



springboot 整合 Elasticsearch
Elasticsearch
一个分布式的搜索引擎
支持各种类型的数据检索
搜索速度快,可以提供实时的搜索服务
便于水平扩展,每秒可以处理BP级海量数据。
Elasticsearch术语 意思
索引 相当于数据库
类型 数据库中的表(最新版本已弃用)
文档 一行数据(相当于一个对象全部数据)
字段 就是一列一个字段
然后我们要学习Elasticsearch的话,先下载
可以去 www.elastic.co 下载哦!
版本问题
这里要注意一下哈,7.0后的版本开始逐步遗弃掉类型的概念,用索引来代替拉,
但是俺还是用6.4.3的版本试试吧。
文件下载下来,就是一个压缩包哈,解压即可!
解压后以后呢,我们要对config配置文件进行配置一下哈。
进去后,打开 elasticsearch.yml 文件哈,然后进行如下配置即可
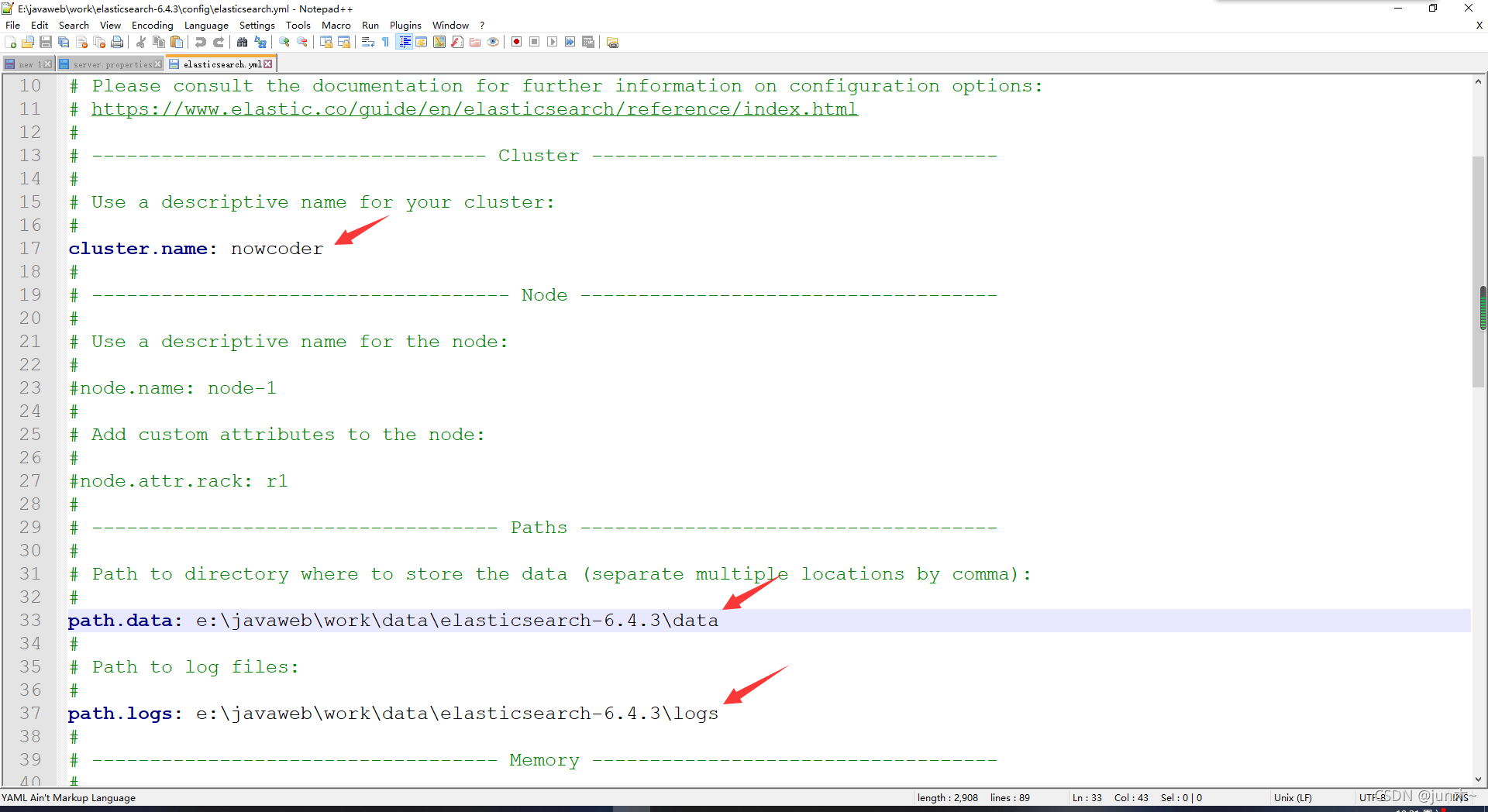
配置好文件后呢,我们还要去下载一个 分词 的软件
分词软件
那么啥是分词呢?
