
face detection[FaceBoxes]
该文来自《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》。该文时间线是2018年1月
虽然人脸检测上随着深度学习的普及,引来了巨大的进步,可是如何在CPU环境下实时的保持高准确度是一个难题,因为高准确度的网络往往伴随着大量的计算。本文提出的模型就是如何在CPU环境下依然保持高准确度。为此Shifeng Zhang提出了FaceBoxes,一个轻量级且强大的网络结构,其中包含:
- 快速消解卷积层(rapidly digested convolutional layers,RDCL);
- 多尺度卷积层(Multiple Scale Convolutional Layers,MSCL)。
其中RDCL设计用来确保FaceBoxes能在CPU上获得实时的能力;而MSCL为了丰富不同网络层上的感受野和离散的锚点以帮助处理不同尺度的人脸。同时,提出了一个新的锚增密策略来让不同类型的锚在图片上都有相同的密度,这明显的提升了在小人脸上的召回度。提出的检测器在单CPU核上可以跑到20FPS,在GPU上可以跑到125FPS。并且FaceBoxes的速度对于人脸的数量具有不变性。
0 引言
人脸检测中的挑战主要来自2个方向:
- 在嘈杂背景下人脸具有较大的视觉变化,需要处理复杂的人脸二分类问题;
- 搜索空间很大:基于可控时间内,对人脸可能存在的位置以及人脸尺度进行搜索。
如上述两个问题,所以如何保证实时性,然后网络结构又不复杂,且高准确度一直是个难点。而之前提出的级联CNN虽然进一步加速了整个检测过程,不过其本身还是有不少问题:
- 检测速度是相对图片中人脸的个数的,如果图片中人脸数量很多,那么整体速度就会下降了;
- 该方法在训练的时候是几个网络单独训练的,从而让训练变得相对复杂,而且最后输出的哦模型不是最优的;
- 对于VGA分辨率的图片,在CPU上运行的效率是14FPS,还是赶不上实时的速度。
受到Faster RCNN中的RPN和SSD的多尺度机制的启发,作者提出了一个能在CPU上跑出实时的模型,叫FaceBoxes。其只包含一个全卷积网络,且能end to end的训练。
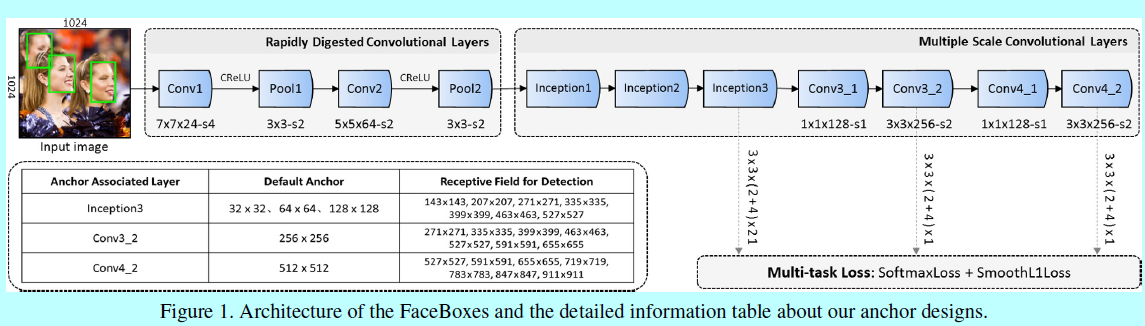

如图1,其中包含快速消融卷积层(RDCL)和多尺度卷积层(MSCL)。所以本文的主要贡献:
- 设计了RDCL用来确保CPU上的实时性;
- 引入了MSCL用来丰富不同网络层上的感受野和离散锚从而处理多尺度的人脸;
- 提出了一个新的锚增密策略来提升小脸的召回率;
- 让AFW, PASCAL人脸,FDDB数据集上的最好结果又提升了。
1 结构
1.1 快速消解卷积层 RDCL
RDCL设计之初就是为了快速将图像的尺度将下去,并相对其他网络减少通道数,从而确保FaceBoxes能够实时:
