

最近2个月没做什么新项目 完全是对于旧的系统进行性能优化 避免超时 死锁 数据处理能力不够等常见的性能问题
这里不从架构方面出发 毕竟动大手脚成本比较高 那么我们以实例为前提 从细节开始
优化角度
一.业务逻辑优化
二.DB优化
三.数据处理优化
四.锁与性能
五.cpu飙高小结
六.crash现象分析
业务逻辑优化
这一条不具有普遍性 不同的业务不同的场景 如果归纳起来 就是在不影响业务的前提下进行流程精简
1. 废弃冗余逻辑
常见于各种基于数据库的检查 很多同学在维护别人代码的时候 没有深入理解别人的逻辑 也许别人在取数据的时候已经在查询条件中已经过滤了相关逻辑 而后来维护的同学又来了一次check
当然如果处于数据安全的角度 double check无可厚非,但是如果连锁都没有的double check 其实不做也罢。
毕竟 省一次dbcall 可能效果胜于你做的N多优化
2. 合并业务请求
出发点和上述一致 节省dbcall 但是存在一个矛盾的点 如果业务包在事务里 这条需要慎重考虑 事务的设计原则里 当然能小则小
DB优化
这个其实是比较核心的点
1. 索引优化
这个点比较泛泛 但是做好的人不多 一个专攻于索引优化的人也可以在运维方面独当一面了
我们拿实例来看一个索引优化例子
首先利其器 选中你需要的调试信息
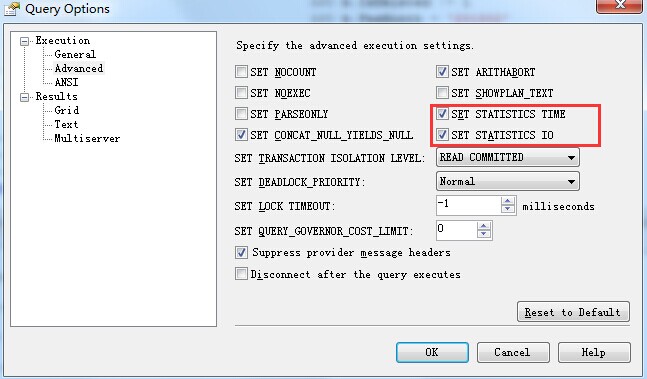
然后打开自动统计信息更新 特别对于测试阶段 数据以及数据量频繁变更的时候 统计信息一定要记得刷新
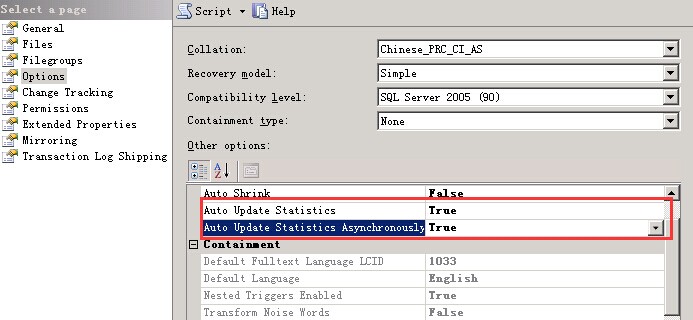
创建索引时,查询优化器自动存储有关索引列的统计信息。另外,当 AUTO_CREATE_STATISTICS 数据库选项设置为 ON(默认值)时, 数据库引擎自动为没有用于谓词的索引的列创建统计信息。随着列中数据发生变化,索引和列的统计信息可能会过时,从而导致查询优化器选择的查询处理方法不是 最佳的。 当 AUTO_UPDATE_STATISTICS 数据库选项设置为 ON(默认值)时,查询优化器会在表中的数据发生变化时自动定期更新这些统计信息。 每当查询执行计划中使用的统计信息没有通过针对当前统计信息的测试时就会启动统计信息更新。 采样是在各个数据页上随机进行的,取自表或统计信息所需列的最小非聚集索引。从磁盘读取一个数据页后,该数据页上的所有行都被用来更新统计信息。 常规情况是:在大约有 20% 的数据行发生变化时更新统计信息。但是,查询优化器始终确保采样的行数尽量少。 对于小于 8 MB 的表,则始终进行完整扫描来收集统计信息。
