2022OO第一单元总结
2022OO第一单元总结
一、第一次作业分析
1.总类图以及架构分析
-
总类图
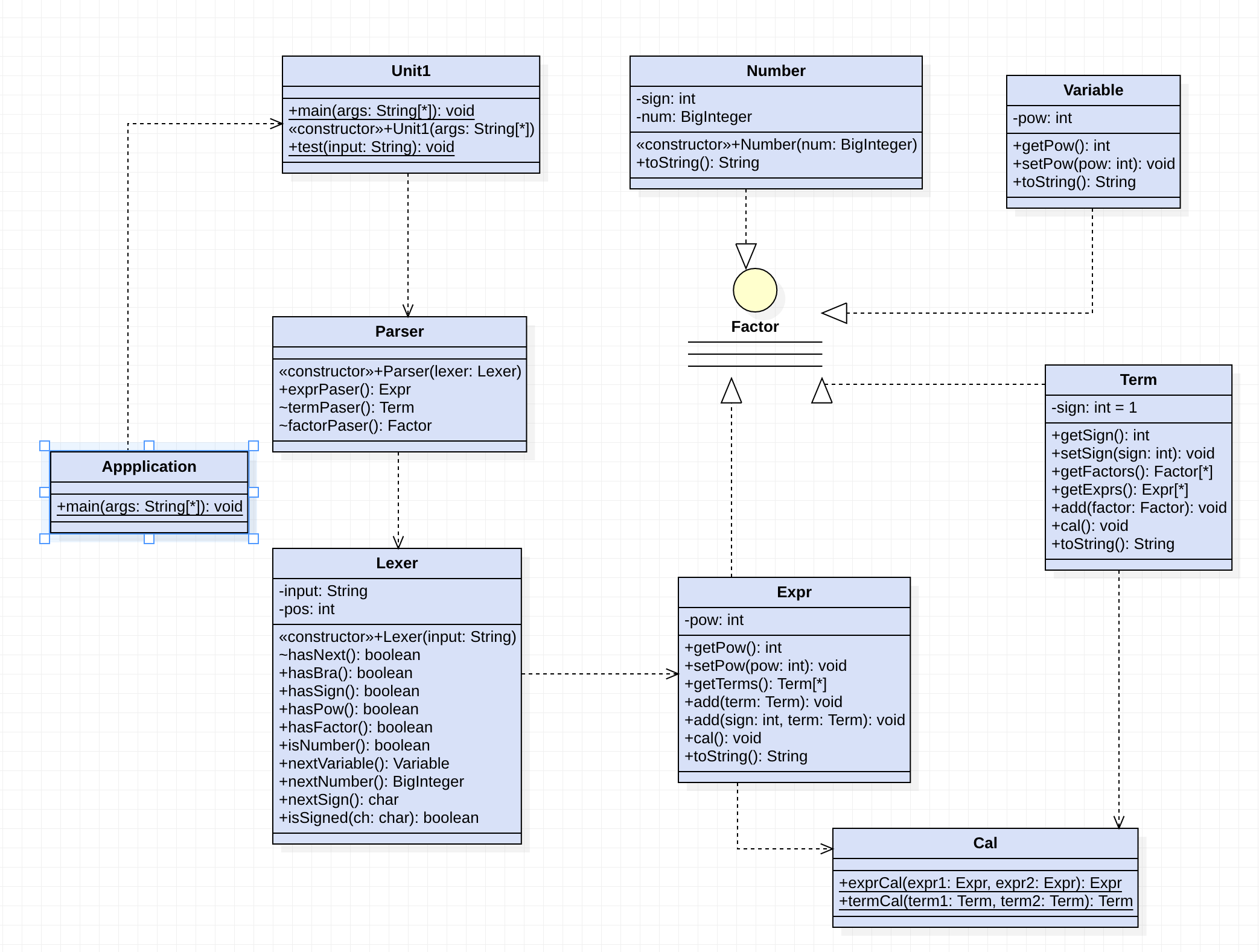
-
架构分析
- 初始架构:由于一直难以找到一个合适的架构,所以本次作业开始的比较晚,最后受课上实验的启发,采用了递归下降的方式,实现了本次作业。下面就类图简要介绍思路。
- 表达式解析:Lexer和Parser是两个简单的解析类,其中Lexer中为了防止单个方法的复杂度过高,将数字符号括号等的识别全部转化为单个方法,然后Parser调用Lexer中的方法得到相应的因子。
- Factor接口:这是最重要的一个类,虽然在其中并未实现任何方法,但是却是一个重要的识别内,表达式中所有对象全部继承自这个类,Expr、Term、Number、Variable等表达式中可能存在的因子均实现了这个类,这样就方便了之后的共同处理。
- Cal类 :是化简的辅助类,处理Expr之间的相乘,以及Term之间的相乘,Term之间的相乘通过简单的合并List就行,Expr之间的相乘通过循环将每个Term相乘。
- Expr和Term:把这两个放在一起说,是因为其处理方法十分相似。表达式类,其中只有两个属性,一个是次方pow,这个属性在表达式被读取之后可以通过cal()方法消去,另一个是由ArrayList存储的多个Term对应了最后需要输出的简单因子,而相应的Term中则存了除了Term本身的所有因子。在文法解析的时候两个类均通过add()方法添加新的成员。
- 递归下降:Expr和Term另外一个重要的方法cal()是化简的核心,首先Term的cal方法将判断所存的因子当中是否存在表达式,如果不存在表达式,不作处理,如果存在表达式,则先调用Cal类中的exprCal()方法将之后的Expr合并,最后将剩下的其他因子再调用termCal()与最后的表达式合并,得到一个最终的表达式,而表达式的化简只需要保证terms中的每个成员均被化简即可,这样反复递归下降最终一定会得到只含有Number和Variable的简单因子
2.代码复杂度分析
-
代码规模分析
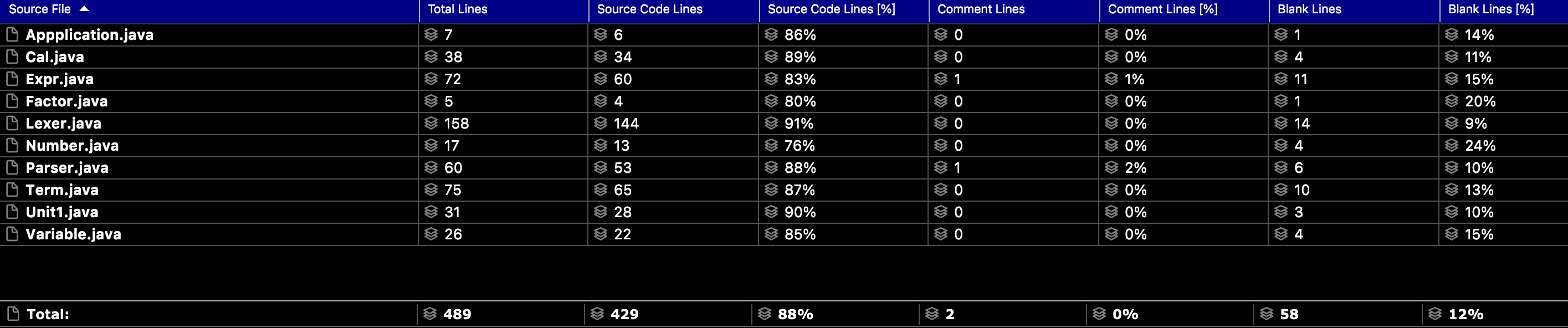
由于第一次作业功能较少,所以代码量不大,但是词法分析的两个类Expr和Lexer两个类写的过于臃肿,分析代码发现有大量重复的代码,例如识别括号符号等小符号的方法可以融合到一个方法中。
-
方法复杂度分析
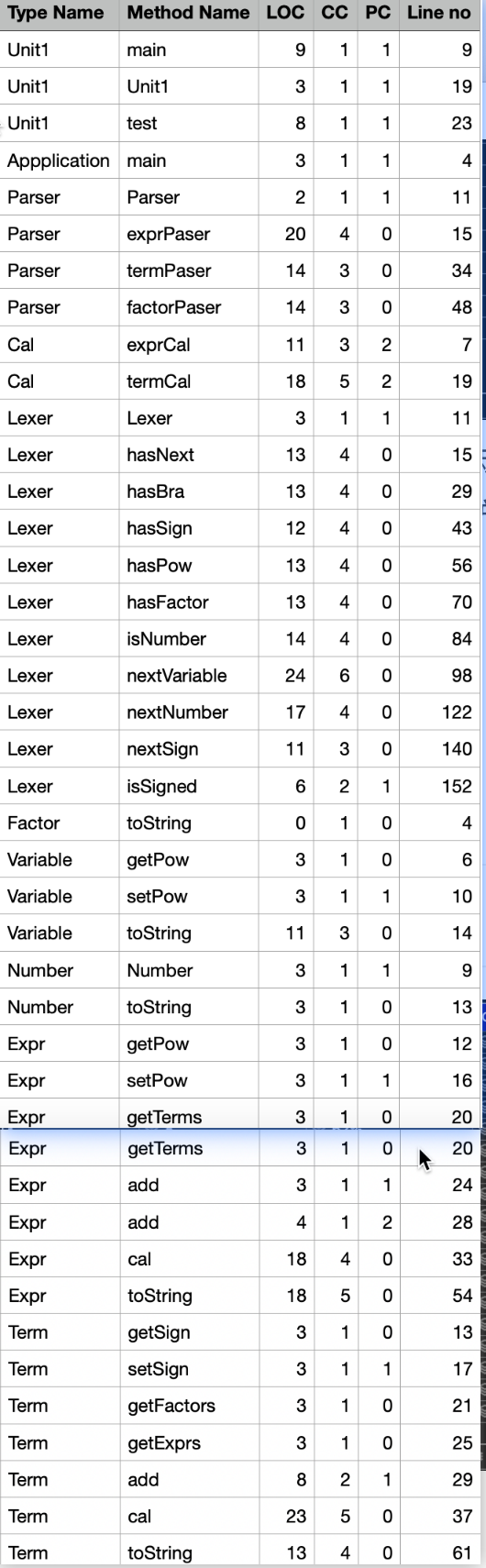
本次作业没有臃肿的方法,这是比较好一点,但是有些方法也写的太开了,导致有许多一两行的方法。另外有几个方法没有注意优化,导致圈复杂度较高。
-
类复杂度分析
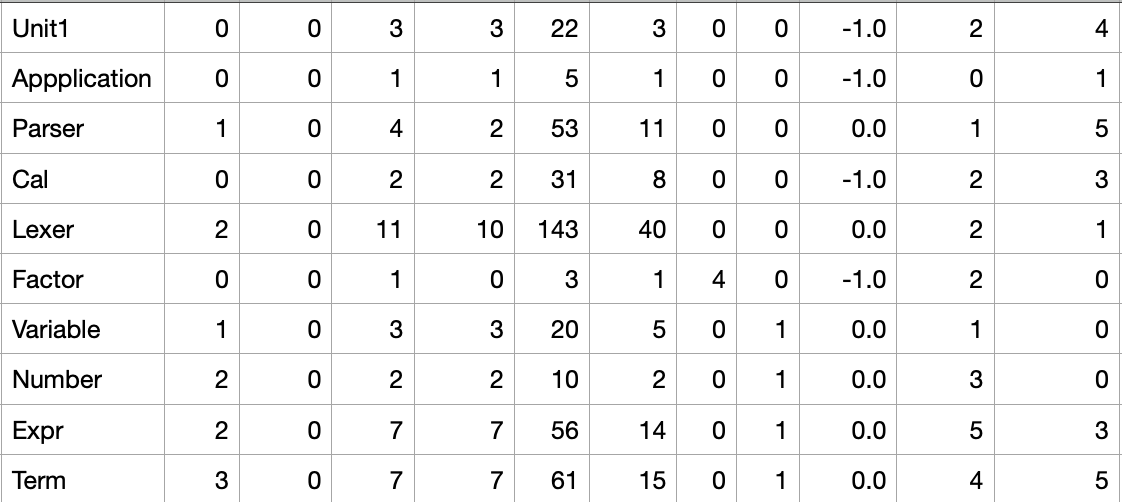
本次作业由于难度不大,所以十分类的复杂度不高,各个类之间的耦合度也不高,但是有Lexer这么一个臃肿的类,原因还是之前的,将功能分的太细,反而有反作用。
3.优缺点分析
- 优点主要是递归下降的思路,这种思路不管之后增加什么因子,均只需要在增加的因子里面添加对应的功能,或者在不影响之前功能的情况下添加一些处理。
