

手把手玩转协同编辑(1):AST (Address Space Transformation)地址空间转换算法 基本介绍
写在前面的话
加入实验室已经有大半年的时间了,科研上一直没有取得什么重大突破。除去自身的实力问题之外,最大的问题恐怕就是对于自己或导师提出的一个问题往往不知道从何入手去研究,如何快速的了解相关工作的现状。相信这个导致我进步缓慢而且不断走弯路的主要原因。
写下这篇博客,出发点是为了能够记录自己在学习AST时的一些总结和感想,分享给以后的自己和实验室的小伙伴们。
看论文的方法
首先,对于一个刚进实验室的我来说如何找一个相关领域的优质论文是一件很棘手的事。因此,暂且把我现在找论文的一些心得记录下来,大神勿喷谢谢!
首先给出ccf推荐排名 http://www.ccf.org.cn/sites/ccf/paiming.jsp
在这个链接中有个领域的权威会议和期刊并且给出了在dblp【http://dblp.uni-trier.de/db/】上的链接,由于google学术需要FQ所以上述两个网站基本是我搜索论文的主要途径。
搜索论文的三要素:引用,被引用,作者
可以从一篇论文的相关工作出发,他引用的寻找权威会议的论文
可以从一篇论文的相关工作出发,寻找他被引用数多的引用论文
寻找一个领域的权威作者,搜索这个作者的相关论文
除去这几点之外,平时也需要广撒网没事看看相关领域会议论文的摘要,一篇一篇看这样也能对他们在做什么有一些了解。
AST(地址空间转换)的预备知识
从下文开始我会结合一些论文介绍一些ast的预备知识,相关论文会以引用的方式出现:
需要入门ast第一个要看的必定是老板的论文[1,2],好在中英文版都有。不过有略微的区别,需要对照的看。
AST的有什么用?
AST的应用领域可以说是比较广泛的,一个重要的领域就是协同编辑[支持多个用户在不同的计算机终端同时协同处理共享文档]:Demo和若干产品 collabedit 石墨 google drive One drive等等。AST是用来处理并发操作冲突的一个算法,那为什么会产生并发操作呢?
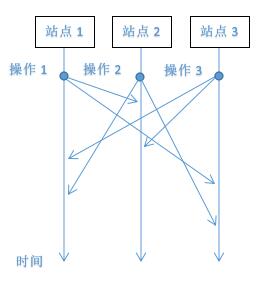
图1
各个站点的操作执行序列
站点1:操作1 -> 操作3 -> 操作2
站点2:操作2 -> 操作1 -> 操作3
站点3:操作3 -> 操作1 -> 操作2
图1所示的三个操作为并发操作,当并发操作发生的时候若不加以算法控制会导致各个站点上执行效果完全不一致。
操作间的关系
在分布式系统中没有办法保证各个站点的时钟精确一致,因此不能通过时钟确定操作的先后关系,因此Lamport提出了操作之间的逻辑关系[3],他提出的操作间的逻辑顺序在协同编辑研究领域被广泛采用。
定义1:因果关系"->" 假设操作a和操作b,于是操作满足关系a->b当且仅当 (1)他们来自于同一个站点且a的发生时间在b之前。(2)他们来自于不同站点且a在站点b的执行时间在b操作产生之前。(3)存在一个操作x使得a -> x && x -> b。
满足因果关系的前两种图示:第三种情况规定了操作因果关系的可传递性。
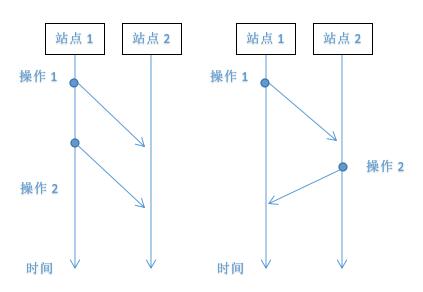
图2
定义2: 并发关系"||" 假设操作a和操作b,操作满足a||b,当且仅当不存在a->b也不存在b->a。如图2所示。
存储结构,操作,时间戳
AST的基本存储结构为线性结构,AST需要管理的是一系列操作的集合,然后将这些操作确定一个全序关系(就是两两之间可比较的)。这样不管操作在每个站点的到达顺序是怎么样的,他都会按照一定的顺序执行并且使得每个站点得到的文本状态最终一致。
站点1:操作1 -> 操作3 -> 操作2 站点1:操作1 -> 操作2 -> 操作3
站点2:操作2 -> 操作1 -> 操作3 -->> AST 站点2:操作1 -> 操作2 -> 操作3
站点3:操作3 -> 操作1 -> 操作2 站点3:操作1 -> 操作2 -> 操作3