最后执行 SET STATISTICS PROFILE ON,可以看到更详细的计划
随便拿个典型sql来作示例 相关值为虚假值 仅供参考
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECT DISTINCT TOP 1000 a.CustomerID FROM TravelTicket(nolock) aWHERE a.TicketChargeDate < GETDATE()AND a.AvailableAmount > 999AND a.[Status] <>999AND a.IsInCome <>999AND a.IsInCome <>998 AND NOT EXISTS (SELECT TOP 1 1 FROM TicketCharge(NOLOCK) b WHERE b.CustomerID = a.CustomerID AND b.chargetype = 999 AND b.IsSuccessful = 999 AND b.IsDeleted != 999 AND b.FeeMonth = '999') |
在完全没有任何索引的前提下我们查询一遍看下各种io信息以及执行计划

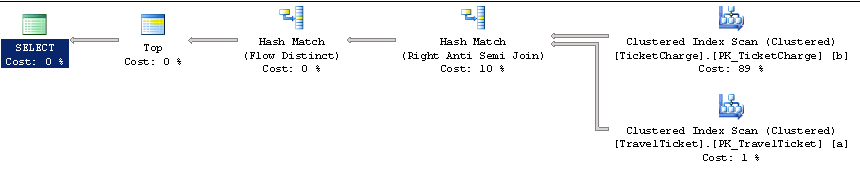

如图中所示 存在2个聚集索引扫描 先介绍下基础知识
【Table Scan】:遍历整个表,查找所有匹配的记录行。这个操作将会一行一行的检查,当然,效率也是最差的。
【Index Scan】:根据索引,从表中过滤出来一部分记录,再查找所有匹配的记录行,显然比第一种方式的查找范围要小,因此比【Table Scan】要快。
【Index Seek】:根据索引,定位(获取)记录的存放位置,然后取得记录,因此,比起前二种方式会更快。
在有聚集索引的表格上,数据是直接存放在索引的最底层的,所以要扫描整个表格里的数据,就要把整个聚集索引扫描一遍。在这里,聚集索引扫描
【Clustered Index Scan】就相当于一个表扫描【Table
Scan】。所要用的时间和资源与表扫描没有什么差别。并不是说这里有了“Index”这个字样,就说明执行计划比表扫描的有多大进步。当然反过来讲,如
果看到“Table Scan”的字样,就说明这个表格上没有聚集索引。换句话说 上面那段sql存在2个表扫描。
【Clustered Index Seek】:直接根据聚集索引获取记录,最快!
