Oracle 存储过程&杂记
傻瓜式linux安装流程:https://blog.csdn.net/rod0320/article/details/119455271
存储过程
循环
-- 循环while create or replace procedure proc_test_while is i number; begin i := 0; while i < 5 loop i := i + 1; dbms_output.put_line(i); end loop; end; -- 循环for create or replace procedure proc_test_for is i number; begin for i IN 1..10 LOOP dbms_output.put_line(i); end loop; end; -- 调用函数 begin proc_test_for(); end; -- 调用函数 begin proc_test_while(); end;
循环数组
-- 循环数组 create or replace procedure proc_test_array is i number; TYPE type_array is varray(3) of varchar2(20); var_array type_array := type_array('AAA','BBB','CCC'); begin for i IN 1..var_array.count LOOP dbms_output.put_line(var_array(i)); end loop; end; -- 调用函数 begin proc_test_array(); end;
判断
-- 判断 create or replace procedure IF_TEST(a in number) IS begin IF a < 5 then dbms_output.put_line('AAAA'); elsif a < 10 then dbms_output.put_line('BBBB'); else dbms_output.put_line('CCCC'); end IF; end; -- 调用函数 begin IF_TEST(90); end;
无返回值函数
--不带返回值 create or replace procedure exchange(a in out varchar2, b in out varchar2) IS v_b varchar2(30); begin v_b :=a; a := b; b := v_b; dbms_output.put_line('a:'||a||' b:'||b); end; declare a varchar2(20) := '01'; b varchar2(20) := '02'; begin exchange(a ,b); END;
有返回值函数
-- 带返回值 create or replace procedure addOne(a in number,b in number,c out number) IS begin c:= a + b; end; declare c number; begin addOne(12,23,c); dbms_output.put_line(c); end;
随机值函数
create or replace procedure generateRandomNum(a in number,b in number,random_num out number) IS BEGIN select floor(dbms_random.value(a,b)) into random_num from dual; END;


declare type type_r1 is record ( site varchar2(20), zjlh varchar2(20), yjlh varchar2(20), pmdndocno varchar2(20), pmdnseq varchar2(20), pmdn007 number, xmdc007 number ); TYPE type_r1_array IS TABLE OF type_r1 INDEX BY BINARY_INTEGER; rceds type_r1_array; i number; j number; bom_num_str VARCHAR(100); TYPE exp_array is varray(3000) of varchar2(30); exp_arrays exp_array := exp_array(); t_sql VARCHAR(100); exp_strs exp_array := exp_array(); rate_num number; begin DBMS_OUTPUT.ENABLE(buffer_size => null); select pmdlsite,pmdn001 zjlh,xmdc001 yjlh,pmdndocno,pmdnseq,pmdn007,xmdc007 bulk collect into rceds from pmdn_t left join pmdl_t on pmdlent = pmdnent and pmdldocno = pmdndocno and pmdlsite = pmdnsite left join xmdc_t on xmdcent = pmdnent and xmdcdocno = pmdnud001 and xmdcseq = pmdnud002 where pmdlent = 67 and pmdnud001 is not null and pmdlstus in ('Y','C'); dbms_output.put_line(rceds.count); for i IN 1..rceds.count LOOP -------------------- bom比例 bom_num_str := ''; BEGIN select qty2 into bom_num_str from ( SELECT connect_by_root bmba001 root,bmba003,LTRIM(SYS_CONNECT_BY_PATH(to_char(bmba011,'FM99999990.000000'),'*'),'*') qty2 from ( SELECT bmaa001,bmba001,bmba003,bmba011/bmba012 bmba011 FROM bmaa_t LEFT JOIN bmba_t ON bmaaent = bmbaent AND bmaasite = bmbasite AND bmaa001 = bmba001 AND bmaa002 = bmba002 LEFT JOIN rtaxl_t ON bmbaent = rtaxlent AND substr(bmba001,1,3) = rtaxl001 AND rtaxl002='zh_CN' left join bmbb_t on bmbbent=bmaaent and bmba001=bmbb001 and bmbb003=bmba003 and bmbbsite = bmbasite WHERE bmaaent = 67 and bmbasite = rceds(i).site UNION all ( select bmea001 as bmaa001,bmea001 as bmba001,bmea008 as bmba003,round(bmba011 * bmea011,5) as bmba011 from bmea_t left join bmba_t on bmbaent = bmeaent and bmbasite = bmeasite and bmba001 = bmea001 and bmea003 = bmba003 where bmeasite = rceds(i).site and bmeaent = 67 ) ) start with bmaa001 = rceds(i).zjlh Connect by nocycle prior bmba003 = bmaa001 ) where root = rceds(i).zjlh and bmba003 = rceds(i).yjlh group by qty2; EXCEPTION WHEN NO_DATA_FOUND THEN bom_num_str := ''; ---赋值变量为null END; dbms_output.put_line(bom_num_str); ---字符串bom计算bom SELECT REGEXP_SUBSTR(bom_num_str, '[^*]+', 1, LEVEL) bulk collect into exp_strs FROM DUAL CONNECT BY LEVEL <= LENGTH(bom_num_str) - LENGTH(REPLACE(bom_num_str, '*')) + 1; --dbms_output.put_line(exp_arrays(i)); rate_num := 1; for j IN 1..exp_strs.count LOOP rate_num := rate_num*exp_strs(j); end loop; IF rceds(i).zjlh = rceds(i).yjlh then rate_num := 1; end IF; dbms_output.put_line(rceds(i).site||' '||rceds(i).zjlh||' '||rceds(i).yjlh||' '||rceds(i).pmdndocno||' '||rceds(i).pmdnseq||' '||rceds(i).pmdn007||' '||rceds(i).xmdc007||' '||rate_num||' '||rate_num*rceds(i).pmdn007); update pmdn_t set pmdnud011 = rate_num*rceds(i).pmdn007 where pmdnent = 67 and pmdnsite = rceds(i).site and pmdndocno = rceds(i).pmdndocno and pmdnseq = rceds(i).pmdnseq; end loop; --select 'adsas','123','qweqwe' into rceds from dual; end;
declare type type_r1 is record ( site varchar2(20), zjlh varchar2(20), yjlh varchar2(20), pmdndocno varchar2(20), pmdnseq varchar2(20), pmdn007 number, xmdc007 number ); TYPE type_r1_array IS TABLE OF type_r1 INDEX BY BINARY_INTEGER; rceds type_r1_array; i number; j number; bom_num_str VARCHAR(100); TYPE exp_array is varray(3000) of varchar2(30); exp_arrays exp_array := exp_array(); t_sql VARCHAR(100); exp_strs exp_array := exp_array(); rate_num number; begin DBMS_OUTPUT.ENABLE(buffer_size => null); select pmdlsite,pmdn001 zjlh,xmdc001 yjlh,pmdndocno,pmdnseq,pmdn007,xmdc007 bulk collect into rceds from pmdn_t left join pmdl_t on pmdlent = pmdnent and pmdldocno = pmdndocno and pmdlsite = pmdnsite left join xmdc_t on xmdcent = pmdnent and xmdcdocno = pmdnud001 and xmdcseq = pmdnud002 where pmdlent = 67 and pmdnud001 is not null and (pmdnud011 = 0 or pmdnud011 is null) and pmdlstus in ('Y','C') and SUBSTR(pmdldocno, 3, 4) != 'CG08'; dbms_output.put_line(rceds.count); for i IN 1..rceds.count LOOP -------------------- bom比例 bom_num_str := ''; BEGIN select qty2 into bom_num_str from ( SELECT connect_by_root bmba001 root,bmba003,LTRIM(SYS_CONNECT_BY_PATH(to_char(bmba011,'FM99999990.000000'),'*'),'*') qty2 from ( SELECT bmaa001,bmba001,bmba003,bmba011/bmba012 bmba011 FROM bmaa_t LEFT JOIN bmba_t ON bmaaent = bmbaent AND bmaasite = bmbasite AND bmaa001 = bmba001 AND bmaa002 = bmba002 LEFT JOIN rtaxl_t ON bmbaent = rtaxlent AND substr(bmba001,1,3) = rtaxl001 AND rtaxl002='zh_CN' left join bmbb_t on bmbbent=bmaaent and bmba001=bmbb001 and bmbb003=bmba003 and bmbbsite = bmbasite WHERE bmaaent = 67 and bmbasite = rceds(i).site UNION all ( select bmea001 as bmaa001,bmea001 as bmba001,bmea008 as bmba003,round(bmba011 * bmea011,5) as bmba011 from bmea_t left join bmba_t on bmbaent = bmeaent and bmbasite = bmeasite and bmba001 = bmea001 and bmea003 = bmba003 where bmeasite = rceds(i).site and bmeaent = 67 ) ) start with bmaa001 = rceds(i).zjlh Connect by nocycle prior bmba003 = bmaa001 ) where root = rceds(i).zjlh and bmba003 = rceds(i).yjlh group by qty2; EXCEPTION WHEN NO_DATA_FOUND THEN bom_num_str := ''; ---赋值变量为null END; dbms_output.put_line('bom_num_str: '||bom_num_str); ---字符串bom计算bom SELECT REGEXP_SUBSTR(bom_num_str, '[^*]+', 1, LEVEL) bulk collect into exp_strs FROM