举个例子: 互联网招聘
我要所搜互联网招聘,那么我们就要将其分成 互联、联网、网招、招聘、互联网等等。
这样匹配多的那就放在最前面,方便我们的搜索!!
但是哈,下载的elasticsearch只有对英文的分词,没有中文的,所以我们还要进行下载一个对中文分词的插件
这个插件可以去 github 上下载哈,直接搜索 elasticsearch ik 即可,一般第一个就是。
然后我们要找到和自己下载的elastic版本相同的分词版本哈!!
这个也是个压缩包,你解压到 原来elasticsearch文件里面的 插件文件plugins 下面的 ik文件夹下即可。(ik文件夹自己创建哈)
到这里,我们就可以使用命令行,进行操作了,(记得将里面bin路径存放到环境变量里面去哈!)
bin路径下的 elasticsearch.bat 文件可以启动服务器,不用的时候直接关掉就行
完成后,我们就可以在cmd里面进行简单的测试了
我们可以试试以下命令
# 查看该es服务器的健康状态
curl -X GET "localhost:9200/_cat/health?v"
# 查看节点
curl -X GET "localhost:9200/_cat/nodes?v"
# 查看索引
curl -X GET "localhost:9200/_cat/indeces?v"
# 创建索引
curl -X PUT "localhost:9200/test"
# 删除索引
curl -X DELETE "localhost:9200/test"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这里就不给你们试了哈,不过记得试下哈,怕出问题。
然后命令行其实存东西是挺麻烦的,所以我们还要下载个东东 — postMan
让我们用起来更方便的 下载地址:www.getpostman.com
postMan
先利用命令向里面存放点东西 localhost:9200/test/_doc/3
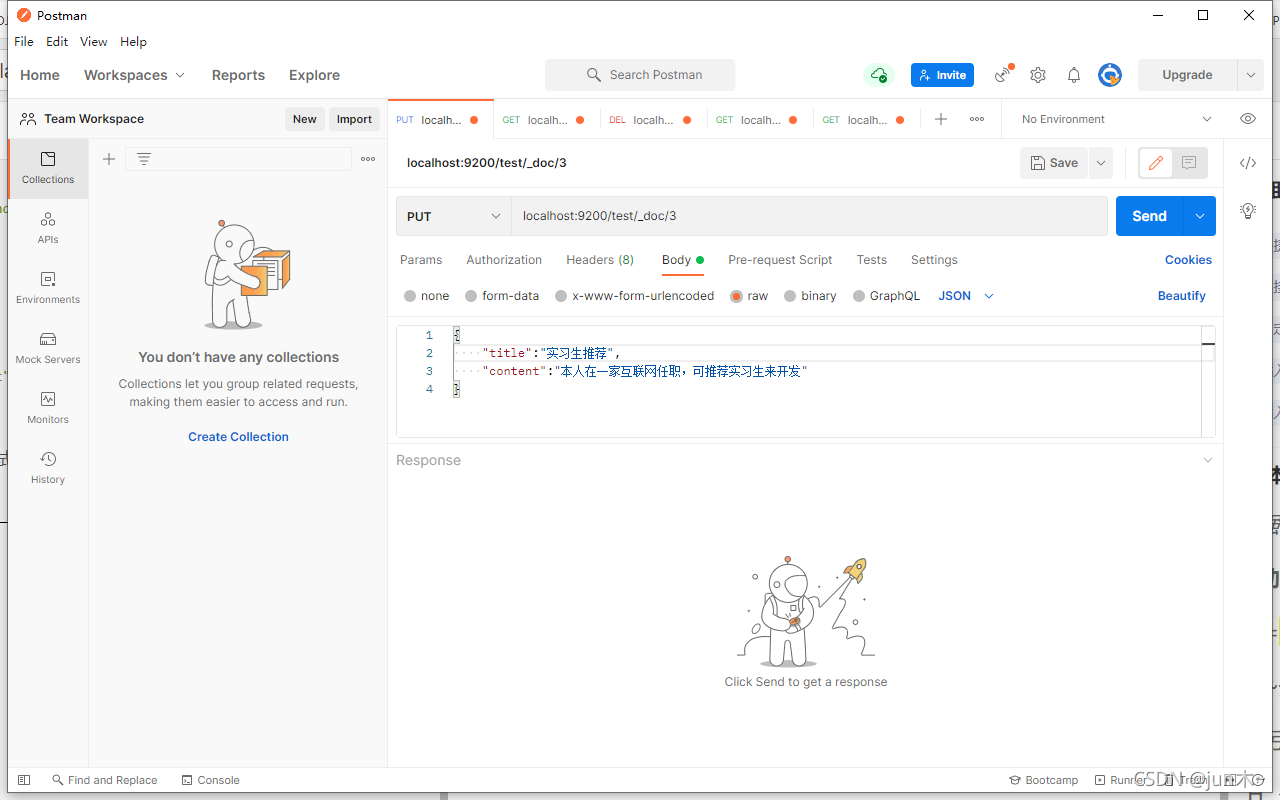
这里,我们 test索引 里面就会有数据了,记得看清哈,我们使用的是Body里面的raw里面,数据采用JSON进行传输即可。
然后采用 localhost:9200/test/_search 命令进行数据的分词搜索

这不比cmd舒服?啊哈哈哈哈哈
搞定这些,我们就可以进行数据的整合啦!
spring 整合 Elasticsearch
三步走:
一、 引入依赖
二、 对Elasticsearch进行配置
