生产prometheus-operator 监控二进制kubernetes
什么是 Operator?
operator是由CoreOS公司开发的,用来扩展kubernetes APi ,特定的应用程序控制器,它用来创建,配置和管理复杂的有状态应用,例如数据库,缓存和监控系统。Operator基于Kubernetes的资源和控制器概念之上构建,但同时又包含了应用程序特定的一些专业知识,比如创建一个数据库的Operator,则必须对创建的数据库和各种运维方式非常了解,创建operator的关键是 CRD(CustomResourceDefinition/自定义资源定义)的设计。
CRD 是对Kubernetes APi的扩展,Kubernetes中的每个资源都会是一个API对象的集合,例如我们在YAML文件里定义的那些
spec都是对 Kubernetes 中的资源对象的定义,所有的自定义资源可以跟 Kubernetes 中内建的资源一样使用 kubectl 操作。
Operate是将运维人员对软件操作的知识给代码化,同时利用Kubernetes强大的抽象来管理大规模的软件应用,目前CoreOS官方提供了几种Operator的实现,其中就包括我们今天的主角:Prometheus Operator,Operator的核心实现就是基于 Kubernetes 的以下两个概念:
- 资源:对象的状态定义
- 控制器:观测、分析和行动,以调节资源的分布
当然我们如果有对应的需求也完全可以自己去实现一个Operator,接下来我们就来给大家详细介绍下Prometheus-Operator的使用方法。
介绍Prometheus-Operator
首先我们先来了解下Prometheus-Operator的架构图:
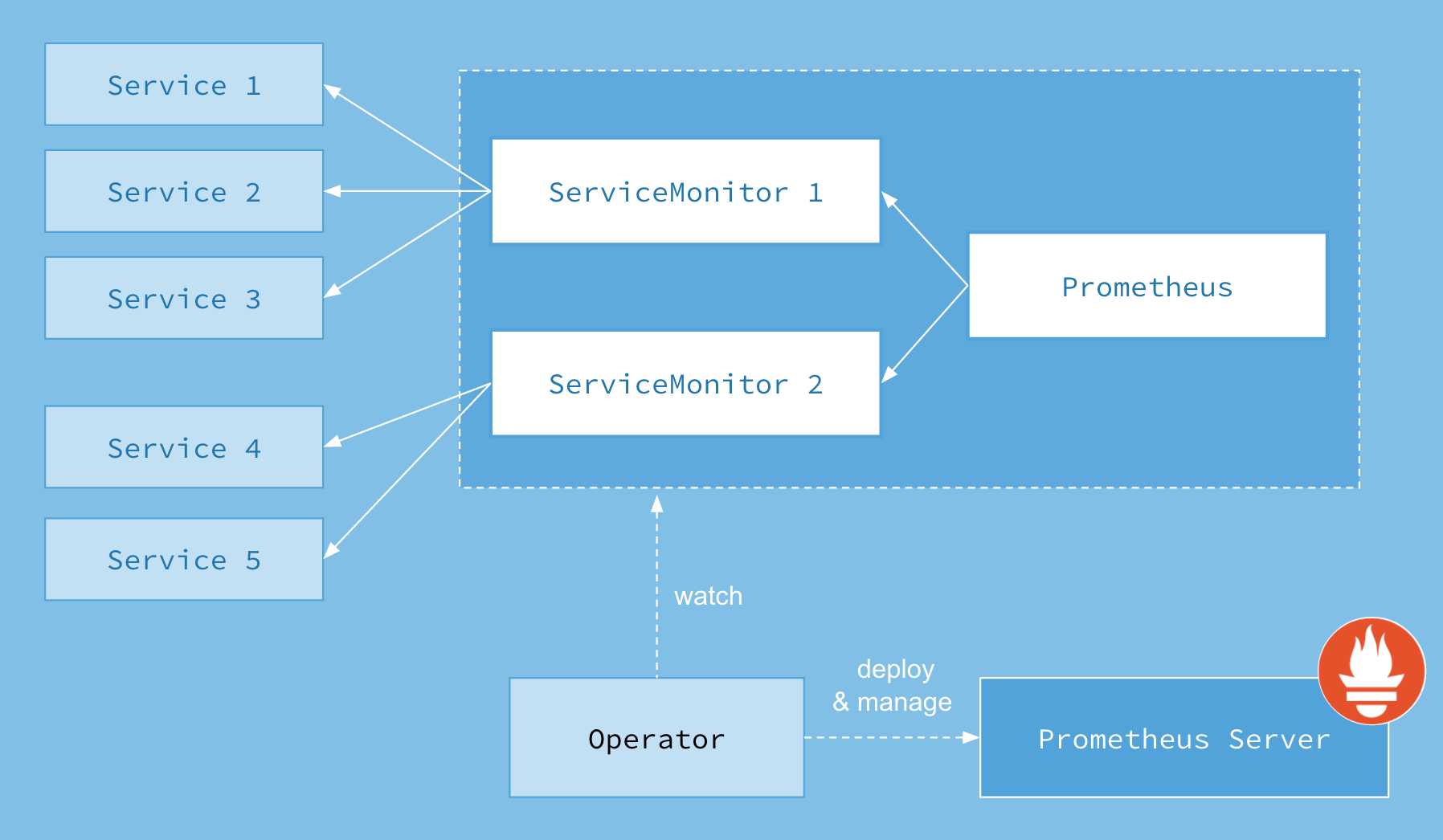
上图是Prometheus-Operator官方提供的架构图,其中Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的prometheus这种资源对象就是作为Prometheus Server存在,而ServiceMonitor就是exporter的各种抽象,exporter前面我们已经学习了,是用来提供专门提供metrics数据接口的工具,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的,当然alertmanager这种资源对象就是对应的AlertManager的抽象,而PrometheusRule是用来被Prometheus实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
1,service 和Endpoint 通过名称来相对应,不管是k8s集群外部来时k8s集群内部,只要svc 下面有资源(Pod)那么他就会对应有 endpoint
2,ServerMonitor 通过lable 来匹配service的,后面详细讲解如何匹配
3,prometheus 通过
Prometheus.spec.serviceMonitorNamespaceSelector和Prometheus.spec.serviceMonitorSelector来匹配ServerMonitor
安装Prometheus-operate
我们这里采用prometheus-operate 源码来安装。
官方给出的一个版本监控测试表,我们查看自己安装的kubernetes 版本,然后选择prometheus-operate对应的版本,防止出现不兼容情况

注意:由于Kubernetes v1.16.1和Kubernetes v1.16.5之前的两个bug,kube-prometheus release-0.4分支只支持v1.16.5及以上版本。可以手动编辑 kube-system 命名空间中的 extension-apiserver-authentication-reader 角色,以包含 list 和 watch 权限,从而解决 Kubernetes v1.16.2 至 v1.16.4 中的第二个问题。
我这边集群是1.15版本,所以我就拉去release-0.3版本,首先Clone 代码
git clone https://github.com/prometheus-operator/kube-prometheus.git
git checkout release-0.3
最新的版本官方将资源https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus迁移到了独立的 git 仓库中:https://github.com/coreos/kube-prometheus.git
官方把所有文件都放在一起了,我们给他分开存放
mkdir kube-prom
cp -a kube-prometheus/manifests/* kube-prom/
cd kube-prom/
mkdir -p node-exporter alertmanager grafana kube-state-metrics prometheus serviceMonitor adapter
mv *-serviceMonitor* serviceMonitor/
