Python 开发面试梳理
整体知识框架
后端工程师的整理工作流程以一次web请求为例
这期间的每个流程需要进行掌握其中涉及的知识点以及相关技术栈

- 浏览器这里的前端相关
- 负载均衡一般有哪些方式, 比如 nginx 之类的,
- web 框架可以选的 django 或者 flask
- 业务逻辑相关的具体实现涉及到编程范式, 设计模式等
- 数据库相关sql或者nosql, 缓存的 redis 之类
技术栈大纲
▓ Python 预言基础 - 语言特点 / 语法基础 / 高级特性
▓ Python函数常考 / 参数传递 / 不可变对象 / 可变参数
▓ 算法和数据结构 - 时间空间复杂度 / 实现常见的数据结构和算法
▓ 编程范式 - 面向对象编程 / 常用设计模式 / 函数式编程
▓ 操作系统 - 常用的 Linux 命令 / 进程 / 线程 / 内存管理
▓ 网络编程 - 常用协议 TCP, IP, HTTP / Socket 编程基础 / Python 并发库
▓ 数据库 - Mysql 索引优化 / 关系型和NoSQL 的使用场景
▓ Web 框架 - 常见的框架对比 / RESTful / WSGI 原理 / Web 安全问题
▓ 系统设计 - 设计原则, 如何分析 / 后端常用的组件 (缓存, 数据库, 消息队列) / 技术选型和实现 (短网址服务 , Feed 流系统)
▓ 软实力 - 学习能力 / 业务理解能力 / 沟通交流能力 / 心态
python 基础问题
python 是静态还是动态 , 强类型还是弱类型
动态强类型
ps:
动态 or 静态 ? 编译期还是运行期间确定类型
强类型指不会发生隐式类型转换
python 作为后端预言的优缺点
优点 : 胶水预言, 轮子多, 应用广泛 ,预言灵活, 生产力高
缺点 : 性能问题, 代码维护问题, python 2 / 3 兼容问题
什么是鸭子类型

关注点在对象的行为, 而不是类型
比如 file, StringIO, socket 对象都支持 read / wirte 方法
再比如定义了 __iter__ 魔术方法的对象可以用 for 迭代
什么是 monkey patch, 哪里用到了, 如何自己实现
所谓猴子补丁就是运行时的替换, 比如 gevent 库需要修改内置的 socket
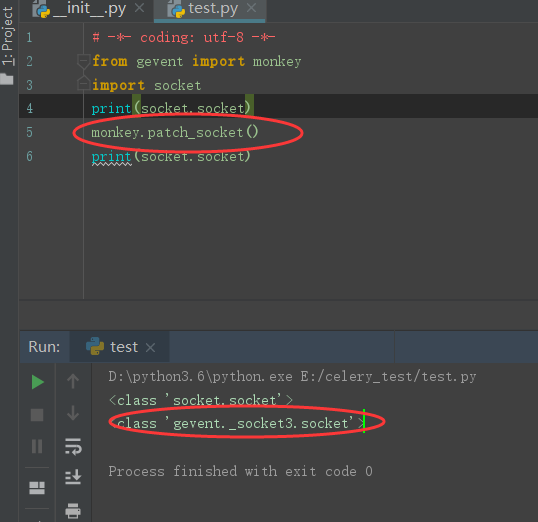
简单的实现样例
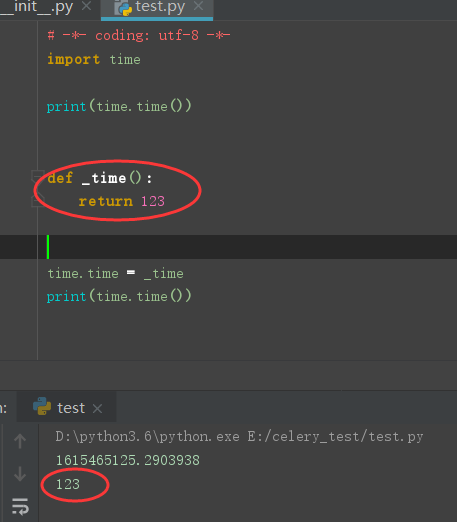
什么是自省
Introspection
运行时判断一个对象的类型的能力
python 一切皆对象, 用 type, id, isinstance 获取对象的信息
Inspect 模块提供了更多获取对象信息的函数
ps:
id 获取其内存地址
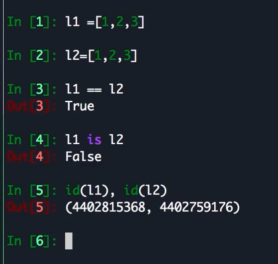
"is" 和 "==" 的区别?
is 相当于调用 id 判断两个的内存地址是否一样
== 则是判断值是否一致
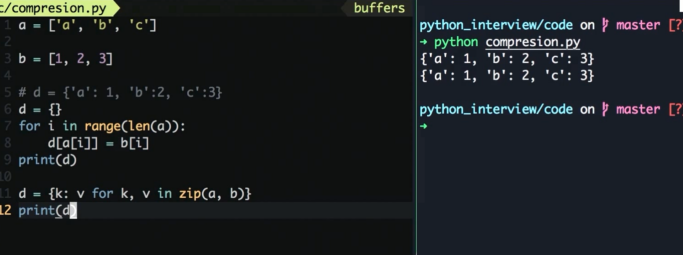
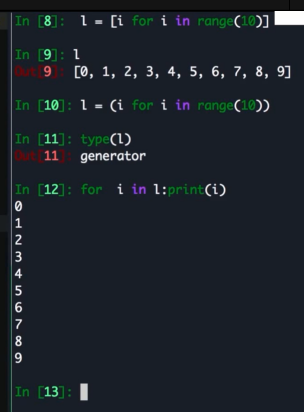
什么是列表和字段推导 (语法糖)
比如

