

数据分析02_数据筛选
本次学习数据以Titanic为例,链接:https://www.kaggle.com/competitions/titanic/data
本次学习工具:jupyter
本次学习目录文件:
数据分析主要使用python的numpy和pandas库
import numpy as np import pandas as pd
一、数据类型
1.DataFrame
DataFrame 是由多种类型的列构成的二维标签数据结构,类似于 Excel 、SQL 表,或 Series 对象构成的字典。
支持多种格式:
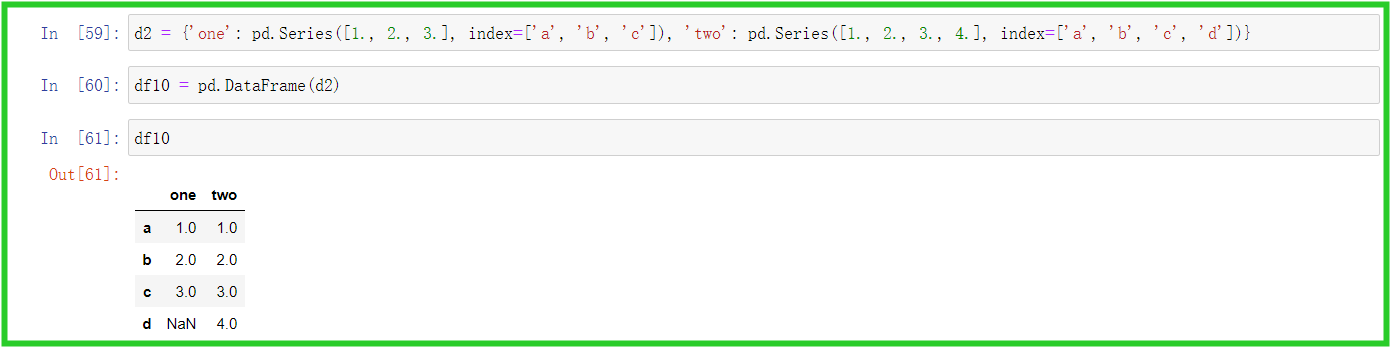
① Series生成DataFrame
