

数据分析综述:联邦学习中的数据安全和隐私保护问题
©作者 | Doreen
01 联邦学习的背景知识
近年来,随着大量数据、更强的算力以及深度学习模型的出现,机器学习在各领域的应用中取得了较大的成功。
然而在实际操作中,为了使机器学习有更好的效果,人们不得不将大量原始数据送入模型中训练,这使得一些敏感数据被恶意的攻击者窃取。
因此,研究人员开始琢磨如何在保护数据安全和隐私的前提下提高机器学习的准确率。经过多年的探索,[1]提出了一个基于机器学习框架的联邦学习模型。
联邦学习模型的实现主要分为以下三个步骤:
1、模型选择:中央服务器先预训练一个模型,然后将整个模型(包括其初始参数)分享给所有的用户终端;
2、本地训练模型:用户接收到分发的模型后用各自的数据训练该模型,同时更新参数,然后将训练好的模型重新发送给中央服务器;
3、整合模型:中央服务器接收到各个用户的模型后将其整合成一个全局模型,然后再分享给各个用户终端。
通过以上三步不断迭代直至模型收敛为止。流程图如图1所示。
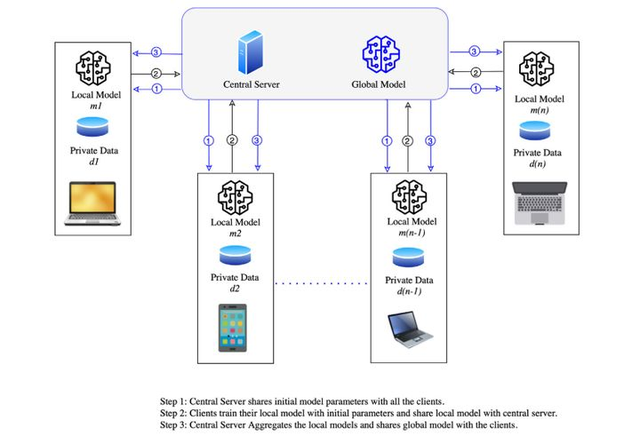
图1 联邦学习流程图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)
目前,联邦学习根据不同标准可以分为不同类别。按照网络拓扑结构,联邦学习可分为中心化和完全去中心化联邦学习。前者依赖一个中心服务器去分享、整合训练模型。
与传统的中心服务器不同,联邦学习的中心服务器通过实时或非实时的用户更新模型来整合全局模型,在此过程中不涉及到数据的传输。
完全去中心化联邦学习(网络拓扑图如图2所示)没有中心服务器和全局模型的概念,采用了端对端共享信息来更新用户模型。
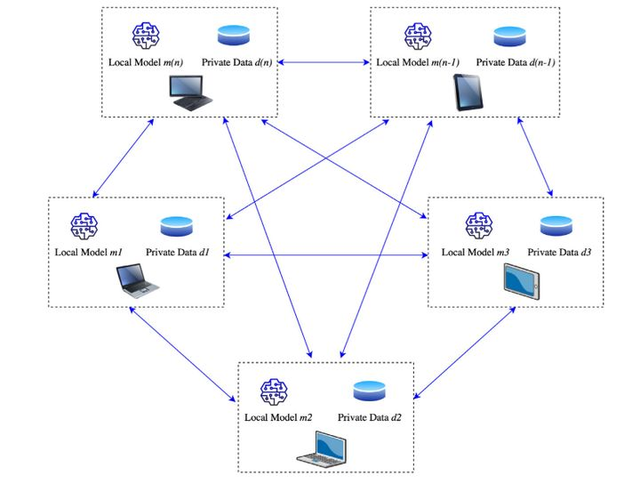
图2 完全去中心化联邦学习的网络拓扑图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)
按照数据分区来划分,联邦学习分为横向联邦学习、纵向联邦学习和联邦迁移学习。
其中,横向联邦学习(如图3所示)适用于同一领域的不同用户数据有着较多的相似特征。最经典的案例是谷歌的Gboard,当用户在手机键盘上输出一个词,利用横向联邦学习模型可以预测出用户想要输出的下一个词。
纵向联邦学习(如图4所示)适用于不同领域的用户拥有共同数据(数据特征不一致)的情况。最典型的案例是银行通过纵向联邦学习模型从不同用户的信用卡网购信息中学习到用户的购物喜好,并根据该信息为用户提供相关的刷卡折扣优惠同时优化自身的联邦学习模型。
联邦迁移学习(如图5所示)是指利用一个在相似数据集上训练好的模型作为初始模型去解决另一个完全不同的问题,其应用场景与纵向联邦学习的应用类似。在该模型中,全局模型在云服务器上运行,用户可以下载该模型并根据自己的需求更新模型,从而使得模型更加个性化。
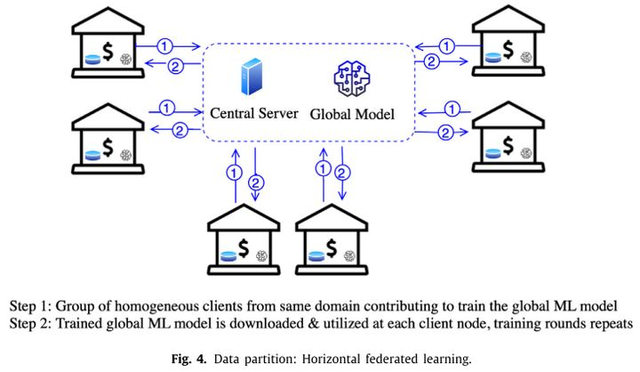
图3 横向联邦学习示意图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)

图4 纵向联邦学习示意图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)

图5 联邦迁移学习示意图(图片来自论文:Mothukuri Viraaji,Parizi Reza M.,Pouriyeh Seyedamin,Huang Yan,Dehghantanha Ali,Srivastava Gautam. A survey on security and privacy of federated learning[J].Future Generation Computer Systems,2021,115)
鉴于联邦学习模型在传递信息的过程中始终将原始数据保留在用户终端,其在数据安全和隐私保护方面有着较大的优势。
凭借该优势,联邦学习已经广泛应用于各个领域。在医疗领域,各个医疗机构都存储了大量的患者信息,这为实现精准医疗奠定了基础。
然而在实际应用过程中,为了提高机器学习模型的泛化能力,常常需要将不同机构的数据混在一起送入模型中训练,因此一些敏感信息很容易遭到泄露进而给患者带来一定的安全风险。
