



request 模块: python中远程的一款基于网络请求的模块, 功能非常强大,效率高。
如何使用:
— 指定url
— 发送数据到服务器,等待服务的回复
— 得到回复之后解析url的数据。
—解析之后放入数据库中
#! /usr/bin/env python #coding=utf-8 #这个项目是为了在搜狗浏览器里面输入指定的词汇 然后显示搜狗输出的页面 import requests #处理url的参数 kw = input('enter a word:') headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' } param = { 'query': kw } url = 'https://www.sogou.com/' #对指定的url发起的请求对应的url是携带参数的 并且请求过程中处理了参数 response = requests.get(url = url, params = param, headers = headers) print(response.text)
以上的代码是一个最简单的爬虫的程序。
下面要做的是如何做出一个百度翻译的爬虫程序:

其中 这个圈定的XHR里面会有AJAX数据请求包(AJAX数据请求包是动态的请求包,当网页输入一个单词的时候会网页会自动变化的数据包)

如图所示 这个是一个post的请求包 得到的是一个jason变量:

那么问题就是如何使用request去发送一个post的请求
#! /usr/bin/env python #coding=utf-8 import requests url = "https://fanyi.baidu.com/sug" word = input("enter the word you want to search: ") params = { 'kw' : word } headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36' } result = requests.post(url, params ,headers) data = result.json() with open(word+'.json', 'w', encoding = 'utf-8') as fd: fd.write(str(data)) print("it is over!")
请看这个程序如下行所述:
url = "https://fanyi.baidu.com/sug"
这就是post的请求 这个东西是我们从:
![]()
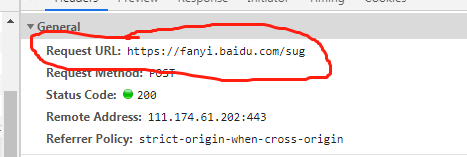
·这里得到的,只有这样我们在response的时候才能得到相应的json数据。
而且
result = requests.post(url, params ,headers)这个函数发送一个post函数到服务器。
当确定相应类型是json类型的话 才会返回json类型
data = result.json()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号