d2 = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']), 'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df10 = pd.DataFrame(d2)
df10
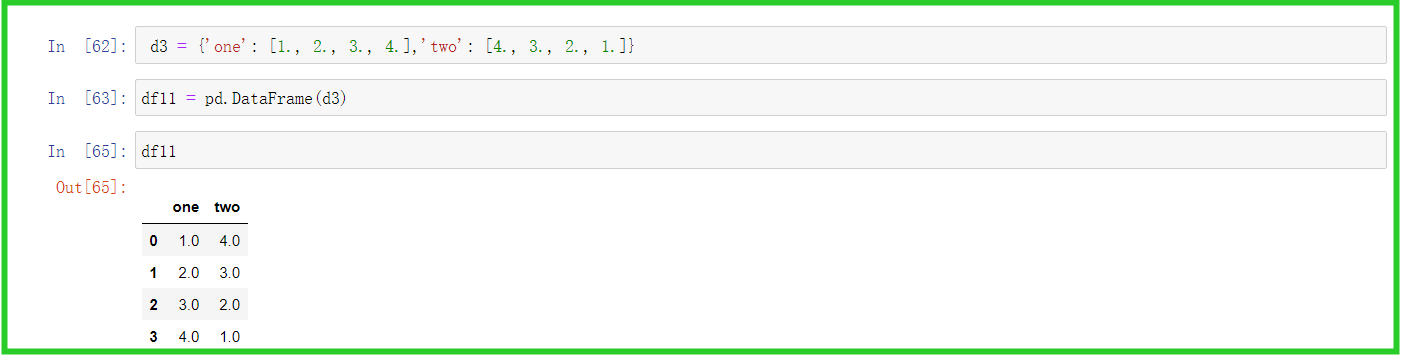
② 用多维数组字典、列表字典生成DataFrame
d3 = {'one': [1., 2., 3., 4.],'two': [4., 3., 2., 1.]}
df11 = pd.DataFrame(d3)
df11
③ 用结构多维数组或记录多维数组生成 DataFrame