针对这个问题,联邦学习可以令中央服务器整合各个机构训练后的模型来生成一个全局模型分享给用户,不仅提升了模型的泛化能力,而且有效地保护了敏感信息。
除此之外,联邦学习在自动驾驶、恶意软件分类、入侵检测等方面也有着广泛应用。
02 联邦学习在数据安全和隐私保护方面国内外的研究进展
众所周知,系统中的漏洞使得一些恶意攻击者通过使用特定的技术就能轻松获取未授权的高级权限。一旦拥有了该权限,攻击者不仅可以窃取各种敏感数据,而且能够任意更改系统的配置来达到自己的目的。
因此,找到漏洞源头是维持系统安全稳定运行的前提条件。联邦学习作为一个分布式机器学习模型,可以部署到各种各样的终端上,其存在着一些与分布式系统类似的安全漏洞。
通过分析联邦学习模型的运行流程,可以将漏洞的来源确定为以下五个方面[1]:
①通信协议:联邦学习是一个反复迭代的模型,在学习过程中会随机选取一些客户端信息进行交互。由于存在多次的信息传递,不安全的通信信道成为漏洞的一个源头;
②用户数据操控:在一个大型的联邦学习环境中,众多终端都拥有一些敏感数据和模型参数,一旦被攻击者利用,攻击者可以凭借终端信息推测出全局模型并根据自己的目的任意更改模型,从而对模型输出结果的准确率造成一定的影响;
③受到安全威胁的中央服务器:中央服务器负责整合用户端上传的更新模型,并将原全局模型进一步更新后下发给各用户终端。若中央服务器遭到攻击者的破坏,全局模型的输出结果将会受到影响;
④弱聚合算法:聚合算法是整个联邦学习模型的核心,其通过对用户端模型的处理和整合,将原全局模型改进为个性化的全局模型。若算法的安全漏洞被攻击者所利用,其将不能识别恶意用户上传的错误模型,因此不能保证更新后的全局模型的有效性;
⑤联邦学习环境的实施者:由于缺乏敏感数据的定义和安全防护的标准,联邦学习的架构师、开发者们常常忽视了一些安全预控措施,导致自身成为安全隐患的源头。
(1)目前存在的数据安全和隐私保护方面的风险
攻击者们确定了漏洞的来源后,会针对不同漏洞的特点确定不同类型的攻击方案。一般而言,用户端是联邦学习中比较薄弱的部分,攻击者利用其弱点通过更改用户端模型参数来控制模型的训练过程,进而取得全局模型的控制权。
这类数据安全风险可以分为以下几类:
A、数据投毒
数据投毒是一种通过生成脏数据集来训练用户模型,然后将更新后的用户模型上传给中央服务器。由于脏数据集的输入使用户模型产生错误的模型参数,最终使得全局模型的有效性大受影响。[2]第一次提出了利用数据投毒攻击支持向量机。
这类攻击成功的关键是机器学习算法默认训练数据的分布符合常识。然而在实际情况中,攻击者利用一些恶意数据就可以推测出机器学习算法的决策方程,并根据此构建更巧妙的恶意数据混淆机器学习算法。
数据投毒的范围较广,主要包含数据注入、数据更改等多个子类。其中,数据注入指的是恶意用户将错误数据送入本地模型进行训练从而控制若干个本地模型的训练结果。
数据更改则是通过将若干个类别的数据混在一起作为训练样本来混淆本地训练模型,或者通过对训练数据的标签进行随机交换使模型的输出结果发生错乱。
B、模型投毒
模型投毒通常会更改用户终端更新后的模型,比数据投毒(更改数据)能更直接地作用于全局模型,因此其攻击效果也更有效[3]。[4]第一次研究了如何在抗拜占庭攻击的联邦学习中制造有效的攻击模型。
基本思路是攻击者控制了其中一个用户端的模型后对模型参数进行修改,再将其上传给服务器。攻击者通过操纵全局模型使其在测试任何示例时都具有较高的错误率,最终导致拒绝服务攻击。
在实际操作过程中,模型投毒的攻击性在用户终端足够多的大型联邦学习环境中比较明显。
C、后门攻击
相比投毒攻击的透明性,后门攻击具有一定的潜在性和不易觉察性。后门攻击是在全局模型正常运行的情况下注入了一个恶意程序,其本质上也是一个模型投毒攻击。
由于该恶意程序不会立即影响全局模型的输出结果,因此需要花很长时间才能对其进行鉴别。[5]详细介绍了如何对联邦学习框架进行后门攻击,主要关注了语义后门攻击。
语义后门不需要对样本进行修改即可出发后门攻击,相对于较弱的像素模式攻击,语义后门在大量部署联邦学习系统的环境中攻击力更强。
D、生成对抗性网络攻击
