
利用topologySpreadConstraints使多个Pod在节点之间均衡调度
在ingress-nginx部署时有个需求,就是3个节点单个节点需要至少跑3个实例。
这需求有点像异地多活时,每个区域至少要跑2实例一样,不同之处是一个是节点级别,一个是区域级别。
deployment在副本数多的时候虽然可以让调度器大致上的平均调度,但是当遇到个别节点压力大的时候会降低调度score,导致调度不均衡,非常不可控。
查阅文档发现有这么个配置项:topologySpreadConstraints
里面有个maxSkew参数,可以控制节点之间最多可以相差几个pod,利用该约束,当maxSkew=1,replicas=10时,3个节点的pod数分布为3、3、4,满足需求。(这里其实有问题,详见下文)
---
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional; beta since v1.25
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional; beta since v1.27
nodeAffinityPolicy: [Honor|Ignore] # optional; beta since v1.26
nodeTaintsPolicy: [Honor|Ignore] # optional; beta since v1.26
### other Pod fields go here
这里有几个关键配置项
labelSelector:pod选择器,用来统计pod数量
maxSkew:节点之间最多可以相差几个pod,最少为1
topologyKey:统计维度,可以配置按主机还是按区域或其他
whenUnsatisfiable:条件不满足时策略,默认是DoNotSchedule(不调度),另一个选项是ScheduleAnyway
一开始我比较迷惑为什么会有ScheduleAnyway这个选项
后来看到这个功能是才想到,他的作用是尽可能往maxSkew靠,被字面意思的Anyway给迷惑了
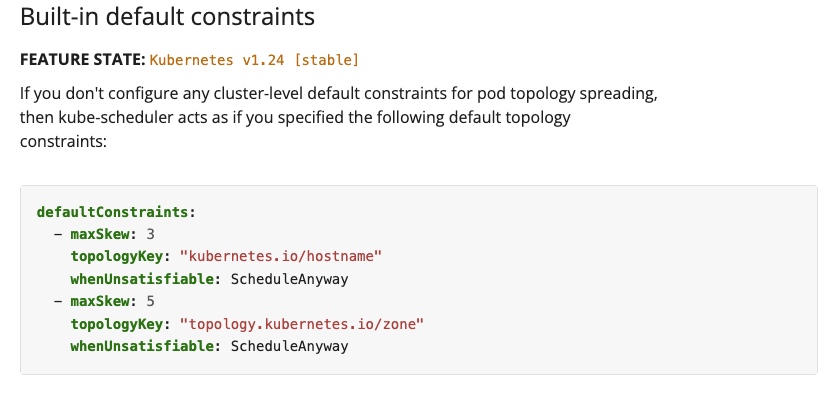
将需求转为配置,这里以httpbin为例,节点之间pod数最多差1个,超出的不可调度
topologySpreadConstraints:
- labelSelector:
matchLabels:
app: httpbin
maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
实验
将副本数从1加到7,观察pod分布情况
for i in `seq 1 7`; do
echo "replicas=$i"
kx test155 scale --replicas=$i deploy/httpbin
sleep 1
kx test155 get po -o wide|grep httpbin|awk '{print $7}'|sort|uniq -c
done
deployment.apps/httpbin scaled
1 master193.169.200.151
replicas=2
deployment.apps/httpbin scaled
1 master193.169.200.151
1 master193.169.200.152
replicas=3
deployment.apps/httpbin scaled
1 master193.169.200.151
1 master193.169.200.152
1 master193.169.200.153
replicas=4
deployment.apps/httpbin scaled
2 master193.169.200.151
1 master193.169.200.152
1 master193.169.200.153
replicas=5
deployment.apps/httpbin scaled
2 master193.169.200.151
1 master193.169.200.152
2 master193.169.200.153
replicas=6
deployment.apps/httpbin scaled
2 master193.169.200.151
2 master193.169.200.152
2 master193.169.200.153
replicas=7
deployment.apps/httpbin scaled
3 master193.169.200.151
2 master193.169.200.152
2 master193.169.200.153
结果符合预期
接下来看看滚动更新是否正常
kubectl rollout restart deploy/httpbin
deployment.apps/httpbin restarted
kx test155 get po -o wide|grep httpbin|awk '{print $7}'|sort|uniq -c
1 master193.169.200.151
3 master193.169.200.152
3 master193.169.200.153
问题已经浮现,重启后pod数差异大于1,规则失效。
配置maxSurge=25%,maxUnavailable=0,并且副本数改到20以增加样本数