三、 使用Spring Data Elasticsearch
一、引入依赖
因为是spring boot项目,所以他的上面会有他自己调试好的版本,所以我们不需要写版本号
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
1
2
3
4
二、 配置Elasticsearch
在 application.properties 里面配置
# ElasticsearchProperties
spring.data.elasticsearch.cluster-name=nowcoder
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
1
2
3
这里的cluster-name 就是前面配置的时候配置的。
Elasticsearch将绑定到HTTP和节点/传输API的单个端口。
它会先尝试最低的可用端口,如果已经被使用,请尝试下一个端口。如果在机器上运行单个节点,则只能绑定到9200和9300。
端口的区别
9200用于外部通讯,基于http协议,程序与es的通信使用9200端口。
9300jar之间就是通过tcp协议通信,遵循tcp协议,es集群中的节点之间也通过9300端口进行通信。
三、 使用 Spring Data Elastisearch (6.4.3版本)
这里它有两个类可以使用哈!
ElasticsearchTemplate
ElasticsearchRepository
后者使用起来方便一点,所以我们使用后者哈!(高版本前者已经被取消了)
ElasticSearchRepository
先对我们的实体进行加注解,这样就能达到一个 映射 的目的
这里我们主要是对帖子进行查询,所以我们对帖子实体类进行加注解
@Id
private int id;
@Field(type = FieldType.Integer)
private int userId;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
@Field(type = FieldType.Integer)
private int type;
@Field(type = FieldType.Integer)
private int status;
@Field(type = FieldType.Date)
private Date createTime;
@Field(type = FieldType.Integer)
private int commentCount;