- 这次作业由于我个人原因开的比较晚,所以导致容器的选取十分不合理,选择了ArrayList作为存放的容器,导致后续的化简十分麻烦,并且由于本人十分粗心的将指导书看错,把性能的评判标准误认为是时间,导致表达式完全没有优化,也没有意识到容器的问题,后期的时间都花在了评测上。
4.数据构造与测评
目标:
尽可能的覆盖所有情况,并且覆盖到边界特殊情况,并且符合标准输入条件。
数据生成器
-
常量池:根据指导书要求构造常量池,自己测试的时候可以适当超出限制,互测的数据再降低数据强度
public static final String [] constNum = { "0","1","2","3","4","5","6","7","8","10","99","12","132","232", "14","15","2147483647","2147483648","144","124","123","12412789","12789","12479","17698","23","213", "0","1","2","3","4","5","6","7","8","10","99","12","132","232", "0","1","2","3","4","5","6","7","8","10","99","12","132","232", "14","15","2147483647","2147483648","144","124","123","12412789","12789","12479","17698","23","213", "137985525229","372198332133", "9223372036854775807","9223372036854775808", "23333333233333332333", "23333333233333334666" }; public static final String [] constExprAdd = { "+(x+1)","+(x-1)","-(x+1)","-(x+1)", "+(x+2)","+(x-2)","-(x+2)","-(x+2)", "+(2*x+1)","+(3*x-1)","-(4*x+1)","-(x+5)", "+(x+2)**3","+(x-2)**4", "+(x+1)**3","+(x-1)**8" }; public static final String [] getConstExprMul = { "*(x**2+x+1)","*(x**2-x+1)","*2*(x**2+x+1)","*2*(x**2-x+1)", "*(-x**2+x+1)","*(-x**2-x+1)","*2*(-x**2+x+1)","*2*(-x**2-x+1)", "*(-x**8+x+1)","*(-x**4-x-1)","*2*(-x**4+x+5)","*2*(-x**2-x-4)", };- 一些边界的大数,例如int边界2147483647,以及long边界和远超long的大数9223372036854775808 和23333333233333332333
- 一些卡指数限制的数据
-
生成思路