生成对抗性网络(GAN)是近几年发展较快的一个模型,利用该模型能发起投毒类型的攻击,给联邦学习系统的数据安全和隐私保护两方面均可造成一定的威胁。
[6]设计了一种针对协同深度学习的攻击,在该攻击模型中,攻击者可以在服务器正常工作时影响学习过程,并通过引入协同学习中的欺骗概念诱导其他用户欺骗受害者,使其发布自己的敏感数据。
由于基于GAN的攻击通常是不能被预见的,因此该攻击是一种影响力和优先级都较高的攻击方式。
E、搭便车攻击
搭便车攻击是一种被动的攻击方式,指的是参与联邦学习的用户只利用全局模型来更新自己的本地模型而拒绝向全局模型提供有价值的本地信息。由于缺乏一些有用的客户端信息改进全局模型,这种攻击对于小型联邦学习模型的输出结果影响较大。
但在实际场景中,各个用户端都想利用泛化性能强大的全局模型优化自己的本地模型,因此出现搭便车攻击的几率较小,其安全风险也比上面几种攻击的风险较低。
除了上述数据安全方面的攻击外,联邦学习系统本身也存在着隐私泄露的问题。虽然在整个系统中尽可能减少了数据的流通,但一些攻击者还是能够利用用户终端相互传递的模型信息来猜出用户端数据。
目前联邦学习所涉及的隐私保护方面的攻击主要包括以下几种:
A、成员推理攻击[7]

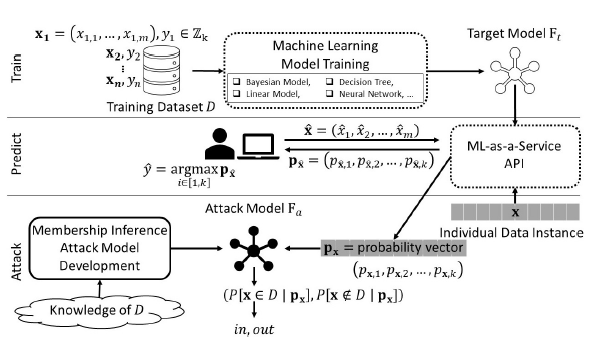
图6 成员推理攻击流程图(图片来自论文:S. Truex, L. Liu, M. E. Gursoy, L. Yu and W. Wei, "Demystifying Membership Inference Attacks in Machine Learning as a Service," in IEEE Transactions on Services Computing, vol. 14, no. 6, pp. 2073-2089, 1 Nov.-Dec. 2021)
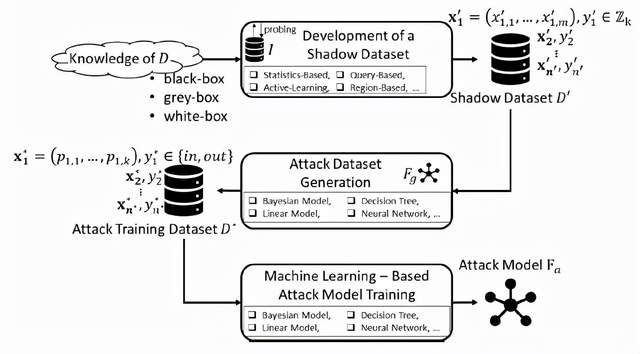
图7 成员推理攻击模型(图片来自论文:S. Truex, L. Liu, M. E. Gursoy, L. Yu and W. Wei, "Demystifying Membership Inference Attacks in Machine Learning as a Service," in IEEE Transactions on Services Computing, vol. 14, no. 6, pp. 2073-2089, 1 Nov.-Dec. 2021)
B、基于GAN的推理攻击
GAN近年来广泛应用于机器视觉领域,利用其优点,B. Hitaj[8]等人第一次提出了基于GAN的重构攻击模型(如图8所示)。在该模型中有受害人V和攻击者A两个参与者,首先令V训练模型。
V从中央服务器下载了一些参数来更新自己的本地模型(本地模型由带有标签a,b的数据集来训练),然后将更新后的模型参数重新上传给服务器;接着令攻击者A训练模型。
A首先也从中央服务器下载了一些参数更新自己的本地模型(该模型对于受害者是不可知的)使其输出结果的标签逐渐接近受害者的a标签,同时通过训练自己的攻击模型令其生成带有标签c的数据集。
然后利用带有标签b,c的数据集训练攻击模型,并将更新后的本地模型参数上传给服务器。通过攻击者和受害者两人不断重复上述过程直至模型收敛为止。
虽然基于GAN的推理攻击模型在一定程度上成功地推理出了受害者的训练样本,但是由于攻击者对全局模型的影响会随着对上传的本地模型参数的平均整合而逐渐减弱,其在联邦学习系统中的表现并不理想。
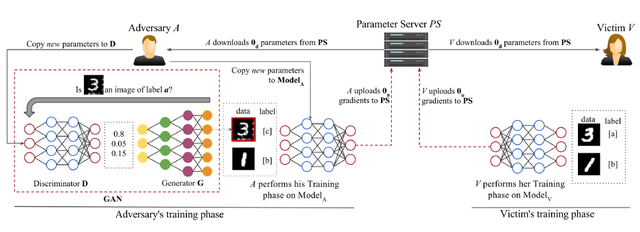
图8 基于GAN的攻击模型(图片来自论文:B.Hitaj, G.Ateniese, F.Perez-Cruz,"Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning," in Proc of ACM CCS. ACM,2017)

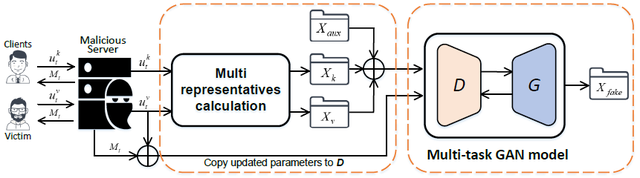