所以我们优化的目标是将扫描(scan)变为查找(seek)

先来尝试TicketCharge表 下面我们所新添并且讨论的索引都是非聚集索引
江湖上流传着这么一篇秘诀,建符合索引根据where查询的顺序来,好吧我们姑且先尝试一下
|
1
2
3
4
5
6
7
8
9
10
11
12
|
/****** Object: Index [rgyu_test1] Script Date: 2015-2-2 17:52:50 ******/CREATE NONCLUSTERED INDEX [chongzi_test] ON [dbo].[TicketCharge]( [CustomerID] ASC, [ChargeType] ASC, [IsSuccessful] ASC, [IsDeleted] ASC, [FeeMonth] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]GOALTER INDEX [chongzi_test] ON [dbo].[TicketCharge] DISABLEGO |
再看看新的执行计划
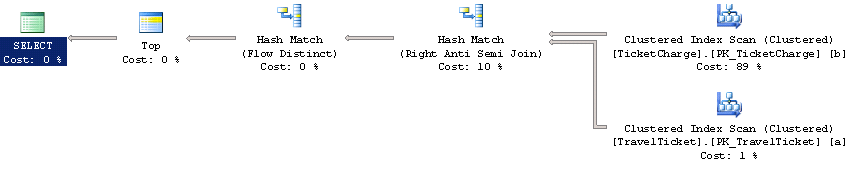
没变!江湖秘诀果然还是得慎重点用,我们来分析下索引没命中的原因。
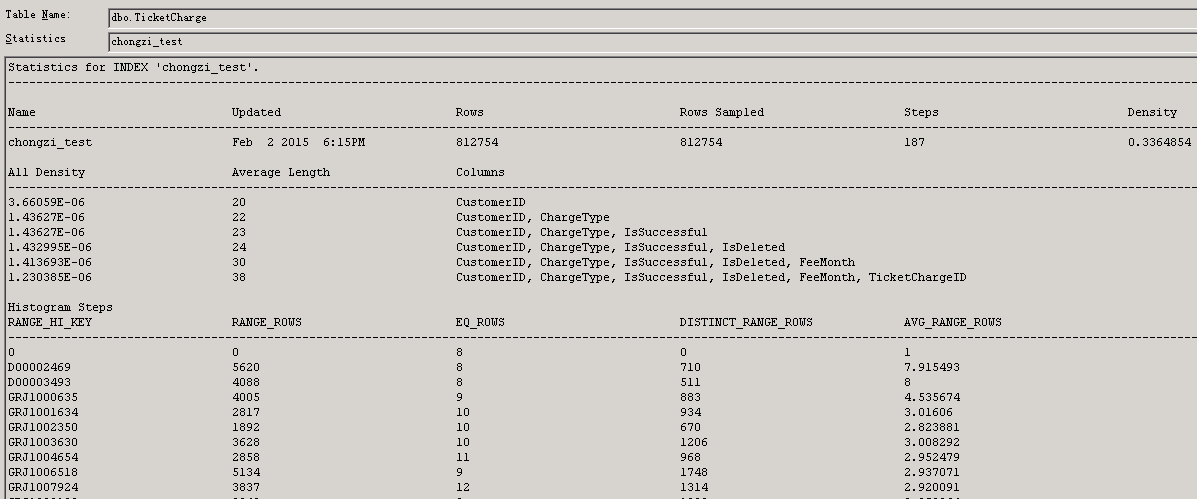

第一块是索引基本信息
| 列名 | 描述说明 |
|
Name |
统计信息对象名称 |
|
Update |
上一次更新统计信息的日期和时间 |
|
Rows |
在目标索引、统计信息或列中的总行数。如果筛选索引或统计信息,此行数可能小于表的行数。 |
| Rows Sampled | 用于统计信息计算的抽样总行数。 |
| Steps | 统计信息对象第一个键列的直方图中的值范围数。每个步骤包括在直方图结果中定义的 RANGE_ROWS 和 EQ_ROWS。 |
|
Density |
查询优化器不使用此值。显示此值的唯一目的是为了向后兼容。密度的计算公式为 1 / distinct rows,其中 distinct rows 是直方图输出中所有步骤的 DISTINCT_RANGE_ROWS 之和。如果对行进行抽样,distinct rows 则基于抽样行的直方图值。 |
| Average Key Length | 统计信息对象的键列中,所有抽样值中的每个值的平均字节数 |
| String Index | 如果为“是”,则统计信息中包含字符串摘要索引,以支持为 LIKE 条件估算结果集大小。仅当第一个键列的数据类型为char、varchar、nchar、nvarchar、varchar(max)、nvarchar(max)、text 或 ntext 时,才会对此键列创建字符串索引。 |
| Filter Expression | 包含在统计信息对象中的表行子集的表达式。NULL = 未筛选的统计信息。有关详细信息,请参阅筛选统计信息。 |