data = np.zeros((2, ), dtype=[('A', 'i4'), ('B', 'f4'), ('C', 'a10')]) data[:] = [(1, 2., 'Hello'), (2, 3., "World")] pd.DataFrame(data)

④ 用列表字典生成 DataFrame
data2 = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
pd.DataFrame(data2)

⑤ 用元组字典生成DataFrame
pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})

2.Series
Series是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引。
创建Series格式: s = pd.Series(data, index=index)
其中data支持格式3种:python字典、多维数组、标量值(e.g. 5)
① 多维数组——data长度与index长度需一致,无index时自动创建(注意点)
s1 = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])

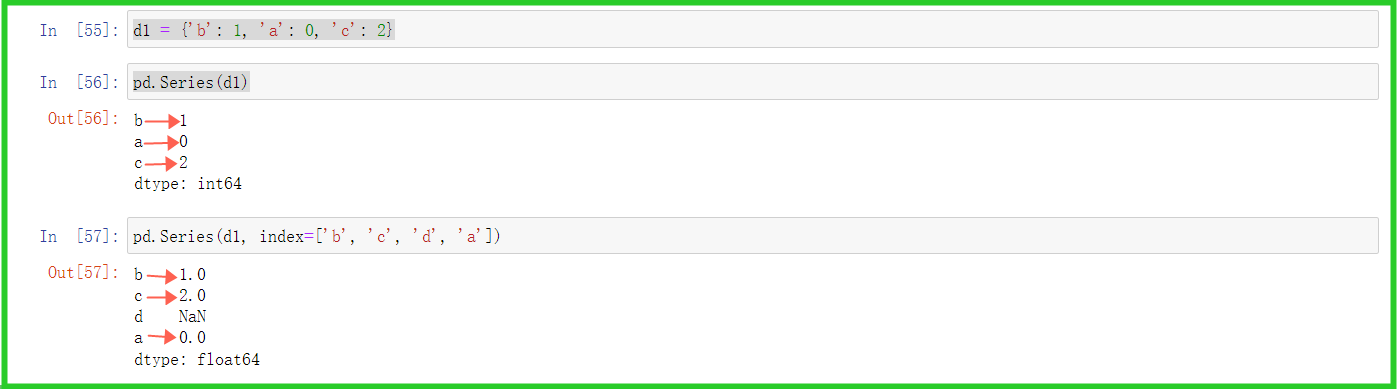
② 字典——字典可通过Series实例化
i.实例化
d1 = {'b': 1, 'a': 0, 'c': 2}
pd.Series(d1)

ii. 通过index提取对应值
