大数据基础---Map/Reduce,Yarn是什么?
简单概括:Map/Reduce是分布式离线处理的一个框架。 Yarn是Map/Reduce中的一个资源管理器。
一.图形说明下Map/Reduce结构:
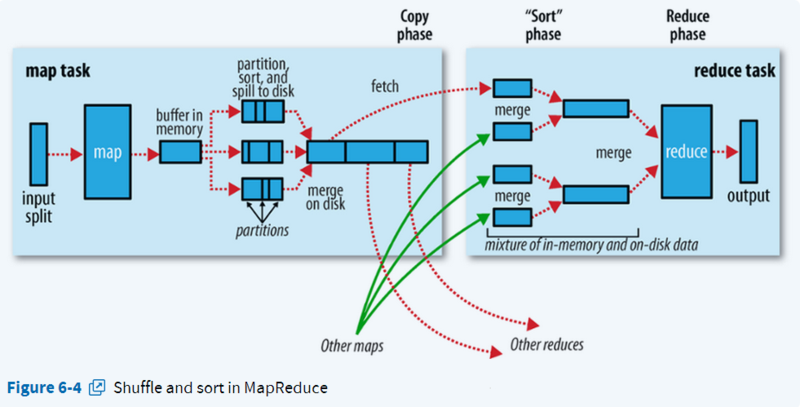
官方示意图:
另外还可以参考这个:
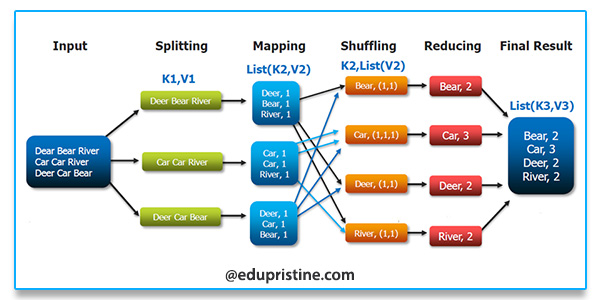
流程介绍:
HDFS首先会把块进行逻辑上切片处理,然后进行Map映射。一个切片对应一个Map映射。
因为文件内容有可能一个单词被切到两个文件里面,这样计算就会有问题,所以Map映射时除了第一个切片完全映射,其余的映射都会从第二行开始映射,而第一行传递给上一个Map处理。
Map程序初始化会设定一个阈值,比如80%,当超过这个值的时候就会就会进行内存溢出。溢出前会进行一个【快速排序】,排完后写入硬盘分区。(不设置阈值,当内存满后,就会阻塞数据继续写入。设定的阈值根据实际情况设定,太小了会增加读写压力,太大了会产生阻塞。)
程序可以设置合并操作,当分区数超过设定值后就进行合并(combiner)。(比如分区>3后)(合并后,相同key的数据就压缩了,拉取的时候就会减少IO)
Reduce会检查是否Map完,有一个Map完后就能拉取一次。