之后的表达式之间的生成主要就是靠随机数选择基础数据,再用加减符号连接各个项与表达式因子,自底向上层次保证数据符合形式化要求。
- 生成因子
最底层有三个方法,getNum,getPow,getExpr,这三个方法均是通过随机数来生成index,来选择基础数据,获得数字,项,以及表达式因子,其中getNum如下,其他量的生成方法类似,主要是要用Random类生成随机数,固定随机数种子,保证能够复现数据,除了基础的数据,也会通过随机数生成long范围的数
static String getNum(Random random) { int length = ConstData.constNum.length - 4; int index = random.nextInt(length); if (random.nextInt(2) == 1) { return ConstData.constNum[index]; } else { return String.valueOf(Math.abs(random.nextLong())); } }- 连接表达式
基础的因子以及符号都可以获得之后,就可以自底向上生成具有一定强度的表达式了, 需要注意的是课程组100个有效字符的要求(本地对拍时可以生成更长的表达式,毕竟表达式更长可能能够发现更多的bug)。表达式的连接其实就是将各个因子与符号之间连接,通过random可以选择不同的因子,以及不同的长度。
先生成项static String getTerm(Random random){ StringBuilder sb = new StringBuilder(); sb.append(getNum(random)); int num = random.nextInt(3); for (int i = 0; i < num; i++) { sb.append(getPow(random)); } return sb.toString(); }再结合getSign()方法连接成表达式
static void strongExpr(Random random) { for (int i = 0; i < 5; i++) { StringBuilder sb = new StringBuilder(); int num = 3 + random.nextInt(5); for (int j = 0; j < num; j++) { sb.append(getTerm(random)); if (j != num - 1) { sb.append(getSign(random)); } } list.add(sb.toString()); } }其中list是存储不同组数据的容器,最后将它打印出来即可,通过System.set()方法可以重定向到文件中方便后续对拍。
自动评测工具
第一次作业自动评测比较简单,因为有强大的python库sympy(