- 快速降低输入的空间尺度:通过在卷积层和池化层引入一系列大strides,如图1所示,Conv1,Pool1,Conv2和Pool2的stride分别是4,2,2,2.总的RDCL是32,意味着输入图片的空间尺度被减小了32倍;
- 选择合适的核尺度:网络中最开始的层上核尺度应该是小的,从而才能加速。同时它也应该足够大,以减轻空间尺寸减小带来的信息损失。如图1,为了尽可能保持高效,在Conv1,Conv2,Conv3上分别选择7x7,5x5,3x3的卷积核;
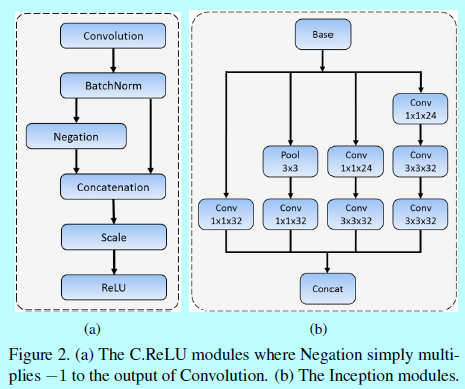
- 减少输出的通道数:这里利用C.ReLU激活函数(如图2(a)),去减少输出的通道数。C.ReLU是来自CNN的观察,其中较低层中的滤波器会形成对(即滤波器具有相反相位)。 根据这一观察,C.ReLU可以通过在ReLU之前简单地concatenating否定的输出来使输出通道的数量加倍。 使用C.ReLU可显着提高速度,而且精度基本没下降。
1.2 多尺度卷积层 MSCL
RPN原来是基于多类别目标检测提出的,而人脸检测就是个单类别。而作为独立的人脸检测器,RPN并不能提供很高的性能。作者认为这样的现象主要来自两个方面:
- RPN中的锚只与最后的卷积层相关联,而一层卷积层含有的特征和分辨率对于抓取不同尺度的人脸来说太弱了;
- 一个关联锚的层(RPN层)需要负责在一个尺度范围内检测人脸,但是一个感受野(此时是基于一个划窗位置上,这里参考faster rcnn的RPN部分)并不能匹配不同尺度的人脸。
为了解决上述2个问题,MSCL主要遵循下面2个维度:
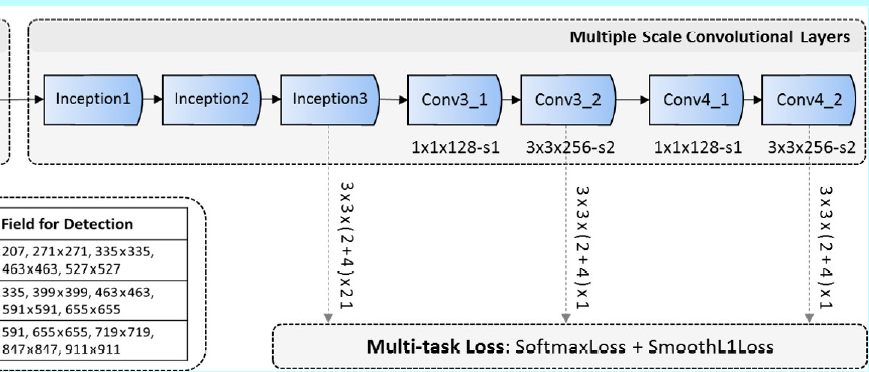
- 基于网络深度的多尺度设计:如图1,MSCL包含几层,这些层在尺寸上是逐步减小的,因此形成一个多尺度feature map。如SSD,这里默认的锚是关联着多尺度feature map(即,Inception3,Conv3_2,Conv4_2)。这些层就如基于网络深度这个维度上进行的多尺度设计,基于不同分辨率的多层去分散锚能够处理不同尺度的人脸;
- 基于网络宽度的多尺度设计:为了学习不同尺度人脸的模式,关联锚的层的输出特征应该对应不同尺度的感受野,这可以容易的通过Inception模块去实现。Inception模块包含不同核的多个卷积分支。这些分支作为网络宽度上的多尺度设计,如图1中,MSCL前三个层都是基于Inception实现的。图2(b)详细介绍了Inception模块,用于捕捉不同尺度的人脸。
1.3 锚增密策略
如图1,这里引入的是1:1的默认锚(即平方锚),因为人脸大多都是正方形的。Inception3层中锚的尺度分别是32,64,128;而Conv3_2和Conv4_2层上锚的尺度分别是256和512个像素。