DUAL CONNECT BY LEVEL <= LENGTH(bom_num_str) - LENGTH(REPLACE(bom_num_str, '*')) + 1; --dbms_output.put_line(exp_arrays(i)); rate_num := 1; for j IN 1..exp_strs.count LOOP rate_num := rate_num*exp_strs(j); end loop; IF rceds(i).zjlh = rceds(i).yjlh then rate_num := 1; end IF; dbms_output.put_line(rceds(i).site||' zjlh:'||rceds(i).zjlh||' yjlh:'||rceds(i).yjlh||' pmdndocno:'||rceds(i).pmdndocno||' pmdnseq:'||rceds(i).pmdnseq||' pmdn007:'||rceds(i).pmdn007||' xmdc007:'||rceds(i).xmdc007||' rate_num:'||rate_num||' rate_num*rceds(i).xmdc007:'||rate_num*rceds(i).xmdc007); --update pmdn_t set pmdnud011 = rate_num*rceds(i).pmdn007 where pmdnent = 67 and pmdnsite = rceds(i).site and pmdndocno = rceds(i).pmdndocno and pmdnseq = rceds(i).pmdnseq; end loop; --select 'adsas','123','qweqwe' into rceds from dual; end;
存储过程中的临时表
insert into temp_table_CCC(col1, col2) values('aaaa', 1); select * from temp_table_CCC create or replace procedure p_create_table is begin Execute Immediate 'create global temporary table temp_table_CCC ( col1 varchar2(10), col2 number ) on commit preserve rows'; end; create or replace procedure p_drop_table is begin Execute Immediate 'drop table temp_table_CCC'; end; begin p_drop_table(); end; begin p_create_table(); end;
表循环输出,寻找目标临时表
declare v_cnt number; v_ent varchar2(10); v_sql varchar2(100); begin for i in (SELECT table_name FROM all_tables where table_name like '%ASFT310_01_SFDC_T%' order by table_name desc) loop v_sql := 'select count(0) from ' || i.table_name ; execute immediate v_sql into v_cnt; if v_cnt > 0 then v_sql := 'select sfdcent from ' || i.table_name || ' where rownum = 1'; execute immediate v_sql into v_ent; if v_ent = 82 then dbms_output.put_line(i.table_name); end if; --dbms_output.put_line(v_sql); else continue; end if; end loop; end;
炉号生成记录
--创建临时表的函数 create or replace procedure p_create_table is begin Execute Immediate 'create global temporary table temp_table_CCC ( df_num number, inadud001 varchar2(100) ) on commit preserve rows'; end; --删除临时表的函数 create or replace procedure p_drop_table is begin Execute Immediate 'drop table temp_table_CCC'; end; begin p_drop_table(); end; begin p_create_table(); end; declare type type_r2 is record ( sfec005 varchar2(3000), sfec014 varchar2(3000), inadud001s varchar2(3000) ); TYPE type_r2_array IS TABLE OF type_r2 INDEX BY BINARY_INTEGER; rceds type_r2_array; i number; j number; new_inadud001 VARCHAR(5000); str_sql VARCHAR(5000); TYPE str_array is varray(3000) of varchar2(2000); str_arrays str_array := str_array(); t_sql VARCHAR(100); str_strs str_array := str_array(); rate_num number; begin DBMS_OUTPUT.ENABLE(buffer_size => null); --根据完工入库单 匹配工单 去找 发料单 获取原材料炉号 ,再根据工单分组,获取这笔工单完工入库的最终炉号合集(没有去重),最后再根据料号批号分组,获取炉号 select sfec005,sfec014,inadud001s bulk collect into rceds from ( select sfec005,sfec014,listagg(inadud001s, ',') within group(ORDER BY sfec005,sfec014) AS inadud001s from ( select sfecdocno,sfdc001,sfec005,sfec014,t1.inadud001s,inadud001 from sfec_t left join sfea_t on sfecdocno = sfeadocno and sfecent = sfeaent and sfeasite = sfecsite left join inad_t on inad001 = sfec005 and inad003 = sfec014 and inadent = sfecent and inadsite = sfecsite left join inag_t on inag001 = sfec005 and inag006 = sfec014 and inagent = sfecent and inagsite = sfecsite left join ( select sfdc001,sfaa010,listagg(inadud001, ',') within group(ORDER BY sfdc001,sfaa010) AS inadud001s from sfdc_t left join sfdd_t on sfdcdocno = sfdddocno and sfdcseq = sfddseq and sfdcent = sfddent and sfdcsite = sfddsite left join sfda_t on sfdcdocno = sfdadocno and sfdcent = sfdaent and sfdcsite = sfdasite left join sfaa_t on sfaadocno = sfdc001 and sfaaent = sfdcent and sfaasite = sfdcsite left join inad_t on inadent = sfddent and inadsite = sfddsite and inad001 = sfdd001 and inad003 = sfdd005 where sfdcent = 67 and sfdcsite = '126' and sfdastus = 'S' and inadud001 is not null group by sfdc001,sfaa010 ) t1 on t1.sfdc001 = sfec001 and sfecent = 67 and sfecsite = '126' where sfecent = 67 and sfecsite = '126' and sfec012 = '109' and sfeastus = 'S' and inadud001 is null )group by sfec005,sfec014 ); dbms_output.put_line(rceds.count); for i IN 1..rceds.count LOOP new_inadud001 := ''; --使用临时表对重复炉号去重 --提前准备临时表 delete temp_table_CCC; SELECT REGEXP_SUBSTR(rceds(i).inadud001s, '[^,]+', 1, LEVEL) bulk collect into str_strs FROM DUAL CONNECT BY LEVEL <= LENGTH(rceds(i).inadud001s) - LENGTH(REPLACE(rceds(i).inadud001s, ',')) + 1; for j IN 1..str_strs.count LOOP insert into temp_table_CCC(df_num,inadud001) values(1,str_strs(j)); end loop; select listagg(inadud001, ',') within group(ORDER BY df_num) into new_inadud001 from ( select DISTINCT * from temp_table_CCC ) group by df_num; dbms_output.put_line(rceds(i).sfec005||' '||rceds(i).sfec014||' '||new_inadud001); --将需要刷的数据导入CCC中 A料号 B批号 C炉号 --insert into CCC(A,B,C) values(rceds(i).sfec005,rceds(i).sfec014,new_inadud001); end loop; end;
账面库存异常查询
declare type type_r1 is record ( site varchar2(20) ); TYPE type_r1_array IS TABLE OF type_r1 INDEX BY BINARY_INTEGER; rceds type_r1_array; type type_r2 is record ( site varchar2(20), inaj005 varchar2(20), inaj008 varchar2(20), inaj009 varchar2(20), inaj010 varchar2(20), num1 number, num2 number, num3 number, num4 number, num5 number ); TYPE type_r2_array IS TABLE OF type_r2 INDEX BY BINARY_INTEGER; rceds2 type_r2_array; i number; j number; begin DBMS_OUTPUT.ENABLE(buffer_size => null); select site bulk collect into rceds from ( select '104' as site from dual union all select '105' as site from dual union all select '106' as site from dual union all select '110' as site from dual union all select '112' as site from dual union all select '126' as site from dual union all select '135' as site from dual ); for i IN 1..rceds.count LOOP -- BEGIN select rceds(i).site,t2.inaj005,t2.inaj008,t2.inaj009,t2.inaj010,t2.上月期末 aa,t2.本月异动合计,t2.kc_sum,t3.inag008 ,t2.kc_sum - t3.inag008 bulk collect into rceds2 from ( select inaj005,inaj008,inaj009,inaj010,sum_inaj011 本月异动合计,NVL(t4.inat015, 0) 上月期末,sum_inaj011+NVL(t4.inat015, 0) kc_sum from ( select inaj005,inaj008,inaj009,inaj010,sum(inaj011*inaj004) sum_inaj011 from inaj_t where inajent = 67 and inajsite = rceds(i).site and TO_CHAR(inaj022,'YYYY-MM-DD') >= '2023-08-01' group by inaj005,inaj008,inaj009,inaj010 ) t1 left join ( select inat001,inat004,inat005,inat006,sum(inat015) inat015 from inat_t where inatsite = rceds(i).site and inatent = 67 and inat008 = '2023' and inat009 = '7' group by inat001,inat004,inat005,inat006 ) t4 on t1.inaj005 = t4.inat001 and t1.inaj008 = t4.inat004 and t1.inaj009 = t4.inat005 and t1.inaj010 = t4.inat006 ) t2 left join ( select inag001,inag004,inag005,inag006,sum(inag008) inag008 from inag_t where inagent = 67 and inagsite = rceds(i).site group by inag001,inag004,inag005,inag006 ) t3 on t2.inaj005 = t3.inag001 and t2.inaj008 = t3.inag004 and t2.inaj009 = t3.inag005 