@Field(type = FieldType.Double)
private double score;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26

最上面的四个,分别表示: 索引 、 文档 、 节点数 、 副本数
id是设置主键哈,其余的跟着套用就行。
要查询的字段是 title 和content 所以我们还要设置他的查询方式。
Elasticsearch 其实就是一个特殊的数据库,所以我们也要搞一个数据访问层
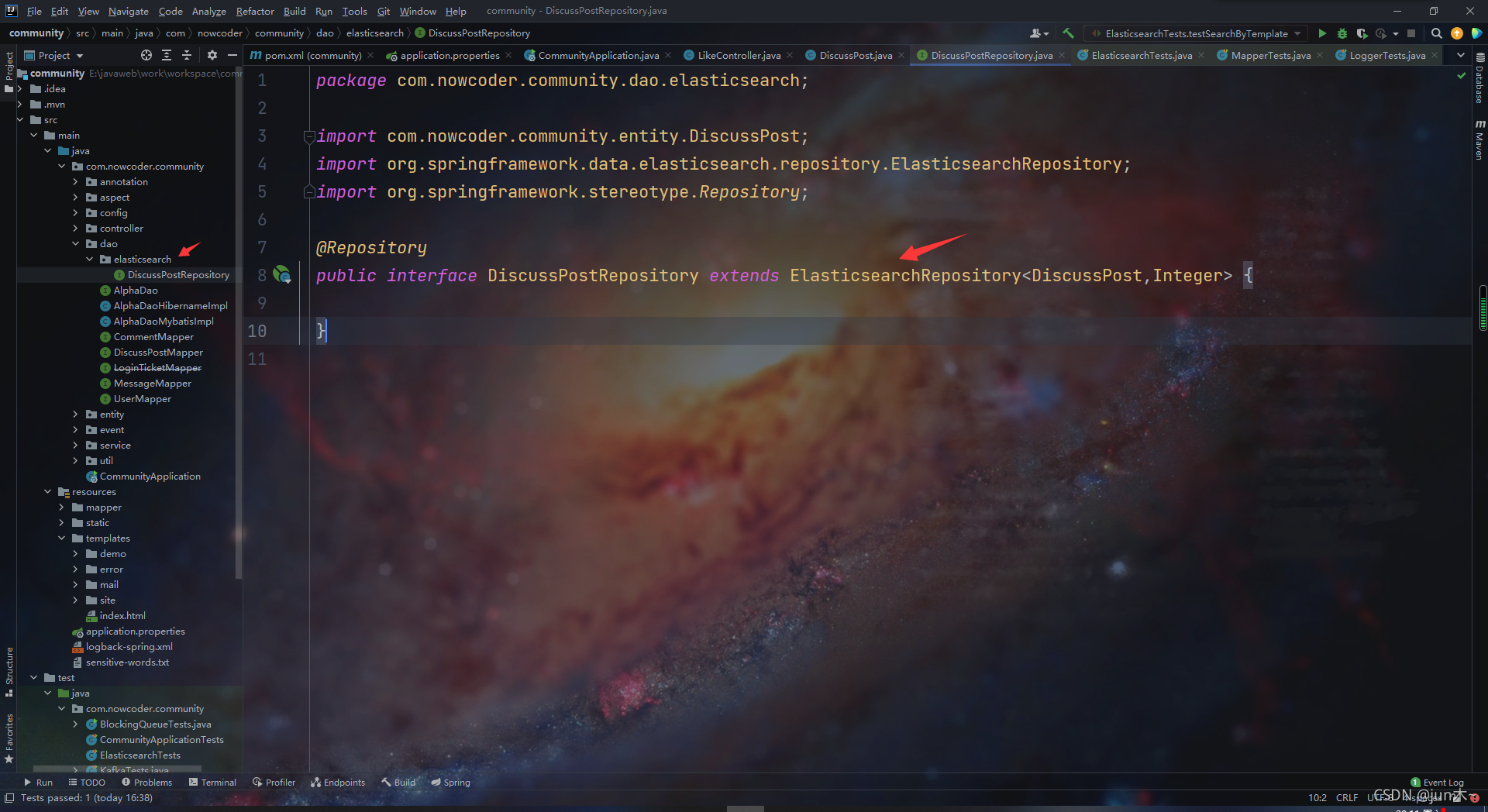
可以看出哈,这个不需要我们做什么,只需要加个注解,然后继承个ElasticsearchRepository类,然后设置下泛型即可。
Mapper注解式 mybatis 专属的哈, Repository 才是 spring提供的数据访问层的注解哈!
冲突问题
这个划重点哈!
因为不重视的话,就会 报错
available processors value [%d] did not match current value [%d]
这个我们要看看 Netty4Utils 类里面啦
原因就是原来的 Redis 服务将这个给占用了,然后我们的es也依赖这个,所以就冲突了,但是还好,人家给了解决方法,将那个类设置为false即可跳过这个检查!!!
但是在初始化的时候完成,所以这个时候,我们就可以用上 @PostPostConstruct 注解来完成初始化。我们写在CommunityApplication里面的哈
@SpringBootApplication
public class CommunityApplication {
@PostConstruct
public void init(){
// 解决netty启动冲突问题
// see Netty4Utils.setAvailableProcessors()
System.setProperty("es.set.netty.runtime.available.processors","false");
}
public static void main(String[] args) {
SpringApplication.run(CommunityApplication.class, args);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
搞完这些,我们就可以建立测试类,进行测试拉!!