kubectl scale --replicas=20 deploy/httpbin
kx test155 get po -o wide|grep httpbin|awk '{print $7}'|sort|uniq -c
7 master193.169.200.151
6 master193.169.200.152
7 master193.169.200.153
开始滚动更新
kubectl rollout restart deploy/httpbin
第一批25%创建后的pod分布
9 master193.169.200.151
8 master193.169.200.152
8 master193.169.200.153
最终
9 master193.169.200.151
5 master193.169.200.152
6 master193.169.200.153
在滚动更新期间差异数<=1,结束后>1,应该是将Terminating也作为一个pod在计算
maxSurge=25%意味着最多Pod数=25个,推测最后一轮pod创建完后:
master193.169.200.151 0个Terminating 共9个Pod
master193.169.200.152 3个Terminating 共8个Pod
master193.169.200.153 2个Terminating 共8个Pod
查文档发现:
Known limitations
There's no guarantee that the constraints remain satisfied when Pods are removed. For example, scaling down a Deployment may result in imbalanced Pods distribution.
You can use a tool such as the Descheduler to rebalance the Pods distribution.
确实是在删除pod时会导致数量不平衡。
那如果我一个一个删除呢?即设maxSurge=1,此时最多Pod数为21,根据Terminating倒推:
master193.169.200.151 0个Terminating 共7个Pod
master193.169.200.152 1个Terminating 共7个Pod
master193.169.200.153 0个Terminating 共7个Pod
最终
7 master193.169.200.151
6 master193.169.200.152
7 master193.169.200.153
结果符合规则
这也存在其他情况:
当21个副本时
master193.169.200.151 0个Terminating 共7个Pod
master193.169.200.152 1个Terminating 共7个Pod
master193.169.200.153 0个Terminating 共8个Pod
最终
7 master193.169.200.151
6 master193.169.200.152
8 master193.169.200.153
当19个副本时
master193.169.200.151 0个Terminating 共7个Pod
master193.169.200.152 1个Terminating 共6个Pod
master193.169.200.153 0个Terminating 共7个Pod
最终
7 master193.169.200.151
5 master193.169.200.152
7 master193.169.200.153
可见,当replicas + maxSurge不能被节点数整除时,会存在调度不均衡的情况
由此可以得出节点pod数保证公式:
replicas = node_count * (pod_min_count + maxSkew) - maxSurge
修改参数为maxSurge=1,maxUnavailable=0,开始验证
rollout restart
kx test155 get po -o wide|grep httpbin|awk '{print $7}'|sort|uniq -c
7 master193.169.200.151
6 master193.169.200.152
7 master193.169.200.153
跟推想的一致
总结
- maxSkew可以控制节点间pod数量差异,配合副本数实现每个节点调度至少几个pod
- topologySpreadConstraints对滚动更新支持的不好
- 滚动更新需要配置参数maxSurge=1,maxUnavailable=0
- 当replicas + maxSurge不能被节点数整除时,会存在调度不均衡的情况
- 节点pod数保证公式:replicas = node_count * (pod_min_count + maxSkew) - maxSurge
- 如果3节点要保证每节点至少有3个pod,需要配置副本数 3*4-1=11
参考
https://kubernetes.io/docs/concepts/scheduling-eviction/topology-spread-constraints/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号