and t2.inaj010 = t3.inag006 where t2.kc_sum - t3.inag008 != 0; IF rceds2.count = 0 THEN continue; END IF; for j IN 1..rceds2.count LOOP --select '据点' 据点,'料号' 料号,'库位' 库位,'储位' 储位, '批号' 批号,'上月期末' 上月期末,'本月异动合计' 本月异动合计,'合计' 合计,'当前库存' 当前库存,'差异' 差异 from dual dbms_output.put_line(rceds2(j).site||' '||rceds2(j).inaj005||' '||rceds2(j).inaj008||' '||rceds2(j).inaj009||' '||rceds2(j).inaj010||' '||rceds2(j).num1||' '||rceds2(j).num2||' '||rceds2(j).num3||' '||rceds2(j).num4||' '||rceds2(j).num5); --insert into CCC(A,B,C,D,E,F,G,H,I,J) values(rceds2(j).site,rceds2(j).inaj005,rceds2(j).inaj008,rceds2(j).inaj009,rceds2(j).inaj010,rceds2(j).num1,rceds2(j).num2,rceds2(j).num3,rceds2(j).num4,rceds2(j).num5); end loop; end loop; end;
存储过程返回游标
CREATE OR REPLACE PROCEDURE f_gen_product_views( pct OUT SYS_REFCURSOR, a IN VARCHAR2 ) AS v_sql VARCHAR2(4000); BEGIN v_sql := ' select A from CCC where B='''||a||''''; DBMS_OUTPUT.PUT_LINE(v_sql); OPEN pct FOR v_sql; END; DECLARE v_cursor SYS_REFCURSOR; -- 声明游标变量 v_a VARCHAR2(30) := 'A'; -- 输入参数值(示例) v_result NUMBER; -- 存储查询结果的变量 BEGIN -- 调用存储过程 f_gen_product_views(v_cursor, v_a); -- 循环读取游标数据 LOOP FETCH v_cursor INTO v_result; EXIT WHEN v_cursor%NOTFOUND; DBMS_OUTPUT.PUT_LINE('A列的值: ' || v_result); END LOOP; -- 关闭游标 CLOSE v_cursor; END;
函数
函数示例
CREATE OR REPLACE function f_get_product_no(long_str varchar2,start_num number,end_num number,sortation_1 varchar2,sortation_2 varchar2,flg varchar2) return varchar2 is res_no varchar(40); i number; str_length number; product_no varchar(40); count_num number; product_no_last varchar2(40); begin if end_num = 0 then str_length := length(long_str)+1; else str_length := end_num; end if; str_length := str_length - 10; while str_length >= start_num loop product_no := SUBSTR(long_str, str_length, 9); product_no_last := SUBSTR(long_str, str_length+9, 1); --dbms_output.put_line(str_length||' '||product_no||' '||product_no_last); if flg = 3 then if flg = product_no_last then return(product_no); end if; else if SUBSTR(product_no, 1, 1) = sortation_1 and SUBSTR(product_no, 3, 1) = sortation_2 then if flg = product_no_last then return(product_no); end if; end if; end if; str_length := str_length - 11; end loop; return(null); end f_get_product_no; select f_get_product_no('2090070001*2080070001*2070070001*2050070001/2090070012*2080070012*2070070012*2050070012',1,instr('2090070001*2080070001*2070070001*2050070001/2090070012*2080070012*2070070012*2050070012','/'),'2','5',1) from dual
VBA
Function ExtractAndFormatDates(inputText As String, index As String) As String Dim regex As Object Set regex = CreateObject("VBScript.RegExp") ' 匹配日期范围 With regex .Pattern = "(\d{2,4}\.\d{1,2}\.\d{1,2})-(\d{2,4}\.\d{1,2}\.\d{1,2})" .Global = True End With Dim matches As Object Set matches = regex.Execute(inputText) Dim result As String result = "" ExtractAndFormatDates = "'" & Format(CDate(Replace(matches(0).SubMatches(index), ".", "/")), "yyyy-mm-dd") Set regex = Nothing Set matches = Nothing End Function Function ExtractChineseUsingRegex(text As String) As String Dim regex As Object Set regex = CreateObject("VBScript.RegExp") regex.Pattern = "[\u4e00-\u9fa5]" ' 匹配任意中文字符 regex.Global = True Dim matches As Object Set matches = regex.Execute(text) Dim result As String result = "" Dim match As Variant For Each match In matches result = result & match.Value Next match ExtractChineseUsingRegex = result End Function Sub 内容提取() Dim wsSource