

face detection[S^3FD]
本文来自《\(S^3\)FD: Single Shot Scale-invariant Face Detector》,时间线为2017年11月.
0 引言
基于锚的目标检测方法,是通过分类和回归一系列预先设定的锚来检测目标的。这里预先设定的锚通常都是一个个基于不同尺度和长宽比的框。这些锚通常都是关联一层(faster rcnn)或者多层(SSD)卷积层。通过不同卷积层的空间尺度和stride大小来决定锚的位置和间隔。关联锚的网络层通常是为了用来分类和对齐这些锚。相比于其他方法,基于锚的检测方法在复杂场景下更鲁棒,而且他们针对不同的对象个数也具有速度不变性(即不会因为图片中目标个数增加而导致整体计算量增加)。然而,正如《Speed/accuracy trade-offs for modern convolutional object detectors》所述,基于锚的检测器会随着目标尺寸的变小,其效果会急剧变差。
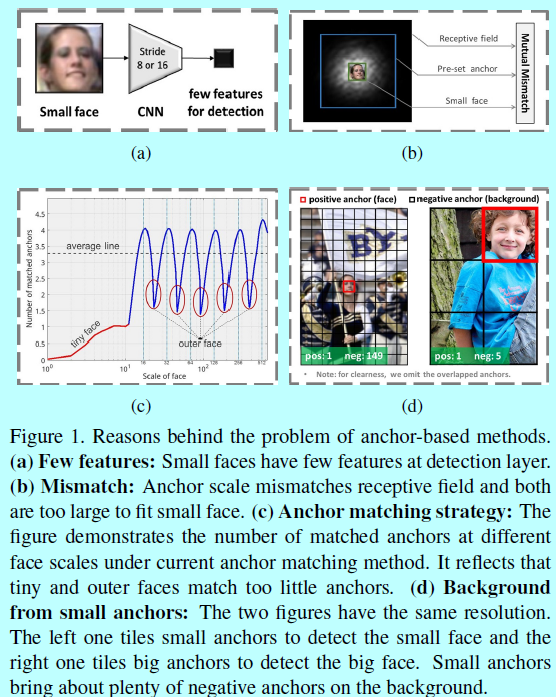
为了得到一个基于锚的尺度不变人脸检测器,作者综合分析了背后的原因:
- 有偏框架:基于锚的检测框架通常会丢失小型和中型的人脸。首先,最低的关联锚的层的stride太大了(如SSD中8个像素,Faster rcnn中16个像素 ),因此小型人脸和中型人脸在这些层上就被极度压缩,从而几乎没有特征以供检测,如图1(a);其次,小型人脸,锚的尺度,感受野互相不匹配:锚的尺度首先和感受野不匹配,然后他们相对小型人脸而言都太大了,如图1(b)。为了处理这样的问题,作者提出了一个尺度等同的人脸检测框架。作者在一个范围内的网络层上平铺锚(如SSD),其中stride从4个像素到128个像素,从而保证了人脸的各种尺度都有足够的特征以供检测。同时,基于不同层上的感受野大小,设计锚本身的尺度从16个像素到512个像素,并提出一个等比例区间原则,从而确保不同层上的锚能够匹配他们对应的感受野,而且不同尺度的锚点均匀分布在图像上。
- 锚匹配策略:在基于锚的检测框架中,锚的尺度都是离散的(即16,32,64,128,256,512),但是人脸的尺度确是连续的。因而,那些人脸的尺度就会严重偏离从而没法很好的匹配锚,比如非常小的,和非常大的,如图1(c),从而导致召回率很低。为了提升这些被忽略的人脸的尺度,作者提出了一个基于2阶段的尺度补偿锚匹配策略。第一个阶段就是采用当前的锚匹配方法,不过调整到一个更合理的阈值;第二个阶段就是通过尺度补偿确保每个尺度的人脸都有足够的锚去匹配。
- 小锚的背景:为了很好的检测小型人脸,需要许多小的锚密集的平铺在图片上,如图1(d),这些小的锚导致背景上负锚的数量急剧上升,从而带来许多假阳性人脸。例如,在作者的尺度等同框架中,超过75%的负锚都来自最低的conv3_3层,而这一层是用来检测小型人脸的。本文基于最低检测网络层提出了一个max-out背景标签,从而减少小型人脸带来的假阳性比率。
本文的贡献:
- 提出了一个尺度等同人脸检测框架:基于一个较广的范围内去建立锚和卷积层关联,并且加之一系列合理的锚尺度,一起去处理不同尺度的人脸;
