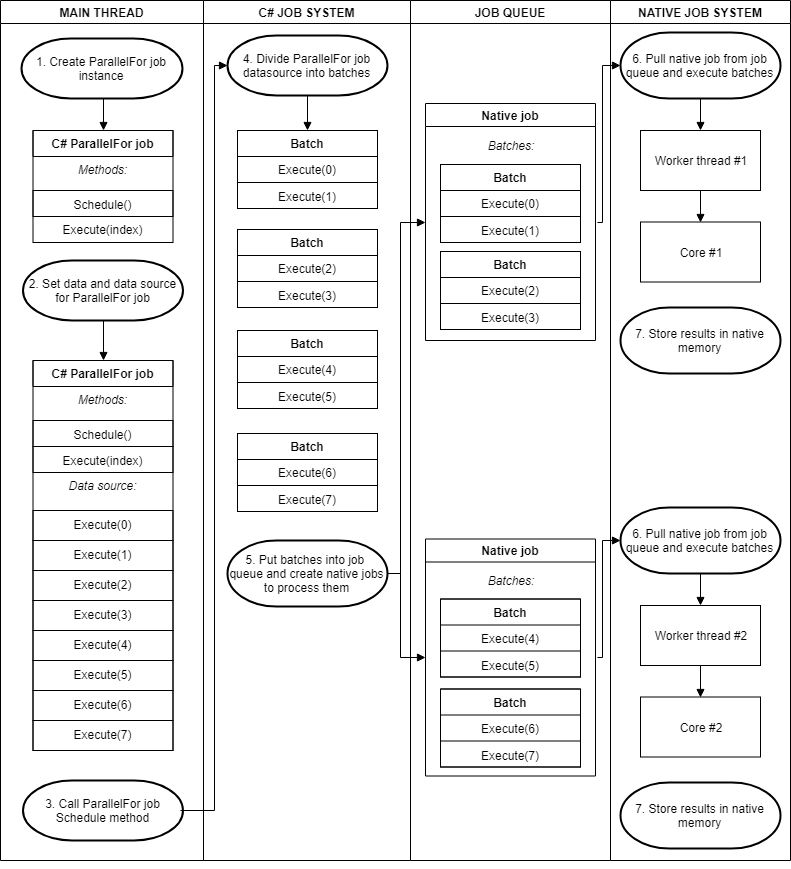
当一个native job提前完成它的batches,它会从其他的native job偷取一部分batches,然后继续执行。
颗粒度问题:分得太细会有work不断重建的开销,分得太粗又会有单核负载问题。
尝试法:所以最佳实践是从1开始逐步增加,直到性能不再提高。
public struct MyParallelJob : IJobParallelFor
{
public NativeArray<float> a;
public NativeArray<float> b;
public NativeArray<float> result;
public void Execute(int index)
{
result[index] = a[index] + b[index];
}
}
private void TestScheduleParallelJob()
{
NativeArray<float> a = new NativeArray<float>(10, Allocator.TempJob);
NativeArray<float> b = new NativeArray<float>(10, Allocator.TempJob);
NativeArray<float> result = new NativeArray<float>(10, Allocator.TempJob);
for(int i = 0; i < 10; ++i)
{
a[i] = i * 0.3f;
b[i] = i * 0.5f;
}
MyParallelJob jobData = new MyParallelJob();
jobData.a = a;
jobData.b = b;
jobData.result = result;
JobHandle handle = jobData.Schedule(10, 1);
handle.Complete();
for(int i = 0; i < 10; ++i)
{
Debug.LogError(result[i]);
}
a.Dispose();
b.Dispose();
result.Dispose();
}
ParallelForTransform jobs
public struct MyTransformParallelJob : IJobParallelForTransform
{
public void Execute(int index, TransformAccess transform)
{
}
}
注意事项:
(1)不能在job中访问static数据
在job中访问static数据是没有Safety System保证的,可能会导致crash。unity后续版本会增加static analysis来阻止这种用法。
(2)Flush scheduled batchs
JobHandle.ScheduleBatchedJobs:当你想要你的job开始执行是,可以调用这个函数flush调度的batch。
不flush batch会导致调度延迟到主线程等待batch执行结果时才触发执行。
JobHandle.Complete:直接开始执行。
在ECS中,batch flush是隐式执行的,不需要手动调用JobHandle.ScheduleBatchJobs。
(3)不要试图更新NativeContainer的内容
因为缺乏ref returns机制,所以不要这样用:
nativeArray[0]++;
// 等同于:
var tmp = nativeArray[0];
tmp++;
// 不生效!
// 正确的写法是:
var tmp = nativeArray[0];
tmp++;
nativeArray[0] = tmp;
MyStruct temp = myNativeArray[i];
temp.memberVariable = 0;
myNativeArray[i] = temp;
(4)调用JobHandle.Complete来让main thread重获控制权
主线程在访问数据之前,需要依赖的job调用complete。不能只是check JobHandle.IsCompleted,而是需要手动调用JobHandle.Complete()。
此调用还会清理Safety System的状态,不调用的话会有内存泄漏。
(5)在主线程中使用Schedule和Complete
这两个函数只能在主线程中调用。不能因为一个job依赖另一个job,就在前一个job中手动schedule另一个job。
(6)在正确的时间使用Schedule和Complete
Schedule:在数据填充完毕,立马调用
Complete:只在你需要result的时候调用
(7)NativeContainer添加read-only标记
默认是可读写的,如果确定只读就标记为read-only,可以提升性能。
(8)检查数据依赖
如果在profiler里看到main thread有“WaitForJobGroup”,就表示在等待worker thread处理完成。也就是说你的代码里面在什么地方引入了一个data dependency,这时候可以通过检查JobHandle.Complete来看一下是什么依赖关系导致了main thread需要等待的情况。
(9)调试jobs
Jobs有一个Run函数,你可以用它来替换原本调用Schedule的地方,从而在main thread上立即执行这个job。可以使用这个方法来调试。
(10)不要在job里面分配托管内存managed memory
在job里面分配托管内存是非常慢的,而且会导致Burst compiler没法使用。
Burst是基于LLVM的后端编译技术,它可以利用平台特定能力将c# jobs代码编译成高度优化过的机器码。
Unity GDC 2018: C# Job System
Unity at GDC - Job System & Entity Component System
Job System介绍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号