| Unfiltered Rows | 应用筛选器表达式前表中的总行数。如果 Filter Expression 为 NULL,Unfiltered Rows 等于行标题值。 |
第二块对指定 DENSITY_VECTOR 时结果集中所返回的列进行了说明。
| 列名 | 说明 |
| All Density | 针对统计信息对象中的列的每个前缀计算密度(1/ distinct_rows)。 |
| Average Length | 每个列前缀的列值向量的平均长度(按字节计)。例如,如果列前缀为列 A 和 B,则长度为列 A 和列 B 的字节之和。 |
| Columns | 为其显示 All density 和 Average length 的前缀中的列的名称。 |
第三块对指定 HISTOGRAM 选项时结果集中所返回的列进行了说明。
| 列名 | 说明 |
| RANGE_HI_KEY | 直方图步骤的上限值。 |
|
RANGE_ROWS |
表中位于直方图步骤内(不包括上限)的行的估算数目。 |
| EQ_ROWS | 表中值与直方图步骤的上限值相等的行的估算数目。 |
| DISTINCT_RANGE_ROWS | 直方图步骤内(不包括上限)非重复值的估算数目。 |
| AVG_RANGE_ROWS | 直方图步骤内(不包括上限)重复值的频率或平均数目(如果 DISTINCT_RANGE_ROWS > 0,则为 RANGE_ROWS / DISTINCT_RANGE_ROWS)。 |
越小的SQL Server索引密度意味着具有更高的索引选择性。当密度趋近于1,索引就变得有更少的选择性,基本上没有用处了。当索引的选择性低的时候,优化器可能会 选择一个表扫描(table scan),或者叶子级的索引扫描(Index scan),而不会进行索引查找(index seek),因为这样会付出更多的代价。当心你的数据库中低选择性的索引。这样的索引通常是对系统的性能是一个损害。它们通常不仅不会用来进行数据的检 索,而且也会使得数据修改语句变得缓慢,因为需要额外的索引维护。识别这些索引,考虑删除掉它们。
而上图我们的密度已经达到0.33,因为这不是一个好的方案。我们调整索引顺序,将feemonth提到第一列。
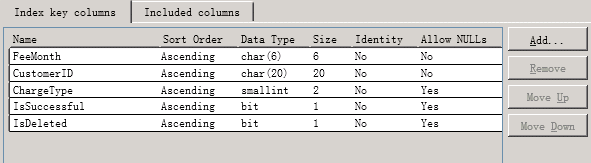
再看执行io和执行计划

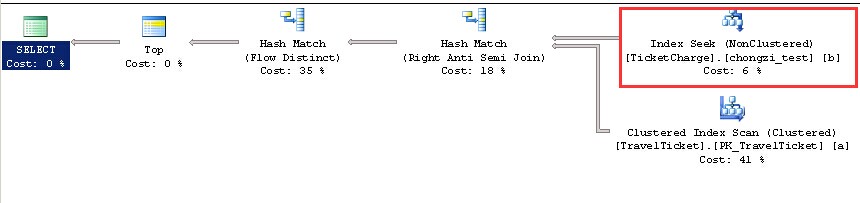
搞定,我们再看下统计分析
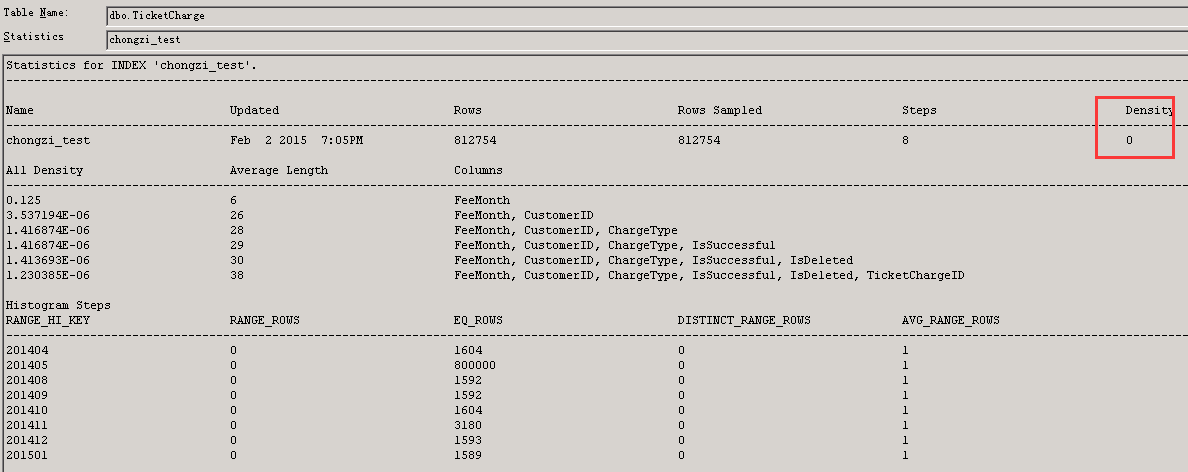
到此为止或许你以为已经搞定了这个索引问题 ticketcharge的读取从1w3降低到了13 但是友情提请一下 密度会随着数据分布的变化而变化 本次的demo数据具有特殊性 具体的问题还需要具体来分析
我们看一下更详细的计划

另外针对本文这种sql写法 还有另外一个点需要关注 那就是索引第一列不可以是于第一张表关联的列
