
软件工程-作业2
个人项目:论文查重系统
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业链接 |
| 这个作业的目标 | 算法设计与实现、工程化能力、文档与报告 |
GitHub 项目地址:shiyao.com
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 10 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 180 | 200 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 15 |
| Design Spec | 生成设计文档 | 20 | 10 |
| Design Review | 设计复审 | 10 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| Design | 具体设计 | 10 | 5 |
| Coding | 具体编码 | 60 | 80 |
| Code Review | 代码复审 | 20 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 20 |
| Reporting | 报告 | 30 | 45 |
| Test Repor | 测试报告 | 30 | 45 |
| Size Measurement | 计算工作量 | 20 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| ·合计 | 485 | 510 |
二、计算模块设计
1. 接口设计与实现
类结构
Main: 程序入口,处理命令行参数FileUtils: 文件读写工具类PaperCheckService: 查重算法ApplicationExceptionHandler: 启动类异常处理CommandLineArgsChecker: 启动前参数检查
Main->CommandLineArgsChecker(检查参数)->FileUtils(读)->PaperCheckService(查重计算)->FileUtils(写)->结束
算法关键:词频向量的余弦相似度
三、性能改进
PaperCheckService: 查重算法中,一开始想用滑动窗口+二分查找来查重,但是对与复杂文本难以适用于是改用词频向量的余弦相似度
1.滑动窗口+二分查找:
class LCSChecker {
// 使用二分查找 + 滑动窗口找最长公共子串的长度
public static int binarySearchLCS(String s1, String s2) {
// 确保 s1 是较短的字符串,减少哈希集合的大小,提高匹配效率
if (s1.length() > s2.length()) {
String temp = s1;
s1 = s2;
s2 = temp;
}
int low = 0, high = s1.length(); // 二分查找范围
int bestLength = 0; // 记录最长公共子串的长度
// 二分查找最长公共子串
while (low <= high) {
int mid = (low + high) / 2; // 取中间长度
if (hasCommonSubstring(s1, s2, mid)) { // 判断是否存在该长度的公共子串
bestLength = mid; // 更新最长子串长度
low = mid + 1; // 尝试更长的子串
} else {
high = mid - 1; // 尝试更短的子串
}
}
return bestLength;
}
}
2.词频向量的余弦相似度:
@Service
public class PaperCheckService {
// 停用词表
private static final Set<String> STOP_WORDS = new HashSet<>(Arrays.asList(
"的", "了", "在", "是", "我", "有", "和", "就", "不", "人", "都", "与", "上", "这", "你"
));
/**
* 计算两篇文本的相似度
* @param original 原始文本
* @param plagiarized 待检测文本
* @return 相似度得分(0.0~1.0)
*/
public static double computeSimilarity(String original, String plagiarized) {
// 处理空文本边界情况
if (original.isEmpty() && plagiarized.isEmpty()) return 1.0; // 两文本均为空视为完全相似
if (original.isEmpty() || plagiarized.isEmpty()) return 0.0; // 任一文本为空视为无相似
// 文本预处理:分词 -> 过滤停用词 -> 过滤单字
List<String> originalTerms = processText(original);
List<String> plagiarizedTerms = processText(plagiarized);
// 构建联合词频向量(Key: 词语, Value: int[2]数组,0位存原文词频,1位存待检测文本词频)
Map<String, int[]> termFrequency = new HashMap<>();
buildTermFrequencyVector(originalTerms, termFrequency, 0); // 处理原文
buildTermFrequencyVector(plagiarizedTerms, termFrequency, 1); // 处理待检测文本
// 计算并返回余弦相似度
return calculateCosineSimilarity(termFrequency);
}
/**
* 文本预处理流水线
* @param text 原始文本
* @return 处理后的词语列表(小写,已过滤停用词和单字)
* @author zyh
* @date 2025/03/06
*/
private static List<String> processText(String text) {
return ToAnalysis.parse(text).getTerms().stream() // 分词器进行中文分词
.map(Term::getName) // 提取分词结果
.filter(word -> !STOP_WORDS.contains(word)) // 过滤停用词
.filter(word -> word.length() > 1) // 过滤单字
.collect(Collectors.toList());
}
/**
* 构建词频统计向量
* @param terms 词语列表
* @param frequencyMap 词频统计Map
* @param index 统计位置(0表示原文,1表示待检测文本)
* @author zyh
* @date 2025/03/06
*/
private static void buildTermFrequencyVector(List<String> terms,
Map<String, int[]> frequencyMap,
int index) {
terms.forEach(term -> {
frequencyMap.putIfAbsent(term, new int[2]); // 初始化词频数组
frequencyMap.get(term)[index]++; // 对应位置词频+1
});
}
/**
* 计算余弦相似度公式:cos=(A·B)/(||A||*||B||)
* @param frequencyMap 词频统计表
* @return 余弦相似度值(范围0.0~1.0)
* @author zyh
* @date 2025/03/06
*/
private static double calculateCosineSimilarity(Map<String, int[]> frequencyMap) {
double dotProduct = 0.0; // 点积(分子)
