论文阅读 | Pre-trained Models for Natural Language Processing: A Survey
论文:Pre-trained Models for Natural Language Processing: A Survey
-
首先简要介绍了语言表示学习及相关研究进展;
-
其次从四个方面对现有 PTM (Pre-trained Model) 进行系统分类(Contextual、Architectures、Task Types、Extensions);
-
再次描述了如何将 PTM 的知识应用于下游任务;
-
最后展望了未来 PTM 的一些潜在发展方向。
第一代 PTM 旨在学习词嵌入。由于下游的任务不再需要这些模型的帮助,因此为了计算效率,它们通常采用浅层模型,如 Skip-Gram 和 GloVe。尽管这些经过预训练的嵌入向量也可以捕捉单词的语义,但它们却不受上下文限制,只是简单地学习「共现词频」。这样的方法明显无法理解更高层次的文本概念,如句法结构、语义角色、指代等等。
第二代 PTM 专注于学习上下文的词嵌入,如 CoVe、ELMo、OpenAI GPT 以及 BERT。它们会学习更合理的词表征,这些表征囊括了词的上下文信息,可以用于问答系统、机器翻译等后续任务。另一层面,这些模型还提出了各种语言任务来训练 PTM,以便支持更广泛的应用,因此它们也可以称为预训练语言模型。
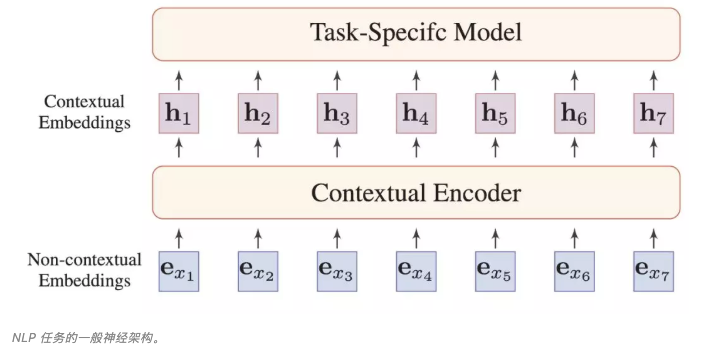
如上图所示,之前 NLP 任务一般会预训练 e 这些不包含上下文信息的词嵌入,我们会针对不同的任务确定不同的上下文信息编码方式,以构建特定的隐藏向量 h,从而进一步完成特定任务。
但对于预训练语言模型来说,我们的输入也是 e 这些嵌入向量,不同之处在于我们会在大规模语料库上预训练 Contextual Encoder,并期待它在各种情况下都能获得足够好的 h,从而直接完成各种 NLP 任务。换而言之,最近的一些 PTM 将预训练编码的信息,提高了一个层级。
各种预训练方法的主要区别在于文本编码器、预训练任务和目标的不同。
现有的预训练方法分为四部分:
- 预训练方法(PTM)使用的词表征类型;
- 预训练方法使用的主干网络;
- PTM 使用的 预训练任务类型;
- 为特定场景与输入类型所设计的 PTM。
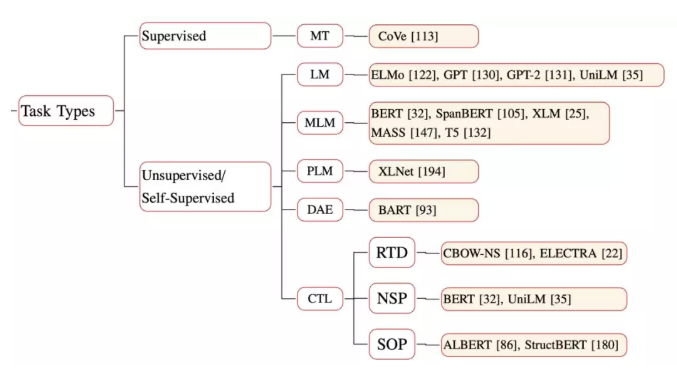
图 3 详细地展示了各种 PTM 的所属类别:
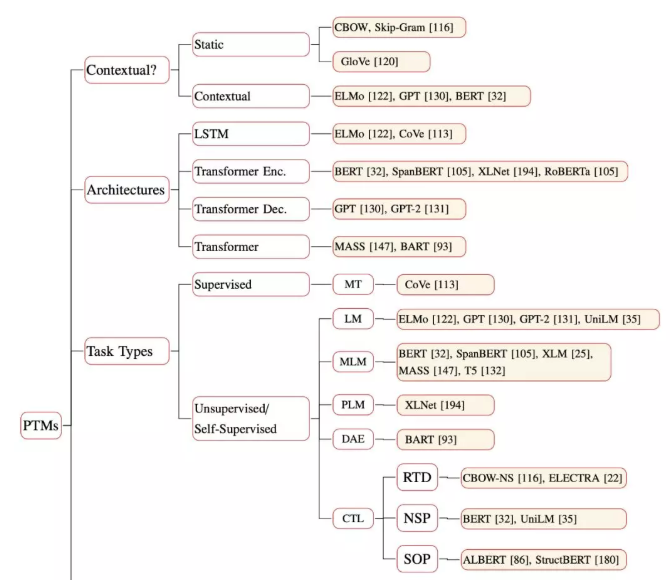
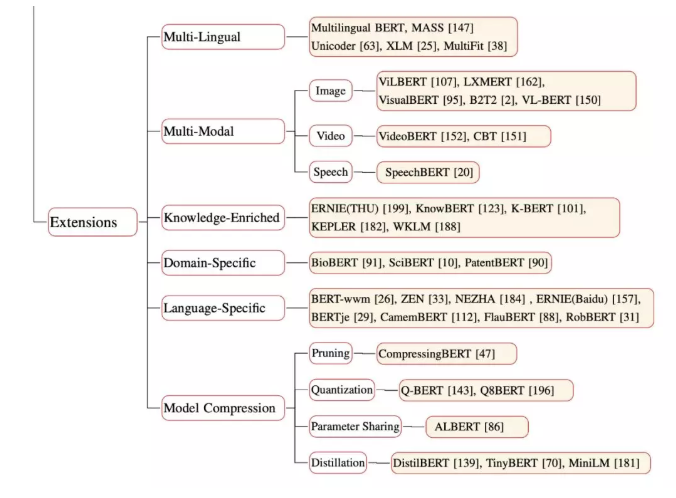
细节对比:
预训练任务
预训练任务的目的在于,迫使模型学习自然语言的各种结构与意义,这才有可能将通用语言知识嵌入到模型内。