估计我们能达到这个库的效果最好),我最开始的时候想到带值计算,但是后面了解到可以直接通过equal方法直接比较,具体代码如下:from sympy import * import os def cmp(std, your, stdline, yourout): if(std.equals(your) == false): print(" stdout is", std, "\n", " yourout is", your, "Expr:", stdline) print(std.equals(your) ) exit(0) else: return # os.system("java -jar dataGenerator.jar") # os.system("java -jar Test.jar") stdout = open("data.txt", "r+") yourout = open("output.txt", "r+") x = Symbol("x") z = 0 for stdline in stdout: z = z + 1 print (z) yourline = yourout.readline() str1 = "a" + "=" + "x + " + stdline str2 = "b" + "=" + "x + " + yourline exec(str1) exec(str2) a = a.expand() cmp(a, b, stdline, yourline) print("Success!")其中增加x以免解析失败。
5.bug分析
hack策略
课程组的本意是想我们读别人的代码,来实现hack,但是一个房间几个人,每人上千行的代码实在难以阅读,所以此次hack主要还是采用黑盒的方式。先写一个类能够运行所有代码,首先手工输入一些边界数据hack,在将代码丢到评测机里,实现大规模数据的自动化测评。
bug
由于自己数学知识的匮乏,导致强测出现了一个bug,具体是把负数的0次方错误输出为-1,同时也说明了数据生成器在边界数据上的不足。由于错了一个点,导致房间等级不高,这次写的数据生成器都没怎么用,最后用了一下保证人人中刀,总计hack到了14次,其中非同质bug有
- 预解析模式下只有一个输入时解析错误
- 没有使用bigInteger
- 优化+0时错误
二、第二次作业分析
1.总类图以及架构分析
-
总类图
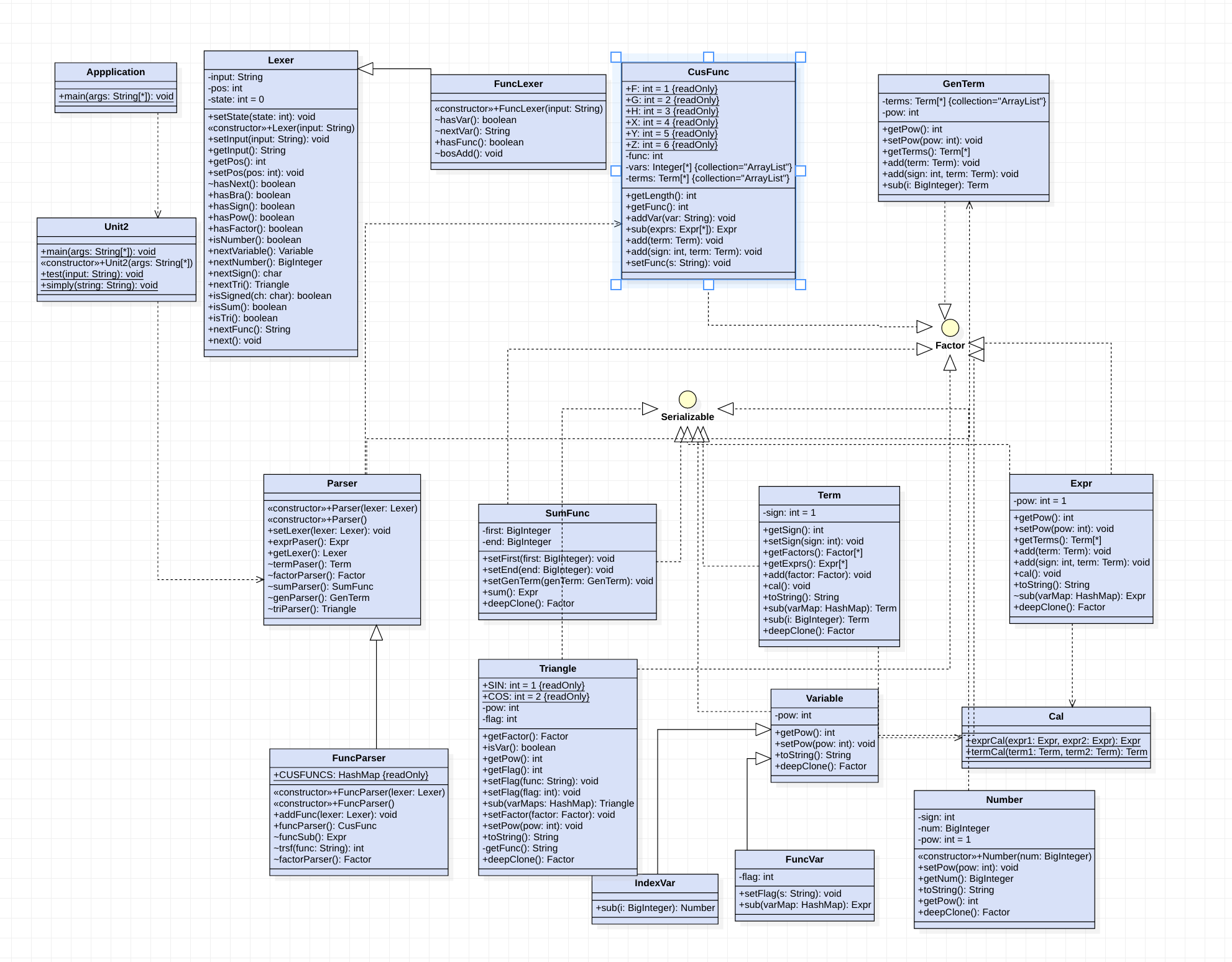
-
第二次作业增加内容
第二次作业难度陡增,主要是sum函数以及函数的代入比较恶心,但是由于第一次的计算架构比较完善(容器的问题这一次依旧没有长记性,性能还是出了大问题),所以这一次主要增加的是函数的存储与代入计算,以及sum函数的解析与运算。为了保证之后的可扩展性,所以我没有考虑用字符串替换,所以我认为这次的难点反而在解析上。
- Serializable:由于我的递归比较深,而且大量计算乘法,所以原有的clone模式很容易出问题,另外同一个函数可能被调用多次,所以我将因子分别实现了该接口,增加deepclone()方法通过序列化实现深clone。
- Triangle类:包含pow, factor, flag属性,其中flag存储三角函数类型,pow存指数,factor存因子。
- sum函数解析:
- 增加SumFunc类,用以存储上下限以及求和表达式并且有一个sub()方法,可以代入Number
- 增加IndexVar因子,作为可代入的因子,由于sum函数只能代入Number,使用sub()方法返回代入的Number以及pow。