调整我们的索引顺序同样可以让sql命中索引 我们来看下效果
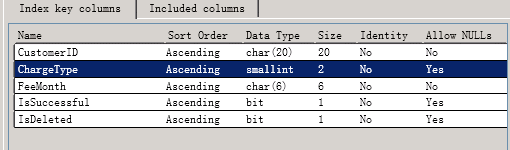
执行一下
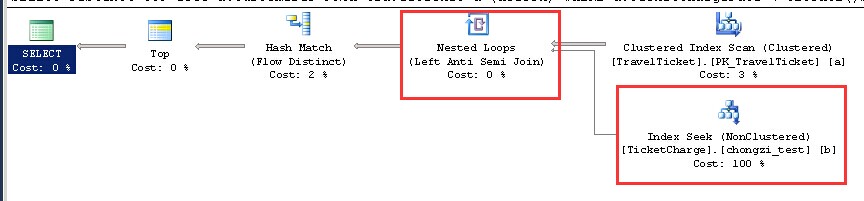


虽然命中了索引 但是由于关联键的问题 导致ticketcharge进行了循环。
所以说 江湖上流传的按照where查询条件设计索引顺序是完全错误的 第一列的选择要根据密度选择性来判断
另外非聚集索引列分为键值列和包含列(include)
复合索引的键值列不是越多越好,首先索引本身有长度的限制。但是使用非键值列就不算在索引长度内。键列存储在索引的所有级别中,而非键列仅存储在叶 级别中。简单来说本来索引类似于字典的部首查找,你根据部首查找以后还要根据该汉字对应的页数去查看详细,但是如果你只是要一个简单的该汉字的拼音,那么 包含列相当于把拼音直接附加在部首查找后面,你就不需要再去详细页查看其它你不需要的信息了。
换个角度来说,当查询中的所有列都作为键列或非键列包含在索引中时,带有包含性非键列的索引可以显著提高查询性能。这样可以实现性能提升,因为查询优化器可以在索引中找到所有列值;不访问表或聚集索引数据,从而减少磁盘 I/O 操作。
至于travelticket的索引设计也类似,不过需要注意的点是不等于运算 以及like运算 都是不能使用索引的。需要结合业务来调整。
除了上述人为的添加索引 还有一种取巧的办法
打开sql server profiler
按照自己的需求新建一个跟踪脚本

写个脚本循环跑这个语句然后保存跟踪脚本。打开推荐sql优化器
导入刚才的跟踪脚本,并且选择索引优化
执行分析
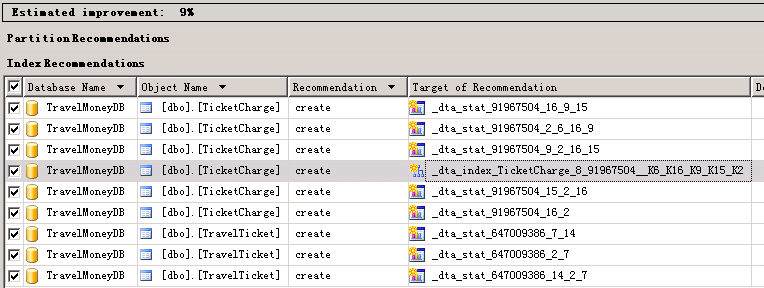
数据处理优化
对于db优化在程序员能力已经到瓶颈的前提下,可以着手从应用程序上的细节出发,例如并行。
所谓并行也就是多线程针对同任务分区分块协同处理。多线程的技术大家都很了解,这里突出以下线程同步的问题。例如我有1000个人我分10组任务执行,如何正确的保证当前10组任务正确的完成互相不冲突并且等到所有任务完成后才开启下一轮1000.
这里介绍一个比较通用的方法,首先申明一个信号量队列List<ManualResetEvent>();
取出1000条后对于1000条进行添加顺序标识表示并且模余分组。标识从1开始递增就可以,模余分组方法如下
testInfos.GroupBy(i => i.index % workTaskCount).Select(g => g.ToList()).ToList();
其中index为刚才添加的顺序标识, workTaskCount为分组的任务数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