NLP 中最常见的无监督任务是概率语言建模(language modeling),它是一个经典的概率密度估值问题。实际上,作为一种一般性概念,语言建模通常特指自回归或单向语言建模。传统语言建模用下面一个公式就能说清楚,即每次给定前面所有词下预测下一个词。
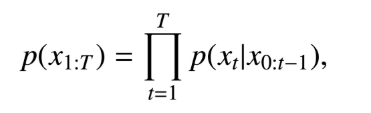
Wilson L. Taylor 等人在论文《「cloze procedure」: A new tool for measuring readability》的文献中首次提出了掩码语言建模(masked language modeling,MLM)概念,他们称之为完形填空(Cloze)任务。接着,Jacob Devlin 等人在 BERT 中将 MLM 视为新型预训练任务,以克服标准单向语言建模的缺陷。
因此,笼统地讲,MLM 首次从输入序列中遮掩一些 token,然后训练模型来通过其余的 token 预测 masked 的 token。
尽管 MLM 在预训练中得到了广泛应用,Zhilin Yang 等在论文《XLNet: Generalized autoregressive pretraining for language understanding》中表示,当模型应用于下游任务时,[MASK] 等在 MLM 预训练中使用的一些特殊 token 并不存在,这导致预训练和微调之间出现差距。
为了克服这一问题,Zhilin Yang 在这篇论文中提出以排列语言建模(Permuted Language Modeling,PLM)来取代 MLM。简单地说,PLM 是一种在输入序列随机排列上的语言建模任务。给定一个序列,然后从所有可能的排列中随机抽样一个排列。接着将排列序列中的一些 token 选定为目标,同时训练模型以根据其余 token 和目标的正常位置(natural position)来预测这些目标。
去噪自编码器(denoising autoencoder,DAE)接受部分损坏的输入,并以恢复这些未失真的原始输入为目标。这类任务会使用标准 Transformer 等模型来重建原始文本,它与 MLM 的不同之处在于,DAE 会给输入额外加一些噪声。
Nikunj Saunshi 等人论文《A theoretical analysis of contrastive unsupervised representation learning》中的对比学习(contrastive learning,CTL)假设,一些观察到的文本对在语义上比随机取样的文本更为接近。CTL 背后的原理是「在对比中学习」。相较于语言建模,CTL 的计算复杂度更低,因而在预训练中是理想的替代训练标准。
CTL 一般可以分为以下三种类型:
- 替换 token 检测(Replaced Token Detection,RTD)与 NCE 相同,但前者会根据上下文语境来预测是否替换 token。
- NSP 训练模型以区分两个输入句子是否为训练语料库中的连续片段。
- SOP 使用同一文档中的两个连续片段作为正样本,而相同的两个连续片段互换顺序作为负样本。
预训练扩展
清华大学提出了 ERNIE,它会结合知识图谱中的多信息实体,并将其作为外部知识改善语言表征。
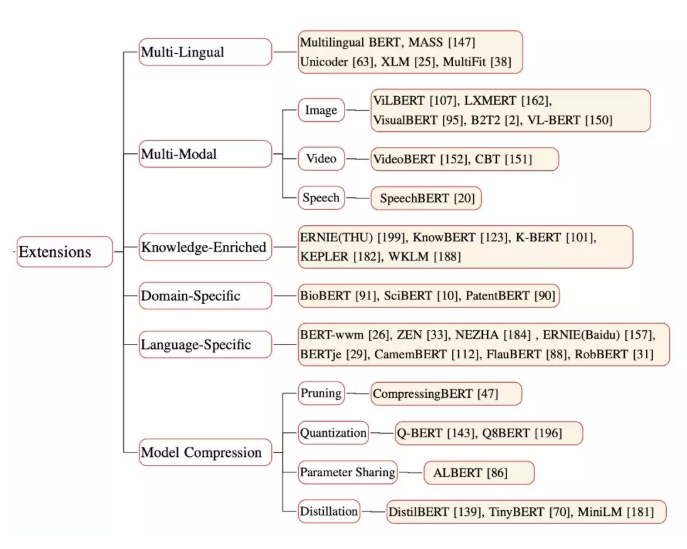
PTM 能够从大规模通用文本语料库中学习一般的语言表征,但缺乏领域知识。Knowledge-Enriched PTM 则可以借助语言学、语义学、常识和特定领域的知识来加强预训练方法。
一些研究集中在如何获取 PTM 的交叉模式版本,而绝大多数是为了通用的视觉以及语言特征编码而设计的。此类模型在大规模的跨模式数据语料库上进行了预训练,并结合扩展的预训练任务从而充分利用其多模式特征。
模型压缩是减小模型大小并提高计算效率的方法。目前有四种压缩 PTM 的常用方法:(1)删除那些不太重要的参数;(2)权重量化,使用少量的位去表示参数;(3)在相似的模型单元之间共享参数 ;(4)知识提炼。
表 3 详细区分了一些代表性的压缩 PTM。

大多数公开的 PTM 都有过通用领域语料库的训练,如 Wikipedia,而这会使得其应用限制在特定领域。而一些研究提出了另一些受过专业语料库训练的 PTM,例如 BioBERT 用于生物医学方向,SciBERT 用于科学方向,ClinicalBERT 用于临床方向。
模型学习多语言文本说明跨语言共享在 NLP 任务起着非常重要的作用。MLM 对多语言的 BERT^3(M-BERT)进行了预训练,并在 Wikipedia 文本上使用来自多达 104 种主要语言共享词汇及权重。每个训练样本都是单语文档,没有专门设计的跨语言目标,也没有任何跨语言的数据。
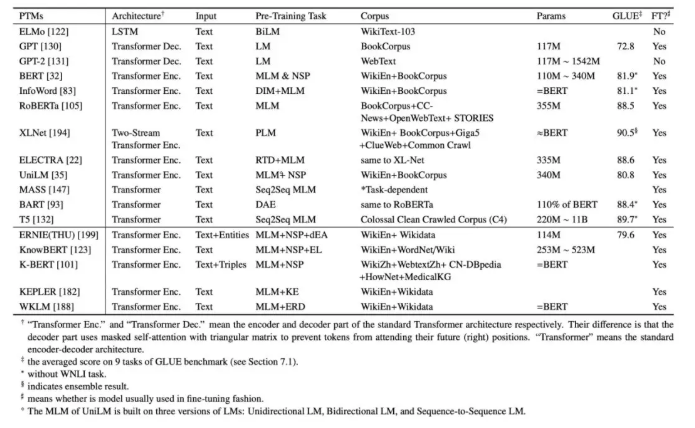
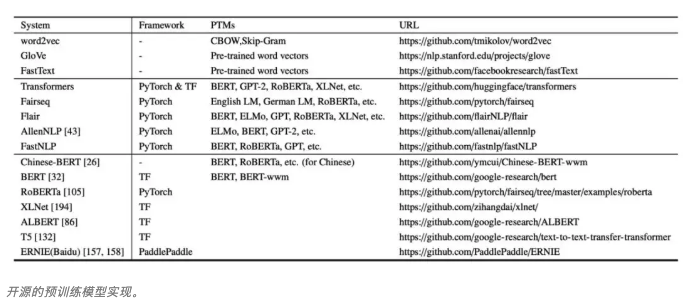
PTM资源

PTM 未来发展方向展望
虽然 PTM 已经在很多 NLP 任务中显示出了他们强大的能力,然而由于语言的复杂性,仍存在诸多挑战。这里,研究者给出了五个未来 PTM 发展方向的建议。
PTM 的上限
目前,PTM 并没有触及其上限。大多数的 PTM 可通过使用更多训练步长以及更大数据集,来提升其性能。目前 NLP 中的 SOTA 也可通过加深模型层数来更进一步提升。PTM 的最终目的一直是我们对学习语言中通用知识内部机理的追寻。然而,这使得 PTM 需要更深层的结构,更大的数据集以及具有挑战的预训练任务,这将导致更加高昂的训练成本。因此,一个更加切实的方向是在现有的软硬件基础上,设计出更高效的模型结构、自监督预训练任务、优化器和训练技巧等。例如 ELECTRA 就是此方向上很好的一个解决方案。