- 提出一个尺度补偿锚匹配策略去提升小型人脸的召回率;
- 引入一个max-out背景标签方法,去减少小型人脸的假阳性比例;
- 在AFW,PASCAL face,FDDB,WIDER FACE上达到了实时的效果。
1 结构
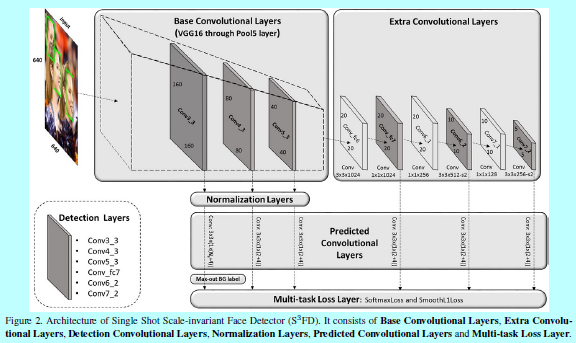


如图所示,可以看出,该模型和《FaceBoxes》模型还是挺像的,毕竟来自同一个人之手。
1.1 尺度等同结构
这里的尺度等同架构也是基于锚的检测框架,如RPN和SSD。而这些网络的一个缺点就是随着目标尺度的变小,其检测性能急速下降。为了提升人脸尺度的鲁棒性,作者提出了一个有着较广范围的锚关联层的网络结构,这里stride从4个像素逐步增长到128个像素。因此,这个架构确保不同人脸的尺度在对应的锚关联层上有合适的特征用来做检测。在决定锚的位置后,还设计了基于感受野和等比例间隔的锚尺度,其从16个像素逐步过渡到512个像素。前面的考虑是为了保证每个尺度的锚能够匹配对应的感受野;后面的考虑是为了让不同尺度的锚在图片上有相同的平铺密度。
构建的结构:如上图的图2所示
- 基础卷积层:保留VGG16的conv1_1到pool5,移除其他后续的层;
- 额外卷积层:将VGG16的fc6和fc7通过子采样的方式构建卷积层,然后在后面增加额外的卷积层,这些层可以逐渐的降低feature map的尺度,并形成多尺度feature map;
- 检测卷积层:这里选择conv3_3,conv4_3,conv5_3,conv_fc7,conv6_2,conv7_2作为检测层,它们都关联不同尺度的锚以供检测;
- 归一化层:相比于其他检测层,conv3_3,conv4_3,conv5_3有不同的特征尺度,这里使用L2归一化的方式去将他们的范数缩放到10.8.5,然后在BP中学习该尺度;
- 预测的卷积层:每个检测层后面都跟着一个\(p\times 3 \times 3 \times q\)的卷积层,这里p 和q 是对应的输入和输出的通道数,3x3是核尺度。对于每个锚,这里都预测其4个坐标的偏移量和对应的\(N_s\)个类别的分类得分,对于conv3_3检测层,\(N_s=N_m+1\),(\(N_m\)就是后面介绍的max-out背景标签),而其他检测层\(N_s=2\)。
- 多任务loss层:使用softmax loss做分类,使用平滑L1 loss做回归。
基于锚设计的尺度:
上述介绍的6个检测层都关联一个特定尺度的锚(如下表)
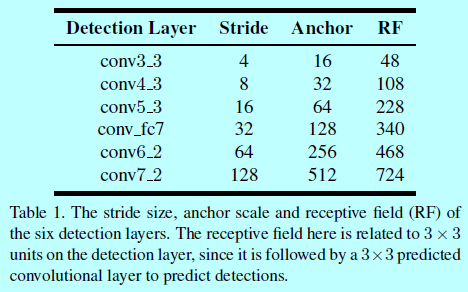
因为人脸基本都是方形的,所以这里的锚长宽比都是1:1(平方锚)。如表1中第2和第4列,每个检测层上的感受野和stride都是固定的,这里有2点设计原则:
- 有效的感受野:如《Understanding the effective receptive field in deep convolutional neural networks》指出的,CNN中一个单一有2种类型的感受野:一种是理论上的感受野,其表示输入区域可以理论上影响该单元的值。然而不是每个理论感受野上的像素都能够在最终输出上有相同的贡献度。通常而言,中心区域的像素会比外围像素有更多的影响,如图3(a)
