

分布式数据库greenplum详解
前言
在数据库诞生到现在,我们所能耳熟能详的数据库如oracle,mysql,sqlserver等,都属于关系型数据库,它们主要是基本的、日常的事务处理,记录即时的增、删、改、查,实时性要求很高,但数据量不会很大,不会做很多复杂的逻辑,这一类归于OLTP(联机事务处理)型数据库,而分布式数据库是对海量的数据进行管理,解决的是海量的数据处理及分析能力,更多的是对数据进行读的操作,增、删、改是比较低频的操作,它对实时性要求不高,更强调的是数据的分析处理能力,属于OLAP(联机分析处理)型数据库。
以下是OLAP和OLTP的比较:
| OLTP | OLAP | |
| 适用场景 | 主要供基层人员使用,进行一线业务操作 | 探索并挖掘数据价值,作为企业高层进行决策的参考 |
| 数据特点 | 当前的、最新的、细节的, 二维的、分立的 | 历史的, 聚集的, 多维的,集成的, 统一的 |
| 存取能力 | 可以读/写数十条记录 | 读上百万条记录 |
| 复杂度 | 简单的事务 | 复杂任务 |
| 可承载用户 | 可承载用户数量为上千个 | 上百万个 |
| DB大小 | 大小为100GB | 可以达到100TB |
| 时效性 | 实时 | 时间的要求不严格 |
greenplum属于OLAP型的一种分布式的关系型数据库,应用于数据仓库,它的底层是基于开源的关系型数据库postgresql进行开发完成的,postgresql拥有丰富的数据类型,强容错能力及存储结构等优点,因而也一跃而上,成为目前主流的数据库之一,由于greenplum底层是postgresql的原因,因此greenplum也继承了postgresql的这些优点,并且两者之间进行数据迁移可以做到完全兼容,避免进行数据转换。
postgresql排名图:

结构
主从结构
greenplum采用一主(Master)多从(Segment)的结构,Master负责查询解析、优化及任务分发,Segment负责查询处理、数据存储,双方通过Interconnect通信,总体架构如下:
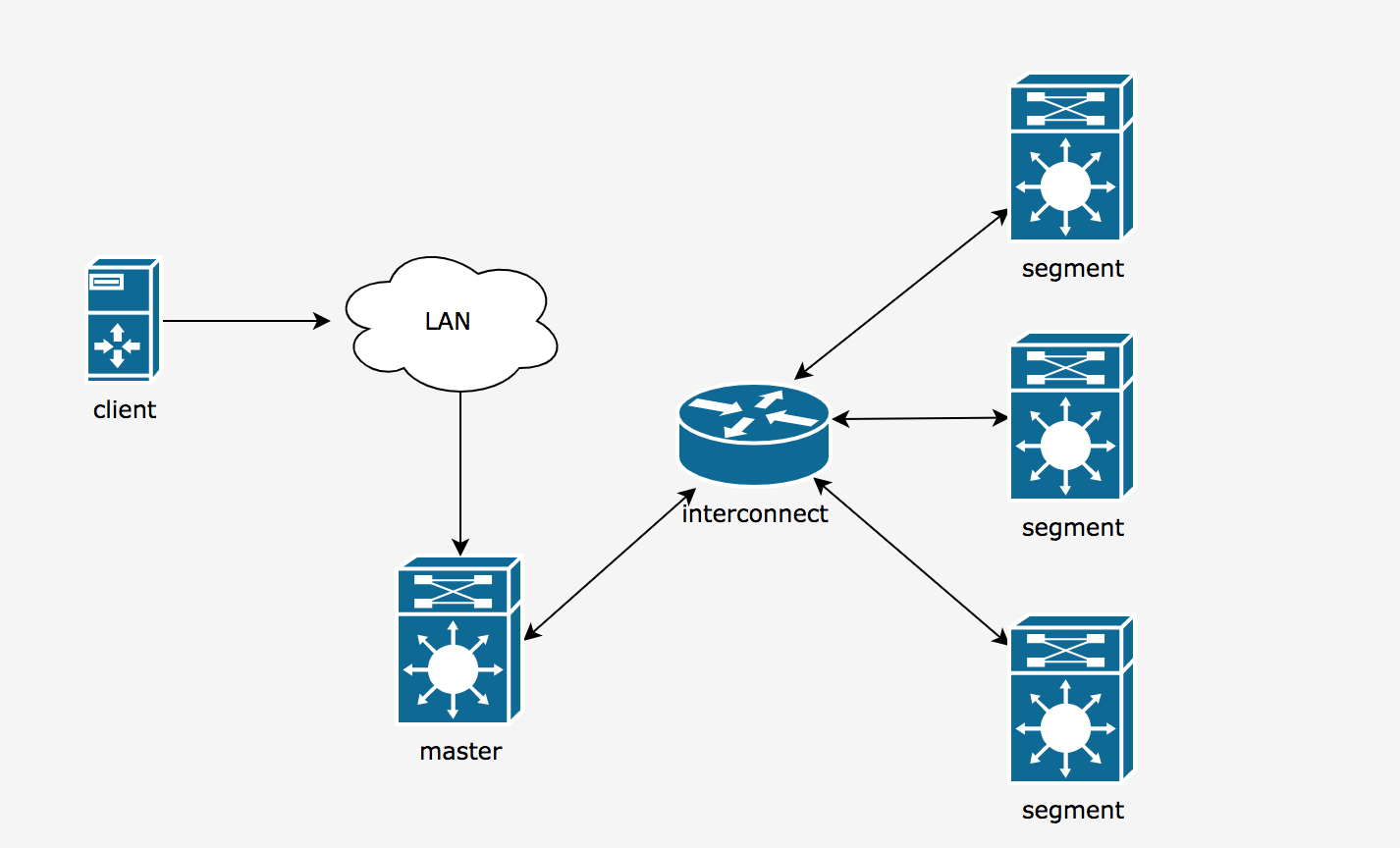
master节点:
是整个系统的控制中心和对外的服务接入点,它负责接收用户SQL请求,将SQL生成查询计划并进行并行处理优化,然后将查询计划分配(dispatch)到所有的Segment节点进行并行处理,协调组织各个Segment节点按照查询计划一步一步地进行并行处理,最后获取到Segment的计算结果,再返回给客户端;从用户的角度看Greenplum集群,看到的只是Master节点,无需关心集群内部的机制,所有的并行处理都是在Master控制下自动完成的。Master节点一般只有一个或两个(互为备份),主备方案实现高可用;
segment节点:
是Greenplum执行并行任务的并行运算节点,它接收Master的指令进行MPP并行计算,因此所有Segment节点的计算性能总和就是整个集群的性能,通过增加Segment节点,可以线性化得增加集群的处理性能和存储容量,Segment节点可以是1~10000个节点,它的数量决定greenplum的算力,可通过横向扩容提升整个数据库的算力及性能;
Interconnect:
是Master节点与Segment节点、Segment节点与Segment节点之间的数据传输组件,它基于千兆交换机或万兆交换机实现数据在节点间的高速传输;
无共享/MPP架构
Greenplum数据库软件将数据平均分布到系统的所有节点服务器上,所以节点存储每张表或表分区的部分行,所有数据加载和查询都是自动在各个节点服务器上并行运行,并且该架构支持扩展到上万个节点,做到数据完全的物理隔离。
Greenplum的架构采用了MPP(大规模并行处理),在 MPP 系统中,每个 SMP节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution) 。
SMP(SymmetricMulti-Processing),对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。在这种技术的支持下,一个服务器系统可以同时运行多个处理器,并共享内存和其他的主机资源。传统的ORACLE和DB2均是此种类型,ORACLE RAC 是半共享状态;
与传统的SMP架构明显不同,通常情况下,MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点,但是这也不是绝对的,因为 MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反,如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。