As Worksheet Dim wsNew As Worksheet Dim sourceSheets As Object Dim cellValue As Variant Dim col As Integer Dim lastRow As Integer Dim mbRow As Integer Dim flg As Integer Dim items() As String Dim chineseParts() As String Dim text As String ' 创建字典对象存储符合条件的源工作表 Set sourceSheets = CreateObject("Scripting.Dictionary") ' 遍历所有工作表,根据条件添加到源工作表集合 For Each wsSource In ThisWorkbook.Worksheets ' 示例条件:工作表可见且不是隐藏的 If wsSource.Name <> "目标" Then sourceSheets.Add wsSource.Name, wsSource '设置输出的行号 lastRow = Cells(Rows.Count, 1).End(xlUp).Row + 5 For i = 1 To lastRow If wsSource.Cells(i, "A").Value = "Remark:" Then col = i + 10 End If Next i For i = 1 To lastRow If wsSource.Cells(i, "A").Value > 0 And wsSource.Cells(i, "A").Value <= 100 Then mbRow = i ' 物品编号 wsSource.Cells(col, "E").Value = wsSource.Range("F" & mbRow).Value ' 物品名称 wsSource.Cells(col, "F").Value = wsSource.Range("B" & mbRow).Value ' 供应商编号 wsSource.Cells(col, "B").Value = Right(wsSource.Range("S" & mbRow).Value, 9) ' 使用Split函数按"/"分割字符串 items = Split(wsSource.Range("E3").Value, "/") ' 提取每个部分的中文 For j = LBound(items) To UBound(items) text = items(j) text = ExtractChineseUsingRegex(items(j)) If wsSource.Cells(col, "F").Value = text Then ' 生效日期 wsSource.Cells(col, "G").Value = ExtractAndFormatDates(items(j), 0) ' 有效期 wsSource.Cells(col, "H").Value = ExtractAndFormatDates(items(j), 1) Exit For End If ' 生效日期 wsSource.Cells(col, "G").Value = ExtractAndFormatDates(items(j), 0) ' 有效期 wsSource.Cells(col, "H").Value = ExtractAndFormatDates(items(j), 1) Next j ' 价格 wsSource.Cells(col, "j").Value = wsSource.Range("Q" & mbRow).Value ' 报价类型 wsSource.Cells(col, "R").Value = "'" & "00" ' 税代码 wsSource.Cells(col, "L").Value = "V" & wsSource.Range("R" & mbRow).Value * 100 ' W wsSource.Cells(col, "W").Value = wsSource.Range("R" & mbRow) ' 批次代码 wsSource.Cells(col, "A").Value = Format(Date, "yyyymmdd") With Rows(col).Font .Name = "宋体" ' 设置字体 .Size = 9 ' 设置字号为9 End With col = col + 1 End If Next i End If Next wsSource End Sub
杂记
插入时间格式
TO_DATE('2022-06-14 00:00:00', 'SYYYY-MM-DD HH24:MI:SS') TO_CHAR(inbadocdt,'YYYY-MM-DD')
日期计算
--当前月最后一天 LAST_DAY(TO_DATE('2025'||'-'||'05', 'YYYY-MM')) --日期减10天 select sysdate-10 from dual --日期加减月份 select to_char(ADD_MONTHS(SYSDATE, -1),'YYYY-MM') from dual
保留两位小数百分比
TO_CHAR(round(num,4)*100,'FM9999990.00')||'%'
位数不够前面补零
replace(lpad('6',2),' ','0')
listagg函数超过字段长度处理方式
select listagg(col, ',' ON OVERFLOW TRUNCATE) within group(ORDER BY col) from dual
EXISTS示例
select sfcb024,(SELECT C FROM CCC3 WHERE sfcbdocno = A and sfcb002 = B ) from sfcb_t where sfcbent = 67 and sfcbsite = '112' and EXISTS ( SELECT C FROM CCC3 WHERE sfcbdocno = A and sfcb002 = B )
oracle 添加用户
sqlplus / as sysdba
create tablespace oratt datafile 'D:\Oracle\oradata\oratt.dbf' size 500M;
userid分组后取日期最新的记录
SELECT * FROM ( SELECT ROW_NUMBER() OVER(PARTITION BY userid ORDER BY datetime DESC) rn,t.* FROM ( table ) t) WHERE rn = 1
分组累计求和
SELECT SUM(count) OVER(PARTITION BY userid ORDER BY datetime DESC) count_sum,t.* FROM ( table ) t
两表关联更新
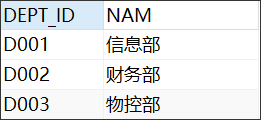
DROP TABLE "C##ORATT"."DEPT"; CREATE TABLE "C##ORATT"."DEPT" ( "DEPT_ID" VARCHAR2(255 BYTE) VISIBLE, "NAM" VARCHAR2(255 BYTE) VISIBLE ) TABLESPACE "ORATT" LOGGING NOCOMPRESS PCTFREE 10 INITRANS 1 STORAGE ( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT ) PARALLEL 1 NOCACHE DISABLE ROW MOVEMENT ; -- ---------------------------- -- Records of DEPT -- ---------------------------- INSERT INTO "C##ORATT"."DEPT" VALUES ('D001', '信息部'); INSERT INTO "C##ORATT"."DEPT" VALUES ('D002', '财务部'); INSERT INTO "C##ORATT"."DEPT" VALUES ('D003', '物控部');