mv setup operator/
mv grafana-* grafana/
mv kube-state-metrics-* kube-state-metrics/
mv alertmanager-* alertmanager/
mv node-exporter-* node-exporter/
mv prometheus-adapter* adapter/
mv prometheus-* prometheus/
$ ll
total 32
drwxr-xr-x 2 root root 4096 Dec 2 09:53 adapter
drwxr-xr-x 2 root root 4096 Dec 2 09:53 alertmanager
drwxr-xr-x 2 root root 4096 Dec 2 09:53 grafana
drwxr-xr-x 2 root root 4096 Dec 2 09:53 kube-state-metrics
drwxr-xr-x 2 root root 4096 Dec 2 09:53 node-exporter
drwxr-xr-x 2 root root 4096 Dec 2 09:34 operator
drwxr-xr-x 2 root root 4096 Dec 2 09:53 prometheus
drwxr-xr-x 2 root root 4096 Dec 2 09:53 serviceMonitor
$ ll operator/
total 660
-rw-r--r-- 1 root root 60 Dec 2 09:34 0namespace-namespace.yaml
-rw-r--r-- 1 root root 274629 Dec 2 09:34 prometheus-operator-0alertmanagerCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 12100 Dec 2 09:34 prometheus-operator-0podmonitorCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 321507 Dec 2 09:34 prometheus-operator-0prometheusCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 14561 Dec 2 09:34 prometheus-operator-0prometheusruleCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 17422 Dec 2 09:34 prometheus-operator-0servicemonitorCustomResourceDefinition.yaml
-rw-r--r-- 1 root root 425 Dec 2 09:34 prometheus-operator-clusterRoleBinding.yaml
-rw-r--r-- 1 root root 1066 Dec 2 09:34 prometheus-operator-clusterRole.yaml
-rw-r--r-- 1 root root 1405 Dec 2 09:34 prometheus-operator-deployment.yaml
-rw-r--r-- 1 root root 239 Dec 2 09:34 prometheus-operator-serviceAccount.yaml
-rw-r--r-- 1 root root 420 Dec 2 09:34 prometheus-operator-service.yaml
有些版本的k8s的label为beta.kubernetes.io/os,
// 查看当前k8s集群nodes 上面的label标签
# cat > label.sh <<-'EOF'
#!/bin/bash
kubectl get nodes -o go-template='{{printf "%-39s %-12s\n" "Node" "Label"}}
{{- range .items}}
{{- if $labels := (index .metadata.labels) }}
{{- .metadata.name }}{{ "\t" }}
{{- range $key, $value := $labels }}
{{$key}}{{ "\t" }}{{$value}}
{{- end }}
{{- "\n" }}
{{- end}}
{{- end}}'
EOF
# bash label.sh
Node Label
jx4-74.host.com
beta.kubernetes.io/arch amd64
beta.kubernetes.io/os linux
kubernetes.io/arch amd64
kubernetes.io/hostname jx4-74.host.com
kubernetes.io/os linux
node-role.kubernetes.io/master
