


xml -> csv
https://www.cnblogs.com/pacino12134/p/11291398.html
1、xml
使用labelmg工具对图片进行标注得到xml格式文件,以图片为例介绍内容信息:

对上面的图片进行标注后,得到xml文件:
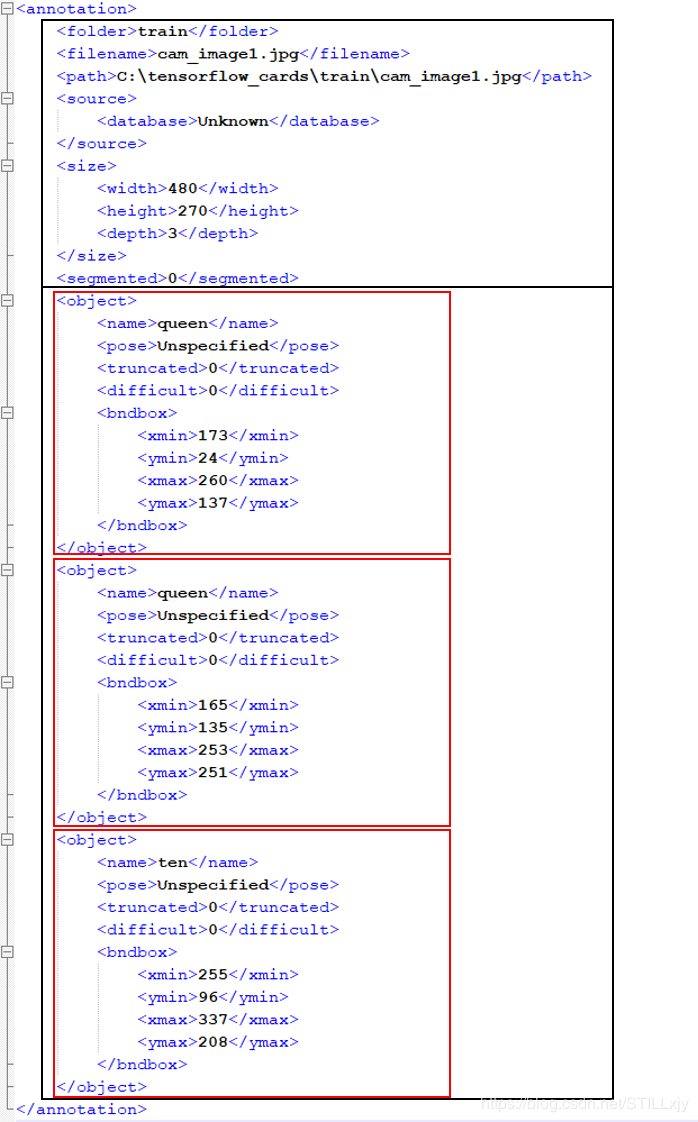
其内容分类两部分:
- 第一个黑色方框,图像的整体部分,包括图像的名称、位置、长宽高等等;
- 第二个黑色方框,标注框信息,每个红色框就是一个object标签(表示一个标注框)的信息,包括目标类别名称、位置信息等
xml内的信息是由一个个对象组成,标签之间存在层级关系,例如annotation为最上层的标签,就是这个xml所在的文件夹,其他标签为字标签。
2、xml -> csv
字符(逗号)分割值。
每个object标签代表一个标注框,都会在csv文件中生成一条数据,每天数据的属性为:图片文件名、宽度、高度、类别、框的左上角x坐标、框的左上角y、框的右上角x、框的右上角y。
xml转csv的代码如下:

# -*- coding: utf-8 -*-
"""
将文件夹内所有XML文件的信息记录到CSV文件中
"""
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path): #path:annotations的文件夹路径
xml_list = []
for xml_file in glob.glob(path + '/*.xml'): #对path目录下的每一个xml文件
tree = ET.parse(xml_file) #获得xml对应的解析树
root = tree.getroot() #获得根标签annotations
# print(root)
print(root.find('filename').text)
for member in root.findall('object'): #对每一个object标签(框)
value = (root.find('filename').text, #在根标签下查找filename标签(图片文件名字),获得文本信息
int(root.find('size')[0].text), #在根标签下找size标签,并获得第0个字标签(width)的文本信息,转化为int
int(root.find('size')[1].text), #在根标签下找size标签,并获得di1个字标签(height)的文本信息,转化为int
member[0].text, #获得object标签的第0个字标签name的文信息
int(member[4][0].text), #获得object的第四个子标签bndbox,获得bndbox的第0个字标签(xmin)的文本信息,转化为int
int(float(member[4][1].text)), #获得object的第四个子标签bndbox,获得bndbox的第1个字标签(ymin)的文本信息,转化为int
int(member[4][2].text), #获得object的第四个子标签bndbox,获得bndbox的第2个字标签(xmax)的文本信息,转化为int
int(member[4][3].text) #获得object的第四个子标签bndbox,获得bndbox的第3个字标签(ymax)的文本信息,转化为int
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
for directory in ['train','test','validation']: #对应train和test文件夹
#对应根目录下的/images中的train和test文件夹,本脚本要放在voc文件夹下,和annotations是同级的,否则修改getcwd函数
xml_path = os.path.join(os.getcwd(), 'annotations/{}'.format(directory))
xml_df = xml_to_csv(xml_path)
xml_df.to_csv('data/whsyxt_{}_labels.csv'.format(directory), index=None) #xml转化为对应的csv保存
print('Successfully converted xml to csv.')
main()
对应的xml文件如下图:
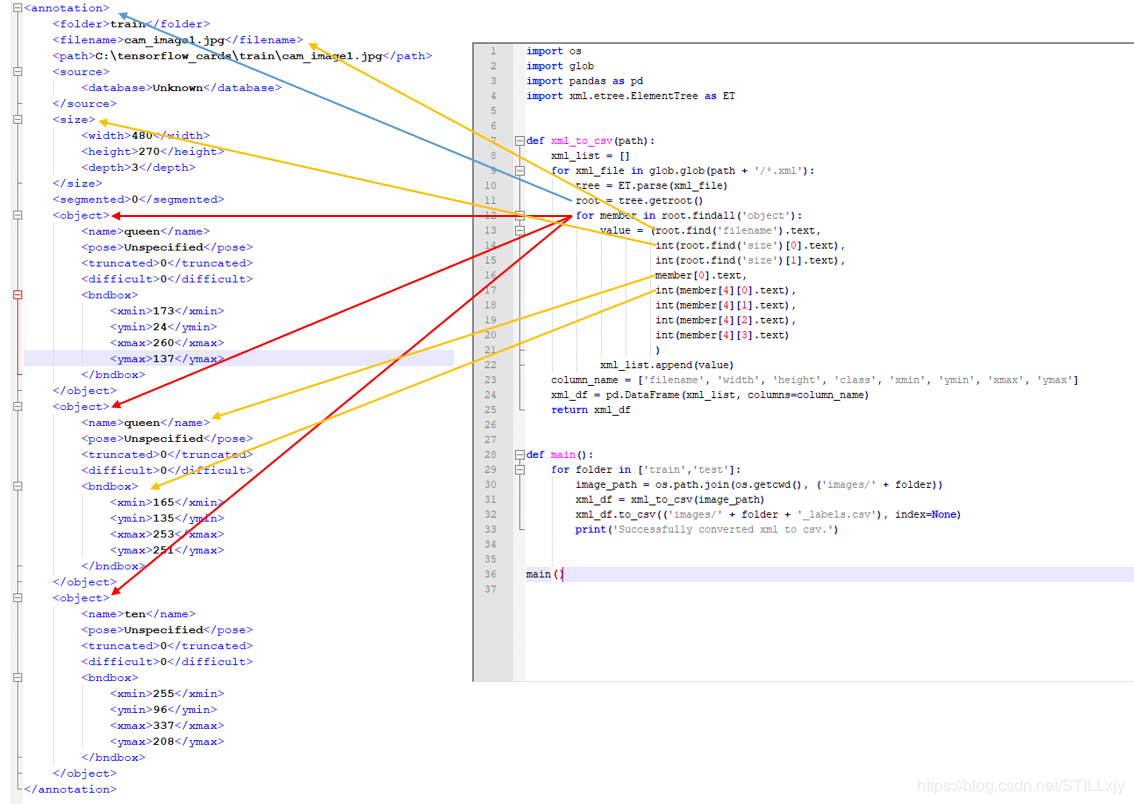
最后得到两个文件:

文件打开类似于这样的:

其中的filename只是图片文件的名字,不包括路径。
3、xml转换为tfrecord
每个图片会生成一个xml文件,批量的将xml文件转化成tfrecord格式。
4、csv转换成tfrecord
将多个xml文件写入到一个csv文件中去,每一行是一个xml文件的信息,接下来直接将这个csv文件转换成tfrecord格式就可以了,很方便快。
由于图像和标签值不在一起,所以要将整张图片信息和csv文件合并起来,整合成为tfrecord格式写入到本地中,用于训练。
代码来自tensorflow/object_dection/models-master/research/object_detection/test_generate_tfrecord.py:
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record
# Create test data:
python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
"""
DEFINE_string定义了个命令行参数
flage_name:csv_input,参数名字
defalut_name:默认值 ,这里的默认值是data/test_labels.csv
docstring:对该参数的说明
可以使用tf.app.flags.FLAGS取出该参数的值:
FLAGS = tf.app.flags.FLAGS
print(FLAGS.csv_input),输出的就是data/test_labels.csv
"""
flags.DEFINE_string('csv_input', 'data/test_labels.csv', 'Path to the CSV input')
flags.DEFINE_string('output_path', 'data/test.record', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
# 修改成你自己的标签
def class_text_to_int(row_label):
if row_label == 'face':
return 0
elif row_label == 'cat':
return 1
#............
def split(df, group):
"""namedtuple工厂函数,返回一个名为`data`的类,并赋值给名为data的变量
定义:Point = namedtuple('Point', ['x', 'y'])
创建对象:p = Point(11, y=22)
p[0] + p[1] 输出 33
解包:x, y = p
x,y 输出:(11, 22)
访问:p.x + p.y 输出 33
"""
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
#读取每张图片,得到每张图片的信息,将每张图片信息和图片里的object标注框信息(在csv里)合并在一起
#group
#path:iamge目录
def create_tf_example(group, path):
#image目录 + image的名字 = image的绝对路径路径
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
#图像所有信息encoded_jpg和object信息整合一起
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), 'images/test') #一个csv文件最后生成一个tfrecord文件
examples = pd.read_csv(FLAGS.csv_input)//读csv文件内容,返回pandas对象矩阵
"""
filename width height class xmin ymin xmax ymax
0 000001.jpg 353 500 dog 43 233 205 362
1 000001.jpg 353 500 person 117 12 296 226
2 000002.jpg 335 500 train 122 188 220 299
"""
grouped = split(examples, 'filename')
"""
[
data(filename='000002.jpg', object= filename width height class xmin ymin xmax ymax
2 000002.jpg 335 500 train 122 188 220 299),
#两个1.jpg是因为这张图片里面有两个object
data(filename='000001.jpg', object= filename width height class xmin ymin xmax ymax
0 000001.jpg 353 500 dog 43 233 205 362
1 000001.jpg 353 500 person 117 12 296 226)
]
"""
for group in grouped:
tf_example = create_tf_example(group, path)//将每个图片的标注信息和图像信息结合在一起
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
同理还有train_generate_tfrecord.py:
"""
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record
# Create test data:
python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', 'data/train_labels.csv', 'Path to the CSV input')
flags.DEFINE_string('output_path', 'data/train.record', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'face':
return 1
else:
0
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), 'images/train')
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号