换句话说,只有部分区域会影响到输出值;另一种就叫做有效感受野,根据该理论,锚应该明显的小于理论感受野,从而才能匹配有效感受野(图3b);- 等比例间隔原则:一个检测层的stride决定输入图像上锚的间隔。例如conv3_3的stride是4个像素,那么他的锚应该是16x16,表示一个16x16的锚在输入图像上每4个像素会平铺一个。如表1中第2列和第3列,锚的尺度应该是刚好4倍于它的间隔。这里称这种叫等比例间隔原则(图3c),从而保证不同尺度的锚在图像上有相同的密度,所以每个尺度的人脸都大致有相同数量的锚。

1.2 尺度补偿和锚匹配策略
在训练中,需要决定哪个锚对应哪个人脸边界框。当前的锚匹配策略首先匹配与人脸IOU最高的那个锚,然后匹配那些与人脸高于阈值(通常是0.5)的锚。然而,锚尺度是离散的,而人脸尺度是连续的,从而锚没有足够的数量去匹配所有的尺度的人脸,就导致降低了人脸的召回率。如图1c,作者统计了下不同尺度的人脸能匹配的锚的平均数量。发现两个结论:
- 匹配的锚的平均数量是3,这导致没法获得较高召回率;
- 匹配的锚,高度依赖锚的尺度。
那些尺度偏离锚尺度的人脸都容易被忽略。为了解决这个问题,作者提出了一个尺度补偿锚匹配策略,其中包含2个阶段:
- 阶段1:首先遵循当前的锚匹配方法,不过将阈值从0.5降低到0.35,为了增加匹配的锚的数量。
- 阶段2:经过阶段1之后,仍有一些人脸还不够锚,比如,如图4a中那些灰点标出的尺度极小和极大的人脸(tiny,outer)。
对于这些人脸,首先抓取那些与该人脸的IOU超过0.1的锚,然后将它们进行排序,选择前N个匹配的锚(这里的N就是阶段1的平均锚个数)。
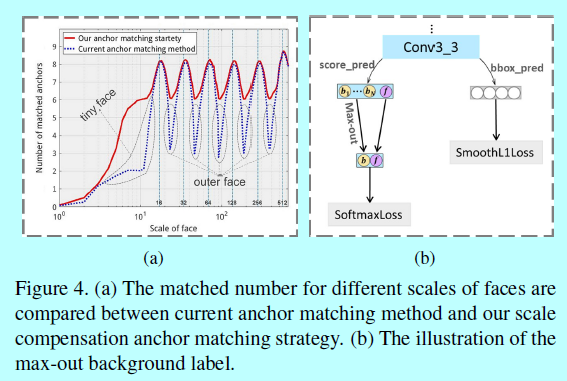
如图4a,这里的锚匹配策略极大的增加了关于极小和极大的人脸匹配的锚,这明显增加了这些人脸的召回率。
1.3 max-out 背景标签
基于锚的人脸检测模型可以被认为是一个二分类问题。而作者发现这是一个不平衡的二值分类问题:按照统计的结果,超过99.8%的预设定锚都属于负锚(即都是背景),只有一小部分是正锚(即人脸)。这极端的不平衡主要是受到检测小型人脸的问题引起的。特别的,为了检测小脸,需要早图像上平铺一堆锚,这导致负锚的数量极端增多。例如如表2,
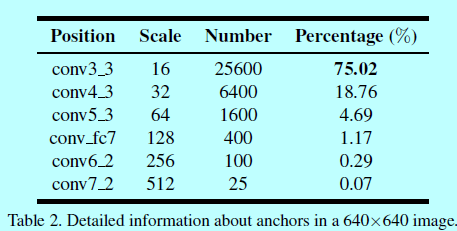
一个640x640的图片一共有34,125个锚,而差不多75%来自conv3_3检测层,该检测层又关联最小的检测锚(16x16)。这些最小的锚贡献了最多的假阳性人脸。所以通过平铺小型锚来提升小人脸检测结果也不可避免的增大了消息人脸的假阳性比例。
为了解决这个问题,作者提出了在最低层上采用一个更好的分类策略来处理来自小型锚的复杂背景。作者在conv3_3检测层上使用max-out 背景标签。对于每个最小的锚,需要预测\(N_m\)的背景标签的得分,然后选择最高分作为最终分手,如图4b。max-out操作将一些局部最优解集成到\(S^3FD\)模型中,从而减少最小人脸的假阳性比例。
