
Multiclass SVM loss:多分类SVM损失函数
1. SVM 损失:在一个样本中,对于真实分类与其他每各个分类,如果真实分类所得的分数与其他各分类所得的分数差距大于或等于安全距离,则真实标签分类与该分类没有损失值;反之则需要计算真实分类与该分类的损失值; 真实分类与其他各分类的损失值的总和即为一个样本的损失值
①即真实标签分类所得分数大于等于该分类的分数+安全距离,S_yi >=S_j + △,那么损失值=0
②否则,损失值等于其他分类的分数 + 安全距离(阈值)- 真实标签分类所得的分数,即损失值=S_j + △ - S_yi
S_yi:真实标签分类的分数 S_j:其他标签的分数 △:安全距离、阈值
③以上是针对每一个样本而言的,一轮的损失值=n个样本损失值Li的算术平均和+正则化(每一个样本是指每一个测试数据)
④算法过程:对于每一个样本,计算真实分类与其他各个分类的损失值,真实分类与其他各个分类的损失值的总和即为一个样本的损失值;
所有的样本损失值的算术平均和 + 正则化 = 总体损失值
Li:(用于理解)此处的安全距离=1

Li表达式:
![]()
L表达式:
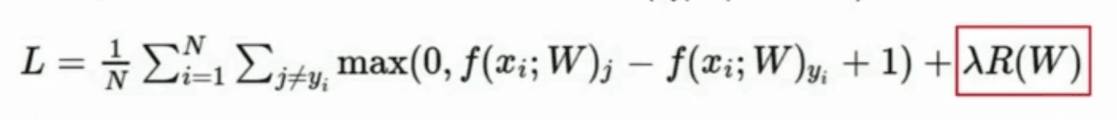
2. Multiclass SVM loss的图像:阈值为1

3. 例子
①一共有3个样本,第一个样本的真实分类是cat,第二个是car,第三个是frog。
注意:真实分类是指数据的真实标签,而不是预测标签

②第一个样本,真实标签是猫,所以要计算其他分类的得分与猫分类的得分是否在一个安全的范围内
max(汽车的分数 + 安全距离 - 猫的分数,0)+ max(青蛙的分数 + 安全距离 - 猫的分数,0)= max(2.9 , 0)+ max(-3.9,0)= 2.9
所有第一个样本的损失值为2.9,以此类推

③算完三个样本的损失值后,求三个样本损失值的算术平均和,该结果即为总体损失值(其实一般还要加一个正则化)
4. 代码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号