提到给操作排序那么我们会想到给操作附加一个信息按照这个信息来进行排序,这个信息我们称为时间戳。由于每个站点的物理时钟是不可能精确统一时间的,因此Eillis.[4]最早将向量时间戳引入了协同编辑领域。
状态向量(时间戳):N表示协同编辑站点的个数,每个站点都有一个唯一的ID,然后对于这些ID从1-N编号,站点j的状态向量是一个N维的向量,其中第i个分量表示站点i上的操作在站点j上被执行了几个。
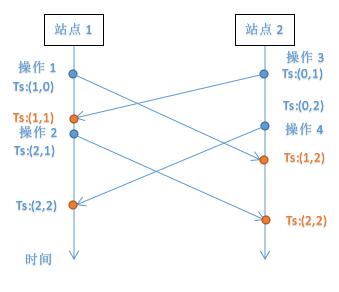
操作发生后各站点时间戳的变化
状态向量的大小关系
两个状态向量a,b 若a=b则a和b的每个分量都相等。
若a<b则a中每个分量都小于等于b中的对应分量,且至少有一个分量小于对应分量。
若a>b则a中至少有一个分量大于b中的对应分量。
举个例子 :(0,0,0) < (1,0,1) < (1,1,1) = (1,1,1)
操作的传输
定义3:对于文档的所有操作都可以拆分成两个基本操作
Insert[c, pos]:在 pos 与 pos + 1 的位置上插入字符c
Delete[c, pos]:在 pos 位置上删除可见字符c
定义[op, ts]为操作的传输结构,其中op表示上述两种操作之一,而ts表示状态向量时间戳。
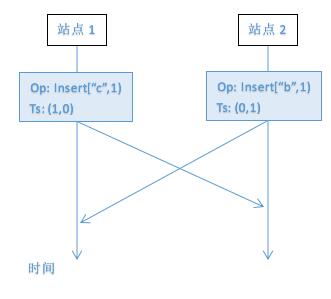
操作的结构化传输
地址空间转换的介绍
在协同编辑算法中,操作被分为两种:本地操作和远程操作。为了保证良好的用户体验,操作产生或者被接收会直接在站点上执行,然而为了保证每个站点副本内容的一致操作必须有序的执行。综合考虑两点矛盾就产生了,如果远程操作到达的顺序和产生的顺序相反那么后到来的操作如何执行呢?AST的解决方案很简单,回到操作产生时的文本状态执行该操作,相应的就是在执行一个远程操作之前先消除应该在该操作之后执行的操作对于文本的影响,在操作执行完之后再恢复那些操作的影响。
地址空间结构
地址空间由若干节点组成,每个节点除了字母信息外还有一个有效位(在回溯操作中需要用到),节点上包含对于这个字母的插入和删除操作。操作节点的内容和操作的传输结构类似,包含基本操作和状态向量(时间戳)两部分。地址空间结构如下图所示:
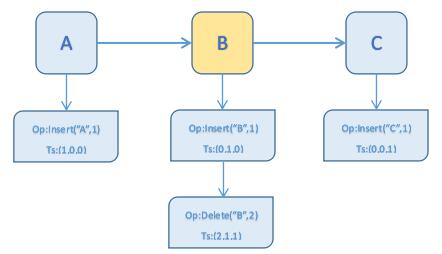
地址空间结构图(黄色为无效节点)
操作的划分
接着,我们来讨论哪些操作的集合才是文本执行时的状态呢?试想当一个用户操作A在一个站点1上被执行的时候,所有的操作可以被分成三部分:
定义4:因果先序 在站点1上已经执行的操作{X}称因果先序操作 X->A
并发操作 对于任意站点i(i≠1)操作A到达站点i之前产生的操作中还未到达站点1的操作{X}称并发操作 X||A
因果后序 对于任意站点i(i≠1)操作A到达该站点后产生的操作和站点1在操作A之后产生的操作{X}称因果后序操作 A->X
所谓的文本执行时状态指的是因果先序操作集合,因此在地址空间回溯的时候仅仅保留因果先序操作集合。
性质1:一个操作可以在站点上执行当且仅当以下两种情况:
(1)操作是该站点的本地操作
(2)操作是远程操作且操作的因果先序操作已经在当前站点上全部执行。
回溯算法介绍
性质1是操作的前提条件,在满足性质1的情况下提出回溯操作的算法框架,其中SV表示需要回溯到的时间戳:

AST回溯算法步骤
算法解释:对于每个操作节点进行扫描,通过时间戳的比较判断此操作节点是否为当前操作的因果先序操作,若不是则将该操作节点值为无效。回溯算法的目的是回到操作产生时的文本状态,也就是仅仅保留因果先序操作。
操作逻辑关系在状态向量(时间戳)上的体现
通过时间向量的比较我们可以确定操作之间的逻辑关系,提出如下性质:
性质2:定义操作A和操作B分别产生于站点1和站点2他们的时间戳分别为SVa和SVb。
A->B 因果先序 则有SVa<SVb
A||B 并发关系 则有SVa>SVb && SVb>SVa
A<-B 因果后序 则有SVb<SVa
控制算法介绍
当一个来自与R站点的操作O到来时操作的时间戳为SVo,且性质1已经被满足,则当前时间戳为SVS时站点S的控制算法过程如下所示:

AST控制算法步骤