面向任务的预训练和模型压缩
在实践中,不同的目标任务需要 PTM 拥有不同功能。而 PTM 与下游目标任务间的差异通常在于两方面:模型架构与数据分发。尽管较大的 PTM 通常情况下会带来更好的性能表现,但实际问题是如何在一定情况下使用这类较大的 PTM 模型,比如低容量的设备以及低延迟的应用程序。而通常的解决方法是为目标任务设计特定的模型体系架构以及与训练任务,或者直接从现有的 PTM 中提取部分信息用以目标任务。
此外,我们还可以使用模型压缩等技术去解决现有问题,尽管在 CV 方面对 CNN 的模型压缩技术进行了广泛的研究,但对于 NLP 的 PTM 来说,压缩研究只是个开始。Transformer 的全连接架构也使得模型压缩非常具有挑战性。
PTM 的结构
对于预训练,Transformer 已经被证实是一个高效的架构。然而 Transformer 最大的局限在于其计算复杂度(输入序列长度的平方倍)。受限于 GPU 显存大小,目前大多数 PTM 无法处理超过 512 个 token 的序列长度。打破这一限制需要改进 Transformer 的结构设计,例如 Transformer-XL。因此,寻找更高效的 PTM 架构设计对于捕捉长距上下文信息十分重要。设计深层神经网络结构很有挑战,或许使用如神经结构搜索 (NAS) 这类自动结构搜索方法不失为一种好的选择。
在参数微调之上的知识迁移
微调是目前将 PTM 的知识转移至下游任务的主要方法,但效率却很低,每个下游任务都有特定的微调参数。而改进的解决方案是修复 PTM 的原始参数,并特定为任务添加小型的微调适配模块,因此可以使用共享的 PTM 服务于多个下游任务。从 PTM 挖掘知识可以变得更加灵活,如特征提取、知识提取和数据扩充等方面。
PTMs 的解释性与可靠性
虽然 PTM 取得了令人印象深刻的表现,然而其深层非线性结构使得决策过程非常不透明。最近,可解释的人工智能 (XAI) 成为通用 AI 社区的热点话题。不同于 CNN 使用图像,由于 Transformer 类结构和语言的复杂性,解释 PTM 变得更加困难。另外,当 PTMs 在生产系统中大规模应用时,其可靠性逐渐引起了广泛关注。深层神经网络模型在对抗性样本中显得十分脆弱,在原输入中加入难以察觉的扰动即可误导模型产生攻击者预先设定好的错误预测。
除此之外,PTM 的敌对攻击防御手段是一个很有前途的方向,其能够提高 PTMs 的鲁棒性,同时使得他们对敌对攻击免疫。总之,PTMs 的可解释性与可靠性仍然需要从各个方面去探索,它能够帮助我们理解 PTM 的工作机制,为更好的使用及性能改进提供指引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号