- 再使用bigInt写的循环,为Expr和Term增加sub方法,Expr调用所有Term的sub()方法,Term再调用IndexVar的sub()方法,依旧是递归下降的方式实现sum函数的替换。这当中要注意的是上下限不合法时的特判,(以及我本人数学知识的再次匮乏,将上下限相等的情况直接输出0)。
- 自定义函数解析:
- 增加GenFun类,用以存储函数表达式,这里面的Term,可以存储一个新的因子FuncVar,继承自Variable类,不同之处是也有一个sub()方法,不同之处是这个方法返回一个表达式,以保证代入的实参可以是表达式。
- 增加CusFunc类,里面维护一个静态HashMap<Integer,GenFunc>。其中key代表函数名,也存在一个sub()方法,每当解析到自定义函数时,根据函数名选择相应的GenFunc代入,代入方法和sum类似,依然是递归下降。
- 为了方便解析,而且避免一个类过于臃肿所以新增加了funcParser和funclexer来辅助解析。
2.代码复杂度分析
-
代码规模分析
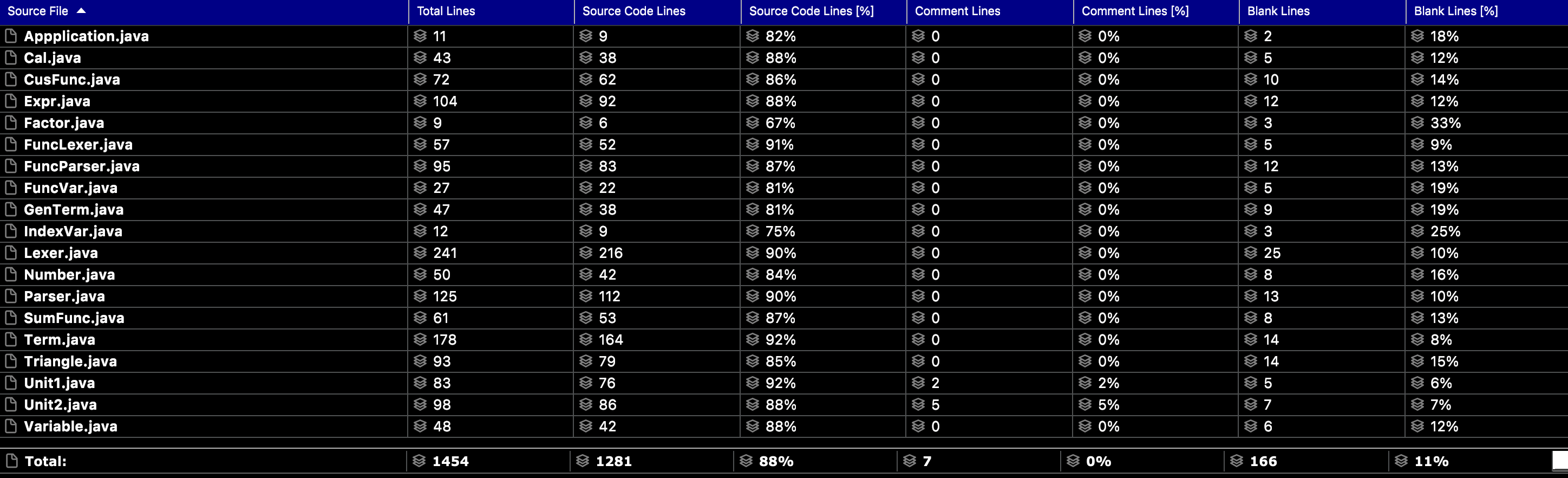
第二次作业代码量陡增,主要就是为每个因子均增加了sub和deepclone方法,deepclone下一次可以考虑使用抽象类,以降低代码复杂度,不然每增加一个因子均要添加该方法。
-
方法复杂度分析(新增)

本次作业依然没有比较臃肿的方法,但是sub方法依旧写的比较烂,另外就是deepclone下次可以使用继承写在父类上。
-
类复杂度分析
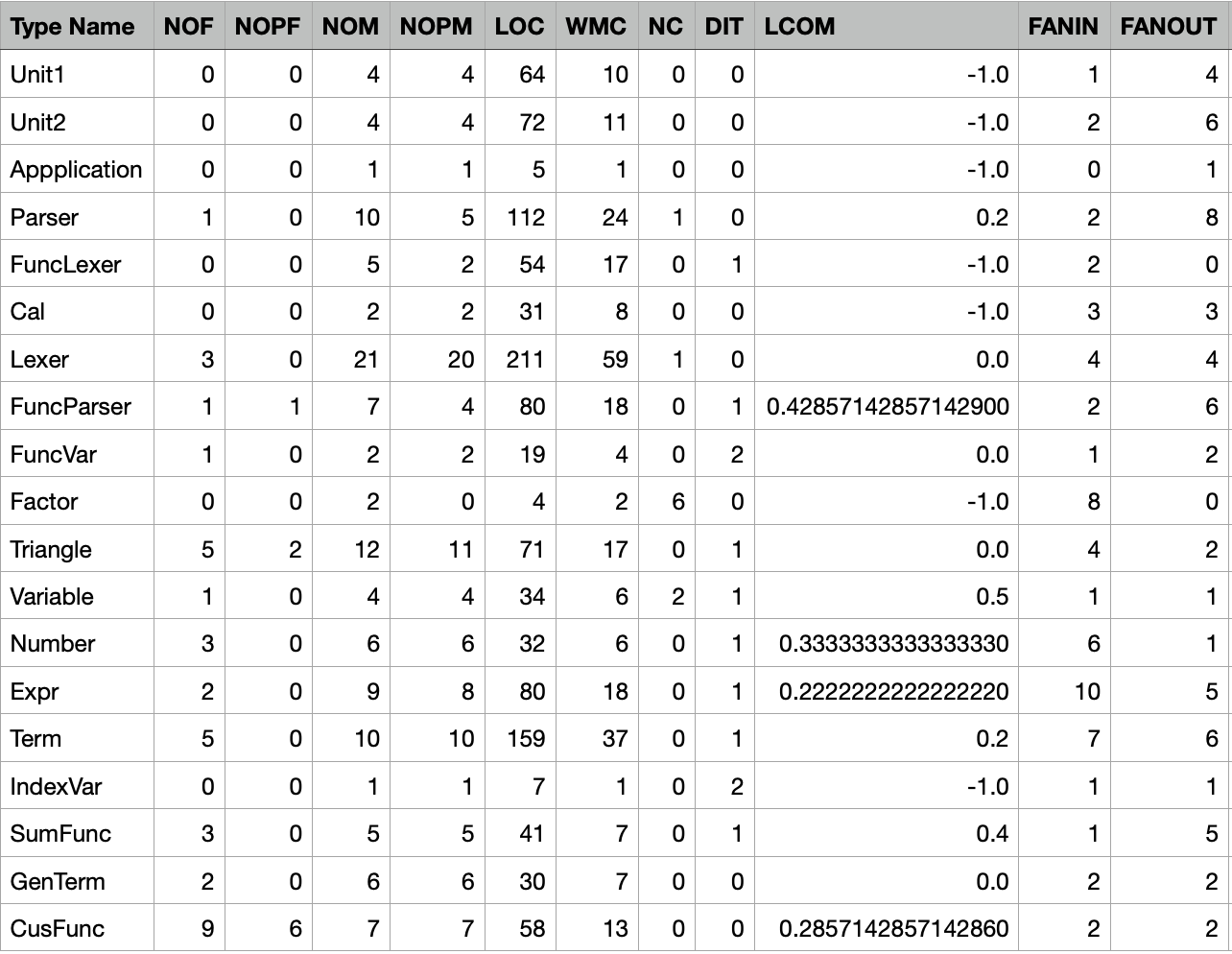
本次作业由于需要多次代入,同一个类肯调用其他好几个类,所以有几个类的耦合度比较高,其实这个时候正确的做法或许是使用工厂类。解析的类依旧比较臃肿(由于这次有几个比较致命的bug一直每de出来,所以来不及优化代码结构)。
3.优缺点分析
- 这次作业的优点主要是自定义函数和sum函数的处理,我一开始就把变量因子可以当作所有其他因子处理,所以可扩展性比较好,所以第三次作业的架构几乎没有改动。
- 这次作业由于我个人原因依旧开的比较晚,所以之前的容器问题依旧没得到解决,现在想来当时是真的烂,第三次作业改变容器之后许多外部辅助的类均可以抛弃,化简也变得简单。
4.数据构造与测评
新增常量池
public static final String [] getTriExprMul = {
"(sin(x**2)**4+sin(x)+1)**0","(sin(x**0)**1-sin(x)+1)**2",
"(-cos(x**3)**4+cos(x)+1)**3","(-cos(x**3)**0-cos(x)+1)**3",
"(sin(x**2)**4+sin(x)+1)","(sin(x**0)**3-sin(x)+1)",
"(-cos(x**4)**4+cos(x)+1)","(-cos(x**3)**3-cos(x)+1)",
"(sin(x)**2+sin(x)+1)","(sin(x)**2-sin(x)+1)",