算法解释:首先回溯到操作产生时的文本状态(第一行),然后执行操作加入时间戳(第二、三行),接着更新当前站点时间戳(第四行),最后回溯站点至当前文本状态(第五行)。
操作执行算法
下面来讨论一个操作具体的执行步骤。
操作O是一个删除操作,则仅需在地址空间中找到操作的相应位置(从左至右对有效节点计数),将操作附着到这个节点上。
操作O是一个插入操作,现在地址空间中找到操作的相应位置(从左至右对有效节点计数),建立一个新的字符节点,初始化节点的标记并把它插入到插入范围中的一个确定位置。
对于插入操作存在一个问题:根据插入操作的位置仅仅能够确认插入的位置位于两个有效节点之间,但并不能够知道具体位置(两个有效节点之间可能存在若干个无效节点)。
对于这个问题AST是通过range-scan算法来确定操作的具体插入位置,range-scan的原理在于通过定义TOrder函数来确定操作两两之间的全序关系(操作两两之间可以直接比较)。TOrder函数的定义如下:
定义5:考虑连个元素CNa和CNb,他对应的操作分别产生至站点a和站点b,并且时间戳分别为SVa和SVb。有TOrder(CNa)<TOrder(CNb)当且仅当:
(1)sum(SVa)<sum(SVb)
(2)sum(SVa)=sum(SVb)且a<b
TOrder是一个全序关系且是传递的,也就是说任意两个节点之间是可比较的。在这个基础上提出了range-scan算法,CNa和CNb是算法的执行范围,是两个相邻的有效节点,CNnew是将要插入的节点,P表示一个位置:

AST的range-scan算法步骤
算法解释:range-scan算法可能是初学者最容易弄不懂的地方了,接下来详细解释一下他的执行过程。首先在两个有效节点之间的无效节点分为两类:因果先序操作节点(算法12-17行)和并发关系操作节点(算法4-11行)。算法的初始化将p赋值为空,将扫描指针CNscan赋值为第一个无效节点。外层循环依次扫描每个无效节点直到遇到有效节点CNb停止并返回位置P。对于因果先序操作节点规定新节点一定插入在其左侧,对于并发关系操作节点则按照TOrder函数比较插入在合适的位置。
至此整个AST算法就介绍完了。
声明
算法步骤图摘自[5],部分关于算法细节的说明参考了[1,5,6]。
转发请注明来源 http://www.cnblogs.com/shu-xiaohao/p/5358455.html
参考文献
[1] 顾宁, 杨江明, 张琦炜. 协同组编辑中基于地址空间转换的一致性维护方法[J]. 计算机学报, 2007, 30(5):763-774.
[2] Gu N, Yang J, Zhang Q. Consistency maintenance based on the mark & retrace technique in groupware systems[C]// Proceedings of the 2005 International ACM SIGGROUP Conference on Supporting Group Work, GROUP 2005, Sanibel Island, Florida, USA, November 6-9, 2005. 2005:264-273.
[3] L. Lamport. Time, clocks, and the ordering of events in a distributed system. Commun, 7:558–565, 1978.
[4] Ellis C A, Gibbs S J. Concurrency control in groupware systems[J]. Acm Sigmod Record, 1989, 18(2):399-407.
[5] 杨江明. 协同组编辑环境中的数据一致性维护方法[D]. 复旦大学, 2007.
[6] 张琦炜. 大规模协同环境下的实时组编辑技术研究[D]. 复旦大学, 2007.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号