node-role.kubernetes.io/node
jx4-75.host.com
beta.kubernetes.io/arch amd64
beta.kubernetes.io/os linux
kubernetes.io/arch amd64
kubernetes.io/hostname jx4-75.host.com
kubernetes.io/os linux
node-role.kubernetes.io/master
node-role.kubernetes.io/node
jx4-76.host.com
beta.kubernetes.io/arch amd64
beta.kubernetes.io/os linux
kubernetes.io/arch amd64
kubernetes.io/hostname jx4-76.host.com
kubernetes.io/os linux
node-role.kubernetes.io/node
如果是上面这种没有kubernetes.io/os: linux的情况则需要修改yaml里的nodeselector字段
$ grep -A1 nodeSelector alertmanager/alertmanager-alertmanager.yaml
nodeSelector:
kubernetes.io/os: linux
需要修改下面这些文件:
adapter/prometheus-adapter-deployment.yaml
alertmanager/alertmanager-alertmanager.yaml
grafana/grafana-deployment.yaml
kube-state-metrics/kube-state-metrics-deployment.yaml
node-exporter/node-exporter-daemonset.yaml
operator/prometheus-operator-deployment.yaml
prometheus/prometheus-prometheus.yaml
里面镜像使用的是 quay.io 的,因为我们自己有镜像仓库,所以我们提前先把Docker包拉去下来,然后传到自己仓库里去
# grep "quay.io" -r *| awk -F '[ =]' '{print $NF}' | sort |uniq
quay.io/coreos/configmap-reload:v0.0.1
quay.io/coreos/k8s-prometheus-adapter-amd64:v0.5.0
quay.io/coreos/kube-rbac-proxy:v0.4.1
quay.io/coreos/kube-state-metrics:v1.8.0
quay.io/coreos/prometheus-config-reloader:v0.34.0
quay.io/coreos/prometheus-operator:v0.34.0
quay.io/prometheus/alertmanager
quay.io/prometheus/node-exporter:v0.18.1
quay.io/prometheus/prometheus
# 需要更改的文件内容如下,自行更改这里不再过多的介绍
adapter/prometheus-adapter-deployment.yaml
grafana/grafana-deployment.yaml
kube-state-metrics/kube-state-metrics-deployment.yaml
node-exporter/node-exporter-daemonset.yaml
operator/prometheus-operator-deployment.yaml
部署Operator
这个需要提前部署
kubectl apply -f operator/
确认正常之后在往后执行
# kubectl -n monitoring get pods
NAME READY STATUS RESTARTS AGE
prometheus-operator-58bc77f954-q54pw 1/1 Running 0 33h
部署整套CRD
kubectl apply -f adapter/
kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f grafana/
kubectl apply -f prometheus/
kubectl apply -f serviceMonitor/
如果我们使用的是自己的harbor 仓库,这一步应该很快就结束了。
# kubectl -n monitoring get all
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 0 33h
pod/alertmanager-main-1 2/2 Running 0 33h
pod/alertmanager-main-2 2/2 Running 0 33h
pod/grafana-848969744d-6dxgb 1/1 Running 0 33h
pod/kube-state-metrics-5dd8b47cbb-nf68s 3/3 Running 0 33h