一种快速生成 list / dict / set 的方式, 用来代替 map 或者 filter 等
ps:
换成 () 也可以返回生成器, 从而节省内存
什么是深拷贝, 什么是浅拷贝
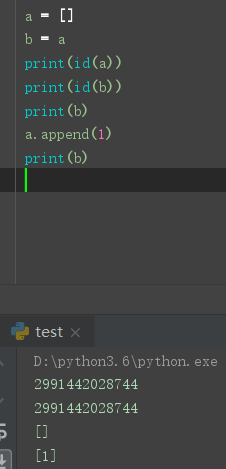

浅拷贝共享地址, 比如引用
深拷贝不同享内存地址, 彼此独立. 互不影响

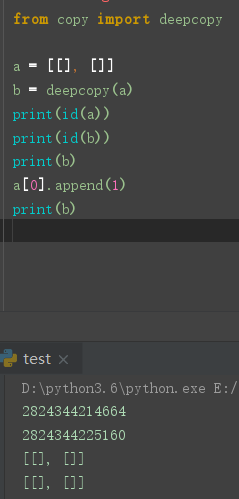
尽管深拷贝已经独立出来, 但是只能独立一层, 对于多层的可变对象的内部依旧是引用
可以使用 deepcopy 进行解决
ps:
如何正确初始化一个 3 * 3 的二维数组
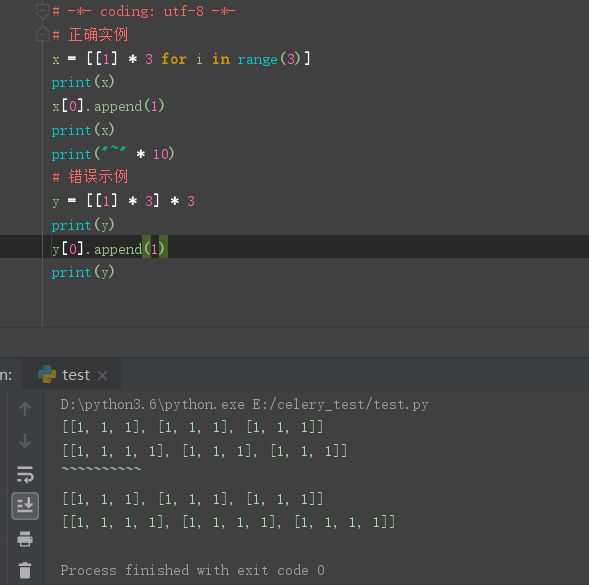 \
\
什么是python 之禅
终端内 进行 this 的导入即可看到