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class ElasticsearchTests {
@Autowired
private DiscussPostMapper discussMapper;
@Autowired
private DiscussPostRepository discussRepository;
@Autowired
private ElasticsearchTemplate elasticTemplate;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
我们先整个测试类,并且将要用到的东东注进去
先来存单条数据
@Test
public void testInsert(){
discussRepository.save(discussMapper.selectDiscussPostById(241));
discussRepository.save(discussMapper.selectDiscussPostById(242));
discussRepository.save(discussMapper.selectDiscussPostById(243));
}
1
2
3
4
5
6
这样通过id就可将这个帖子存放进去。而他的 索引 就是 discusspost,在上面的实体类上的注解已经定义过啦!!
先来存多条数据
@Test
public void testInsertList(){
discussRepository.saveAll(discussMapper.selectDiscussPosts(101,0,100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(102,0,100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(103,0,100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(111,0,100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(112,0,100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(131,0,100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(132,0,100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(133,0,100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(134,0,100));
}
1
2
3
4
5
6
7
8
9
10
11
12
这里我们可以使用 postMan 进行查询一下哈
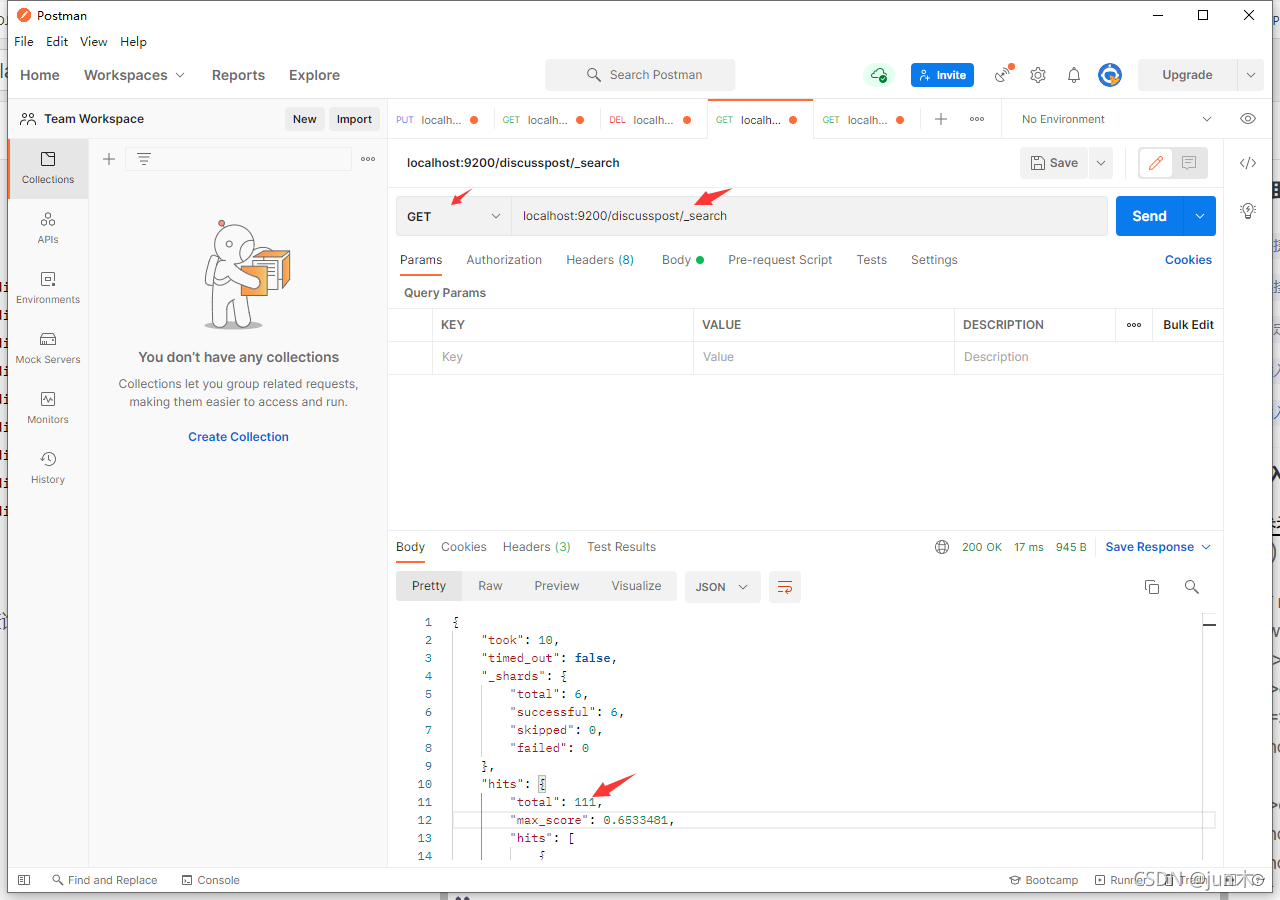
可以看出来,直接插入了一百多条哈!!