pod/node-exporter-4glkn 0/2 Pending 0 33h
pod/node-exporter-8p7c9 0/2 Pending 0 33h
pod/node-exporter-lh77n 0/2 Pending 0 33h
pod/prometheus-adapter-578c5c64b6-bzlp6 1/1 Running 0 33h
pod/prometheus-k8s-0 3/3 Running 1 33h
pod/prometheus-k8s-1 3/3 Running 1 33h
pod/prometheus-operator-58bc77f954-q54pw 1/1 Running 0 33h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.16.131.214 <none> 9093/TCP 33h
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 33h
service/grafana ClusterIP 10.16.36.173 <none> 3000/TCP 33h
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 33h
service/node-exporter ClusterIP None <none> 9100/TCP 33h
service/prometheus-adapter ClusterIP 10.16.212.212 <none> 443/TCP 33h
service/prometheus-k8s ClusterIP 10.16.156.122 <none> 9090/TCP 33h
service/prometheus-operated ClusterIP None <none> 9090/TCP 33h
service/prometheus-operator ClusterIP None <none> 8080/TCP 33h
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/node-exporter 3 3 0 3 0 kubernetes.io/os=linux 33h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/grafana 1/1 1 1 33h
deployment.apps/kube-state-metrics 1/1 1 1 33h
deployment.apps/prometheus-adapter 1/1 1 1 33h
deployment.apps/prometheus-operator 1/1 1 1 33h
NAME DESIRED CURRENT READY AGE
replicaset.apps/grafana-848969744d 1 1 1 33h
replicaset.apps/kube-state-metrics-5dd8b47cbb 1 1 1 33h
replicaset.apps/prometheus-adapter-578c5c64b6 1 1 1 33h
replicaset.apps/prometheus-operator-58bc77f954 1 1 1 33h
NAME READY AGE
statefulset.apps/alertmanager-main 3/3 33h
statefulset.apps/prometheus-k8s 2/2 33h
部署ingress 使其能通过web界面访问
根据自己的实际情况进行更改
# cat ingress.yml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kube-prometheus
namespace: monitoring
spec:
rules:
- host: prometheus.zsf.com
http:
paths:
- path: /
backend:
serviceName: prometheus-k8s
servicePort: 9090
- host: grafana.zsf.com
http:
paths:
- path: /
backend:
serviceName: grafana
servicePort: 3000
到此为止prometheus 基本部署完成,但是我们要解决其中的几个遗漏问题
遗留问题处理
kube-controller-manager 和 kube-scheduler 无监控数据
这里要注意有一个坑,二进制部署k8s管理组件和新版本kubeadm部署的都会发现在prometheus server的页面上发现kube-controller和kube-schedule的target为0/0也就是上图所示
这是因为serviceMonitor是根据label去选取svc的,我们可以看到对应的serviceMonitor是选取的ns范围是kube-system
# cat serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml
...