Python 2/3 的区别
print 成为函数
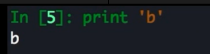
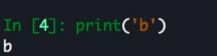
ps:
py3 的 print 函数可以支持多个参数比 py2 的要更灵活的去控制

字符编码
Py3 不在有 Unicode 对象, 默认的 str 就是 Unicode
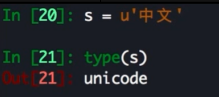
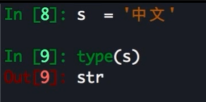
除法变化
Py3 返回的是浮点数, Py2 会直接截断, 返回整数

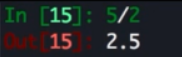
ps:
想要 在py3 中实现 py2 的效果可以使用 //
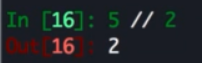
Python 3 的改进
类型注解
type , hint 帮助 IDE 实现类型检查

类型注解只能进行提示无法做到校验
但是可以配合类似 mypy 之类的包进行真正的校验
优化 super()
方便直接调用父类函数

py2 中需要传入参数 自己的类名以及self, 但是py3 中就不需要传入参数了
会方便很多, 是语法糖的一个简化操作
高级解包操作
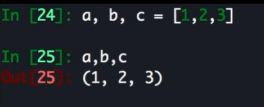
常规操作在23中都可以进行
但是 py3 中有了更强的操作

可以用 * 带进行类似 *args 这样的操作进行便携获取
限定关键字参数
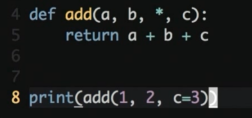
存在多个不定参数的时候, 不想让顺序搞乱
可以使用关键字参数跳过顺序进行传参
关键字参数具备高于顺序位置传参的优先级
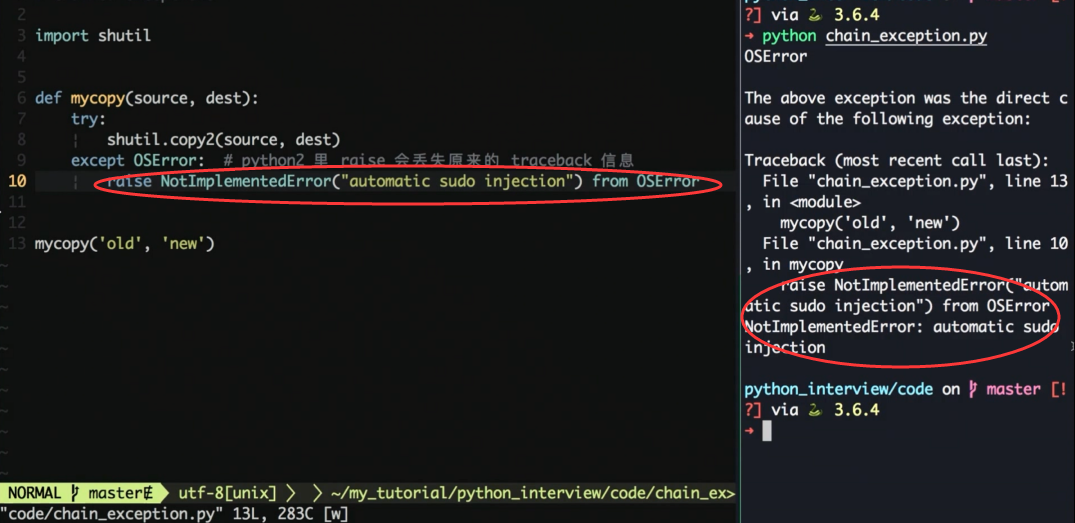
重新抛出异常不会丢失栈信息
py2 中如果在异常中再次抛出异常, 则之前的异常就会丢失
py3 中支持 raise from 保留之前异常, 这样有利于去排错
一切返回迭代器
py2 中很多内置函数返回的就是实打实的列表 (range, zip, map. dict.values, etc,are all)
![]()
如果数量比较大就比较麻烦, 但是 py3 返回的都是迭代器
因为是懒加载. 所以你不用他就不会生成列表去占用内存

