

BP NN 简略版
主要就是贴代码,我还是比较犹豫的,因为我们做工程这件事怎么说呢,应该不算主要业务。
1.用到的 Package
'''-------------------------- 本篇主要分析 Airbnb 2024.4.10 9:07 PM ------------------------------ ''' import pandas as pd import numpy as np import matplotlib.pyplot as plt import os print(np.__version__) os.getcwd()
2.导入数据
# --- 导入数据 --- data_ca = pd.read_csv(r"https://src20211130.oss-cn-beijing.aliyuncs.com/data-2024/listings-ca-usa-1.csv" , encoding='ISO-8859-1' ) data_ny = pd.read_csv(r"https://src20211130.oss-cn-beijing.aliyuncs.com/data-2024/listings-ny-usa-1.csv" , encoding='ISO-8859-1') print("-----------------------") print(data_ca.shape) print(data_ny.shape) data_base = pd.concat([data_ca, data_ny]).fillna(-1).reset_index(drop=True) print("*** data_base ***") print(data_base.shape) print("-----------------------\n")
3.数据处理。这一步仁者见仁智者见智,我们通常的做法,是将所有变量数值化,并且做好标准化(非常有用)。
4.构建 BP NN。这篇代码也是借鉴 Github 上的,参考:
https://shoelesscai.com/EssaySpace2/a/153005100001/945
主要结构都编写在 class 里,部分单独罗列出的函数,是在用在 class 内部定义函数调用的。
参考: https://www.cnblogs.com/jsfantasy/p/12177275.html
我们自己也推导了一份。



处理 Dropout
if (dropout_rate>0): tmp_len = a_pre_.shape[1] tmp_ind = generate_ind( dropout_rate, tmp_len ) for i in range(len(tmp_ind)): a_pre_[0][i] = 0
drop out 一部分 Y value 。为什么是 Y 而不是 weight?
参考:
https://blog.csdn.net/fu6543210/article/details/84450890
Tensorflow 相关参考资料:
https://www.cnblogs.com/Luv-GEM/p/10766241.html
关于 Padding
Cnblogs 这篇讲得听清楚,主要是参数选择。这里关键在于 Padding 本身也是会对图像产生影响的,这一点可以关注。
参考:
https://www.cnblogs.com/tingtin/p/12505853.html
知乎过百赞:
https://zhuanlan.zhihu.com/p/95368411
知乎,这篇解释了我的疑问。padding = size_of_kernel / 2, 因为 kernel 是个方阵,姑且认为是 pooling kernel。
https://zhuanlan.zhihu.com/p/36278093
知乎,综合应用:
https://zhuanlan.zhihu.com/p/372659296
关于 Pooling
唔……这个是先 padding 再 pooling 处理长方形的情形:
https://blog.csdn.net/u010087338/article/details/109068340
也有人说,没有物理上长宽意义的,可以不用神经网络这类模型套用。
参考
https://www.zhihu.com/question/275779187
总的来说, Pooling 适合计算机视觉。一般模型,可以用一些 filter 降维度。
另外,Pooling 的第一层操作的吗?
https://zhuanlan.zhihu.com/p/88985074
这篇文章写了如何在反向传播的时候,返回 Pooling 部分。参考
https://zhuanlan.zhihu.com/p/88985074
我自己在处理的时候,是反向传的时候也 Pooling 一下。
关于【非图像】数据集 Pooling & Padding
推导过程


