
基于模糊聚类和最小割的层次化三维网格分割算法(Hierarchical Mesh Decomposition)
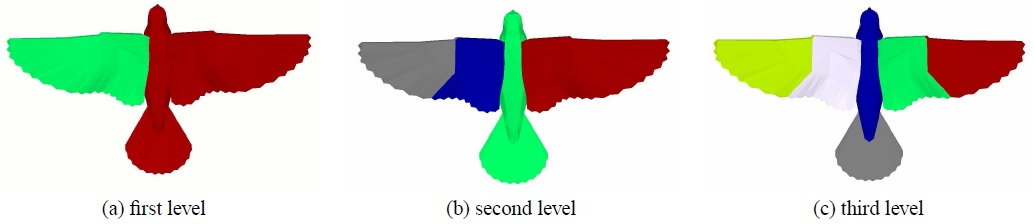
网格分割算法是三维几何处理算法中的重要算法,具有许多实际应用。[Katz et al. 2003]提出了一种新型的层次化网格分割算法,该算法能够将几何模型沿着凹形区域分割成不同的几何部分,并且可以避免过度分割以及锯齿形分割边界。算法的核心思想是先利用模糊聚类的方法分割几何模型,并保留分割边界附近的模糊区域,然后利用最小割的方法在模糊区域里寻找准确的分割边界。算法主要包含以下4个步骤:
1. 计算网格中所有相邻面片之间的距离;
2. 计算每个面片属于不同分割区域的概率;
3. 迭代调整每个面片的概率,直到收敛;
4. 在模糊区域里寻找准确的分割边界。
下面以模型二分为例具体介绍上述计算过程,如果模型需要分割成多个部分,可以以此为基础进行层次化分割。
Step 1:
对于相邻面片fi和fj,定义它们两者之间的测地距离和角度距离(如下图所示)。测地距离为相邻面片质心之间的距离,而角度距离表达式如下:
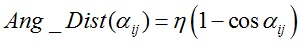
上式中αij为相邻面片之间的二面角,对于凹边η = 1,对于凸边η取较小值(例如0.2)。
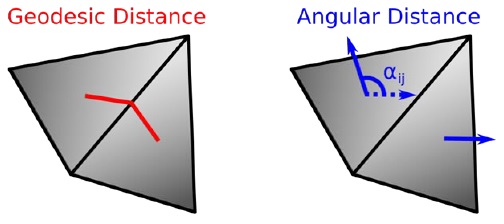
图:测地距离和角度距离示意图
构建网格的对偶图(如下图所示),网格中的每个面片对应对偶图中的一个顶点,同时如果网格中的两个面片相邻,那么对偶图中对应的两个顶点相连。图中边的权重定义为:
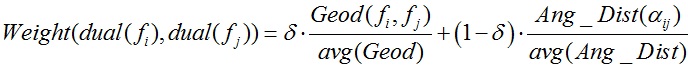
给定网格中任意的两个面片,它们之间的距离等于对偶图中两点之间的最近距离。在预处理阶段,需要计算并记录对偶图中所有顶点之间的最近距离。
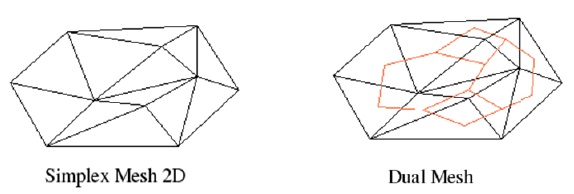
图:网格与对偶网格
Step 2:
选择相距最远的两个面片REPA和REPB作为两个分割区域的种子面片,对于面片fi计算其分别属于两个区域的概率,面片fi属于区域B的概率为:
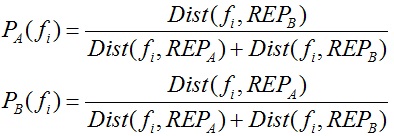