d1 = ['b':'1', 'a':'0', 'c':'2'] pd.Series(d1, index=['b', 'c', 'd', 'a'])
③ 标量值——必须有索引,按照索引将标量值重复
pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])

【注意点】值列表生成Series,自动生成整数索引
s = pd.Series([1, 3, 5, np.nan, 6, 8])

二、数据对比
1.删除列
① del
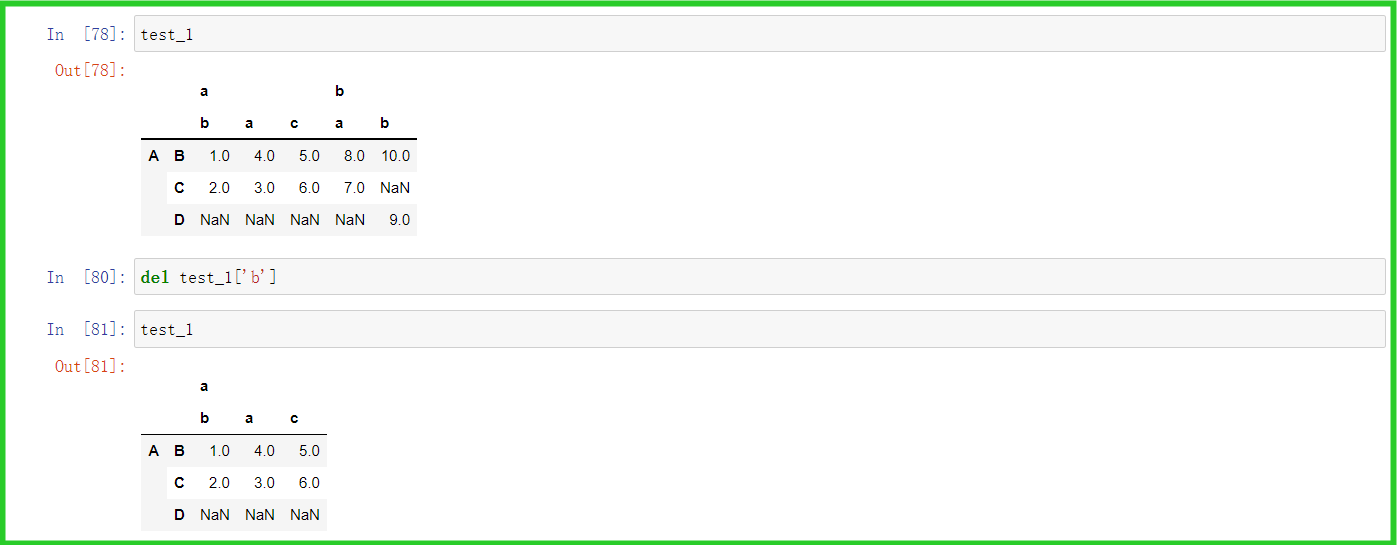
② pop
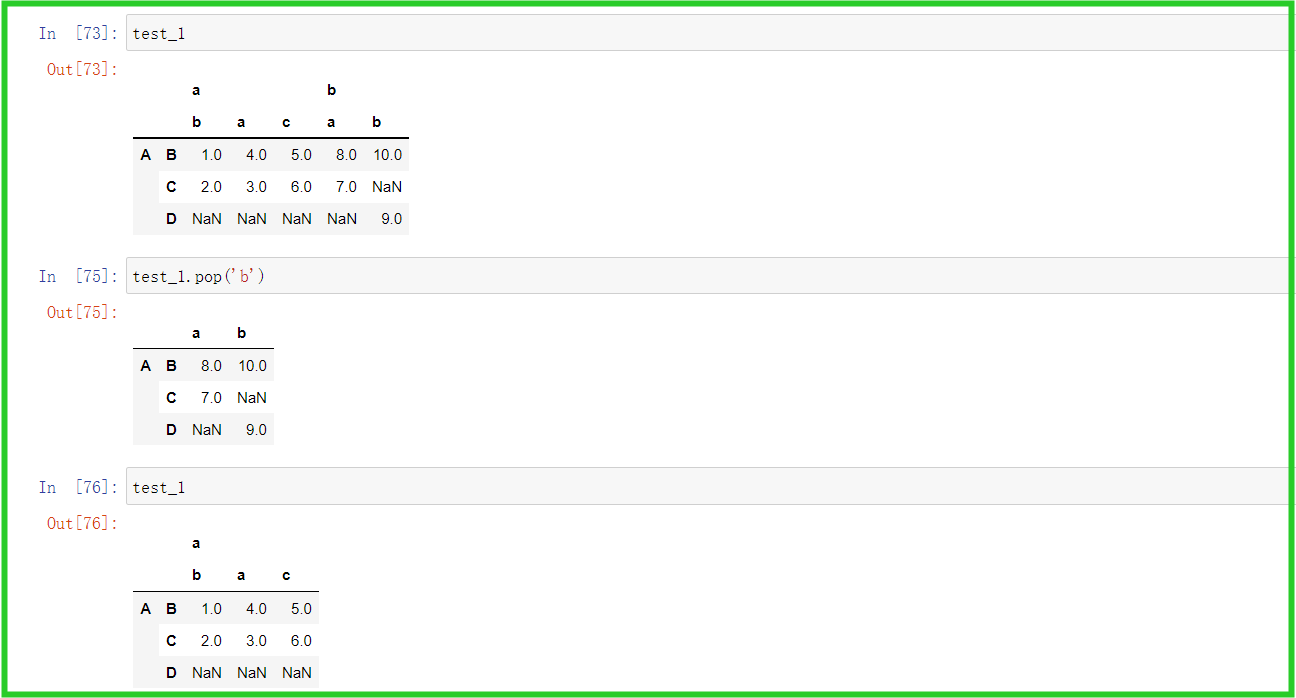
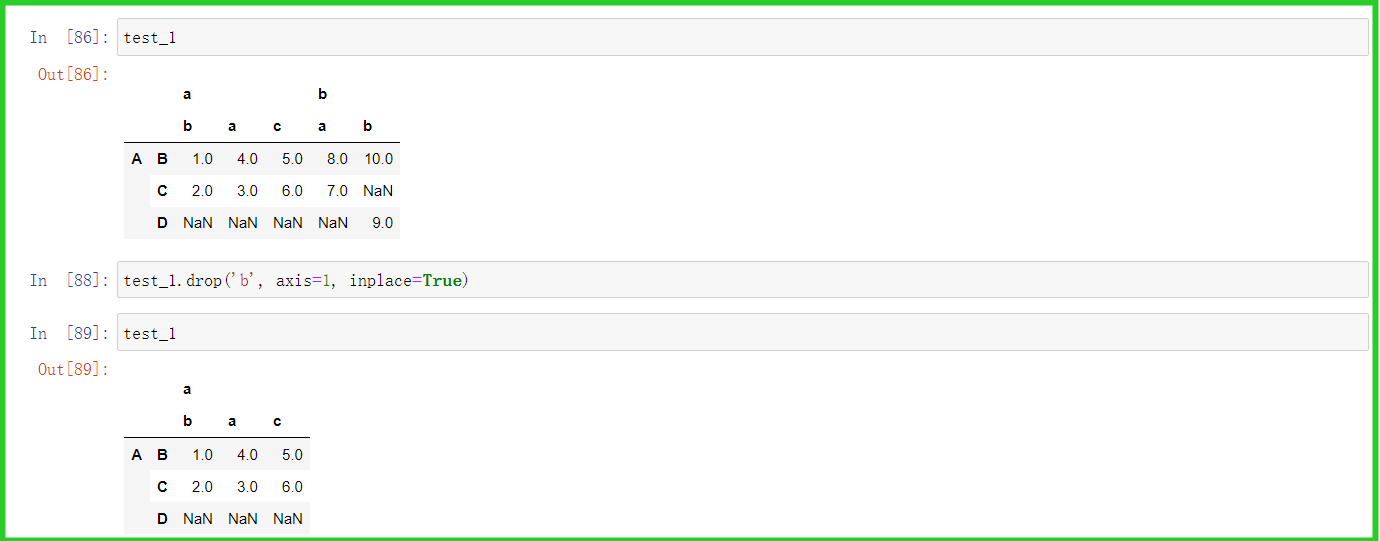
③ drop