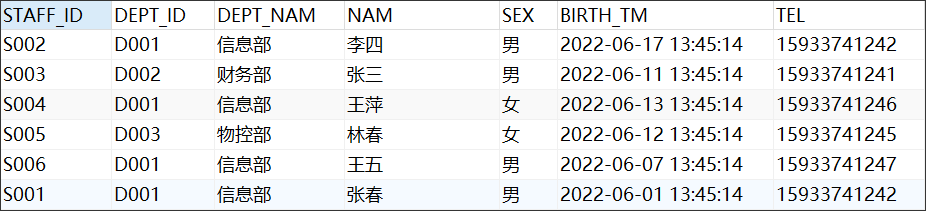
DROP TABLE "C##ORATT"."STAFF"; CREATE TABLE "C##ORATT"."STAFF" ( "STAFF_ID" VARCHAR2(255 BYTE) VISIBLE NOT NULL, "DEPT_ID" VARCHAR2(255 BYTE) VISIBLE, "DEPT_NAM" VARCHAR2(255 BYTE) VISIBLE, "NAM" VARCHAR2(255 BYTE) VISIBLE, "SEX" VARCHAR2(255 BYTE) VISIBLE, "BIRTH_TM" DATE VISIBLE, "TEL" VARCHAR2(255 BYTE) VISIBLE ) TABLESPACE "USERS" LOGGING NOCOMPRESS PCTFREE 10 INITRANS 1 STORAGE ( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT ) PARALLEL 1 NOCACHE DISABLE ROW MOVEMENT ; -- ---------------------------- -- Records of STAFF -- ---------------------------- INSERT INTO "C##ORATT"."STAFF" VALUES ('S002', 'D001', '信息部', '李四', '男', TO_DATE('2022-06-17 13:45:14', 'SYYYY-MM-DD HH24:MI:SS'), '15933741242'); INSERT INTO "C##ORATT"."STAFF" VALUES ('S003', 'D002', '财务部', '张三', '男', TO_DATE('2022-06-11 13:45:14', 'SYYYY-MM-DD HH24:MI:SS'), '15933741241'); INSERT INTO "C##ORATT"."STAFF" VALUES ('S004', 'D001', '信息部', '王萍', '女', TO_DATE('2022-06-13 13:45:14', 'SYYYY-MM-DD HH24:MI:SS'), '15933741246'); INSERT INTO "C##ORATT"."STAFF" VALUES ('S005', 'D003', '物控部', '林春', '女', TO_DATE('2022-06-12 13:45:14', 'SYYYY-MM-DD HH24:MI:SS'), '15933741245'); INSERT INTO "C##ORATT"."STAFF" VALUES ('S006', 'D001', '信息部', '王五', '男', TO_DATE('2022-06-07 13:45:14', 'SYYYY-MM-DD HH24:MI:SS'), '15933741247'); INSERT INTO "C##ORATT"."STAFF" VALUES ('S001', 'D001', '信息部', '张春', '男', TO_DATE('2022-06-01 13:45:14', 'SYYYY-MM-DD HH24:MI:SS'), '15933741242');
DEPT表结构
STAFF表结构
-- 更新部门名称 update STAFF S set S.DEPT_NAM = (select D.NAM from DEPT D where S.DEPT_ID = D.DEPT_ID) where exists (select * from DEPT D where S.DEPT_ID = D.DEPT_ID)
-- 更新部门名称 MERGE INTO STAFF S USING (select * FROM DEPT) D ON (S.DEPT_ID = D.DEPT_ID) WHEN MATCHED THEN UPDATE SET S.DEPT_NAM = D.NAM -- 更新部门名称 只更新信息部 MERGE INTO STAFF S USING (select * FROM DEPT) D ON (S.DEPT_ID = D.DEPT_ID) WHEN MATCHED THEN UPDATE SET S.DEPT_NAM = D.NAM where S.DEPT_ID = 'D001'
多表关联更新
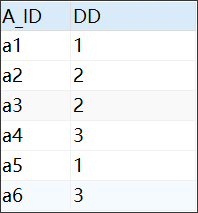
DROP TABLE "C##ORATT"."AAAA"; CREATE TABLE "C##ORATT"."AAAA" ( "A_ID" VARCHAR2(20 BYTE) VISIBLE, "DD" VARCHAR2(255 BYTE) VISIBLE ) TABLESPACE "ORATT" LOGGING NOCOMPRESS PCTFREE 10 INITRANS 1 STORAGE ( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT ) PARALLEL 1 NOCACHE DISABLE ROW MOVEMENT ; -- ---------------------------- -- Records of AAAA -- ---------------------------- INSERT INTO "C##ORATT"."AAAA" VALUES ('a1', '1'); INSERT INTO "C##ORATT"."AAAA" VALUES ('a2', '2'); INSERT INTO "C##ORATT"."AAAA" VALUES ('a3', '2'); INSERT INTO "C##ORATT"."AAAA" VALUES ('a4', '3'); INSERT INTO "C##ORATT"."AAAA" VALUES ('a5', '1'); INSERT INTO "C##ORATT"."AAAA" VALUES ('a6', '3');
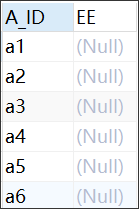
DROP TABLE "C##ORATT"."BBBB"; CREATE TABLE "C##ORATT"."BBBB" ( "A_ID" VARCHAR2(20 BYTE) VISIBLE, "EE" VARCHAR2(255 BYTE) VISIBLE ) TABLESPACE "ORATT" LOGGING NOCOMPRESS PCTFREE 10 INITRANS 1 STORAGE ( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT ) PARALLEL 1 NOCACHE DISABLE ROW MOVEMENT ; -- ---------------------------- -- Records of BBBB -- ---------------------------- INSERT INTO "C##ORATT"."BBBB" VALUES ('a1', NULL); INSERT INTO "C##ORATT"."BBBB" VALUES ('a2', NULL); INSERT INTO "C##ORATT"."BBBB" VALUES ('a3', NULL); INSERT INTO "C##ORATT"."BBBB" VALUES ('a4', NULL); INSERT INTO "C##ORATT"."BBBB" VALUES ('a5', NULL); INSERT INTO "C##ORATT"."BBBB" VALUES ('a6', NULL);