double normA = 0.0; // 向量A的模长平方
double normB = 0.0; // 向量B的模长平方
for (int[] vector : frequencyMap.values()) {
// 计算点积
dotProduct += vector[0] * vector[1];
// 分别累加模长平方
normA += Math.pow(vector[0], 2);
normB += Math.pow(vector[1], 2);
}
// 处理除零情况
if (normA == 0 || normB == 0) return 0.0;
// 计算并返回最终相似度
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));
}
}
3.Intellij Profiler分析:

四、单元测试
1.单元测试代码
class PaperCheckServiceTest {
/**
* 测试完全相同的文本
* 预期结果:相似度应为1.0
*/
@Test
void testExactMatch() {
assertEquals(1.0, PaperCheckService.computeSimilarity("今天天气很好", "今天天气很好"), 0.01);
}
/**
* 测试完全不同的文本
* 预期结果:相似度应为0.0
*/
@Test
void testCompletelyDifferent() {
assertEquals(0.0, PaperCheckService.computeSimilarity("今天天气很好", "计算机科学"), 0.01);
}
/**
* 测试空文本处理(双空)
* 预期结果:相似度应为1.0
*/
@Test
void testBothEmpty() {
assertEquals(1.0, PaperCheckService.computeSimilarity("", ""), 0.01);
}
/**
* 测试空文本与正常文本
* 预期结果:相似度应为0.0
*/
@Test
void testOneEmpty() {
assertEquals(0.0, PaperCheckService.computeSimilarity("", "深度学习"), 0.01);
}
/**
* 测试单字词过滤
* 数据构造:原文含单字词,对比文本无单字词
* 预期结果:相似度为0.0(有效词被过滤后无交集)
*/
@Test
void testSingleCharacterFiltered() {
assertEquals(0.0, PaperCheckService.computeSimilarity("A 数据", "数据挖掘"), 0.01); // 处理后"数据" vs "数据""挖掘"
}
/**
* 测试词序不影响结果
* 数据构造:相同词汇不同顺序
* 预期结果:相似度应为1.0
*/
@Test
void testWordOrderIrrelevant() {
assertEquals(1.0, PaperCheckService.computeSimilarity("机器学习 深度学习", "深度学习 机器学习"), 0.01);
}
/**
* 测试部分重复内容
* 数据构造:两文本有 50% 词汇重叠
* 预期结果:相似度约为 0.5(实际值取决于词频)
*/
@Test
void testPartialOverlap() {
String text1 = "自然语言处理 文本分析 算法";
String text2 = "文本分析 机器学习 算法";
double similarity = PaperCheckService.computeSimilarity(text1, text2);
assertTrue(similarity > 0.4 && similarity < 0.6);
}
/**
* 测试长文本重复
* 数据构造:长文本与自身+少量新增内容对比
* 预期结果:相似度接近 1.0
*/
@Test
void testLongText() {
String base = "分布式系统的核心是容错性和一致性。";
String text1 = base.repeat(100);
String text2 = text1 + "新增补充内容。";
assertTrue(PaperCheckService.computeSimilarity(text1, text2) > 0.95);
}
/**
* 测试特殊符号处理
* 数据构造:含特殊符号的文本与纯净文本对比
* 预期结果:相似度应为 1.0(符号被过滤)
*/
@Test
void testSpecialSymbols() {
assertEquals(1.0, PaperCheckService.computeSimilarity("数据!@#", "数据"), 0.01);
}
/**
* 测试全停用词导致空向量
* 数据构造:两文本均为停用词
* 预期结果:相似度应为 0.0
*/
@Test
void testAllStopWords() {
assertEquals(0.0, PaperCheckService.computeSimilarity("这是的", "就和在"), 0.01);
}
}
2.覆盖率
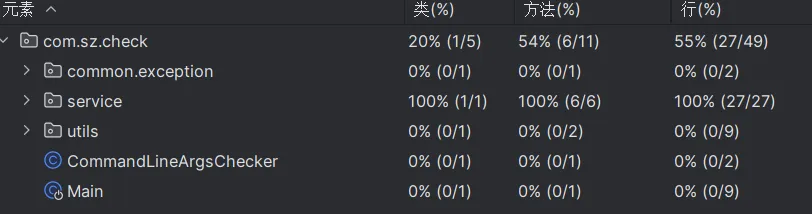
五、异常处理
1.异常设计代码
public class ExceptionTest {
@Test
void testReadFile_FileNotExist() {
//场景:文件不存在
String path = "non_existent.txt";
String content = FileUtil.readFile(path);
assertNull(content); // 预期返回 null
// 控制台应输出:"文件读错误: non_existent.txt"
}
@Test
void testWriteFile_InvalidPath() {
//场景:写入路径不可用(如目录不存在)
String path = "/invalid_directory/result.txt";
FileUtil.writeFile(path, "test content");
// 控制台应输出:"文件写错误: /invalid_directory/result.txt"
}
@Test
void testCheckArgs_InvalidArgumentCount() {
//场景:参数数量不匹配
String[] args = {"path1.txt", "path2.txt"}; // 仅2个参数
Exception exception = assertThrows(RuntimeException.class, () ->
new CommandLineArgsChecker().run(args));
System.out.println("捕获异常: " + exception.getMessage());
// 控制台应输出:"捕获异常: 命令错误,请按照格式输入:java -jar main.jar <原文路径> <抄袭版路径> <答案路径>"
assertTrue(exception.getMessage().contains("命令错误"));
}
}
2.设计目标
1.testReadFile_FileNotExist
- 目标:
- 文件不存在时返回
null,避免程序崩溃 - 打印错误路径(
文件读错误: non_existent.txt),便于定位问题
- 文件不存在时返回
- 场景:文件不存在
2.testWriteFile_InvalidPath
- 目标:
- 写入失败时静默处理,避免程序终止
- 记录错误路径(
文件写错误: /invalid_directory/result.txt)
- 场景:写入路径不可用(如目录不存在)
3.testCheckArgs_InvalidArgumentCount
- 目标:
- 参数不足时立即抛出异常,阻止后续无效操作
- 提示正确命令格式(
java -jar main.jar <原文路径> <抄袭版路径> <答案路径>)
- 场景:参数数量不匹配

 浙公网安备 33010602011771号
浙公网安备 33010602011771号