i.修改为副本,不影响源文件——可用于隐藏数据

ii.保存修改
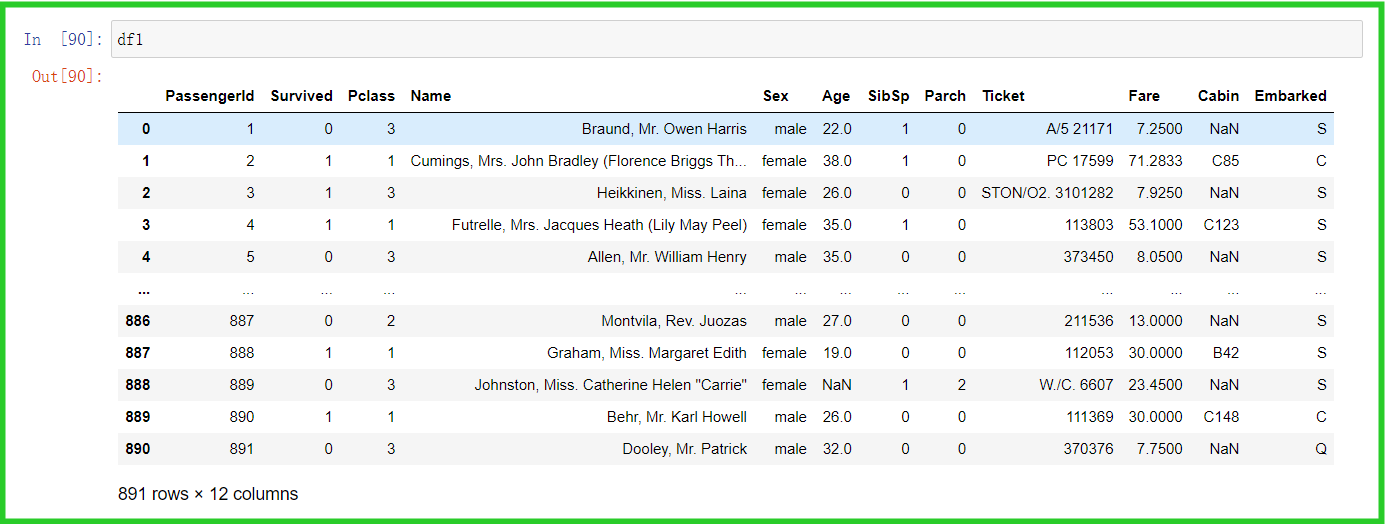
三、数据筛选
源数据
1. 数据交集和并集
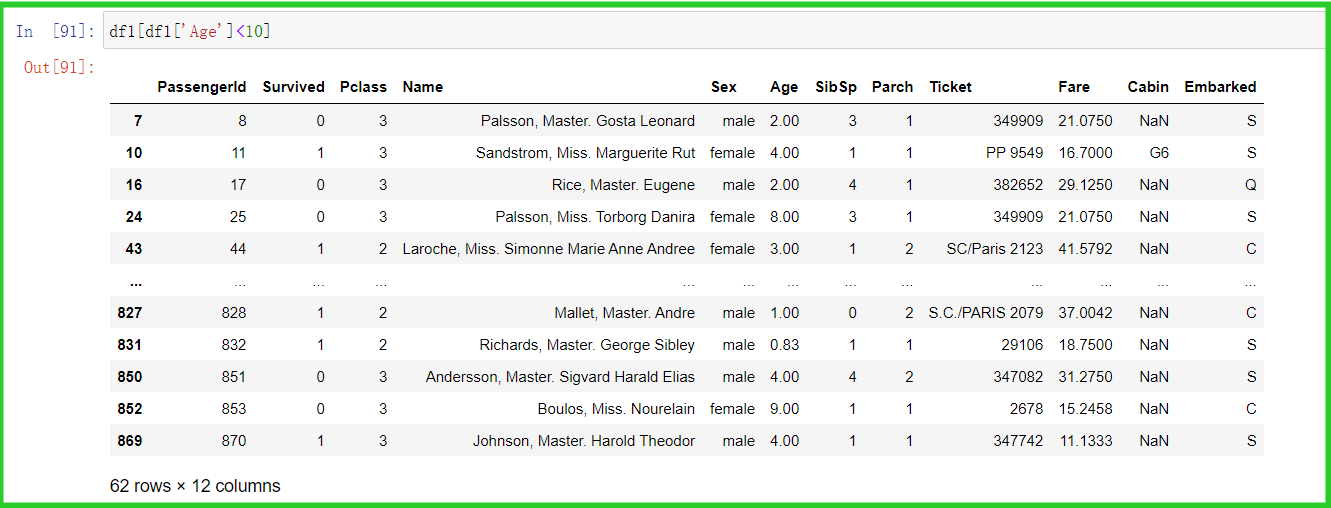
① 筛选10岁以下的乘客
df1[df1['Age']<10]
② 筛选10岁以上50岁以下的乘客(交集)
df1[ (df1['Age']>10) & (df1['Age']<50)]

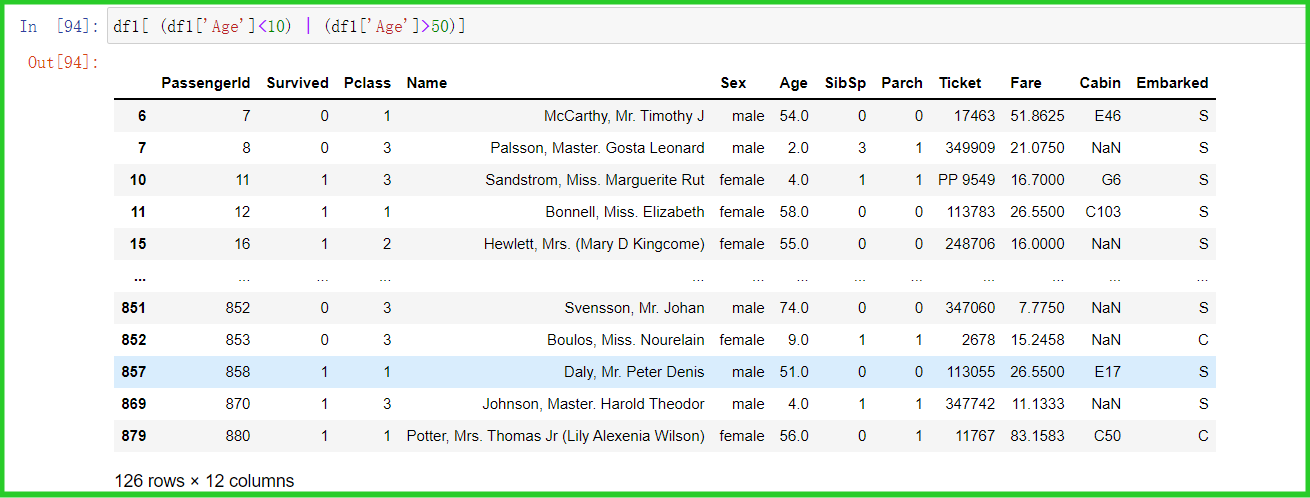
③ 筛选10岁以下或者50岁以上的乘客(并集)
df1[ (df1['Age']<10) | (df1['Age']>50)]
2. 数据抽取