spec:
endpoints:
...
...
port: http-metrics
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-scheduler
# cat serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml
...
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-controller-manager
而默认的 kube-system 里面没有符合上面的svc,所以读取不到
# kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
coredns ClusterIP 10.16.0.2 <none> 53/UDP,53/TCP,9153/TCP 9d
heapster ClusterIP 10.16.157.201 <none> 80/TCP 7d20h
kubelet ClusterIP None <none> 10250/TCP 2d
kubernetes-dashboard ClusterIP 10.16.232.114 <none> 443/TCP 8d
traefik-ingress-service ClusterIP 10.16.193.162 <none> 80/TCP,8080/TCP 9d
但是却有对应的ep(没有带任何label)被创建
解决上述这个问题的办法,我们手动创建一个
# cat prometheus-kubeMasterService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
注意:
Service.spec.ports.name要和ServiceMonitor.spec.endpoints.port对应起来
Service.metadata.namespace要和ServiceMonitor.namespaceSelector.matchNames对应起来
Service.metadata.labels的key要和ServiceMonitor.JobLabel对应起来
Service.metadata.labels要和ServiceMonitor.selector.matchLabels`对应起来
如果是kubeadm 部署的,我们可以查看下controller-manager和scheduler的标签,然后添加Service.spec.selector
...
spec:
selector:
component: kube-scheduler
type: ClusterIP
...
二进制的话需要我们手动填入svc对应的ep的属性,我集群是HA的,所有有三个,仅供参考,别傻傻得照抄,另外这个ep的名字得和上面的svc的名字和属性对应上
# cat prometheus-kubeMasterEndPoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.4.74
- ip: 192.168.4.75
ports:
- name: http-metrics
port: 10252
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.4.74
- ip: 192.168.4.75
ports:
- name: http-metrics
port: 10251
protocol: TCP
然后上述那个问题就不会存在了。
监控只能看到三个Namespaces
默认serviceMonitor实际上只能选三个namespacs,默认和Kube-system和monitoring,见文件cat prometheus-roleSpecificNamespaces.yaml,需要其他的ns自行创建role,我们只需要对着抄一下就行
- apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: prometheus-k8s
namespace: monitoring
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
上述其实只需要更改namespace字段
Apiserver 一直处于 Down 的状态

这个是因为我们自己的证书是自己生成的,并没有通过第三方证书厂商认证,就想我们自己生成的证书放在 nginx 上之后我们通过 curl 的时候会提示证书不可信,这个时候我们可以使用如下操作 对证书不进行验证,我们只需要不验证证书就行了。
$ vim serviceMonitor/prometheus-serviceMonitorKubelet.yaml
...
tlsConfig:
insecureSkipVerify: true
jobLabel: k8s-app
...