关于奇数个变量处理方法,最后一个变量原封不动。
我们考查最终结果。
研究方法也简单,就是按照 【层数、神经元数量、Dropout Rate、Pooling、Num of Epochs】,对模型指标进行考察。
考查指标为, Precision, Recall, Accuracy, F1 Score。
调整的参数
num_epochs 迭代次数
Layer 隐藏层数量
Neuron 神经元数量
实验结果
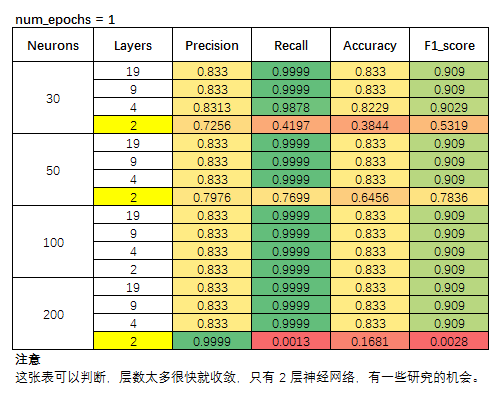
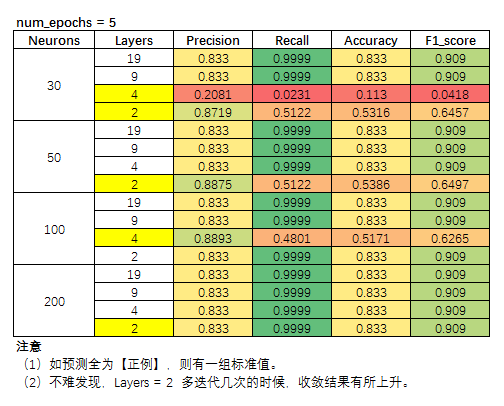
显然,层数越多是很容易收敛的,因此,我们选择指标略有不稳定的 2-Layer,以及 4-Layer,因为 4-Layer 模型指标变化不大,这里就不放结果了。
我们针对 2-Layer 模型,设置每层走 5 步的情形。
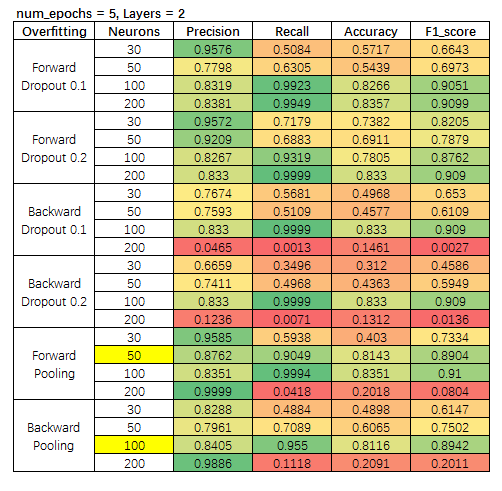
我们选择的标准,保证正例精准度(precision)情况下,保证 F1 不小。 选出两个模型。
模型一:2-Layer,50-Neurons,迭代1次,前向 Pooling;
模型二:2-Layer,100-Neurons,迭代1次,后向 Pooling。
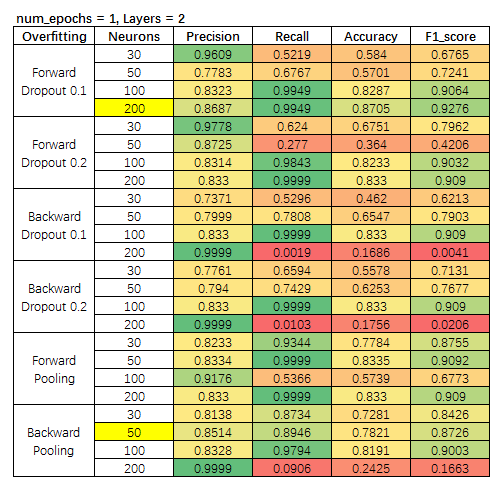
同样标准,我们选出两个模型。
模型三:2-Layer,200-Neurons,迭代5次,前向 Dropout 10%;
模型四:2-Layer,50-Neurons,迭代5次,后向 Pooling。
模型对比
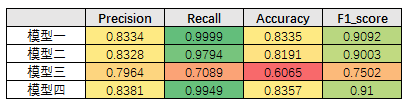
图像对比
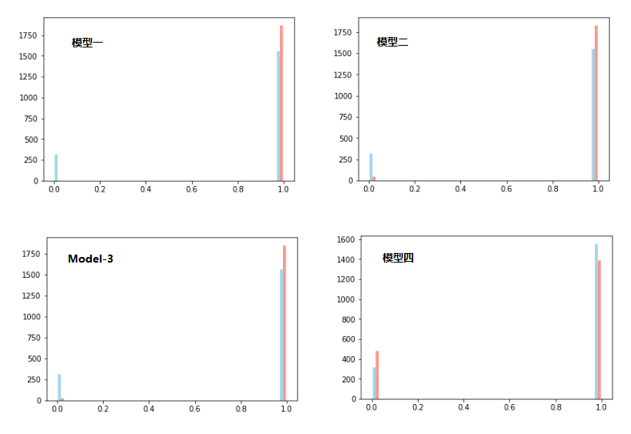
图像和指标都显示,模型四最合适。
【模型四】2-Layer,50-Neurons,迭代5次,后向 Pooling。
注意,这里蓝色是真实值,红色是预测值。这部分真实值对饮 X 没有进入训练集进行训练。完全预测对比。
这些分析都会形成文档的,但是有些数据集的 Origiinal Source 有些找不到了。我们会贴出转存链接(我电脑经常出状况,或没过多久电脑里的资料就爆炸了)。
数据分析比较好的参考
23个数据分析实战项目,解救没有数据分析经历的你
https://www.zhihu.com/tardis/zm/art/355897515?source_id=1005
过百赞回答
https://www.zhihu.com/question/352902986
Python数据分析练手项目合集(附源代码和数据),持续更新
https://zhuanlan.zhihu.com/p/347859009
ShoelessCai.com 值得您的关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号