特性
greenplum是用于海量存储数据进行计算与分析的,它做数据分析跟计算时,往往所做的大量查询都是全表检索的模式进行的,是不建议添加索引的,而是用它分区、分布键的特性结合多个segment的并行将算力达到最大化。
分区
分区是对存储的数据进行逻辑划分,通过 "partition by" 子句完成的,它允许将一个大表划分为多个子表。"subpartition by" 子句可以将子表划分为更小的表 。从理论上讲,Greenplum对于根表(root table)可以拥有多少级(level)或多少个分区表(partitioned table)并没有限制,但是对于任一级分区(表的层次结构级别),一个分区表最多可以有32,767个子分区表。
以时间为例,一个table表可以按字段month(月份)分区成table_01,table_02,... table_11,table_12,但都是在一个segment上。
分布键
与分区不同,分布键是进行物理划分,它是分布在不同的segment上,以指定的分布键字段或字段组合进行哈希/随机的策略分布,散布到不同的segment上,将数据平均分布到每一个节点机器上,为了避免数据倾斜导致算力不均,建议使用哈希策略进行分布,创建表使用 “distributed by(column,[…])” 子句。
同样以时间为例,t_test表中'2020-01-01'的数据散布在segment1的t_test_01表上,'2020-01-02'的数据散布在segment2的t_test_02表上 ...
create table t_test ( id int, month varchar(10), name varchar(64) ) distributed by (month) partition by range(month) ( partition 01 start ('2020-01-01') inclusive end ('2020-01-31') inclusive, partition 02 start ('2020-02-01') inclusive end ('2020-02-31') inclusive, partition 03 start ('2020-03-01') inclusive end ('2020-03-31') inclusive, partition 04 start ('2020-04-01') inclusive end ('2020-04-31') inclusive, partition 05 start ('2020-05-01') inclusive end ('2020-05-31') inclusive, partition 06 start ('2020-06-01') inclusive end ('2020-06-31') inclusive, partition 07 start ('2020-07-01') inclusive end ('2020-07-31') inclusive, partition 08 start ('2020-08-01') inclusive end ('2020-08-31') inclusive, partition 09 start ('2020-09-01') inclusive end ('2020-09-31') inclusive, partition 10 start ('2020-10-01') inclusive end ('2020-10-31') inclusive, partition 11 start ('2020-11-01') inclusive end ('2020-11-31') inclusive, default partition 12 );
存储和执行
Master和Segment都是一个单独的PostgreSQL数据库。每一个都有自己单独的一套元数据字典。
Master节点一般也叫主节点,Segment叫做数据节点。
为了实现高可用,每个Segment都有对应的备节点 Mirror Segment分别存在与不同的机器上。
Client一般只能与Master节点进行交互,Client将SQL发给Master,然后Master对SQL进行分析后再将其分配给所有的Segment进行操作。
Greenplum没有Windows版本,只能安装在类UNIX的操作系统上。
Greenplumn极度消耗I/O资源,所以对存储的要求比较高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号