图9 基于mGAN-AI的攻击模型(图片来自论文:Z Wang,M Song,Z Zhang,Y Song,Q Wang,H Qi,Beyond Inferring Class Representatives: User-Level Privacy Leakage from Federated Learning,in: IEEE INFOCOM 2019-IEEE Conference on Computer Communications,2019)
(2)相关解决方案
联邦学习系统中数据安全漏洞的防御方法主要有主动式和被动式两大类。
主动式防御主要通过猜测可能出现的安全风险的类型来尝试利用相关的技术进行防御。
被动式防御则是确定了攻击类型后,再针对性地进行漏洞修补工作。
目前广泛使用的防御方法主要有以下几种:
A、数据清理
由于现实场景中某些训练数据集的质量无法保证,使得模型无法通过对这部分数据的学习识别出潜在的攻击,因此[10]提出了利用异常检测探测器过滤出可疑的训练数据。
作者提出了在异常检测探测器的训练过程中加入数据清理的操作,生成了许多小模型,并利用这些模型为数据添加临时标签。接着将这些模型与投票策略结合起来判定哪些训练数据可能来源于攻击方。
此外,为了提升数据清理的效果,[11]引入了统计学中的相关知识。通过观察受污染额数据的出现过程对训练样本输出结果的影响,作者提出了迭代修正损失最小化的方法,为理解训练结果的发展趋势提供了进一步的认识。
虽然数据清理在一定程度上有效地防御了数据投毒攻击,但是[12]发现,数据清理在一些高级别的数据投毒攻击中效果并不明显。
B、异常性探测
异常性探测通过学习正常样本的统计分部等特性来找出可疑的数据,常常被用来防御数据投毒和模型投毒之类的攻击。
在联邦学习中,不同种类的数据投毒、模型投毒会用到不同方式的异常性探测技术。
[13]中作者在聚合用户端数据之前对每个用户端更新的数据进行聚类操作。聚类算法中用到了欧氏距离来探测可疑的用户数据并将其剔除。
[4]通过系统性地研究抗拜占庭攻击的联邦学习(即在联邦学习系统中参与者存在不可信任的情况下保证系统的安全运行)提出了两种防御方法——基于错误率的拒绝(ERR)(即移除对全局模型错误率影响较大的数据集)和基于损失函数的拒绝(LFR)(即在一个训练集中寻找一个子集最小化该损失函数,子集外的数据都视为可疑数据)。
[14]从新的角度出发提出了一个基于频谱异常检测的框架来探测异常模型,在主要特征不受影响的前提下剔除掉一些噪声和与目标不相关的特征。
频谱异常探测模型结合了变分自编码器和动态阈值的方法,能兼容无监督和半监督学习场景,在恶意模型未知或者不能提前预判情况下的联邦学习系统中表现较好。
C、知识蒸馏
知识蒸馏是模型压缩技术的一个变形,其利用知识分享取代了模型参数分享,在联邦学习系统中不仅可以针对推理攻击、基于GAN的攻击以及投毒攻击等进行有效防御,而且在实际应用中降低了模型训练的计算开销。
[15]将迁移学习和知识蒸馏技术结合起来,提出了一种新的联邦学习框架使用户端能够独立设计自己的本地模型,主要分以下四个步骤:
①用户从共享数据集中选择一部分数据并结合自己的本地数据训练本地模型,并将模型预测结果的评分发送给中央服务器;
②服务器对各个客户端传送的数据分别求平均分数,然后根据各用户端模型的权重整合平均分数来更新全局模型;
③用户端下载全局模型的平均分数,并利用知识蒸馏的方法用共享数据集在本地模型上拟合得到该平均数;
④各用户端在本地模型上训练本地数据集同时更新本地模型。
以上四步重复进行直到全局模型收敛为止。该框架的提出不仅使用户端根据自身需求训练出合适的模型,而且通过传输训练结果的平均分数保证了用户数据的安全。
由于用户端存在着大量敏感数据,因此找到保护用户端数据隐私的方法是联邦学习中隐私保护的关键。
现有的隐私保护算法主要基于多方安全计算和差分隐私两大类。
A、多方安全计算
多方安全计算是R.Canetti等人首次提出的,主要用于保护参与合作的各用户端的输入数据。在此过程中,用户端之间通过加密方法保护各自的敏感数据。
近年来,随着联邦学习的发展,多方安全计算被改进后迁移到该系统中,通过加密参数来保护敏感数据。由于参数的数量比数据的规模少了好几个数量级,因此大大减少了计算开销。
