【python爬虫】游侠网部分新闻爬取
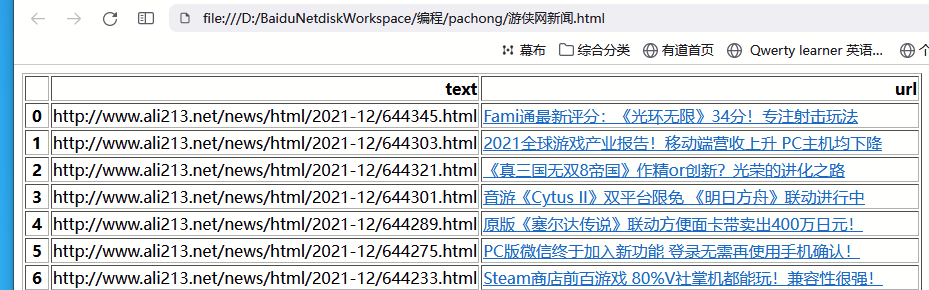
最后效果展示
【用网页表格的形式展示爬取的数据】
用pyinstaller打包成exe了
【python3.6 可运行的环境多一些】
aaaaa出错了!why什么?放到win7虚拟机运行 中文解码错误了~~~
代码
#游侠网 新闻news-link-ul https://www.ali213.net/ li a标签
import os
from re import I
import time
import requests
from lxml import etree
import pandas as pd
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
import traceback
url_list = []
text_list = []
def get_url(url):
header = headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"}
response = requests.get(url,verify=False)
rightcode = response.encoding#得到正确编码
s = response.content
s.decode(rightcode)#对内容进行正确解码
return s
for page in range(2,3):
s = get_url("https://www.ali213.net/")
selector = etree.HTML(s)#与下面的方法是同一样的效果
imgEle = selector.xpath('//ul[@class="news-link-ul"]/li[1]/a[1]')
imgEleText = selector.xpath('//ul[@class="news-link-ul"]/li[1]/a[1]/text()')
label = 'tu%s'%page
for index,i in enumerate(imgEle):
imgUrl = i.xpath('@href')[0]#连接已得到
url_list.append(imgUrl)
text_list.append(imgEleText[index])
#print(imgUrl)
#print(imgEleText[index])
def main1():
j = []
for k in url_list:
j.append('http://'+k.split("/",2)[2])#给网页链接中//去除掉 然后添加 http
dic1 = {
"text":[i for i in j],
"url":[f for f in text_list] # j replace url_list
#"text":["https://www.ali213.net/"],
#"url":["游侠网"]
}
#构建字典 利用字典创建表格数据
df1 = pd.DataFrame(dic1)
df1['url'] = '<a href=' + df1['text'] + '><div>' + df1['url'] + '</div></a>'
nowtime = time.strftime("%d-%m-%Y")
df1 = df1.to_html(nowtime+'游侠网新闻.html',escape=False) #escape = False 与上面一条语句 ,可以将df1[text]中变成url链接
#html_table = df1.to_html('游侠网新闻.html')
#print(df1.to_html()) #可以打印出html 字符串
if __name__ == '__main__':
try:
main1()
except Exception as e:
t=traceback.format_exc()
with open(os.getcwd()+"/error-pa6.txt",'w') as f:
f.write(t)
程序
链接:https://pan.baidu.com/s/1qO7z7UuR1Rlx9o-rmPNpAA
提取码:8888
--来自百度网盘超级会员V3的分享

 浙公网安备 33010602011771号
浙公网安备 33010602011771号