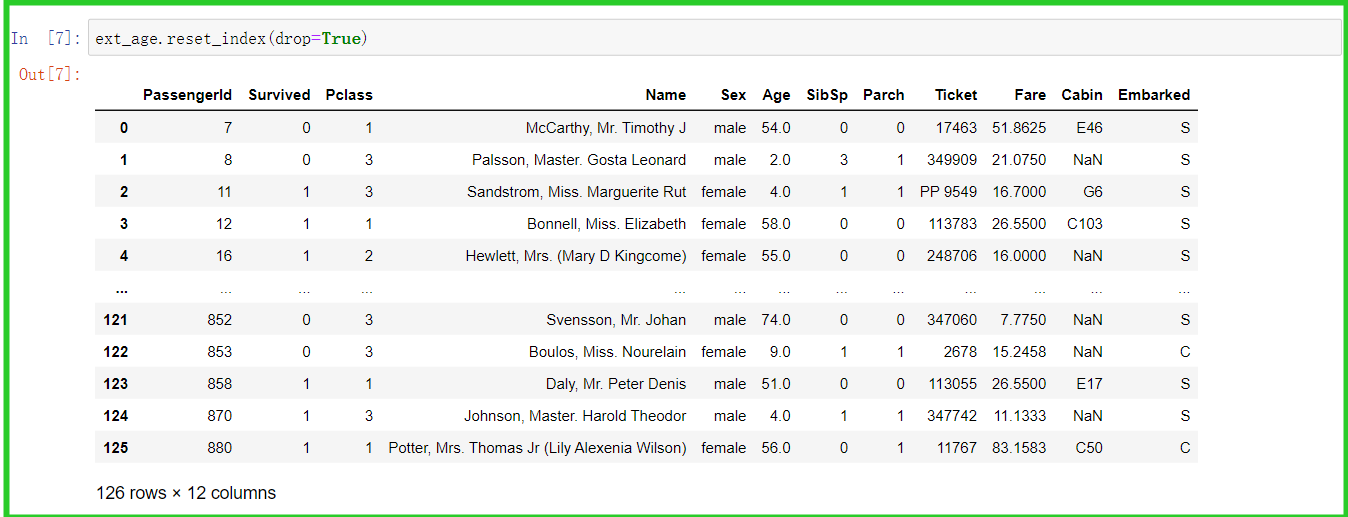
从上述并集中抽取数据,并集组合数据的索引值非等步长增加,组合数据如下图,一共126行12列数据。
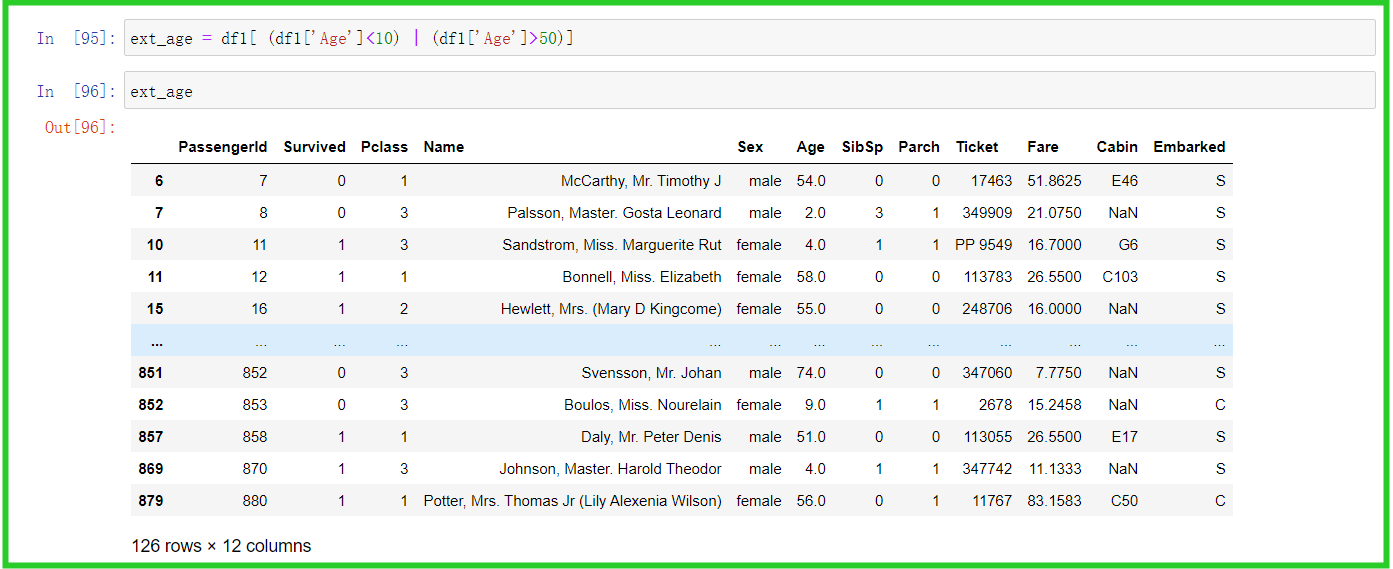
① 组合数据中抽取数据第126行数据
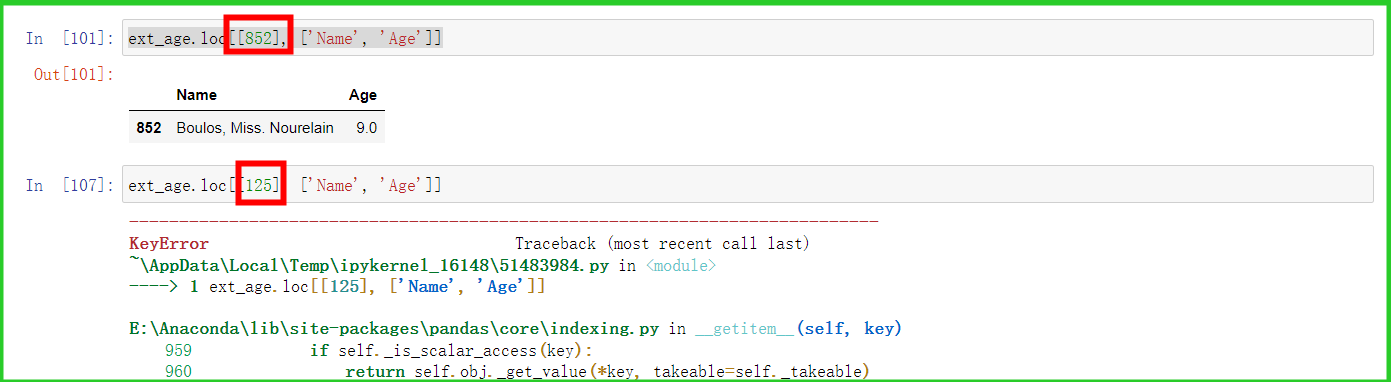
i. loc[]抽取
如下图所示,抽取126行数据失败,抽取852行成功,此索引搜索出的数据仍然是组合前的源数据集合
ii. iloc[]抽取

iii.reset_index(drop=True),删除原索引,重置索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号