虽然计算开销方面的问题得到了一定缓解,但随着研究人员的不断探索,发现传递少量的模型梯度信息也能泄露原始数据。
针对这个问题,L. T. Phong等人[16]提出了在深度学习系统中对所有的梯度信息进行同态加密后将其保存到云服务器上,以此来解决数据泄露问题。
在该系统(如图10所示)中,有一个中央服务器和N个用户终端,用户端共同设置了公钥pk和私钥sk。其中私钥sk对于云服务器是不可知的,而对于所有用户端是透明的。
每个用户端都各自建立一个特有的TLS/SSL安全信道保证通信和同态加密的数据的完整性。
在系统运行过程中,用户端主要执行以下四个步骤:
1、从服务器中下载加密后的所有密文(包括加密后的全局模型权重);
2、利用自己的私钥sk对密文进行解密,并将解密后的权重替换本地模型中相对应的权重;
3、从本地数据中拿出一部分数据,利用更新后的权重去训练本地模型;
4、对更新后的本地模型的梯度信息进行同态加密,并将其送入服务器中。
在上述过程中,用户端向服务器只发送了加密的梯度,若能保证加密方案是CPA安全的,则不会出现用户端数据泄露的情况。
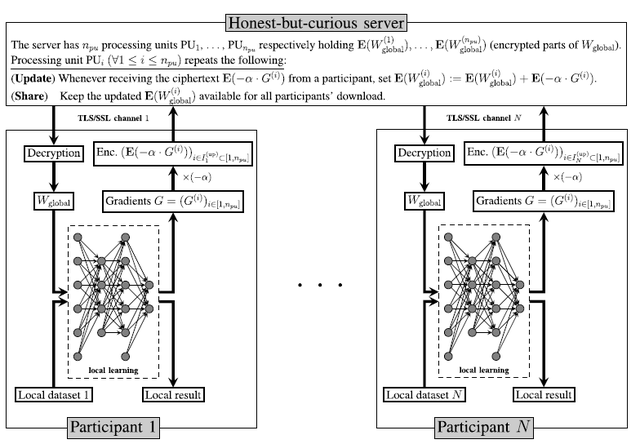
图10 基于异步梯度加密的深度学习模型(图片来自论文:L. T. Phong, Y. Aono, T. Hayashi, L. Wang and S. Moriai, "Privacy-Preserving Deep Learning via Additively Homomorphic Encryption," in IEEE Transactions on Information Forensics and Security, vol. 13, no. 5, pp. 1333-1345, May 2018)
B、差分隐私
差分隐私技术最早由微软研究者Dwork于2006年提出,其利用随机噪声将原始数据淹没在其中,使攻击者无法从数据库中反推出原始数据。
鉴于差分隐私在数据隐私保护方面的优势,研究人员将其迁移到联邦学习系统中,通过将差分隐私和其他技术相结合,产生了许多隐私保护方面的模型。
研究人员[17]提出了一种DPGAN模型,将差分隐私技术应用到GAN模型中,解决了GAN模型泄露训练样本的潜在风险。
与其类似的DPFedAvgGAN[18]将生成模型、联邦学习和差分隐私三项技术结合起来解决了样本的隐私保护问题。
在DPFedAvgGAN中,生成模型利用深度学习了解原始数据的联合分布并根据该分布生成特定的样本;联邦学习负责训练并评价数据同时进一步优化生成模型;差分隐私和联邦学习最后通过协同作用为用户端的数据隐私提供保护。
此外,还有部分研究[19,20]将多方安全计算和差分隐私结合起来,在不损失用户端数据隐私的前提下保证了输出结果的准确率。
C、对抗性训练
除了以上两类常用的防御技术外,对抗性训练技术也能有效地进行防御。对于攻击者向模型注入恶意样本来混淆机器学习模型的情况,对抗性训练是一个很好的解决方案。
作为一种主动的防御方法,对抗性训练从训练阶段就提升了模型的鲁棒性,使其能辨认出各种形式的攻击方式。
其中最典型的例子是Anti-GAN[21]模型。Anti-GAN利用WGANs在用户端生成了虚假的训练样本,在一定程度上减少了推理攻击的风险。
类似的FedGP[22]框架通过FedAvg算法训练生成模块(负责生成虚假样本),然后利用预期的隐私损失评价数据泄露的风险。通过对对抗性训练的充分研究,[23]发现对抗性训练对于黑盒攻击仍然表现不佳。
为了解决这个问题,研究人员引入了集成对抗性训练,即利用数据增广对训练样本增加一定的扰动。实验发现对抗性训练通过减少推理攻击的风险有效地保护了用户端的数据隐私。
此外,针对联邦学习在移动终端应用中带来的隐私泄露问题,[24]提出了一新的框架FEDXGB,充分利用秘钥共享技术和为全局模型提供安全提升、安全预测等协议保证了数据隐私不被泄露。
03 现阶段联邦学习安全方面面临的挑战和相关的解决思路
(1)面临的挑战
考虑到联邦学习的目的是让中央服务器建立一个能反映目标特性的全局模型,同时限制服务器通过上传的数据重构用户的敏感数据,这就需要弄清楚哪些数据是敏感数据以及该数据的隐私级别。
针对联邦学习系统中的安全风险,本文总结了以下几个挑战[25]:
A、本地差分隐私
传统的差分隐私是将各方的原始数据集中到一个可信的数据中心,对计算结果添加噪声后进行差分隐私。
由于难以找到可信的数据中心,因此提出了利用本地差分隐私直接在用户数据集上做差分隐私,然后将其传到数据中心进行整合,这样就避免了原始数据的泄露问题。
虽然本地差分隐私在理论上证明了隐私保护的有效性,但是由于随机噪声的引入必须和原始数据相匹配,这需要整合用户之间的数据,因此本地差分隐私在高维数据的应用中还是面临着一些挑战[26-28]。
B、混合模型的差分隐私
混合模型是根据用户的信任偏好划分的多个模型,一般分为两类——一是采用最少信任并提供最低实用性的模型,该模型可以应用在所有用户端;二是采用最信任并提供很高实用性的模型,但这种模型只能应用在值得信任的用户上。
在联邦学习系统中采用混合模型的差分隐私能在减少用户基数的同时不提供本地添加噪声的隐私放大。
目前关于混合模型的差分隐私是基于用户数据都来源于同一个分布[29-30]的假设。但在实际场景中,因为用户偏好和数据之间的关系比较密切,因此有必要放宽这个假设来提升模型的实用性。
C、置乱模型
在联邦学习系统中,若用户是匿名的,置乱模型可以降低本地模型引入的噪声,实现隐私放大效应。
虽然置乱模型可以通过弱化攻击者的模型使差分隐私问询的准确性进一步提升,但其自身存在两个缺点。
第一,置乱模型缺乏一个可信的中间人。如果用户不信任中央服务器,他们也不可能信任服务器授权的中间人。
第二,置乱模型的差分隐私保证在计算过程中随着参与攻击者数目的增加而减弱。由于攻击者的数目对于服务器和用户端都是不可知的,这就为用户数据的隐私保护带来一些不确定因素。
D、安全聚合协议
通过聚合用户端上传的数据来更新全局模型一直是联邦学习的核心问题。理想的安全聚合算法能够识别用户上传的异常更新数据,并在聚合过程中丢弃这些数据来保证全局模型输出的准确性。
在早期的联邦学习中,参数服务器直接将明文形式的梯度通过求和或者取平均值的方式聚合在一起,这样虽能防止数据的直接泄露,但会让攻击者很容易获得用户端的敏感数据。
针对这个问题,研究人员提出了各种类型的安全聚合协议有效地应用到联邦学习中。但在实际应用中,[31]部分安全协议还是存在以下几个缺陷:
①大多数安全聚合协议都是在半诚实模型的假设上设计的;
②允许服务器监控每轮训练的聚合过程,在此过程中有泄露敏感数据的风险;
③部分安全聚合协议对于稀疏向量的聚合表现不佳;
④缺乏强制用户规范输入数据的能力。
(2)解决思路
1.理解特定场景下隐私保护的需求从而制定相应的措施
由于目前部分联邦学习系统需要从用户端接收大量高纬度数据来处理复杂的学习任务,为了在保证数据安全的前提下按时完成相应的任务,需要在安全和计算开销方面做一个折中。
在实际情况中,用户端的所有数据并非都是敏感数据,可以考虑弄清各种场景下用户数据的隐私保护级别后,以牺牲部分非重要的数据来减少不必要的计算开销。
例如一个企业拥有一个大量的员工薪资数据库,每个员工对应的具体薪酬是敏感数据。对于企业的数据隐私保护而言,只用采取措施避免数据库中员工姓名和对应的薪酬这两个维度的信息不泄露,即使牺牲其他非重要数据也可以高效地利用联邦学习系统完成相关的任务。
又如在智能家居应用中,自动调温器通过特定的程序识别到家里有人或无人时将其开启或关闭,这些数据对于业主来说都是敏感数据,一旦被攻击者获取将会威胁业主的安全。
因此,根据隐私保护的需求只泄露部分不敏感的数据(如室内的温度等)即可在保证用户安全的前提下降低调温器处理大量数据的计算开销。
[32]中提供了隐私保护的框架,分析者可以参考该框架并结合自身对敏感数据的判断对数据提供差异性的隐私保护。
此外,联邦学习框架可以稍作修改,令终端用户自己决定允许的推理攻击,并把其整合到全局模型中为用户提供更精准的服务。
2.利用行为研究制定相应的隐私保护机制
隐私保护很大程度上取决于用户是否能明确地制定出自身的隐私标准。为了达到这个目的,可以从教育和个人偏好两方面[25]对目标群体进行行为研究。
通过教育可使用户明确隐私保护方面的相关技术和数据的使用过程。教育的目的达到后,需要从个人偏好方面使用户提供能代表目标群体特征的高质量数据。
