

深入解读kubernetes网络基本原理
大纲:
1.概述
1.1 Linux的namespace+cgroup 与容器的网络
1.2 容器网络简介
1.2 pod的网络
2.pod的网络详解 - dockershim
2.1 kubernetes网络概述
2.2 详解pod内的网络
2.3 详解pod间的网络
3.pod的网络详解 - cni
<待添加>
正文:
网络概述
1,Linux的namespace+cgroup
namespace和cgroup是Linux 内核的两大特性,namespace的诞生据说就是为了支持容器技术,那么这俩特性到底干了啥呢?
- namespace:linux支持多种类型的namespace,包括Network,IPC,PID, Mount, UTC, User。创建不同类型的namespace就相当于从不同资源维度在主机上作隔离。
- cgroup:为了不让某个进程一家独大,而其他进程饿死,所以它的作用就是控制各进程分配的CPU,Memory,IO等。
- namespace+cgroup也适用进程组,即多进程运行在一个单独的ns中,此时该ns下的进程就可以交互了。
参考:https://coolshell.cn/articles/17010.html
2,容器
容器实际上是结合了namespace 和 cgroup 的一般内核进程,注意,容器就是个进程
所以,当我们使用Docker起一个容器的时候,Docker会为每一个容器创建属于他自己的namespaces,即各个维度资源都专属这个容器了,此时的容器就是一个孤岛,也可以说是一个独立VM就诞生了。当然他不是VM,网上关于二者的区别和优劣有一对资料.
更进一步,也可以将多个容器共享一个namespace,比如如果容器共享的是network 类型的namespace,那么这些容器就可以通过 localhost:[端口号] 来通信了。因为此时的两个容器从网络的角度看,和宿主机上的两个内核进程没啥区别。
详细原理见: Docker容器网络基础
3,kubernetes的pod
根据前面的描述我们知道,多进程/多容器可以共享namespace,而k8s的pod里就是有多个容器,他的网络实现原理就是先创建一个共享namespace,然后将其他业务容器加入到该namespace中。
k8s会自动以"合适"的方式为他们创建这个共享namespace,这正是"pause"容器的诞生。
pause容器:创建的每一个pod都会随之为其创建一个所谓的"父容器"。其主要由两个功能:
- (主要)负责为pod创建容器共享命名空间,pod中的其他业务容器都将被加入到pause容器的namespace中
- (可选) 负责回收其他容器产生的僵尸进程,此时pause容器可以看做是PID为1的init进程,它是所有其他容器(进程)的父进程。但在k8s1.8及以后,该功能缺省是关闭的(可通过配置开启)
水鬼子:我猜这个功能是利用了共享PID类型的Namespace吧
kubernetes之pod网络详解
一,kubernetes网络概述
我们说的k8s网络就是集群网络,因为k8s是用于集群的,单机网络没什么意义。一个集群的网络,主要涉及一下4个方面的通信
1,pod中的容器之间的通信:
这个在前面的章节我们已经说了,pod中容器都是共享网络空间的,所以就如一台机器上的应用一般,使用localhost:port就可以通信,也当然需要容器们自己保证大家别端口冲突了。
2,pod-to-pod的通信
首先k8s给每一个pod都分配ip了,具体他们之间怎么通信取决于具体的网络实施,这个不是k8s做的,但是k8s做了要求,也叫网络模型,具体要求如下:
1)一个节点上的pod可以和所有节点上的所有pod通信,且不需要NAT
2)节点上的agent(比如系统daemons:kubelet)可以和该节点上的所有pod通信
3)如果pod是运行与host的网络中,则要求pod同样可以和节点上的其他pod通信
3,pod和service的通信,这个详见service的定义
4,外网和serice的通信,同样相近service的定义
注:3,4的实现就是service的实现,建议仔仔细细研究官方文档就可以搞清楚了,有时间我会将这部分也整理下分享出来。那部分总结一句话就是:iptables的运用
另外,在进行k8s网络验证之前,需要进行k8s本地环境安装,为了更好的研究我走了一条非常复杂的安装之路:本地编译源码生成二进制,在打包镜像,最后通过三种途径安装了master节点和node节点:yum自动安装,二进制安装,镜像安装,想起来都是泪,想参考的见【爬坑系列】之kubernetes环境搭建:二进制安装与镜像安装
二,详解pod内的通信
1,一个例子模拟pod的通信
模拟k8的行为,首先创建pause容器,然后创建centos容器和nginx容器都加入到pause容器的网络中,然后在centos容器中访问localhost:80,于是访问到了nginx容器。具体如下:
docker run -d --name pause docker.io/ist0ne/pause-amd64