这个问题在 py 的解决方式是用 xrange
因此这个问题在 py3 中不会出现之后. xrange 在 py3 中也被删除
如果需要变成列表则需要 list 强转一下
生成的pyc 文件统一放在 __pychche__ 中
一些内置库的修改
urlib , selector 等
性能优化等
Python3 新增
yield from
连接子生成器
asyncio 内置库
async / await 原生协程支持异步编程
新的内置库
enum, mock, asynic, ipaddress, concurrent.futures 等
Python 2 / 3 工具
- six 模块
- 2to3 等工具
- __future__
Python函数常考 / 参数传递 / 不可变对象 / 可变参数
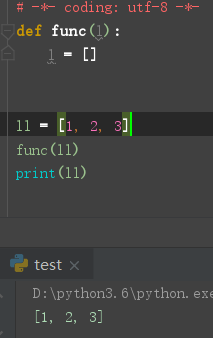
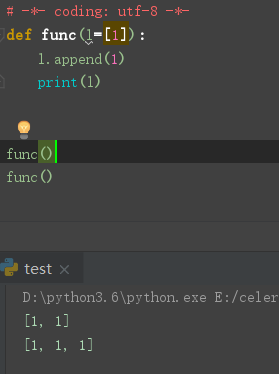
可变参数作为参数 , 不可变参数作为参数的区别

Python 如何传递参数
python 传参并非 值传递 or 引用, 唯一支持的是 共享传参 (Call by Object / Call by sharing)
函数形参获得实参中各个引用的副本

可变的对象直接在原来的基础上进行修改

不可变无法修改, 只能重新创建新的进行修改
ps:

ps:
类似题
Python 可变参数作为默认参数
默认参数只会计算一次
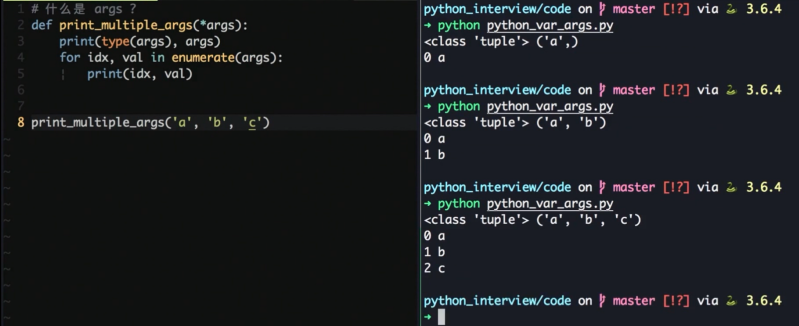
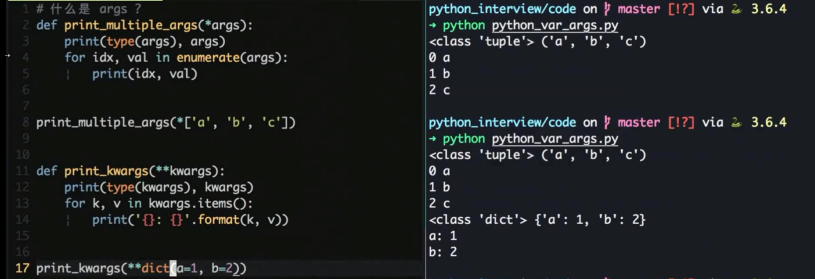
Python *args, **kwargs
用来处理可变参数
*args 会打包成 tuple
*kargs 会打包成 dict
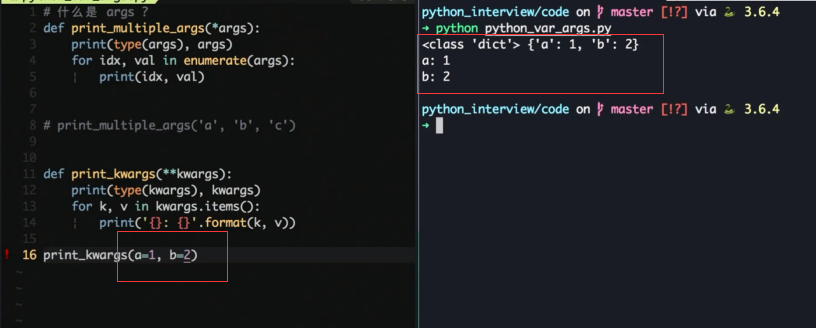
混用
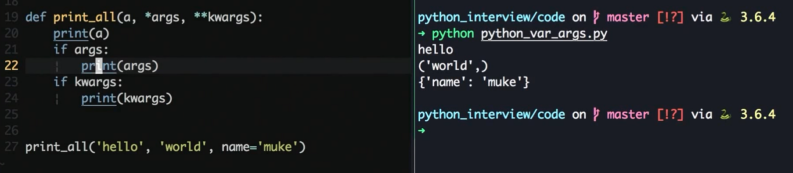
配合解包传参
Python 异常机制常考题

- BaseException 所有的异常都继承此异常
- SystemExit / KeyboardInterrupt / GeneratorExit 控制系统相关的异常
- Esception 其他的常见异常都继承此异常
使用异常的常见场景
- 网络请求, 超时, 连接错误
- 资源访问, 权限, 资源不存在
- 代码逻辑, 越界访问, KeyError 等
如何处理异常

如何自定义异常
继承 Exception 实现自定义异常, 并且加上一些附加信息, 用来处理一些业务相关的特定异常 (rause MyException)

ps :
如果使用 BaseException 的话结束程序都是个问题, 因为控制 Ctrl + c 的 KeyboardInterrupt 异常也被捕获
从而导致无法结束程序
Python 性能分析与优化, GIL 常考题
什么是 ,Cpytjon GIL
- Global Interpreter Lock
- Cpython 解释器的内存管理不是线程安全的
- 为了保护多线程下对 Python对象 的安全访问
- Cpython 使用简单的锁机制避免多线程直接执行
GIL 的影响
- 限制了程序的多核执行
- 同一个时间只能有一个线程执行字节码
- CPU 密集程序难以利用多核心优势
- IO 期间会释放GIL , 对于 IO 密集型程序影响不大
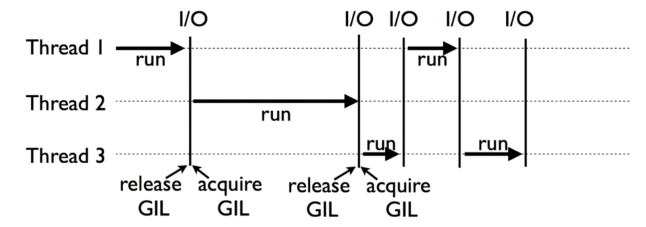
如何规避 CIL 的影响
- CPU密集可以使用多进程 + 进程池
- IO 密集使用多线程 / 协程
- cython 扩展
GIL 的实现

GIL 试题

预测一下输出情况, 按照道理来说执行 5k 次, 每次 + 2 结果应该是 10000

实际上多次执行可以看到偶尔会出现结果未保存就被覆盖的情况与预期不符
为什么有了GIL 还要关注线程安全
python 中的原子操作
- 一个字节码指令就可以完成的就是原子操作
- 原子操作是可以保证线程安全的
- 使用 dis 操作可以来分析字节码
dis 的使用


