
<七>RabbitMQ队列、Redis
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。其中较为成熟的MQ产品有IBM WEBSPHERE MQ等等。
python RabbitMQ队列使用
queue介绍
关于python的队列,内置的有两种,一种是线程queue,另一种是进程queue,但是这两种queue都是只能在同一个进程下的线程间或者父进程与子进程之间进行队列通讯,并不能进行程序与程序之间的信息交换,这时候我们就需要一个中间件,来实现程序之间的通讯。
MQ并不是python内置的模块,而是一个需要你额外安装(ubunto可直接apt-get其余请自行百度。)的程序,安装完毕后可通过python中内置的pika模块来调用MQ发送或接收队列请求。
注意:send端和receive端两端通讯都是实时通信
RabbitMQ安装
#1: 安装erlang程序 #2:安装RabbitMQ # 通过service.msc查看服务是否开启 #3:安装pika模块
队列通信图:
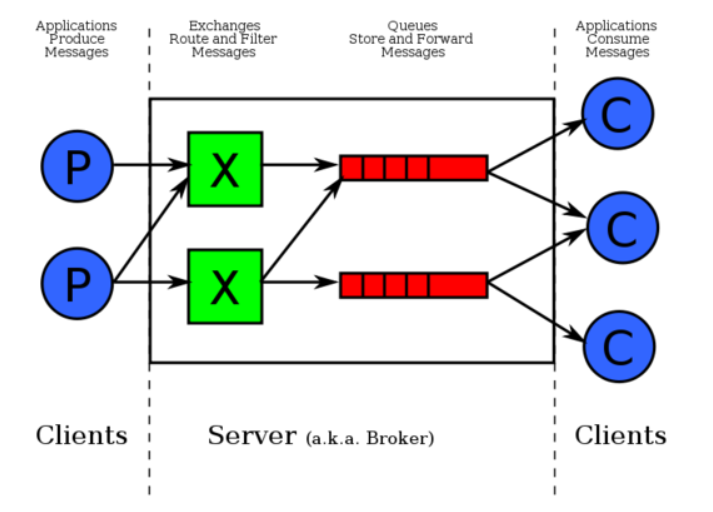
简单通信程序:
send端:
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pika
connection=pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel() #设置管道
channel.queue_declare(queue="hello1", durable=True) #生成消息队列 durable让队列持久化
channel.basic_publish(exchange="",
routing_key="hello1", #消息队列名
body="hello man 1234",
properties=pika.BasicProperties(
delivery_mode=2 #让消息持久化(即使rabbitmq宕机之后仍让存在)
)
) #要发送的消息
print("send data")
connection.close()
receive端:
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pika,time
connection=pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel() #设置管道
channel.queue_declare(queue="hello1", durable=True) #生成消息队列
def callback(ch,method,properties,body):
#print(ch,method,properties)
#time.sleep(2)
print("received data:",body)
ch.basic_ack(delivery_tag=method.delivery_tag) #消费者手动确认消息已收到RabbitMQ可以自由删除它,
channel.basic_qos(prefetch_count=1) #只能处理一条消息 接收处理完再接收 perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
channel.basic_consume(callback, #收到消息就调用callback函数处理
queue="hello1",
#no_ack=True #= no acknownlege
)
print("recv data....")