上式表明一个面片距离哪个区域更近,那么其属于哪个区域的概率更大。

图:概率分布图,红色点代表种子面片
Step 3:
利用模糊聚类的方法迭代更新两个区域的种子面片,具体如下:
1. 计算每个面片分别属于两个区域的概率;
2. 重新计算种子面片:
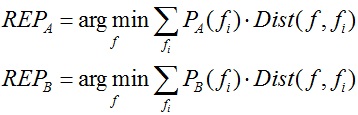
3. 迭代上述步骤直到种子面片不再发生变化。
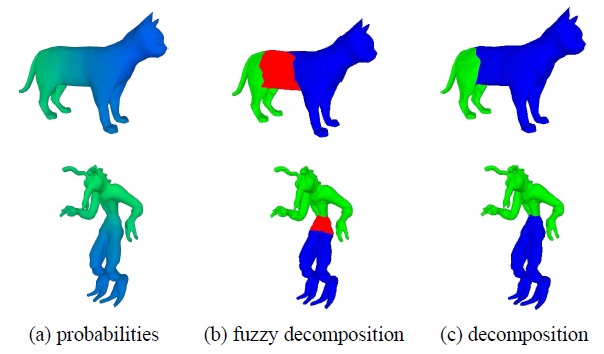
当迭代收敛之后,可以将网格分为3个区域A,B和C,其中C区域为模糊区域,对应下图b中的红色部分。
A = {fi | PB(fi) < 0.5 – ε}
B = {fi | PB(fi) > 0.5 + ε}
C = {fi | 0.5 – ε ≤ PB(fi) ≤ 0.5 + ε}
Step 4:
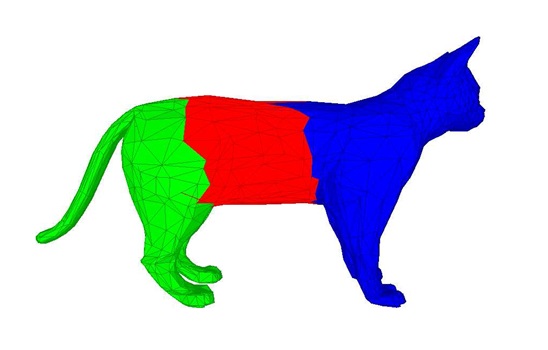
在模糊区域中利用最小割的方法寻找准确边界,首先需要构建模糊区域的网络s-t图G = (V, E)(如下图所示),V和E如下:
V = VC∪VCA∪VCB∪{S,T}
E = EC∪{(S, v), ∀v∈VCA}∪{(T, v), ∀v∈VCB}∪{eij∈E | i∈VC, j∈{VCA∪VCB}}
其中VCA和VCB代表对偶图中与VC相连的VA和VB顶点集,而VA, VB, VC为对偶图中A, B, C区域面片所对应的顶点集。
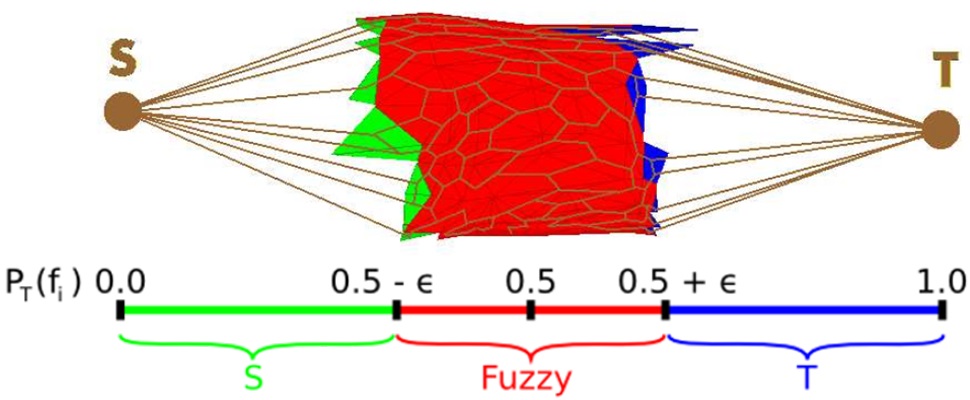
s-t图中边的容量定义为:
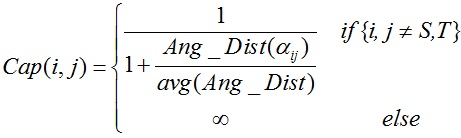
根据上述定义,网络图最小割的结果对应网格中模糊区域内二面角最大的分割边界。
如果模型需要分割成多个部分,可以对每个区域继续进行分割,直到满足终止条件。
参考文献:
[1] Sagi Katz and Ayellet Tal. 2003. Hierarchical mesh decomposition using fuzzy clustering and cuts. ACM Trans. Graph. 22, 3 (July 2003), 954-961.