加锁解决线程安全问题
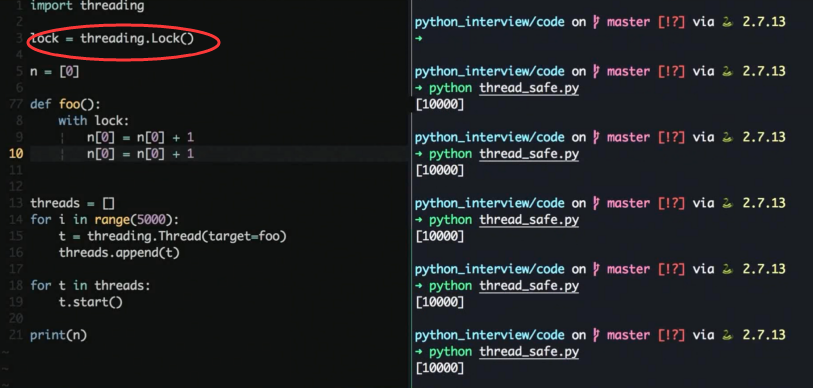
加锁会导致线程的性能下降, 但是保证了安全
如何剖析程序性能
使用各种 profile 工具 (内置或者第三方)
- 二八定律, 大部分时间都耗时在少量的代码上
- 内置的 profile / cprofile 等工具
- 使用 pyflame (uber开源) 的火焰图工具
服务端性能优化措施
- web 应用一般语言不会成为瓶颈
- 数据结构与算法优化
- 数据库层: 索引优化, 慢查询优化, 批量操作减少 IO, NoSQL
- 网络 IO: 批量操作, pipeline 操作减少IO
- 缓存: 使用内存数据库 redis / memcached
- 异步: asyncio / celery
- 并发: gevent / 多线程
Python 生成器 与 协程
Generator
- 生成器就是可以生成值的函数
- 当一个函数里有了 yield关键字就成了生成器
- 生成器可以挂起执行兵器保持当前执行的状态

基于生成器的协程
py3 之前是没有原生协程的
py2 是基于生成器来实现的协程
![]()

生成器可以通过 yield 暂停执行和产出数据
同时支持 send() 向生成器发送数据和 throw() 向生成器抛异常

协程注意点
协程需要使用 send(None) 或者 next(coroutine) 来预激才能启动
在 yield 处协程会暂停执行
单独的 yield value 会产出值给调用方
可以通过 coroutine.send(value) 来给协程发送值
发送的值会赋值给 yield 表达式左边的变量 value = yield
协程完成后(没有遇到下一个 yield语句) 会抛出 StopIteration 异常
协程装饰器

每次预激很麻烦, 装饰器在每次调用的时候先自动执行一个 next 方法从而进行预激
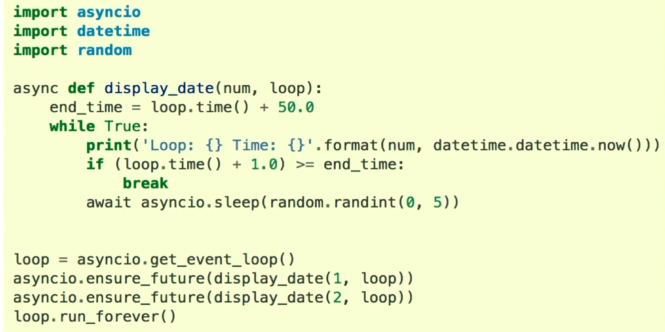
Python3 原生协程
在 3.5 版本的时候引入的 async / await 支持原生协程
Python 单元测试
针对程序模块进行正确性的验证, 一个函数, 一个类进行验证
保证代码逻辑的正确性
单测影响设计, 易测的代码往往是高内聚低耦合的
回归测试, 防止改一处导致整个服务不可用
单元测试相关库
nose/pytest 较为常用
mock 模块用来模拟替换网络请求
coverage 统计测试覆盖率
测试实例
安装
pip install pytest
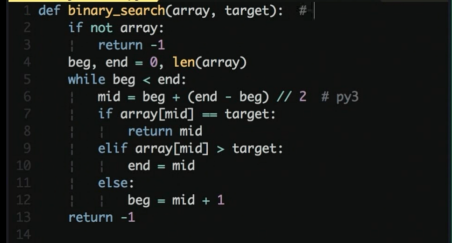
待测函数
一个二分查找, 找到值返回值的位置, 找不到返回 -1
测试用例编写