然后重新运行之后发现正常,就不会报错 401 了。
kubelet 不正常
在 kubelet 启动的时候添加了下面两个参数就正常了
--authentication-token-webhook="true" \
--authorization-mode="Webhook"
生产中的优化
prometheus 数据持久化
官方默认的部署方式不是数据持久化的,如果有对应的需求,需要我们自己来修改
我们通过 prometheus 这个 CRD 创建的 Prometheus 并没有做数据的持久化,我们可以直接查看生成的 Prometheus Pod 的挂载情况就清楚了:
$ kubectl get pod prometheus-k8s-0 -n monitoring -o yaml
......
volumeMounts:
- mountPath: /etc/prometheus/config_out
name: config-out
readOnly: true
- mountPath: /prometheus
name: prometheus-k8s-db
......
volumes:
......
- emptyDir: {}
name: prometheus-k8s-db
......
我们可以看到 Prometheus 的数据目录 /prometheus 实际上是通过 emptyDir 进行挂载的,我们知道 emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,所以如果 Pod 挂掉了,数据也就丢失了,这也就是为什么我们重建 Pod 后之前的数据就没有了的原因,对应线上的监控数据肯定需要做数据的持久化的,同样的 prometheus 这个 CRD 资源也为我们提供了数据持久化的配置方法,
$ vim operator/prometheus-operator-0prometheusCustomResourceDefinition.yaml
....
storage:
description: StorageSpec defines the configured storage for a group
Prometheus servers. If neither `emptyDir` nor `volumeClaimTemplate`
is specified, then by default an [EmptyDir](https://kubernetes.io/docs/concepts/storage/volumes/#emptydir)
will be used.
properties:
emptyDir:
description: Represents an empty directory for a pod. Empty directory
volumes support ownership management and SELinux relabeling.
properties:
medium:
description: 'What type of storage medium should back this directory.
The default is "" which means to use the node''s default medium.
Must be an empty string (default) or Memory. More info: https://kubernetes.io/docs/concepts/storage/volumes#emptydir'
type: string
sizeLimit: {}
type: object
volumeClaimTemplate:
description: PersistentVolumeClaim is a user's request for and claim
to a persistent volume
properties:
apiVersion:
description: 'APIVersion defines the versioned schema of this
representation of an object. Servers should convert recognized
schemas to the latest internal value, and may reject unrecognized
values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources'
type: string
kind:
description: 'Kind is a string value representing the REST resource
this object represents. Servers may infer this from the endpoint
the client submits requests to. Cannot be updated. In CamelCase.
More info: https://git.k8s.io/community
....
由于我们的 Prometheus 最终是通过 Statefulset 控制器进行部署的,所以我们这里需要通过 storageclass 来做数据持久化,首先创建一个 StorageClass 对象:
我们这里是使用 nfs 做 storageClass,存储类的,具体配置如下:
nfs 服务安装在 192.168.4.73,共享的目录为/home/volume
因为 nfs 默认不支持 storageClass ,所以我们需要安装一个外部插件,https://kubernetes.io/zh/docs/concepts/storage/storage-classes/ 那些存储直接支持,可以查看官方文档,我们这里面安装nfs-client 插件,官方地址为:https://github.com/kubernetes-retired/external-storage/tree/master/nfs-client/deploy
创建 rbac 授权
$ vim storage/prometheus-nfs-client-rbac.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["list", "watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
创建 nfs-client 启动文件:
$ vim storage/prometheus-nfs-client-deployment.yml
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.4.73 #nfs server 地址
- name: NFS_PATH
value: /home/volume #nfs共享目录
volumes:
- name: nfs-client-root
nfs:
server: 192.168.4.73
path: /home/volume
创建 storageClass 对象
$ cat storage/prometheus-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: prometheus-data-db
provisioner: fuseim.pri/ifs #对应PROVISIONER_NAME 的值
这里我们声明Storageclass对象,其中provisioner=fuseim.pri/ifs,则是我们集群中使用NFS作为后端存储
创建所有资源
cd storage
kubectl create -f .