"(-cos(x)**2+cos(x)+1)","(-cos(x)**2-cos(x)+1)"
};
这次主要新增了一些三角函数的数据
随机生成基础因子
这次由于代入的要求,所以需要生成一些简单的因子,依旧采用Random控制生成,例如三角函数的生成如下
public static String triGen (Random random) {
return (random.nextInt(2) == 1 ? "sin" : "cos") + "(" + facGen(random) + ")**" + random.nextInt(8);
}
public static String facGen (Random random) {
int op = random.nextInt(5);
if (op == 0) {
return String.valueOf(random.nextInt());
} else if (op <3) {
return "x**" + random.nextInt(4);
} else {
return String.valueOf(random.nextInt(1000));
}
}
由于这次作业可能存在多重嵌套所以降低了指数的大小,以防止指数过大。另外还可以使用一些简单的数学知识控制生成的概率。
自定义函数生成
这是本次数据生成比较困难的一个点,依旧是随机数生成的方式,先利用随机数选择函数个数,再随机选择变量的个数,然后生成函数表达式,利用相应的函数变量替换x,最后将函数存到hashMap当中方便后续代入。这次的数据生成器有一些小缺陷,同一个项中无法包含两个变量,手动构造数据时应当自己构造。
具体代码如下
public static String funcGen (Random random) {
StringBuilder sb = new StringBuilder();
varNum = new int[3];
num = random.nextInt(4);
sb.append(num + "\n");
for (int i = 0; i < num; i++) {
sb.append(name[i] + "(");
HashMap<Character , Boolean> vars = new HashMap();
for (int j = 0; j < 3; j++) {
vars.put(var[j], false);
}
int varlength = random.nextInt(3) + 1;
varNum[i] = varlength;
char [] varSet = new char[varlength];
for (int j = 0; j < varlength; j++) {
int index = random.nextInt(3);
while (vars.get(var[index])) {
index = random.nextInt(3);
}
varSet[j] = var[index];
vars.replace(var[index], true);
sb.append(var[index]);
if (j != varlength - 1)
sb.append(",");