由于实验条件的限制,目前在行为研究方面的文献[33]较少。鉴于行为研究可以对用户提供差异性的隐私保护,其未来将会广泛地应用于联邦学习系统中。
参考文献
[1] MOTHUKURI, VIRAAJI, PARIZI, REZA M., POURIYEH, SEYEDAMIN, et al. A survey on security and privacy of federated learning[J]. Future generations computer systems: FGCS,2021. DOI:10.1016/j.future.2020.10.007.
[2] B. Biggio, B. Nelson, P. Laskov, Poisoning Attacks against Support Vector Machines,
https://arxiv.org/abs/1206.6389
[3] AN Bhagoji,S Chakraborty,P Mittal,S Calo, Analyzing Federated Learning through an Adversarial Lens,
https://arxiv.org/abs/1811.12470v4
[4] Minghong Fang, Xiaoyu Cao, Jinyuan Jia, Neil Zhenqiang Gong, Local Model Poisoning Attacks to Byzantine-Robust,
https://arxiv.org/abs/1911.11815v1
[5] E Bagdasaryan,A Veit,Y Hua,D Estrin,V Shmatikov, How To Backdoor Federated Learning,
https://arxiv.org/abs/1807.00459v3
[6] Briland Hitaj,Giuseppe Ateniese,Fernando Perez-Cruz, Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning,
https://arxiv.org/abs/1702.07464v3
[7] S. Truex, L. Liu, M. E. Gursoy, L. Yu and W. Wei, "Demystifying Membership Inference Attacks in Machine Learning as a Service," in IEEE Transactions on Services Computing, vol. 14, no. 6, pp. 2073-2089, 1 Nov.-Dec. 2021, doi: 10.1109/TSC.2019.2897554.
[8] B.Hitaj, G.Ateniese, F.Perez-Cruz,"Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning," in Proc of ACM CCS. ACM,201
[9] Z Wang,M Song,Z Zhang,Y Song,Q Wang,H Qi,Beyond Inferring Class Representatives: User-Level Privacy Leakage from Federated Learning,in: IEEE INFOCOM 2019-IEEE Conference on Computer Communications,2019,pp.2512-2520
[10] G. F. Cretu, A. Stavrou, M. E. Locasto, S. J. Stolfo and A. D. Keromytis, "Casting out Demons: Sanitizing
Training Data for Anomaly Sensors," 2008 IEEE Symposium on Security and Privacy (sp 2008), 2008, pp. 81-95, doi: 10.1109/SP.2008.11.