附录
K-means算法:
给定一系列数据样本(x1, x2, … , xn),其中每个数据都是一个d维向量,K-means聚类算法的目标是将这n个数据样本归类成k(≤n)个簇,并且满足如下最小能量函数:

其中μi表示第i个簇Si中数据点的平均值 。
算法具体步骤:
1. 随机设定k个聚类中心点的初始值μ1(0), μ2(0), …, μk(0)。
2. 将每个数据点归类到离它最近的那个聚类中心点所代表的簇中。
3. 重新计算每个簇的聚类中心点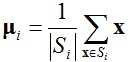 。
。
4. 重复第二步,直到迭代到最大步数或者前后两次能量函数的差值小于设定的阈值为止。
K-medoids算法:
K-medoids算法是K-means算法的一个变种,两者不一样的地方在于聚类中心点的选取。在K-means算法中,我们将中心点取为当前簇中所有数据点的平均值,而在K-medoids算法中,我们从当前簇中选取一个点作为聚类中心点,它满足到当前簇中其他所有点的距离之和最小。
在某些情况下,K-medoids聚类算法的结果要优于K-means算法,如下图所示,但从K-means算法变到K-medoids算法,时间复杂度会增加许多:K-means算法中计算聚类中心点只要求一个平均值O(N)即可,而在K-medoids算法中则需要枚举每个点,并求出它到所有其他点的距离之和,复杂度为 O(N2)。
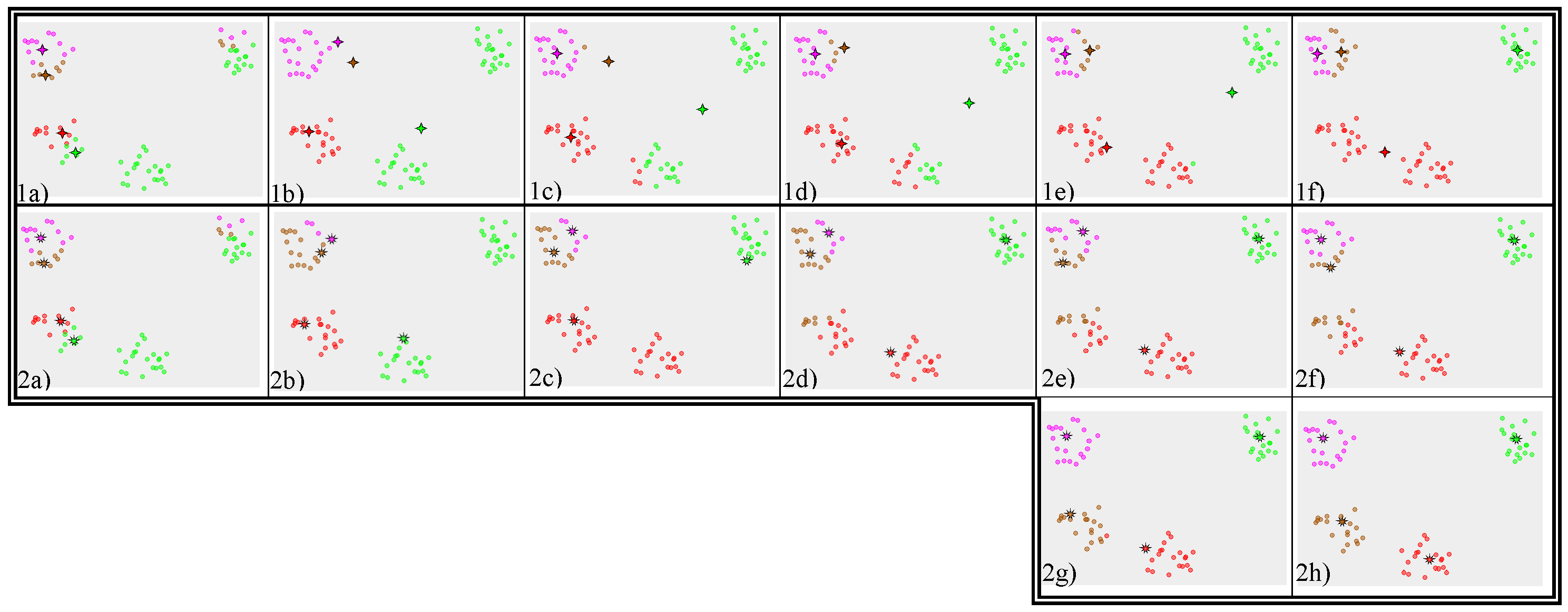
图:在相同的数据和初始条件下,K-means算法(1a - 1f)的结果陷入局部最优解,而K-medoids算法(2a – 2h)的结果更加合理
Max-flow/Min-cut算法
图论中一个常见的问题是网络图中两个节点之间的最大流是多少?这个问题具有重要的现实意义,例如交通工程师希望知道两个城市之间道路的最大通行能力是多少,因为这个信息将决定如何扩建道路,最大流问题的数学描述如下:
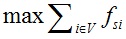
s.t. 