}
sb.append(")=");
int termlengh = random.nextInt(2) + 1;
for (int j = 0; j < termlengh; j++) {
sb.append(getSign(random));
sb.append(getTerm(random).replace("x", String.valueOf(varSet[random.nextInt(varlength)])));
}
sb.append("\n");
}
return sb.toString();
}
测评
由于本次作业有自定义函数,所以只能采用对拍的方式,不过我看到讨论区有大佬发了先手动解析消除掉自定义函数的方法,我自己其实也想到一些正则替换的方法,不过本次作业差点就寄在了中测,所有没有来得及实现。
5.Bug分析
本次作业由于一个小bug找了一整天,所以各类数据都试了一遍,互测和强测均未被hack,也没有hack到别人,不过我看到同房的同学有处理sin(0)的错误(没想到第三次作业就成了我自己的bug)。
三、第三次作业分析
第三次作业总体增量不大,代码大概只增加了几十行,而且功能在第二次作业已经能够完全实现,方法的复杂度也没有太大的区别,而且新增的方法大部分是新增的优化,由于前两次的容器选取太烂,所以此次主要分析代码的一些重构思路。
1.优化与重构
-
容器的重新选取
-
由于之前所有的成员都存在一个list当中,所以化简十分困难,并且我体会到除了一些简单的化简,最好不要使用字符串替换,所以这次的因子几乎是分开存储,此次重构的Term分别只使用一个类存储Variable IndexVar FuncVar并且均不涉及系数,同一个Term系数的维护均由num完成。
-
三角函数的存储是一个难点,不过由于系数已经被提前,所以只需要使用简单的HashMap即可存储三角函数,另外我重写了hashcode和equals方法,只要因子和三角函数名相同,即可被合并,只需要将指数相加即可,得到的新三角函数需要重新加入HashMap并且删除之前的三角函数,以保证元素在其中的不变性。
-
之前Expr中的Term也是存在List当中所以导致最后生成的表达式十分臃肿,难以化简。所以这次依旧使用HashMap存储Term,并且重写hashcode和equals方法,比较除了系数以外的所有因子。若是相当只需要改变系数,即可实现合并。
-
-
三角函数简单优化
此次作业我优化了三角函数的平方和,实现思路是首先判断是否能够合并,判断方法是先使用HashMap取得keySet,再相互取差集,若是两个差集一个是sin(x)**2另一个是cos(x)**2,就可以实现合并,合并只需要去掉原项的需要合并的三角函数即可,比较简单。这里由于对keyset不够了解,导致后续的操作改变了HashMap,虽然没有被hack但是依旧值得惊醒。
-
去括号判断
本次作业为了正确的去括号,依旧采用递归下降方式判断三角函数内部的Factor是否是单独的常数或者幂函数,对于Term只要仅含一个变量因子或者一个常数和一个三角函数,就可以判断为单个因子,对于Expr只要有一个Term并且为单个因子即可判断是单个因子。
2.数据生成