图像上锚点的平铺间隔等于相应关联锚的层的stride大小。例如,Conv3_2的stride是64个像素,他对应的锚是256x256,表示对于输入图片上每64个像素点就有256x256的一个锚。这里定义锚的平铺密度(即\(A_{density}\)):
这里\(A_{scale}\)是锚的尺度,\(A_{interval}\)是锚的平铺间隔。这里默认锚的平铺间隔是32,32,32,64,128。按照上面的式子,对应的密度是1,2,4,4,4。很明显的,这里锚的不同尺度之间存在平铺密度不平衡的问题。相对与大锚(如128x128,256x256,512x512),小锚(如32x32,64x64)太稀疏了,这导致小脸的低召回率。
为了消除这种不平衡,提出了一个新的锚增密策略。特别的,为了增密一个类型的锚n次,我们在一个感受野的中心周围均匀平铺\(A_{number}=n^2\)个锚,而不是只平铺一个锚。如图3
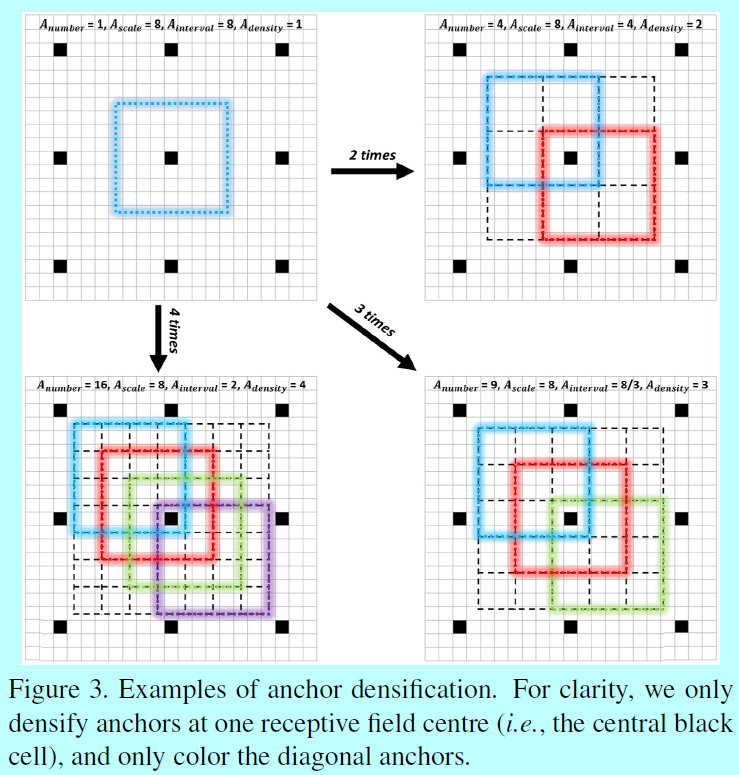
为了提升小锚的平铺密度,作者的策略是使用32x32的锚4次,64x64的锚2次,这保证了不同尺度的锚有相同的密度(即 4),所以不同尺度的人脸就能匹配差不多相同数量的锚。
1.4 训练
这里介绍了训练数据集,数据增强,匹配策略,loss函数,硬负样本挖掘,和其他技术细节。
训练数据集:WIDER FACE
数据增强:每个图片都经历下面的策略:
- 颜色失真:如《Some improvements on deep convolutional neural network based image classification》中的照片失真方法;
- 随机裁剪:从原始图片中随机裁剪5个图片:一个是最大的平方块,其他的是基于最短边的[0.3,1]的尺寸。然后从这5张中随机挑一张给后续处理流程;
- 尺度变化:将裁剪后的图片resize成1024x1024;
- 水平翻转:将resize之后的图片以0.5的概率水平翻转;
- 人脸框过滤:保留那些人脸框的中心还在的图片;将那些人脸框的高或者框小于20的图片删掉。
匹配策略:在训练中,需要检测哪个锚对应哪个人脸框。首先匹配最高IOU值的锚,然后匹配那些IOU高于0.35的锚;
loss 函数:如faster rcnn中的RPN的loss,这里基于二值softmax做人脸分类,用L1平滑loss做回归。
硬负样本挖掘:在锚匹配之后,大部分都是负的,这时候会造成正负样本失衡,所以基于loss进行排序,挑选最高的那些,保证负正样本比例为3:1
其他策略:采用xavier方法初始化,用带有0.9动量的SGD做迭代,权重衰减的系数为0.0005,batchsize为32.最大的迭代次数为120k,采用基于钱80k的迭代,采用0.001作为学习率;基于后面的20k,20k次,分别采用0.0001和0.00001作为学习率。并基于caffe实现。
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号