然后我们在 prometheus 添加如下配置
$ vim
...
spec:
storage:
volumeClaimTemplate:
spec:
storageClassName: prometheus-data-db
resources:
requests:
storage: 10Gi
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
...
然后重新执行启动:
kubectl apply -f prometheus/prometheus-prometheus.yaml
查看结果:
$ kubectl get pvc -n monitoring
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-72a5cb90-8065-4ce8-be47-a01ced7dc152 10Gi RWO prometheus-data-db 31s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-8f4b7527-06f7-41de-9bef-39f10a6c354c 10Gi RWO prometheus-data-db 31s
$ kubectl get pv -n monitoring
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
grafana 5Gi RWO Recycle Available 2d14h
pvc-72a5cb90-8065-4ce8-be47-a01ced7dc152 10Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-0 prometheus-data-db 43s
pvc-8f4b7527-06f7-41de-9bef-39f10a6c354c 10Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-1 prometheus-data-db 43s
Grafana 数据持久化
创建 pv-pvc
# cat grafana-pv-pvc.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-volume
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 192.168.4.73
path: /home/kubernetes-volume/grafana
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-volume
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
创建 pv-pvc 并查看资源是否绑定
# kubectl apply -f grafana-pv-pvc.yaml
# kubectl get -n monitoring pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
grafana-volume Bound grafana 5Gi RWO 59s
更改 grafana 资源清单
$ vim grafana/grafana-deployment.yaml
# volumes:
# - emptyDir: {}
# name: grafana-storage
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-volume
Grafana 修改
官方的yaml grafana-dashboardDefinitions.yaml里面很多promQL的metrics名字还是老的,需要改,后续有空更新
API server
kubelet部分
operation Rate`的`kubelet_runtime_operations_total` –> `kubelet_runtime_operations
[root@k8s-m1 ~]# curl -sSk --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key https://172.16.0.4:10250/metrics | grep -P kubelet_runtime_operations
# HELP kubelet_runtime_operations Cumulative number of runtime operations by operation type.
# TYPE kubelet_runtime_operations counter
kubelet_runtime_operations{operation_type="container_status"} 94
...
operation Error Rate`的`kubelet_runtime_operations_errors_total` –> `kubelet_runtime_operations_errors
# HELP kubelet_runtime_operations_errors Cumulative number of runtime operation errors by operation type.
# TYPE kubelet_runtime_operations_errors counter
kubelet_runtime_operations_errors{operation_type="container_status"} 8
kubelet_runtime_operations_errors{operation_type="pull_image"} 13
Pod部分
下面三个的pod改成pod_name,是Network I/O
grep container_network_ grafana-dashboardDefinitions.yaml
"expr": "sort_desc(sum by (pod) (irate(container_network_receive_bytes_total{job=\"kubelet\", cluster=\"$cluster\", namespace=\"$namespace\", pod=\"$pod\"}[4m])))",
"expr": "sort_desc(sum by (pod) (irate(container_network_transmit_bytes_total{job=\"kubelet\", cluster=\"$cluster\", namespace=\"$namespace\", pod=\"$pod\"}[4m])))",
"expr": "sum(rate(container_network_transmit_bytes_total{job=\"kubelet\", cluster=\"$cluster\", namespace=\"$namespace\", pod=~\"$statefulset.*\"}[3m])) + sum(rate(container_network_receive_bytes_total{cluster=\"$cluster\", namespace=\"$namespace\",pod=~\"$statefulset.*\"}[3m]))",
Total Restarts Per Container
参考资料
https://juejin.im/post/6865504989695967245
https://zhangguanzhang.github.io/2018/10/12/prometheus-operator/#部署官方的prometheus-operator
https://www.qikqiak.com/post/first-use-prometheus-operator/
https://www.qikqiak.com/post/prometheus-operator-monitor-etcd/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号