
Feature Extractor[inception v2 v3]
0 - 背景
在经过了inception v1的基础上,google的人员还是觉得有维度约间的空间,在《Rethinking the Inception Architecture for Computer Vision》一文中,通过卷积分解、网格约间等方式来修改inception模块。当然了在BN那篇论文的附录部分也多少涉及到v2的设计方向。
因为第一篇论文并没有详细说明设计inception v1的一些具体原理,而其主要是从如何减小模型的参数量上下手,所以v3上对这部分做了个简单的原则说明:
- principle 1 - 从模型的输入到输出,不要让网络的特征维度变化太快,最好如金字塔一样,慢慢的减少维度;
- principle 2 - 更大维度的表征可以更容易的在网络内部的局部进行处理,所以,如在卷积网络中增加更多的激活神经元那么可以解耦合更多的特征,从而网络就会训练的更快(因为特征解耦了)(参考figure 7);
- principle 3 - 空间聚合可以进行低维嵌入,这样并不会导致网络表示能力降低太多。例如在3*3的卷积之前,可以先对输入信息进行降维。我们假设降维后的数据用在空间聚合上,那么在维度约简过程中相毗邻的单元之间具有很强的相关性会导致信息的减少不明显。而且假如数据本身很容易被降维,那么还能加速训练;如3*3前面加个1*1的卷积
- principle 4 - 在扩增模型的时候,深度和广度需要相适应,不要畸形扩展,即做好两者的平衡关系。
ps:其实上面几点都还是需要去验证的,这里都只是大致的原则,大致的指导方针吧,主要还是为了说明Inception v2的改进是有理可依的。
v1的网络得益于维度约间。这可以被看成是一种特殊的卷积分解从而减少计算量的需要。在视觉网络中我们都期望相邻的神经元激活值都是高度相关的,因此期望在空间聚合之前可以进行约间,从而生成相似的局部表征。所以任何计算量上的减少就意味着参数量的减少。这也就是说如果有合适的分解方式,那么可以得到更多解耦和的参数,因而能够加速训练了。同样可以将多出的计算和内存用来多增加一些卷积核的数量,并且还能保证单机上多模型的稳定性。
1 - inception v2
1.1 分解卷积
因为是建立视觉网络,所以可以用平移不变性这个特点。而对于一个5*5的卷积,其本身的感受野大小和两个3*3的卷积是一样的,可是所需的计算量是不同的,所以很自然的由此进行替换。而更狠一点,如果考虑不重复的感受野计算,那么还能将一个\(n*n\)的卷积分解成一个\(n*1\)的卷积和一个\(1*n\)的卷积的叠加。如下图所示:
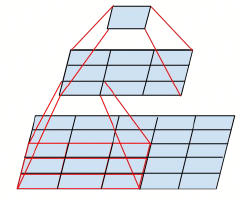
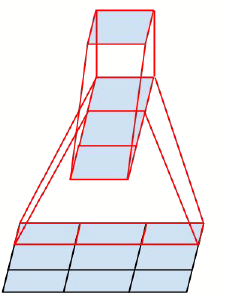
图1.1.1 左:用两个\(3*3\)的代替一个\(5*5\);右:用一个\(3*1\)的和一个\(1*3\)的代替一个\(3*3\)的
所以结果如下:
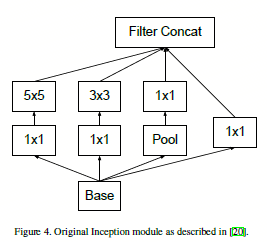
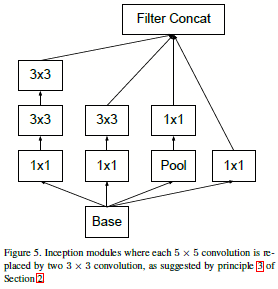
图1.1.2 v1中\(5*5\)的卷积核的替换
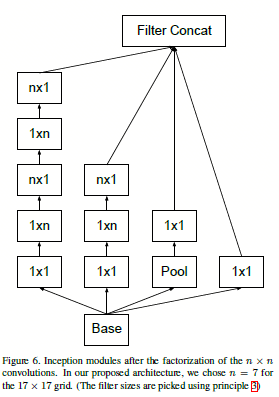
图1.1.3 v1中\(n*n\)的卷积核的替换
不过对于将\(n*n\)的卷积分解成\(n*1\)和\(1*n\)的卷积的时候,发现在网络的前层这样进行卷积分解起不到多大作用,不过在网络的网格为\(m*m\)(m在[12,20]之间)的时候有个较好的结果。在这个层级,如使用\(1*7\)然后使用\(7*1\)的到的结果还是不错的。
1.2 辅助分类器