1.4 训练 & loss函数 & 硬负样本挖掘
这部分,介绍下训练数据集,数据增强,loss函数,硬负样本挖掘和其他细节。
训练数据集:是WIDER FACE数据集;
数据增强:
- 颜色失真:采用一些图像测度的失真方法, 类似《Some improvements on deep convolutional neural network based image classification》;
- 随机裁剪:因为有太多小型人脸,所以通过放大操作来生成更大的人脸。特别的,每个图片都通过以下5种方式中的一种来完成该部分。裁剪最大的正方形,其他四种方形图片块来自原始图像最短边的[0.3,1]倍。这些裁剪图片块中都保证人脸区域的中心还在裁剪的块中;
- 水平翻转:在随机翻转中,选择的平方块被resize到640x640,然后以0.5的概率水平翻转。
loss 函数
采用RPN中定义的多任务loss:
这里\(i\)表示第几个锚,\(p_i\)表示关于第\(i\)个锚预测人脸的概率。这里ground-truth标签如果锚为正,则\(p_i^*\)是1,否则为0。\(t_i\)是一个向量,表示预测的边界框的4个参数化的坐标,\(t_i^*\)是关联一个正锚的ground-truth。分类loss\(L_{cls}(p_i,P_i^*)\)是基于2类的softmax loss。回归loss\(L_{reg}(t_i,t_i^*)\)是《Fast r-cnn》中定义的平滑L1 loss,\(P_i^*L_{reg}\)意味着回归loss只被正锚激活。这两项分别被\(N_{cls}\)和\(N_{reg}\)所归一化,并通过平衡参数\(\lambda\)所权重化。在我们的实现中,\(cls\)项是通过正锚和负锚的数量归一化,而\(reg\)项是通过正锚的数量归一化。因为正锚和负锚之间数量不平衡,所以引入\(\lambda\)进行平衡。
硬负样本挖掘
在锚匹配过程中,大多数锚都是负的,这引入一个明显的正负训练样本不平衡的问题。对于更快的优化和更稳定的训练,需要对负样本进行采样,那么就按照loss进行排序,并挑选排序前面的样本,保持负正样本比例3:1。在使用硬负样本挖掘后,我们将上面的背景标签\(N_m=3\),且\(\lambda=4\)来平衡分类和回归的loss。
其他细节
比如参数初始化,这里急促和卷积层与VGG16采用一样的结构,他们的参数也是《Imagenet large scale visual recognition challenge》进行预训练的。conv_fc6,conv_fc7通过VGG16的fc6和fc7进行子采样来初始化,其他的额外从通过xavier方式初始化。通过带有0.9动量的SGD来训练,权重衰减值为0.0005,batchsize为32。最大的迭代次数为120k,前80k次学习率为0.001,后20k为0.0001,然后接下来20k为0.00001。基于caffe实现。
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号