大数据基础---rowkey的设计及rowkey如何匹配分配到各个分区上?
刚开始,新创建的表预分区:如图所示
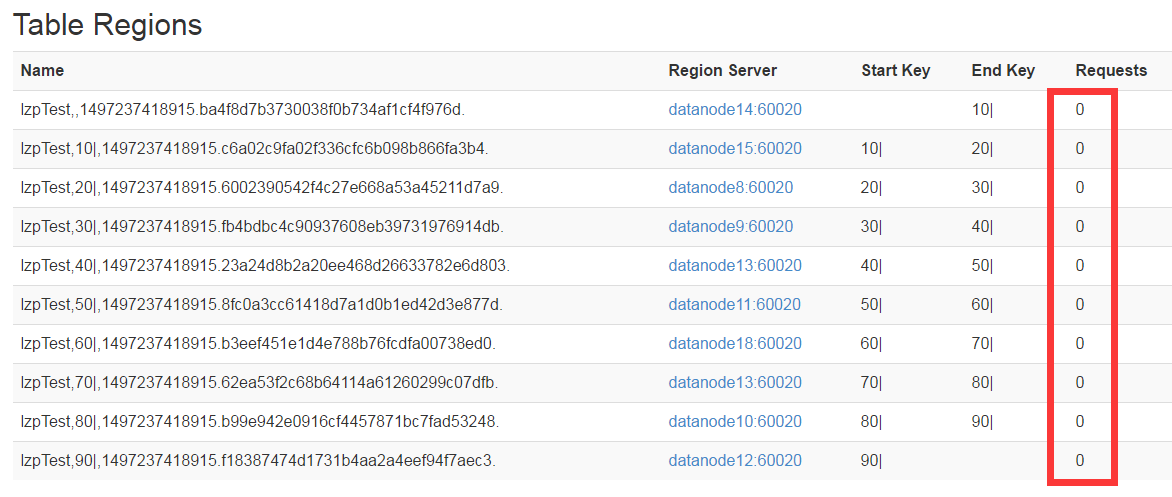
然后插入数据
import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.util.Bytes; public class InsertDateToTable { public static void main(String[] args) { String tableName = "lzpTest"; Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum","改成zookeeper节点"); HTable hTable=null; HBaseAdmin admin = null; try { admin = new HBaseAdmin(conf); hTable = new HTable(conf, tableName); //插入一条数据到hbase表中 Put put = new Put(Bytes.toBytes(10+System.currentTimeMillis()+"-"+111)); put.add("cf1".getBytes(), "name".getBytes(), "lzp".getBytes()); hTable.put(put); //批插入数据到hbase表中 // hTable.put(batchPut(10000)); System.out.println("插入成功!"); } catch (IOException e) { e.printStackTrace(); System.out.println("插入失败!"); } finally { if(hTable!=null) { try { hTable.close(); } catch (IOException e) { e.printStackTrace(); } } if(admin!=null) { try { admin.close(); } catch (IOException e) { e.printStackTrace(); } } } } /** * 产生随机数用于拼接Rowkey前缀 * @return */ public static String getRandomNumber() { String ranStr = Math.random()+""; int index = ranStr.indexOf("."); return ranStr.substring(index+1, index+3); } /** * 批插入数据 * @param num * @return */ public static List<Put> batchPut(int num) { System.out.println("开始插入数据。。。。"); List<Put> list = new ArrayList<>(); System.out.println("插入:"+num+" 数据!"); for(int i =0;i<num;i++) { //Rowkey组成:随机数+"-"+当前系统时间+"-"+i byte[] rowkey = Bytes.toBytes(getRandomNumber()+"-"+System.currentTimeMillis()+"-"+i); Put put = new Put(rowkey); put.add(Bytes.toBytes("cf1"), Bytes.toBytes("name"), Bytes.toBytes("lzp"+i)); list.add(put); } return list; } }
单独插入一条数据:“10+"-"+系统时间当前时间+"-"+111”
通过hbase web UI看到,我们的数据插入到了对应的分区中;
通过scan "lzpTest"查看数据:Rowkey是以10开头,并且插入到了以10结尾(StopKey=10)的分区中;

因此:我们可以这样简单理解,我们的分区stopkey是两位数,也只匹配Rowkey的前两位数(从高位开始匹配);
调用该方法,批量插入数据,查看是否存在热点问题,
hTable.put(batchPut(10000));
结果如下:
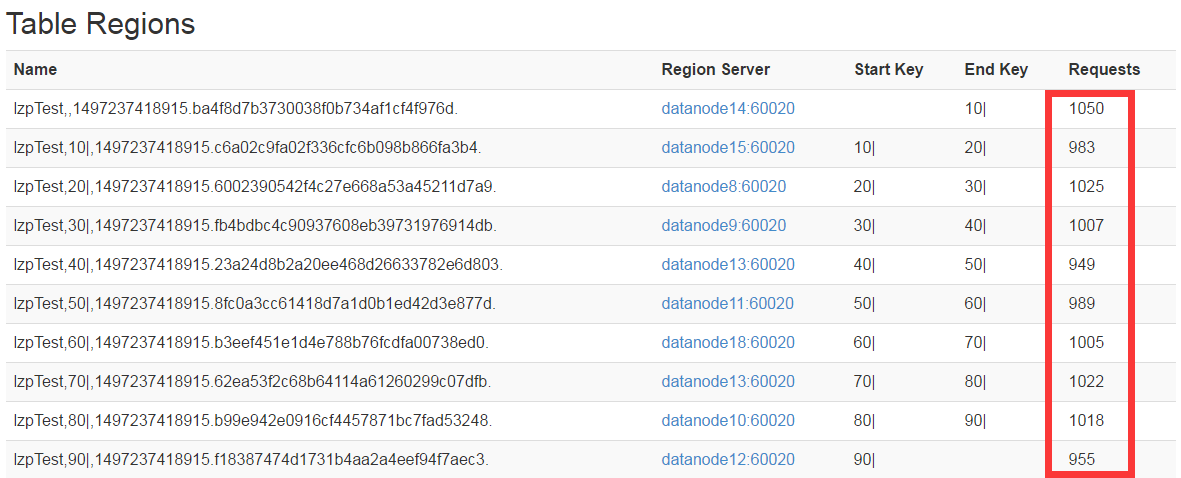
基本上均匀分布在各个节点上;从而很好的解决了热点问题的发生;
本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/13600746.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号