解决最大流问题的一个经典方法是Ford&Fulkerson算法,其方法如下:

我们以下图为例,解释Ford&Fulkerson算法的求解过程。网络图中边上方的标签代表该条边的最大容量,例如边AB上方靠近节点A的标签代表从节点A到节点B的最大容量,而靠近B节点的标签代表从节点B到节点A的最大容量。
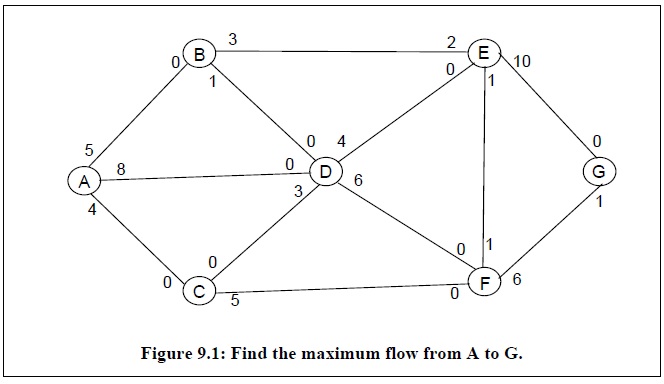
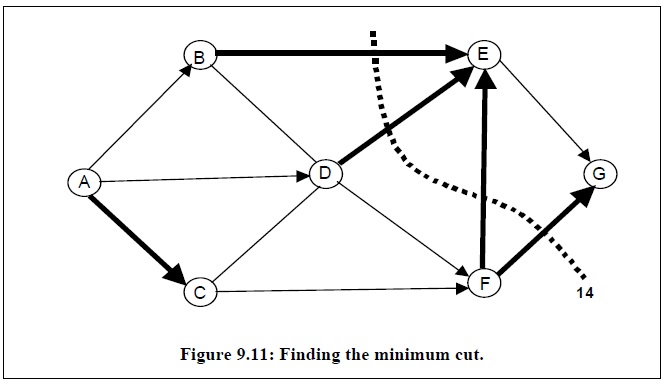
求解从节点A到节点G的最大流,首先需要在当前网络图中寻找从节点A到节点G的路径,接着建立残余网络图,即从当前网络图中减去该路径上的最大流量,然后重复上述步骤直到网络图中不存在从节点A到节点G的路径为止。
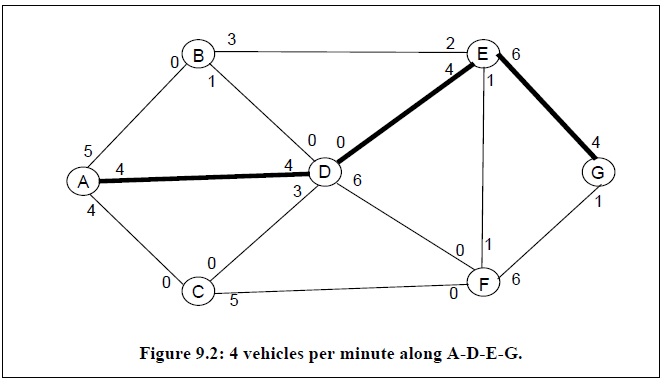
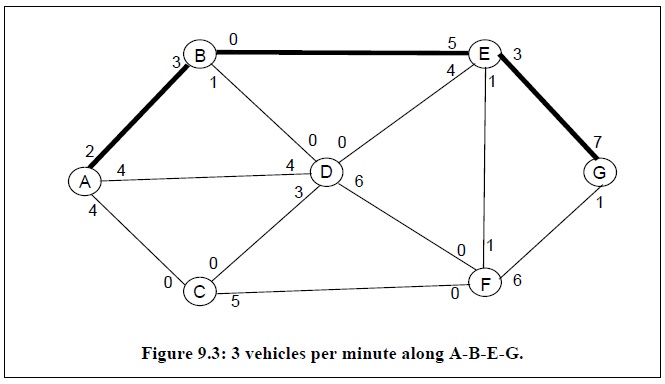
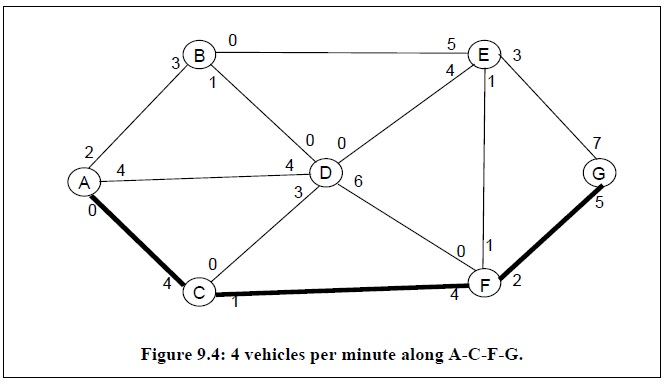
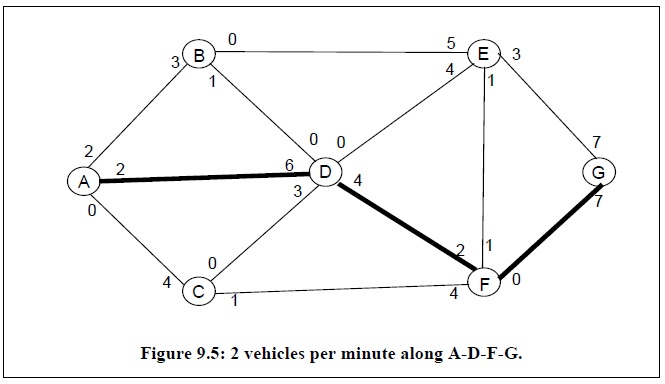

通过上述方法可以发现当算法终止时,可以寻找得到5条从节点A到节点G的路径,所以该网络图的最大流值为4+3+4+2+1=14。而最大流的网络图如下:
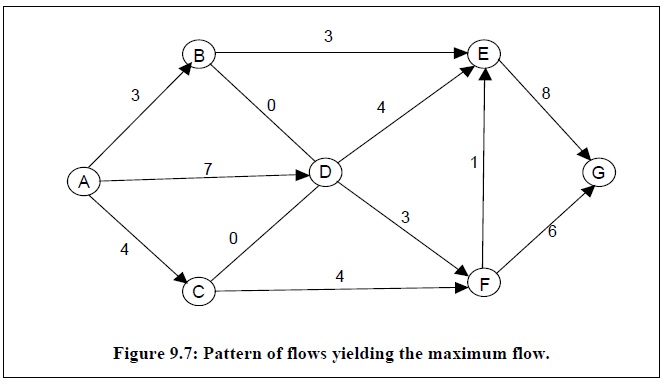