由于第二次写的数据生成器已经比较完善,所以此次几乎没有太大的改动,只需要允许调用其他函数即可,反而此次大部分时间都放在了降低复杂度上。之前由于没有控制数据生成的上下限,所以很多数据都递归太深或者系数太大,很容易TLE,也不满足课程组的要求。
3.Bug分析
由于此次大面积重构,以及化简写的不太完善,出现了不少bug,强测和互测中个被hack一个点,另外我自己在提交之后也发现了一个bug
- 在处理三角函数的0次幂时没有特判,将sin(0)**0输出为0
- 在三角函数化简的时候没有化简内部的嵌套三角函数因子,导致强测错误一个点
- 我自己在测试数据的时候发现由于我直接操作了HashMap的keySet导致错误,但是并未被hack到。
四、个人反思与感想
1.架构与设计反思
-
本次的大架构个人认为没有太大问题,递归下降的思路也让我很受启发,但是实现确实差了点(一开始容器的选取以及表达式的解析等),属于是将win11在最初的晶体管计算机上运行。
-
由于时间没有把握的好,所以每次作业其实都像是在被追赶,最后匆匆交上去一个并不是很好的版本,自己有很多想法也没有来得及实现(实现自定义函数的自动化测评,更加复杂的三角函数变换),所以下一次作业需要提前准备架构,最好在周四公测的时候就能过中测,之后慢慢细化。
-
比较遗憾的一个点是没有使用工厂模式,由于第一次作业的因子不多,所以没有使用工厂模式,但是随着后面作业的深化,其实就应该及时使用工厂模式,简化一些类的耦合度,并且方便获得因子。
-
数据构造的时候没有加入边界数据,下一次构造数据可以考虑加入边界数据集,以及遇到的一些容易出bug的数据。
2.个人提升
- Python能力:苦于上个学期计组的自动化测评不够完善,所以我在假期也自学了一些简单的Python,虽然水平有限,但是已经能够完成一些简单的测评,并且能力通过这次作业有了很大的提升。
- 数据构造能力:上个学期我在CO课上写了数据生成器,但是当时更多的还是基于一些面向过程的思路,虽然分开管理了各个指令,但是最终的生成十分臃肿。有了之前的经验之后,这次的数据生成器明显写起来轻车熟路,而且更多是基于OO的思想,不断增量开发。
- 工程架构能力:在经历上个学期CO课和这个学期的OO,意识到了一个好的架构的重要性,一个上千行的代码尚且如此,以后的工程上的更加大型的东西就更多的时间建立框架,我之前的设计习惯一直不好,喜欢走一步看一步,经过这次学习,设计的思想也进一步提升了。
- OO思想:此次作业主要是抽象表达式因子,我逐步摒弃了之前一些面向过程的思想,提升了面向对象编程的能力。
- java:主要是提升了容器的处理能力。
3.课程建议
OO的课程已经相当完善,我只能提一个浅薄的建议,主要是在互测上的。
个人认为第三次互测的要求完全可以放在第二次,第二次作业大家的bug都比较少,主要就是sum函数和自定义函数都不能使用,而第三次作业仅仅开放了sum,而且互测的要求明显是第二次作业就能够完成的,这种情况下第三次作业依然有大量hack,说明第二次作业的测试强度不够,一些bug被保留到了第三次,我认为第二次作业起码能够开放sum的互测,第三次可以开放自定义函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号