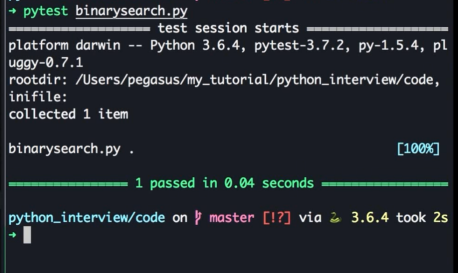
自动执行测试用例
pytest xxx.py
正确执行时
存在错误时
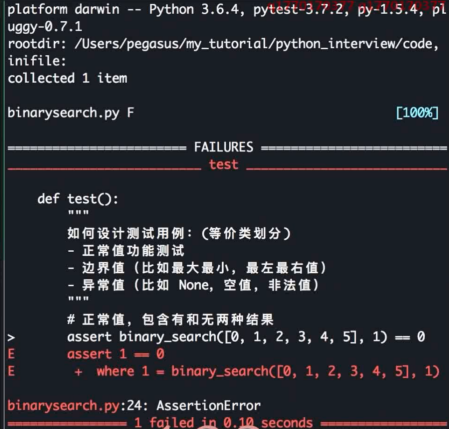
Python 内置的数据结构算法常考

collections 模块相关的数据结构扩展

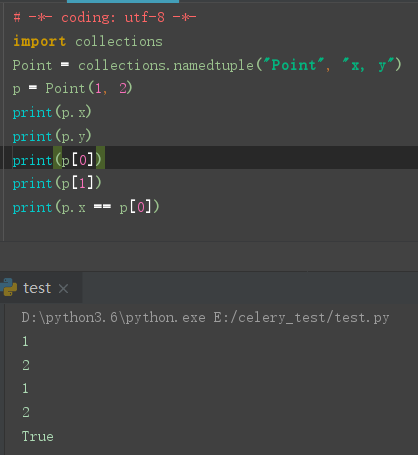
命名元祖 - 方便可读性
双端队列 - 方便前后存取
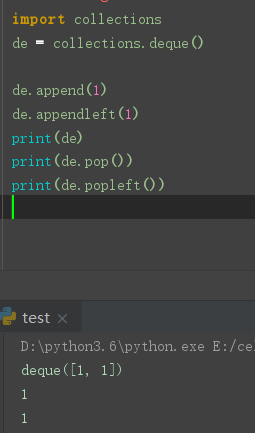
deque 可以很方便的实现 queue / stack
Counter - 计数器

OrderedDict - 有序字典
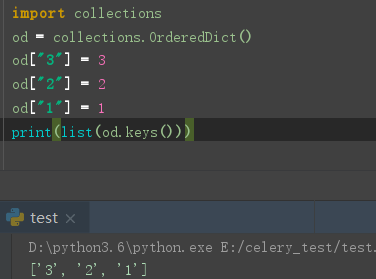
OrderedDict 的 key 顺序是第一次插入的顺序, 可以用来实现 LRUCache
DefaultDict - 默认字典
带默认值的字段

Pytnon dict 底层结构
dict 底层使用的是哈希表
哈希表的平均查找事件复杂度是 O(1)
CPython 解释器使用二次探查解决哈希冲突问题
常问的问题 哈希冲突和扩容
Python list / tuple 区别
都是线性结构, 支持下标访问
list 不能作为字典的 key, tuple 可以 (可变对象不可hash)
list 可变对象, tuple 保存的引用不可变

