

RDMA学习:内核协议栈问题:大规模网络流量以及高速网络带宽
内核协议栈问题:大规模网络流量以及高速网络带宽
传统的网络协议栈是在操作系统内核中以软件的方式工作的,协议栈搭建在软件系统中。
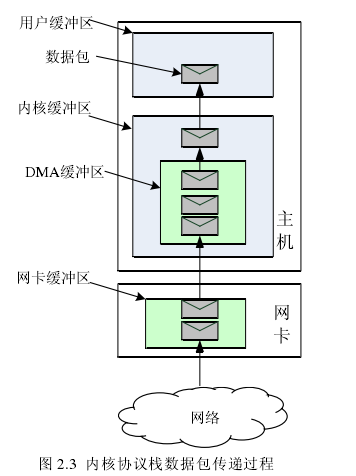
传统内核协议栈集成于操作系统内核之中,并通过系统调用的方式向外部网络应用程序提供网络数据处理服务。以网络数据的接收为例,传统协议处理过程通常如此:硬件网卡在捕获到达本机的数据包之后,将数据包从网卡的硬件缓存拷贝到内核态内存,并发出一个硬件中断通知操作系统内核进行处理;内核收到数据包后,协议栈各层处理程序会对包进行解析,从中得到需要递交给用户态应用程序的数据;用户态应用程序需要处理来自网络的数据时,通过系统调用陷入内核,将内核数据拷贝到用户态缓冲区,最后通过切换特权级退出内核态。由此可知,传统的网络数据处理过程中,协议栈的性能开销主要集中在系统调用、内存拷贝、协议处理与中断处理等方面。这些开销占用了大量的CPU资源,尤其是在应对高速大规模网络流量时,内核协议栈势必会成为整个系统的瓶颈。
- 应用上下文切换开销:通过软中断的方式,网络应用程序可以执行系统调用获取相应的功能。然而系统调用执行于内核空间,应用程序调用系统调用必定会进行特权级切换,会带来额外的上下文切换开销,系统调用前要对应用程序上下文进行保护,系统调用执行完之后,要恢复之前的进程上下文。频繁的上下文切换占用了大量的CPU资源,在万兆以上级别的网络带宽情况下,这种开销更加明显,会严重影响系统性能。
- 内存拷贝开销:数据包在应用程序与网卡间的传递均需要经历两次内存拷贝过程:从网卡到内核态缓冲区;从内核态缓冲区到用户态缓冲区。
- 中断处理开销:大流量时产生的频繁硬中断占用CPU,比轮询没有优势可言,浪费大量系统资源。
协议栈加速方案:
(1)改进协议处理机制。这方面的研究包括协议处理过程加速、优化校验和的计算以及对TCP拥塞控制性能进行优化等。
(2)优化协议处理实现。这方面的研究首要任务是找到优化对象,即主要的性能瓶颈部分在哪里;然后针对操作系统内核以及网络驱动程序进行优化。当前主要集中在减少中断次数、降低内存间的数据复制、高速缓存访问的优化等。
(3)优化协议栈框架。这方面的研究主要包括TCP/IP卸载引擎技术(TOE)、RDMA技术和用户态协议栈加速方案等。
优化协议栈框架
1.TCP/IP协议卸载引擎(TOE)
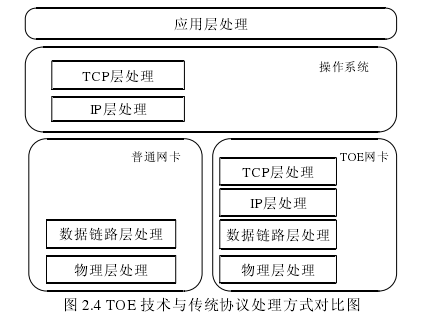
TOE技术的思想是利用硬件的速度优势来解决软件的性能瓶颈[17]。将TCP/IP协议栈的全部或者部分工作卸载到硬件上去执行,通过将协议处理过程卸载到专用的硬件网卡上,利用硬件执行速度快等特性,减轻了CPU和I/O系统的负担。通过软件协议栈的硬件化方式解放了CPU,提高了系统的性能。TOE技术与传统TCP/IP协议处理方式对比如图2.4所示。