DROP TABLE "C##ORATT"."EEEE"; CREATE TABLE "C##ORATT"."EEEE" ( "DD" VARCHAR2(255 BYTE) VISIBLE, "EE" VARCHAR2(255 BYTE) VISIBLE ) TABLESPACE "ORATT" LOGGING NOCOMPRESS PCTFREE 10 INITRANS 1 STORAGE ( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT ) PARALLEL 1 NOCACHE DISABLE ROW MOVEMENT ; -- ---------------------------- -- Records of EEEE -- ---------------------------- INSERT INTO "C##ORATT"."EEEE" VALUES ('1', 'A'); INSERT INTO "C##ORATT"."EEEE" VALUES ('2', 'B'); INSERT INTO "C##ORATT"."EEEE" VALUES ('3', 'C');
AAAA表结构
BBBB表结构
EEEE表结构
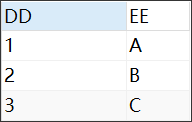
预期结果

MERGE INTO BBBB B USING (select A.A_ID,E.EE from AAAA A left join BBBB B on A.A_ID = B.A_ID left join EEEE E on E.DD = A.DD) C ON (B.A_ID = C.A_ID) WHEN MATCHED THEN UPDATE SET B.EE = C.EE;
根据对照表更新数据
update ecbb_t set ecbb029 = (select F from CCC where C = ecbb002 and A = ecbb004 and B = ecbb001 and D = ecbb012) where ecbb001||ecbb002||ecbb004||ecbb012 in (select B||C||A||D from CCC ) and ecbbent='67' and ecbbsite='105' select * from ecbb_t where ecbb001 in (select B from CCC where C = ecbb002 and A = ecbb004 and B = ecbb001) and ecbbent='67' and ecbbsite='105' select * from ecbb_t where ecbb001||ecbb002||ecbb004||ecbb012 in (select B||C||A||D from CCC ) and ecbbent='67' and ecbbsite='105'
时间类型
select systimestamp from dual --获取当前时间timestamp类型日期 select sysdate from dual --获取当前时间date类型日期
表id自增设置
--添加序列 create sequence SEQ_C_QCDD_T minvalue 1 maxvalue 999999999999999999999999999 start with 1 increment by 1 nocache; ------------------------------------------------- --设置触发器 create or replace trigger C_QCDD_T_ID before insert on C_QCDD_T for each row begin select SEQ_C_QCDD_T.nextval into :new.id from dual; end;
字符串分割并且行展示、两个字符串分割去重并且合并
SELECT trim( regexp_substr( 'CS5555,CS4444,CS1111,CS1111', '[^,]+', 1, ROWNUM ) ) x FROM dual b CONNECT BY ROWNUM <= length( regexp_replace( 'CS5555,CS4444,CS1111,CS1111', '[^,]+' ) ) + 1
SELECT listagg ( x, ',' ) within GROUP ( ORDER BY ROWNUM ) FROM ( SELECT DISTINCT x FROM ( SELECT trim( regexp_substr( 'CS3333,CS5555,CS0000', '[^,]+', 1, ROWNUM ) ) x FROM dual a CONNECT BY ROWNUM <= length( regexp_replace( 'CS3333,CS5555,CS0000', '[^,]+' ) ) + 1 UNION ALL SELECT trim( regexp_substr( 'CS5555,CS4444,CS1111,CS1111', '[^,]+', 1, ROWNUM ) ) x FROM dual b CONNECT BY ROWNUM <= length( regexp_replace( 'CS5555,CS4444,CS1111,CS1111', '[^,]+' ) ) + 1 ) )
字符串分割展示多行
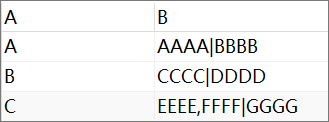
结果:
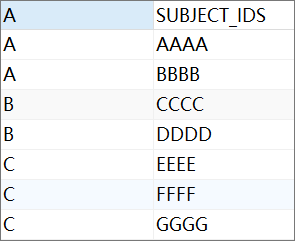
select A,regexp_substr(B, '[^(|,)]+', 1, level) AS SUBJECT_IDS from CCC connect by level <= regexp_count(B, '[^(|,)]+') and B = prior B and prior dbms_random.value > 0
UNPIVOT和PIVOT用法(行专列,列转行)
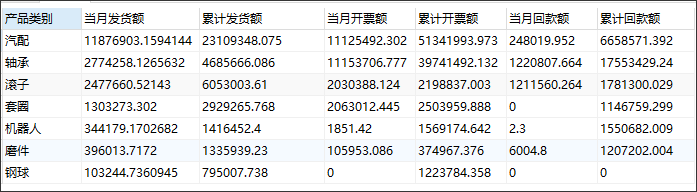
WITH UnpivotedData AS ( SELECT 产品类别, 金额类型, 数值 FROM ( select 产品类别,sum(当月发货额) 当月发货额,sum(累计发货额) 累计发货额,sum(当月开票额) 当月开票额,sum(累计开票额) 累计开票额,sum(当月回款额) 当月回款额,sum(累计回款额) 累计回款额 from cxmq300_t_v group by 产品类别 ) UNPIVOT ( 数值 FOR 金额类型 IN ( 当月发货额, 累计发货额, 当月开票额, 累计开票额, 当月回款额, 累计回款额 ) ) ) SELECT 金额类型, 轴承, 汽配, 滚子, 套圈, 机器人, 磨件, 钢球 FROM UnpivotedData PIVOT ( MAX(数值) FOR 产品类别 IN ( '轴承' AS 轴承, -- 为每个值指定别名 '汽配' AS 汽配, '滚子' AS 滚子, '套圈' AS 套圈, '机器人' AS 机器人, '磨件' AS 磨件, '钢球' AS 钢球 ) ) ORDER BY 金额类型


 浙公网安备 33010602011771号
浙公网安备 33010602011771号