Reduce拉取的时候会有一个真迭代器和一个假迭代器进行嵌套,比如一组数据 A 1 A 1 A 1 B 1,假迭代器会进行循环然后取下一条数据进行比较看是否相同,相同的话进行累加值,再取下一条,这样下一条下一条的取,直到key不相同时候,结束本组循环,进行下一组循环。 这样A就统计出3,B就统计出1来了。
二.图形说明下Yarn的结构:
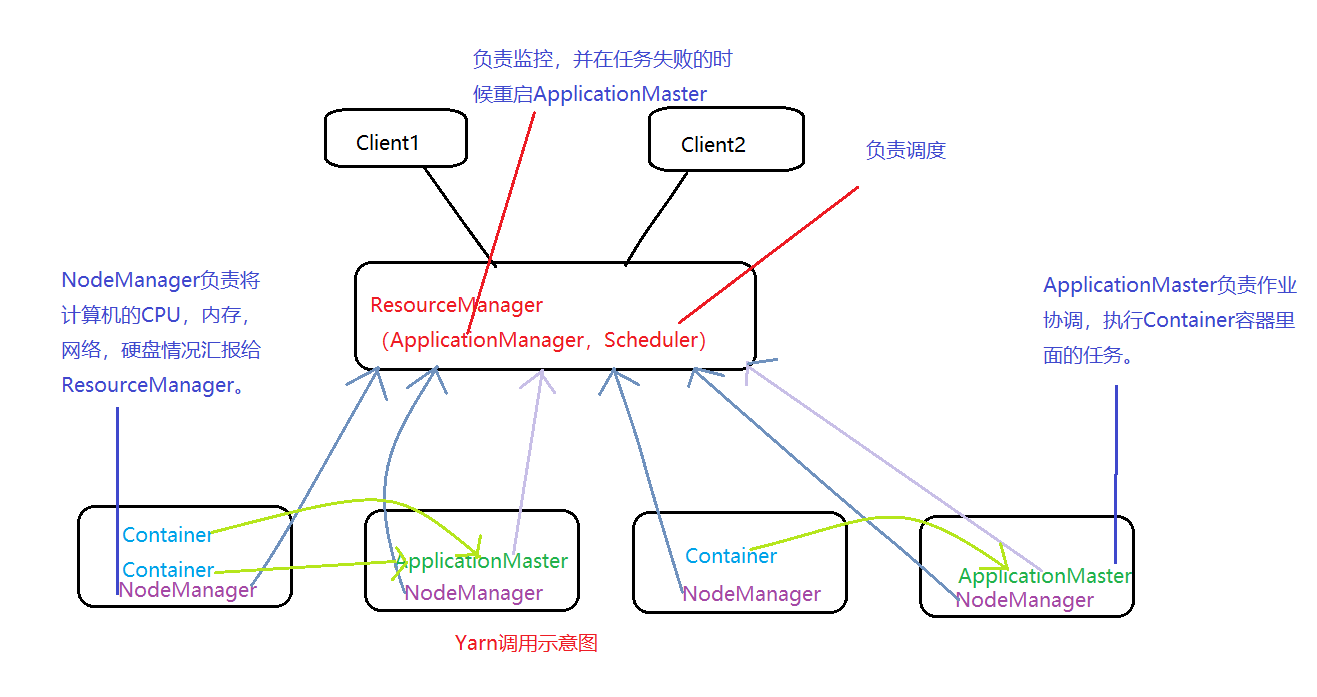
流程介绍:首先Client请求ResourceManager,然后ResourceManager分配一个Container启动ApplicationMaster,ApplicatoinMaster向ResourceManager请求分配更多Container。Container一部分执行Map任务,一部分执行Reduce任务。
三.图形说明下Map/Reduce和Yarn在整个Hadoop系统中的位置以及为什么产生Yarn:
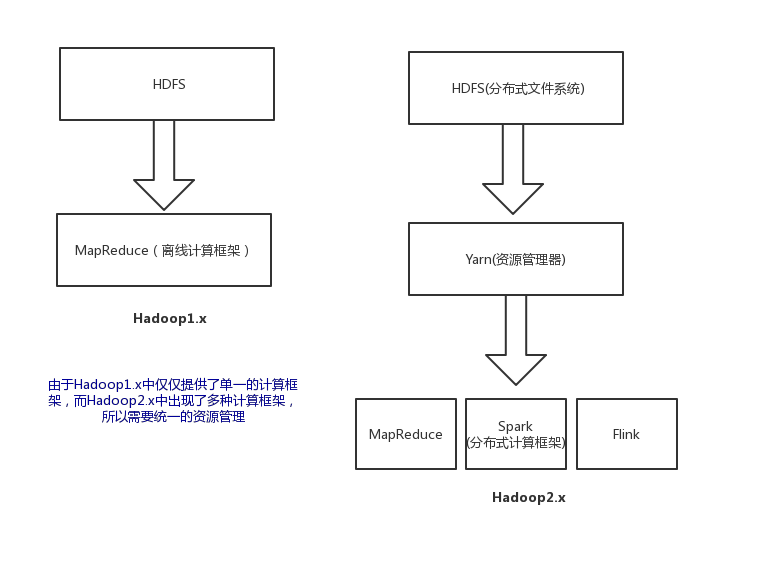
由于产生了多种计算框架,所以需要一个资源管理器来对资源进行分配使用。
本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/11576182.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号