v1中的辅助分类器是为了将有用的梯度能够立即传递给更低的层,从而改善收敛情况和保证在训练中能够稳定收敛。Lee也主张辅助分类器可以让模型更稳定的训练和更好的收敛。不过本文发现,在训练的早期其实是没有改善收敛情况的;假定一个有辅助分类器,一个没有,那么在两个模型中,最开始都是表现一样的,只有在训练的最后,辅助分类器才有帮助提升效果。将v1中两个辅助分类器中更低的辅助分类器去掉,网络没有太大差别,所以v1中原来的假设辅助分类器可以有助于发展低层级的特征的假设是错的。v3中认为辅助分类器其实类似一个正则化器,支持的事实是:如果边分支使用了bn或者使用dropout层,那么主分类器可以表现的更好。当然,这同时也弱证明了bn也是一个正则化器。
1.3 网格尺度约间
所谓网络尺度约间,对于传统cnn来说,就是每层的feature map变小,或者channel变少。假设一个feature map固定分成\(d*d\)大小的网格,且有\(k\)个通道。为了得到下一层为\(\frac{d}{2}*\frac{d}{2}\)大小的网格,且通道\(2k\)(为了不违反准则1,在减少map大小的时候,相应的增加通道数),则如果先以stride=1进行卷积,然后在进行池化,那么需要的操作是\(d*d*k*2k\),而如果直接池化则需要的操作是\(\frac{d}{2}*\frac{d}{2}*k*2k\),可以看出后者比前者减少了\(3/4\)。

图1.3.1 通常的网格尺度约间方法
如图1.3.1所示,左边那种方法因为map尺度下降太快,违反了准则1,而右边的计算量又太大,所以需要找到一种新的网格尺度约间方法。
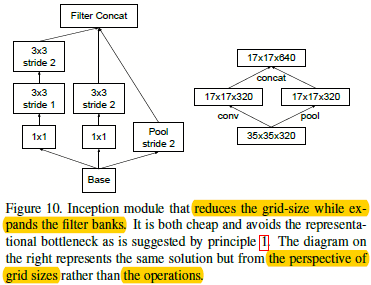
图1.3.2 进行网格尺度约间的方法
作者提出了卷积和池化并行的方式,如图1.3.2右边所示,通过在基于输入为\(35*35*320\)的上面左边是一个stride=2的卷积操作,并列的增加一个stride=2的池化操作,从而并行的输出得到一个\(17*17*640\)的层,可以看出这样即保证了网格尺度的约间,也没有违反准则1.
1.4 google v2网络结构
只要遵循之前的那四点进行网络设计得到的inception的变种,基本上准确度都很稳定。googlenet v2的网络有42层,而计算量只是v1的2.5倍而已,当然还是比vgg要低。
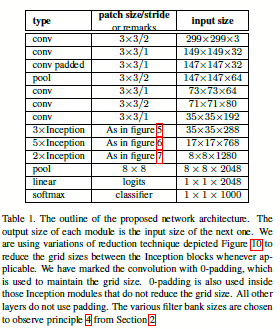
图1.4.1 googlenet v2的网络结构
googlenet v2的网络结构就是将上面的那些修改拿过来组合而成的,而且都遵循着最开始说的4个网络指导原则进行了如下改进(当然这部分描述和图1.4.1略有不符):
- 1 - 将\(7*7\)的卷积替换为3个\(3*3\)的卷积;
- 2 - 其中在\(35*35*288\)的部分引入三个inception v1模块,不过是通过网格尺度约间技术使得输出的时候网络维度变成了\(17*17*768\);
- 3 - 然后引入5个在inception v1上加入卷积分解(大卷积变成小卷积叠加)的模块,同样采用网格尺度约间技术使得网络维度变成了\(8*8*1280\);
- 4 - 接着引入2个在inception v1上加入卷积分解(2维卷积变成1维行(列)卷积)的模块,并将输出的通道合并成2048(即\(8*8*1024\)与另一个\(8*8*1024\)在通道维度上简单的并列)
其中figure 7 如下图:

图1.4.2 在图1.4.1中涉及的figure 7
1.4 低分辨率图片
作者基于不同分辨率进行了网络结构的微调:
- 1 - 299*299的分辨率的在第一层中stride设为2,并且之后采用最大池化;
- 2 - 151*151的分辨率的,在第一层中stride设为1,并且之后采用最大池化;
- 3 - 79*79的分辨率的,在第一层中stride设为1,不要最大池化。
可以看的出来,随着分辨率的降低,那么就需要增加信息的获取;反之减少。基于这三种结构,作者试验发现效果都相当。
1.4 通过标签平滑来进行模型正则
待续
2 - inception v3
其中inception v2加了BN辅助的就是v3了(也就是将针对inception v1 的所有的改进都加起来,然后加个BN)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号