[11] Y Shen,S Sanghavi, Learning with Bad Training Data via Iterative Trimmed Loss Minimization,
https://arxiv.org/abs/1810.11874v2
[12] Koh, P.W., Steinhardt, J. & Liang, P. Stronger data poisoning attacks break data sanitization defenses. Mach
Learn (2021).
https://doi.org/10.1007/s10994-021-06119-y
[13] Shen, S., Tople, S., & Saxena, P. (2016). Auror: defending against poisoning attacks in collaborative deep learning systems. Proceedings of the 32nd Annual Conference on Computer Security Applications.
[14] S Li,Y Cheng,W Wang,Y Liu,T Chen,Learning to Detect Malicious Clients for Robust Federated Learning,
https://arxiv.org/abs/2002.00211
[15] D Li,J Wang, FedMD: Heterogenous Federated Learning via Model Distillation,
https://arxiv.org/abs/1910.03581
[16] Phong, Le Trieu; Aono, Yoshinori; Hayashi, Takuya , Privacy-Preserving Deep Learning via Additively Homomorphic Encryption, doi: 10.1109/TIFS.2017.2787987
[17] L Xie,K Lin,S Wang,F Wang,J Zhou, Differentially Private Generative Adversarial Network,
https://arxiv.org/abs/1802.06739
[18] S Augenstein,et al, Generative Models for Effective ML on Private, Decentralized Datasets,
https://arxiv.org/abs/1911.06679v2
[19] Stacey Truex, Nathalie Baracaldo, et al, A Hybrid Approach to Privacy-Preserving Federated Learning,
https://arxiv.org/abs/1812.03224
[20] M. Hao, H. Li, G. Xu, S. Liu and H. Yang, "Towards Efficient and Privacy-Preserving Federated Deep Learning," ICC 2019 - 2019 IEEE International Conference on Communications (ICC), 2019, pp. 1-6, doi: 10.1109/ICC.2019.8761267.
[21] X. Luo,X. Zhu,Exploiting Defenses against GAN-Based Feature Inference Attacks in Federated Learnin (2020).arXiv:2004.12571
[22] A Triastcyn,B Faltings, Federated Generative Privacy,
https://arxiv.org/abs/1910.08385v1
[23] Florian Tramèr, Alexey Kurakin, et al, Ensemble Adversarial Training: Attacks and Defenses,
https://arxiv.org/abs/1705.07204
[24] Z. Wang, Y. Yang,Y. Liu,X. Lin,B.B.Gupta, J.-F.Ma, Cloud-based federated boosting for mobile crowdsensing. ArXiv abs/2005.05304
[25] Peter Kairouz, et al, Advances and Open Problems in Federated Learning,
https://arxiv.org/abs/1912.04977
[26] J. C. Duchi, M. I. Jordan and M. J. Wainwright, "Local privacy and statistical minimax rates," 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), 2013, pp. 1592-1592, doi: 10.1109/Allerton.2013.6736718.
[27] Kairouz, Peter,Oh, Sewoong,Viswanath, Pramod, Extremal Mechanisms for Local Differential Privacy,
https://arxiv.org/abs/1407.1338v1
[28] M. Ye and A. Barg, "Optimal Schemes for Discrete Distribution Estimation Under Locally Differential Privacy," in IEEE Transactions on Information Theory, vol. 64, no. 8, pp. 5662-5676, Aug. 2018, doi: 10.1109/TIT.2018.2809790.
[29] A Beimel,A Korolova,K Nissim,O Sheffet,U Stemmer, The power of synergy in differential privacy: Combining a small curator with local randomizers,
https://arxiv.org/abs/1912.08951v2
[30] B Avent,Y Dubey,A Korolova, The Power of The Hybrid Model for Mean Estimation,
https://arxiv.org/abs/1811.12040
[31] Keith Bonawitz,Vladimir Ivanov,et al, Practical Secure Aggregation for Privacy-Preserving Machine Learning, Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, October 2017; Pages 1175–1191;
https://doi.org/10.1145/3133956.3133982
[32] D Kifer,A Machanavajjhala, Pufferfish: A framework for mathematical privacy definitions, ACM Transactions on Database Systems, Volume 39, Issue 1, January 2014, Article No.: 3pp 1–36
https://doi.org/10.1145/2514689
[33] ABOWD, JOHN M., SCHMUTTE, IAN M.. An Economic Analysis of Privacy Protection and Statistical Accuracy as Social Choices[J]. The American Economic Review,2019(1). DOI:10.1257/aer.20170627.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号