//循环处理批次任务foreach (var testGroup in testGroups){ var mre = new ManualResetEvent(false); manualEvents.Add(mre); var testMethodParam = new TestMethodParam { mrEvent = mre, testGroup = TestGroup, testParam = testParam }; //线程池处理计划任务 ThreadPool.QueueUserWorkItem(DoTestMethod, testMethodParam);}if (manualEvents.Count != 0){ //等待所有信号量完成 切记这里最大值为64 WaitHandle.WaitAll(manualEvents.ToArray(), 30 * 60 * 1000);} |
DoTestMethod就是旧的任务处理逻辑,testMethodParam负责涵盖你旧逻辑中所需要的参数并且包含一个完成信号量。
这里需要牢记的是WaitHandle等待的信号量最大值为64.
如果你需要的任务分组数超过64那么这里推荐在DoTestMethod方法中不适用信号量,而是使用原子操作的标识,例如 Interlocked.Increment(taskCount)。当taskCount累加到1000(你设计的当前批次值)就结束一轮。不过比起 WaitHandle性能上要慢一些。
另外如果你使用线程池来管理线程,最好加上最大线程限制。过多的线程是导致cpu资源消耗的原因之一,最好的线程数是服务器cpu个数的2倍-1或者-2,
死锁问题
锁超时的问题大多是因为表锁产生。解决表锁的问题说难也不难,不过需要牺牲性能。mssql针对主键的更新不会产生表锁而是产生行锁。针对这个问题那么死锁的问题初步解决起来就简单了。
这是比较通用的处理方法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
DECLARE @step INTDECLARE @id CHAR(12)create table #tmpTest --创建临时表( rec_index INT , id CHAR(12));INSERT INTO #tmpTest (rec_index,ID) SELECT ROW_NUMBER() OVER(ORDER BY ID) AS rec_index,ID FROM TestTable(nolock) WHERE BID = @bIDSET @rowcount=0SET @step=1SELECT @rowcount=COUNT(*) FROM #tmpTest AS ttWHILE(@step<=@rowcount)BEGIN SELECT @id=Id FROM #tmpTest AS tt WHERE @step=rec_index UPDATE TestTable SET UpdateUser = @UpdateUser, UpdateTime = @UpdateTime, WHERE ID =@id SET @step=@step+1END |
cpu飙高小结