channel.start_consuming()
<1>消息持久化
服务器断开之后RabbitMQ中队列会依然保存,但队列中的数据会丢失。
channel.queue_declare(queue="hello1", durable=True) #生成消息队列 durable让队列持久化
为了让队列中的数据也持久化设置 delivery_mode=2即可
channel.basic_publish(exchange="",
routing_key="hello1", #消息队列名
body="hello man 1234",
properties=pika.BasicProperties(
delivery_mode=2 #让消息持久化(即使rabbitmq宕机之后仍让存在)
)
)
<2>消息公平发送
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
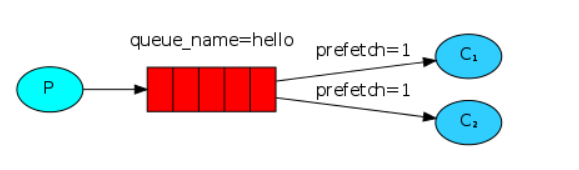
在receive端添加:
channel.basic_qos(prefetch_count=1) #只能处理一条消息 接收处理完再接收
<3>消息发布\订阅
想要消息被所有的Queue收到,类似广播的效果,这时候就要设置exchange的值:
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
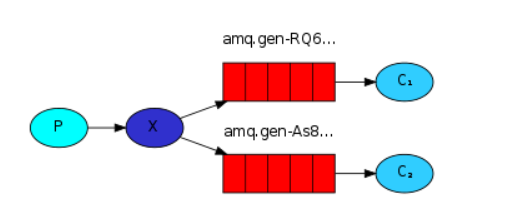
①fanout:所有bind到此exchange的queue都可以接收消息
send端:把消息发送到转发器哪儿即可
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pika
#fanout producer 和consumer 都是实时通讯
connection=pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel() #设置管道
channel.exchange_declare(exchange="logs", #设置转发器
exchange_type="fanout" #fanout: 所有bind到此exchange的queue都可以接收消息
)
msg="hello man 1234"
channel.basic_publish(exchange="logs",
routing_key="", #消息队列名
body=msg,
# properties=pika.BasicProperties(
# delivery_mode=2 #让消息持久化(即使rabbitmq宕机之后仍让存在)
# )
)
print("send data:{}".format(msg))
connection.close()
receive端:首先要从转发器接受,然后随机生成一个queue在把数据传输到receive端。
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pika,time
connection=pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel() #设置管道
channel.exchange_declare(exchange="logs", #从"logs"转发器接收
exchange_type="fanout" #fanout: 所有bind到此exchange的queue都可以接收消息
)
res=channel.queue_declare(exclusive=True) #exclusive 独有的 不指定queue名,rabbit会随机分配一个queue名,exclusive=True会在使用该queue的消费者断开后,自动将该queue名删除
queue_name=res.method.queue
channel.queue_bind(exchange="logs",queue=queue_name)
def callback(ch,method,properties,body):
#print(ch,method,properties)
#time.sleep(2)
print("received data:",body)
#ch.basic_ack(delivery_tag=method.delivery_tag) #消费者手动确认消息已收到RabbitMQ可以自由删除它,
channel.basic_consume(callback, #收到消息就调用callback函数处理
queue=queue_name,
no_ack=True #= no acknownlege
)
print("waiting recv data....")
channel.start_consuming()
②direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
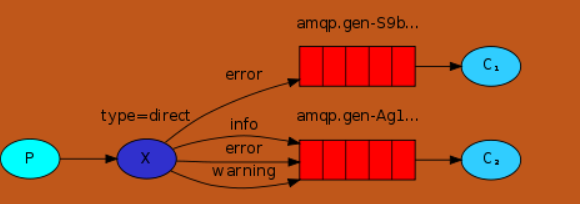
send端:把指令发送到转接器即可
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pika,sys
#fanout producer 和consumer 都是实时通讯
connection=pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel() #设置管道
channel.exchange_declare(exchange="direct_logs", #设置转发器
exchange_type="direct" #fanout: 所有bind到此exchange的queue都可以接收消息
)
severity=sys.argv[1] if len(sys.argv) >1 else "info"
msg="".join(sys.argv[2:]) or "hello!"
channel.basic_publish(exchange="direct_logs",
routing_key=severity, #消息队列名
body=msg,
# properties=pika.BasicProperties(
# delivery_mode=2 #让消息持久化(即使rabbitmq宕机之后仍让存在)
# )
) #要发送的消息
print("send data:{}".format(msg))
connection.close()
receive端:从转接器接受指令并发出指令所对应的queue,实现指定接收端接收消息
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pika,time,sys
connection=pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel() #设置管道
channel.exchange_declare(exchange="direct_logs", #从"logs"转发器接收
exchange_type="direct" #fanout: 所有bind到此exchange的queue都可以接收消息
)
res=channel.queue_declare(exclusive=True) #exclusive 独有的 不指定queue名,rabbit会随机分配一个queue名,exclusive=True会在使用该queue的消费者断开后,自动将该queue名删除
queue_name=res.method.queue
severities=sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange="direct_logs",
queue=queue_name,
routing_key=severity)
def callback(ch,method,properties,body):
#print(ch,method,properties)
#time.sleep(2)
print("received data:",body)
#ch.basic_ack(delivery_tag=method.delivery_tag) #消费者手动确认消息已收到RabbitMQ可以自由删除它,
#channel.basic_qos(prefetch_count=1) #只能处理一条消息 接收处理完再接收 perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
channel.basic_consume(callback, #收到消息就调用callback函数处理
queue=queue_name,
no_ack=True #= no acknownlege
)
print("waiting recv data....")