docker run -d --name nginx --net=container:pause --ipc=container:pause --pid=container:pause nginx
docker run -d -ti --name centos --net=container:pause --ipc=container:pause --pid=container:pause centos /bin/sh
sh-4.2# curl localhost:80 ---访问nginx
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
2,实际的k8s的:
创建一个有俩容器的pod,一个是centos操作系统,一个是nginx,在centos中访问localhost:80可以访问到nginx服务
//创建pod的yaml文件,该pod中有两个容器
# vi centos-nginx.yaml apiVersion: v1 kind: Pod metadata: name: myapp-2c labels: app: centos spec: containers: - name: centos-container image: centos:wxy command: ["/bin/sh"] args: ["-c", "while true; do echo hello; sleep 10; done"] - name: nginx-container image: nginx
//登录pod默认登录到centos-container这个容器,刚好
# kubectl exec -ti myapp-2c /bin/sh Defaulting container name to centos-container. Use 'kubectl describe pod/myapp-2c -n default' to see all of the containers in this pod. sh-4.2# curl localhost:80 <!DOCTYPE html> ... <h1>Welcome to nginx!</h1>
//看看容器的情况:一个pause容器领着领养俩业务容器
# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES edf722104aa6 nginx "nginx -g 'daemon ..." 27 minutes ago Up 27 minutes k8s_nginx-container.570a1191_myapp-2c_default_0461d9cd-8370-11e9-a770-5254006bdf04_702066eb 6e5e2c96bd90 centos:wxy "/bin/sh -c 'while..." 27 minutes ago Up 27 minutes k8s_centos-container.e8c7257b_myapp-2c_default_0461d9cd-8370-11e9-a770-5254006bdf04_d950aeda 044e4c09f0e9 docker.io/ist0ne/pause-amd64 "/pause" 27 minutes ago Up 27 minutes k8s_POD.68b7dd1e_myapp-2c_default_0461d9cd-8370-11e9-a770-5254006bdf04_00db96a2
二:详解pod之间的通信
这个是k8s集群网络的核心,前面说了,取决于具体的网络实施。
水鬼子:如果你刚接触k8s,不知道你是否会对这里感到迷惑,第三方实现是什么鬼?pod之间的通信不是k8s自己做的么?难道要额外安装啥软件?
是的需要额外安装,在这里我们就以etcd + flunnel为例来讲解。
概述:
集群中的各个node,首先一定是连通的,然后基于底层网络之上的flannel其实就是一个overlay网络。说到overlay,如果你看了前面Docker网络的章节,一定大概知道是怎么回事了。flannel网络有多种实现方式,目前支持的有:udp(默认),host-gw,VxLAN(是不是很熟悉?)。实际上pod之间的网络要比docker的还简单。
原理详解:
1,为什么需要etcd
etcd是一个key-value形式的存储系统,可以往里写各种类型的数据。我们需要做的就是首先约定好一个key,以这个key向etcd中写入网络配置参数;然后在安装flannel的时候配置FLANNEL_ETCD_PREFIX参数为此key。
k8s集群中的每个节点上都有安装flanneld作为网络代理,它通过读取etcd知道当前的网络配置信息,为pod分配ip后,再将当前的网络状况比如本节点分得的subnet和对应的public ip等信息再写入etcd中。这种网络管理模式就是所谓的network planes,用我的话说,大家也没什么上下级关系,都是处在同一平级,所以叫"网络平面"。
2,网络拓扑和转发原理
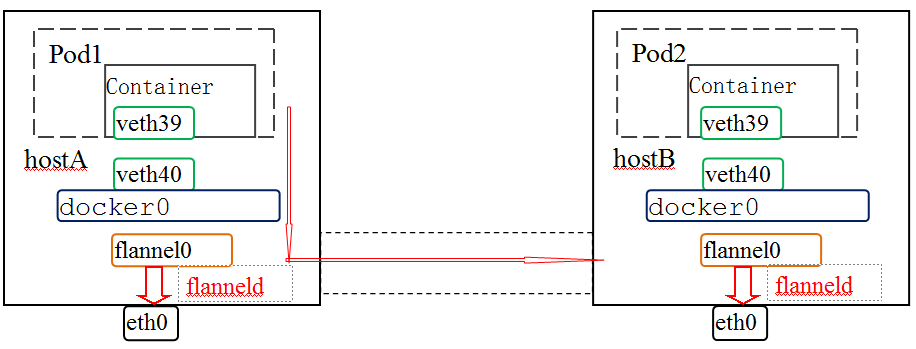
所谓flannel的安装,最主要是在每个节点上安装flanneld,这个"代理"一样的角色会做什么呢?