TOE包括软件部分和硬件部分,将传统的操作系统内核TCP/IP协议栈功能进行了扩展,把数据协议处理工作放到专有的硬件网卡中执行,而CPU只进行相关控制信息的处理任务[18]。TOE技术能够有效减少网络数据拷贝、中断处理操作以及协议处理所带来的大量开销,大大提高系统性能,目前该技术已经得到众多操作系统厂商的青睐。
TOE的实现需要考虑如何将协议卸载到硬件以及如何利用硬件实现复杂的协议处理过程。TOE的卸载方式分为部分卸载与全部卸载两种,不同的卸载方式决定了TOE网卡硬件与上层软件之间的接口划分。采用不同的卸载方式会产生不同的报文处理过程,协议处理性能差异也较大,实现时要选取合适的卸载方式。
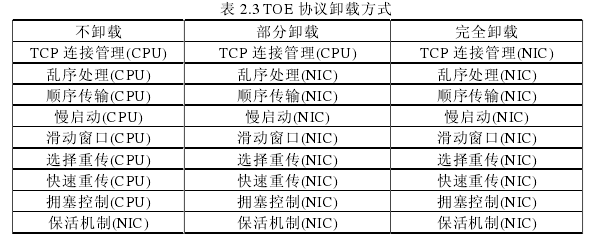
TCP协议处理过程主要包括如下几部分:TCP连接的建立、数据传递、连接的维护、差错控制、拥塞控制与TCP连接的关闭等。其中数据传递过程、连接维护过程、差错控制与拥塞控制作为TCO协议处理的主要部分,是整个协议处理过程的瓶颈所在,需要卸载到硬件上完成,从而提高性能。然而,占整个协议处理流程较小比例的TCP连接的建立以及关闭过程,涉及到复杂的连接状态变化,需要根据实现难度以及性能因素等综合考虑是否卸载。表2.3所示为TOE协议卸载方式。
2. RDMA技术
RDMA[20](Remote Direct Memory Access)全称为远程直接内存存取技术,是一种典型的网络存储零拷贝技术,能有效地消除端系统中存储器之间的非必要的通信数据拷贝过程,简化协议处理层次,并提供更快的应用程序与网络之间的通路[21]。从而消除CPU负载提高CPU有效利用率,腾出CPU周期和总线空间用于改进系统性能,有效地降低通信延迟,极大地提高网络数据吞吐量和网络通信效率。
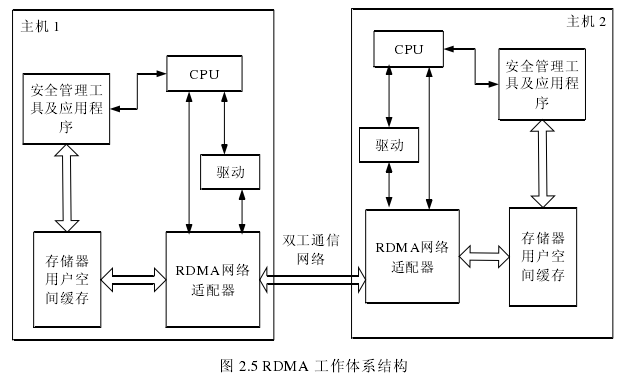
RDMA是DMA由主机总线扩展到网络上的改进,其在网络传输过程中加入相应的RDMA控制信息,从而使得网络硬件能够直接操纵远端主机的内存区域。远端的RDMA网卡对控制信息进行解析,从而得到相应内存区域信息,并通过DMA技术直接操作该主机内存区。零拷贝技术[22]的应用,从根本上消除了将数据在用户态内存与内核态内存之间相互拷贝带来的开销,使得网卡可以直接与用户态内存相互传送数据;内核内存旁路技术保证应用程序不用执行内核态内存系统调用就可以向网卡发送相应命令,在不需要内核参与的情况下,将请求从用户空间发送到本地网卡并通过网络发送给远端硬件网卡,这一技术极大减少了内核空间与用户空间之间的上下文切换次数,图2.5所示为RDMA体系结构图。
RDMA的工作过程如下所述:
(1)当进程发起请求进行RDMA读写操作时,该请求会直接由用户空间发送到本地的RDMA网卡之上,该过程不进行内核态的操作。
(2)RDMA网卡获取硬件缓存中的信息后,将其发送给远端RDMA网卡。RDMA操作包括读取远端应用缓冲数据或者向远端应用内存区写入数据。
(3)远端RDMA网卡对收到的请求信息进行确认,之后取出请求信息,并根据其中的地址信息,将请求信息直接传送到相应的用户空间内存[23]。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号