
Google提出爬取和索引(Crawlable & Indexable)Ajax站点的解决方案
Posted on 2009-10-08 19:15 Google优化 阅读(2626) 评论(0) 编辑 收藏 举报
Google官方博客发布了A proposal for making AJAX-based sites crawlable,Google认为现在Web 69%的内容是基于Ajax的,严重影响到搜索。
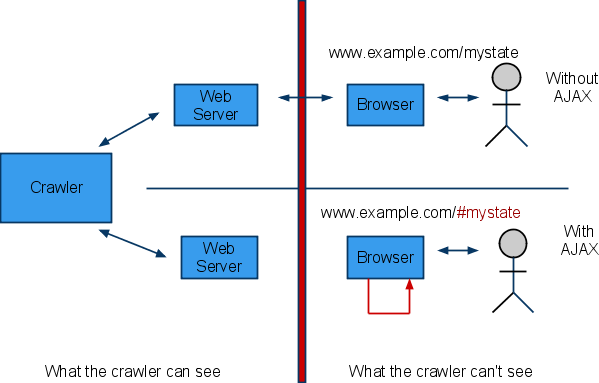
虽然搜索引擎现在能够通过分析js脚本获取Ajax内容,但是太过耗时耗力,而且效果不好,所以Google提出了新的解决方案,希望在Web服务器端使用Headless Browser技术来向爬虫返回Ajax在浏览器端执行的HTML内容,并通过Fragment(#)加上!的特殊的URL(如http://example.com/page?query#state => http://example.com/page?query#!state)来标识的Ajax内容,并显示在搜索结果中(Google称之为Pretty URL),而爬虫则将上述Pretty URL中的特殊Fragment段(#!state)映射为http://example.com/page?query&escaped_fragment_=state(Google称之为Ugly URL)来向服务器获取Ajax内容。整个过程如下所示:
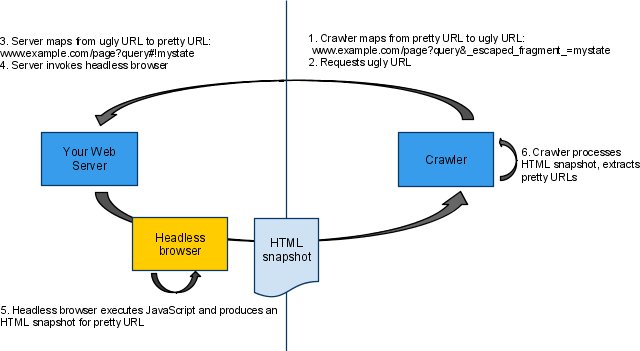

虽然搜索引擎现在能够通过分析js脚本获取Ajax内容,但是太过耗时耗力,而且效果不好,所以Google提出了新的解决方案,希望在Web服务器端使用Headless Browser技术来向爬虫返回Ajax在浏览器端执行的HTML内容,并通过Fragment(#)加上!的特殊的URL(如http://example.com/page?query#state => http://example.com/page?query#!state)来标识的Ajax内容,并显示在搜索结果中(Google称之为Pretty URL),而爬虫则将上述Pretty URL中的特殊Fragment段(#!state)映射为http://example.com/page?query&escaped_fragment_=state(Google称之为Ugly URL)来向服务器获取Ajax内容。整个过程如下所示:
但是由于需要Web服务器承担Ajax脚本执行功能,无疑给Ajax站点带来负担,而且这方案还在讨论中:Webmaster Help Forum,更详细的内容可以参见:SMX East Ajax Proposal