我们也可以利用Repository的save进行数据的修改
@Test
public void testUpdate(){
DiscussPost post = discussMapper.selectDiscussPostById(231);
post.setContent("我是大帅哥,请使劲灌水!!!");
discussRepository.save(post);
}
1
2
3
4
5
6
数据的删除
@Test
public void testDelete(){
discussRepository.deleteById(231);
// 删除所有数据
discussRepository.deleteAll();
}
1
2
3
4
5
6
删除全部,慎用哈!!!
回不来的那种哦!!
数据的查询(代码)
这个要重要说明哈!
我们对 “互联网招聘” 进行搜索, 在 title 和 content 字段里面查询
然后先按 类型 排降序,再按 成绩 排降序, 再按 创建时间 排降序
然后继续分页,从第0页,每页搞10 条
@Test
public void testSearchByRepository(){
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("互联网招聘","title","content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(0,10))
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
Page<DiscussPost> page = discussRepository.search(searchQuery);
System.out.println(page.getTotalElements());
System.out.println(page.getTotalPages());
System.out.println(page.getNumber());
System.out.println(page.getSize());
for (DiscussPost post : page) {
System.out.println(post);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
但是这个没有关键字高亮显示哈。
数据的高亮显示
原理就是再关键字左右加上一个 < em> 标签,然后到页面的时候,利用css进行样式的调节即可。
有点长,这个
@Test
public void testSearchByTemplate(){
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬","title","content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(0,10))
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
Page<DiscussPost> page = elasticTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits();
if(hits.getTotalHits()<=0){ // 没查到数据
return null;
}
List<DiscussPost> list = new ArrayList<>();
for (SearchHit hit : hits) {
DiscussPost post = new DiscussPost();
String id = hit.getSourceAsMap().get("id").toString();
post.setId(Integer.parseInt(id));
String userId = hit.getSourceAsMap().get("userId").toString();
post.setUserId(Integer.parseInt(userId));
String title = hit.getSourceAsMap().get("title").toString();
post.setTitle(title);
String content = hit.getSourceAsMap().get("content").toString();
post.setContent(content);
String status = hit.getSourceAsMap().get("status").toString();
post.setStatus(Integer.parseInt(status));
String createTime = hit.getSourceAsMap().get("createTime").toString();
post.setCreateTime(new Date(Long.parseLong(createTime)));
String commentCount = hit.getSourceAsMap().get("commentCount").toString();
post.setCommentCount(Integer.parseInt(commentCount));
// 处理高亮显示
HighlightField titleField = hit.getHighlightFields().get("title");
if(titleField != null){
post.setTitle(titleField.getFragments()[0].toString());
}
HighlightField contentField = hit.getHighlightFields().get("content");
if(contentField != null){
post.setContent(contentField.getFragments()[0].toString());
}
list.add(post);
}
return new AggregatedPageImpl(list,pageable,
hits.getTotalHits(),response.getAggregations(),response.getScrollId(),hits.getMaxScore());
}
});
System.out.println(page.getTotalElements());
System.out.println(page.getTotalPages());
System.out.println(page.getNumber());
System.out.println(page.getSize());
for (DiscussPost post : page) {
System.out.println(post);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
而且是使用elasticTemplate 的 queryForPage 方法搞定的,这个高版本已经没有了哦,
所以要用的话,记得下载6.*的版本哈。
到这里就完成了利用elasticsearch进行数据的增删改查了哈。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号