对于cpu飙高分2类,应用服务器和db服务器的飙高原因优先排查点不同
对于应用服务器,首先排查while true等死循环,其次看多线程问题。不排除其他原因,这里只介绍主要的情况
在本机就可以根据源代码来调试
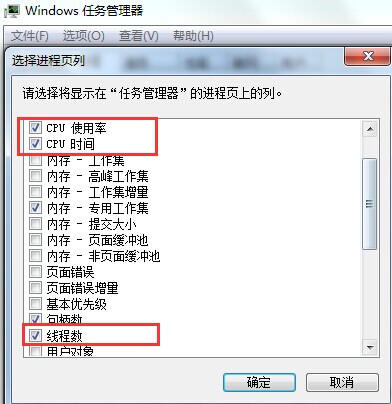
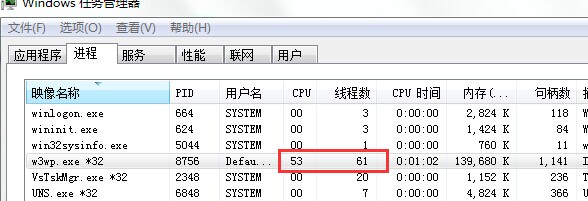
如图所示我们的cpu问题是由于线程过得多导致 因为我的demo用的Threadpool所以一个简单的ThreadPool.SetMaxThreads(5, 5);即可搞定.
如果上述情况检查不出你的程序导致cpu飙高的原因,那么就需要借助于其他工具 例如dotTrace.

根据自己的程序类型加载不同的探查器
截图不具有典型性 操作很简单 没有什么过多值得介绍的 官方文档
http://www.jetbrains.com/profiler/features/index.html
我们随便找个程序
下面我们看看db服务器cpu飙高的一些原因。
最大的一个坑是隐式数据类型转换,之所以为坑是因为他不是显示的出现问题,而是当你的数据分布以及量达到一定条件后才会产生问题。
什么是隐式数据类型转换:
当我们在语句的where 条件等式的左右提供了不同数据类型的列或者变量,SQL Server在处理等式之前,将其中一端的数据转换成跟另一端数值的数据类型一致,这个过程叫做隐式数据类型转换。
比如 char(50)=varchar(50), char(50)=nchar(50), int=float, int=char(20) 这些where 条件的等式都会触发隐式数据类型转换。
但是,对于某些数据类型转换过程中,可以转换的方向只是单向的。例如:
如果你试图比较INT和FLOAT的列,INT数据类型必须被转换成FLOAT型 "CONVERT(FLOAT,C_INT) = C_FLOAT".
如果你试图比较char和nchar的列,char数据类型必须被转换成unicode型 "CONVERT(nchar,C_char) = C_nchar"
因此,我们在.net 或者java的程序中,会经常出现由于隐式数据类型转换而产生的性能问题。
最简单的 我们来做个试验
|
1
2
3
4
5
6
7
8
9
|
CREATE TABLE [Chongzi_Test] ([TAB_KEY] [varchar] (5) NOT NULL ,[Data] [varchar] (10) NOT NULL ,CONSTRAINT [Chongzi_Test_PK] PRIMARY KEY CLUSTERED ([TAB_KEY]) ON [PRIMARY] ) ON [PRIMARY]GO |
然后插入几百条数据
我们执行
|
1
2
3
4
|
declare @p1 intset @p1=0exec sp_prepexec @p1 output,N'@P0 varchar(5)',N'select TAB_KEY,Data from Chongzi_Test where TAB_KEY = @P0',N'0'select @p1 |