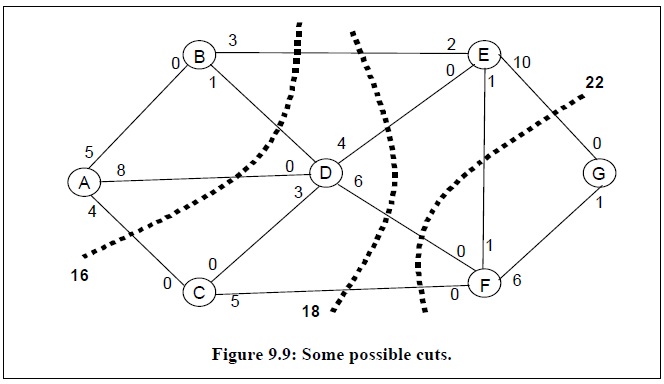
最大流问题与最小割问题密切相关,网络图中的割是指网络图中一些边的集合,当网络图中移除这些边时能够导致网络流中断,而最小割就是指所有割中权重之和最小的一个割,下图给出了网络图中一些割集的情况。最小割问题的数学描述如下:
最大流/最小割定理指出,网络图中从源点到汇点的最大流值等于网络图中的最小割值。但真正问题是最小割的边在网络图中的位置,因为假如交通工程师决定扩展道路,那需要知道该扩展哪些道路。可以想象扩展那些最大流值还未达到最大容量的那些边是毫无意思的,而那些最大流值已达到最大容量的边才是我们关心的,也就是最小割的位置。
本文为原创,转载请注明出处:http://www.cnblogs.com/shushen。
参考:
https://en.wikipedia.org/wiki/K-means_clustering
https://en.wikipedia.org/wiki/K-medoids
http://blog.pluskid.org/?page_id=78
http://www.sce.carleton.ca/faculty/chinneck/po/Chapter9.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号