channel.start_consuming()
程序实现:send端指定info的queue收消息,接收端接收


③topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息(更为细分的消息过滤)
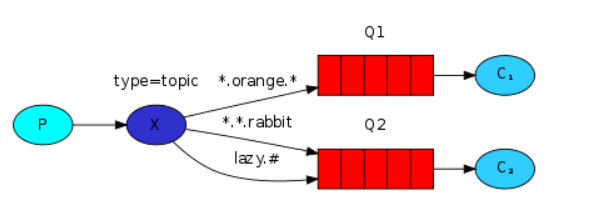
send发送text.txt类型 receive端接收*.text类型的数据
send端:
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pika,sys
#fanout producer 和consumer 都是实时通讯
connection=pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel() #设置管道
channel.exchange_declare(exchange="topic_logs", #设置转发器
exchange_type="topic" #fanout: 所有bind到此exchange的queue都可以接收消息
)
routing_key=sys.argv[1] if len(sys.argv) >1 else "anonymous.info"
msg="".join(sys.argv[2:]) or "hello!"
channel.basic_publish(exchange="topic",
routing_key=routing_key, #消息队列名
body=msg,
# properties=pika.BasicProperties(
# delivery_mode=2 #让消息持久化(即使rabbitmq宕机之后仍让存在)
# )
) #要发送的消息
print("send data:{}".format(msg))
connection.close()
receive端:
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pika,time,sys
connection=pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel() #设置管道
channel.exchange_declare(exchange="topic_logs", #从"logs"转发器接收
exchange_type="topic" #fanout: 所有bind到此exchange的queue都可以接收消息
)
res=channel.queue_declare(exclusive=True) #exclusive 独有的 不指定queue名,rabbit会随机分配一个queue名,exclusive=True会在使用该queue的消费者断开后,自动将该queue名删除
queue_name=res.method.queue
severities=sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [severities]...\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange="topic_logs",
queue=queue_name,
routing_key=severity)
def callback(ch,method,properties,body):
#print(ch,method,properties)
#time.sleep(2)
print("received data:",body)
#ch.basic_ack(delivery_tag=method.delivery_tag) #消费者手动确认消息已收到RabbitMQ可以自由删除它,
#channel.basic_qos(prefetch_count=1) #只能处理一条消息 接收处理完再接收 perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
channel.basic_consume(callback, #收到消息就调用callback函数处理
queue=queue_name,
no_ack=True #= no acknownlege
)
print("waiting recv data....")
channel.start_consuming()
Redis
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis优点
-
异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
-
支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。 -
操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
-
MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
安装Redis环境
$sudo apt-get update $sudo apt-get install redis-server
启动 Redis
$redis-server
查看 redis 是否还在运行
$redis-cli
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> ping PONG
连接方式
1:实例化一个Redis并连接主机,127.0.0.1 是本机的IP地址,6379是 Redis 服务器运行的端口。
#!_*_coding:utf-8_*_
#__author__:"shikai"
import redis
#实现一次性的连接操作
r=redis.Redis(host="127.0.0.1", port=6379)
r.set("name","shikai") #往Redis中扔消息
print(r.get("name")) #获取
2:连接池
connection pool管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
#!_*_coding:utf-8_*_
#__author__:"shikai"
import redis
#连接池
pool=redis.ConnectionPool(host="127.0.0.1", port=6379)
r=redis.Redis(connection_pool=pool)
r.set("name","shikai") #往Redis中扔消息
print(r.get("name")) #获取
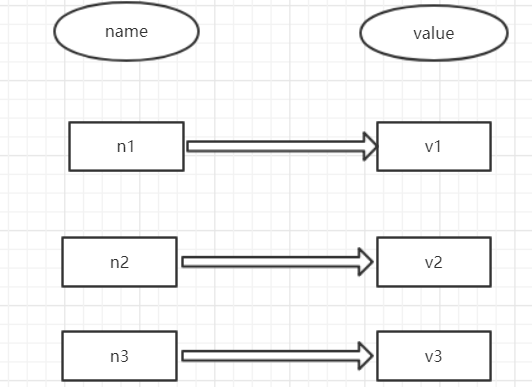
<1>string操作
redis中的String在在内存中按照一个name对应一个value来存储。如图:
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
#r.set("name","shikai")
#r.set("name","shikai",ex=5) #过期5秒
setnx(name, value)
创建值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 创建值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
批量设置值
如:
mset(name="shikai",age="10")
或
mget({'name': 'kkk', 'age': '10'})
mget(keys, *args)
批量获取
如:
r.mget("name","age")
getset(name, value)
设置新值并获取原来的值
#r.getset("name","kkkshikai")
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如: "阿凯" ,0-3表示 "阿"
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
# r.setrange("name",3,1234) #修改字符串内容,从指定字符串索引开始向后替换
setbit(name, offset, value)
# 先把name的值转换成ASSIC值,然后在转换成二进制值,然后在进行替换操作生成新值
# 参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0(将offset换成value值)
getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号