1)首先去etcd那里读取配置。根据配置为自己分配一个subnet,并将其与public ip(在安装flannel时指定的ip,如果没有指定则缺省是host上的eth0的地址)的对应关系再存入etcd中,这样其他节点上的flannel也就共享这些信息了。
2)创建虚拟网卡flannel0并分配一个该子网段ip,还会添加一条路由:所有到其他pod的数据都从flanel0出去;
3))将网段信息写入/run/flannel/subnet.env中,这是一个用于刷新Docker环境变量相关的的文件:/run/flannel/docker。所以这时候重启一下Docker,docker0就有了一个该子网段的ip。
[坑]这里要注意,我不知道别的版本,反正我目前安装的版本,如果flannel重启并重新给自己分配了subnet,那么此时一定记得重启Docker,否则docker0的ip和flannel0的ip不一致,进而导致数据无法正确转发。
最后,数据如何转发的呢?数据从容器出来,经过veth pair到达网桥docker0,根据路由再转发给flannel0,进而数据由flannel的backend(udp或者host-gw或者vxlan)转发给目的pod所在的backend上,最后由目的host上的backend上送至目的pod的容器中。具体如下:
//etcd中存放着flannel网络配置信息:地址空间,缺省backend类型
#etcdctl get /k8s/network/config
{"Network": "10.0.0.0/16"}
//flannel启动后,它会偷偷改变Docker的环境变量
#vi /usr/lib/systemd/system/flanneld.service
...
ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker
...
//于是docker在启动的时候就有了约束,其中bip决定了网桥docker0的IP
# systemctl status docker.service
...
/usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current ... --bip=10.0.42.1/24 --ip-masq=true --mtu=1472
...
//集群中两个节点,分别给自己分配了子网,也都存在了etcd中,包括到达子网络的public ip
# etcdctl ls /k8s/network/subnets /k8s/network/subnets/10.0.58.0-24 /k8s/network/subnets/10.0.42.0-24 # etcdctl get /k8s/network/subnets/10.0.42.0-24 {"PublicIP":"188.x.x.113"}
//veth pair把数据容器里导出来到达网桥docker0,再经过路由表到达flannel0,最后交给backend
# ip addr
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default
link/ether 02:42:ad:d6:96:b7 brd ff:ff:ff:ff:ff:ff
inet 10.0.42.1/24 scope global docker0
valid_lft forever preferred_lft forever
...
36: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.0.42.0/16 scope global flannel0
valid_lft forever preferred_lft forever
40: veth9b5a76f@if48: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue master docker0 state UP group default
link/ether da:e4:3e:d3:cb:f9 brd ff:ff:ff:ff:ff:ff link-netnsid 3
# ip route
default via 172.21.0.1 dev eth0
10.0.0.0/16 dev flannel0 proto kernel scope link src 10.0.42.0
10.0.42.0/24 dev docker0 proto kernel scope link src 10.0.42.1
3,详解flannel的三种backend
参考博客:
Kubernetes网络插件Flannel的3种工作模式 - 雪山飞猪 - 博客园 (cnblogs.com)
我觉得他讲的很明了了
实操
1,创建l两个pod,为了让他们能够分别调度到两个节点上,我还为node打了标签,并为pod配置了nodeSelector,例如
# cat centos.yaml apiVersion: v1 kind: Pod metadata: name: myapp-centos labels: app: centos spec: containers: - name: nginx-container image: centos:wxy command: ["/bin/sh"] args: ["-c", "while true; do echo hello; sleep 10; done"] nodeSelector: node: master
[root@master ~]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-centos 1/1 Running 0 16h myapp-nginx 1/1 Running 0 83s
2,验证连通性:在一个pod里访问另一个pod
1)看一下nginx的ip
# kubectl get pods myapp-nginx -oyaml |grep podIP
podIP: 10.0.58.3
2)在centos中访问一下nginx
[root@master ~]# kubectl exec -ti myapp-centos /bin/sh
sh-4.2# curl http://10.0.58.3:80
...
<h1>Welcome to nginx!</h1>
==============================END===================================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号