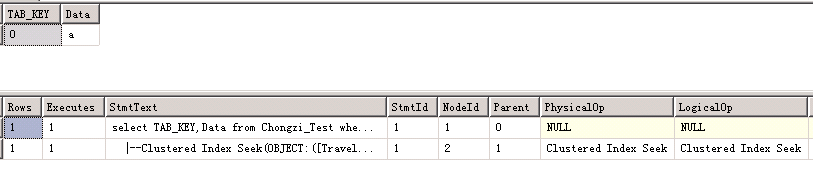
然后我们换一种不匹配类型来看一下
|
1
2
3
4
|
declare @p1 intset @p1=0exec sp_prepexec @p1 output,N'@P0 nvarchar(4000)',N'select TAB_KEY,Data from Chongzi_Test where TAB_KEY = @P0',N'0'select @p1 |
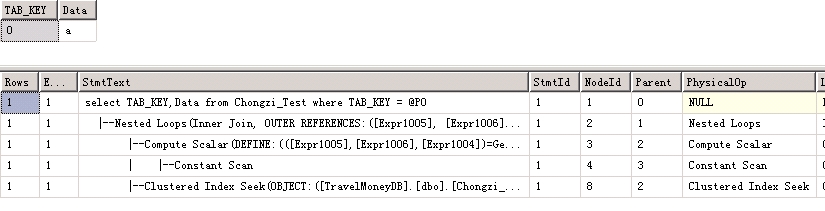
这里出现了一个操作叫做GetRangeThroughConvert(),在这里,SQL Server由于不能直接对varchar(5)的列用nvarchar(4000)的值进行seek,因此,SQL Server必须将nvarchar转换成varchar。
这个过程中不同的应用场景可以带来性能的损耗可能会很大,因为在转换过程中可能会存在表扫描。
例如之前项目中有个nvarchar(max)向varchar(50)转换,由于包含有特别的字符,如全双工字符<, 该字符直接转换成varchar(50)不会那么顺利。需要根据参数的实际长度和表结构中定义的字段长度进行比较,如果小于表结构中定义的字段长 度,Range依旧会比较小,但是如果大于表结构中定义的字段长度,GetRangeMismatchedTypes函数会把Range设得很宽,查询很 慢。
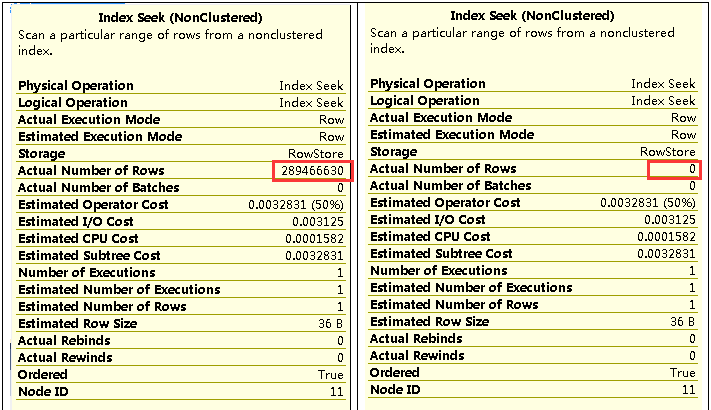
如图执行计划是一样的,返回数据行不同。
附上c# dbtype 与sql 类型的对应表
AnsiString:VarChar
Binary:VarBinary
Byte:TinyInt
Boolean:Bit
Currency:Money
Date:DateTime
DateTime:DateTime
Decimal:Decimal
Double:Float
Guid:UniqueIdentifier
Int16:SmallInt
Int32:Int
Int64:BigInt
Object:Variant
Single:Real
String:NVarChar
Time:DateTime
AnsiStringFixedLength:Char
StringFixedLength:NChar
Xml:Xml
DateTime2:DateTime2
DateTimeOffset:DateTimeOffset
Crash现象分析
目前还是用老办法 抓dump分析堆栈
使用过程可以参考我之前的博文 http://www.cnblogs.com/dubing/p/3878591.html
面向.Net程序员的后端性能优化实战

 浙公网安备 33010602011771号
浙公网安备 33010602011771号