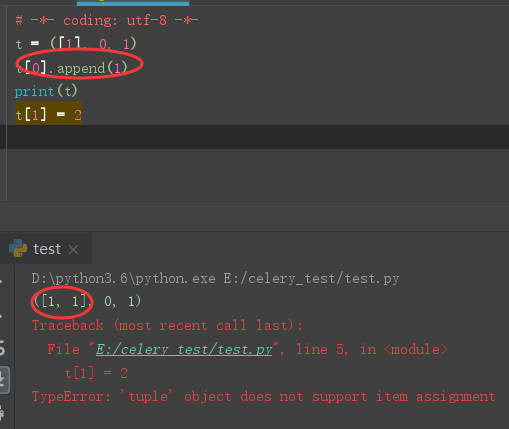
什么是 LRUCache
原理
Least-Recently-Used 替换掉最近最少使用的对象
缓存剔除策略, 当缓存空间不足的时候需要确定一种方式进行剔除key
常见的有 LRU , LFU 等
LRU 通过循环双端队列不断把最新访问的 key 放在表头实现

实现

# -*- coding: utf-8 -*- from collections import OrderedDict class LRUCache: def __init__(self, max_num=128): self.od = OrderedDict() self.max_num = max_num def get(self, k): # 每次访问更新使用的 key if k in self.od: v = self.od[k] # 放在最尾部 (最右边), 表示最新使用过 self.od.move_to_end(k) return v else: return -1 def put(self, k, v): # 更新 k/v if k in self.od: del self.od[k] self.od[k] = v # 更新 key 到表头 else: # 插入 self.od[k] = v # 判断容量 if len(self.od) > self.max_num: # 满了删除最早的 key (最没人用的) self.od.popitem(last=False)
数据结构常考题
常见的数据结构 链表, 队列, 栈, 二叉树, 堆
使用内置的数据结构实现高级的数据结构, 比如内置的 list / deque 实现栈
Leetcode 或者 剑指offer 上的常见题
链表
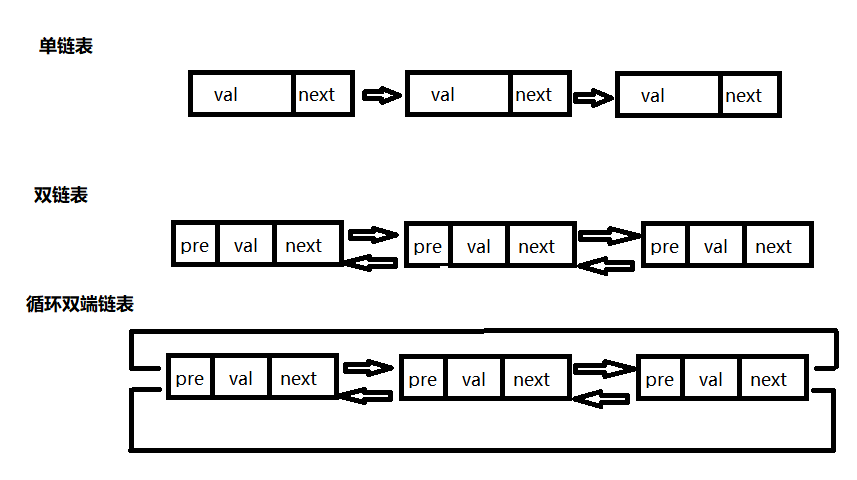
- 如何使用 Python 来表示链表结构
- 实现链表的常见操作, 比如插入节点, 反转链表, 合并多个链表等
- Leetcode 常见的链表题目
删除连表的节点

这道题要求的输入是被删除的节点而没有传入头结点, 因此按照正常来书
比如删除 5 我就找到 4 然后让 4 指向 要被删除的 5 的next 的1 就可以了
但是没有头结点只有 5 , 单链表没法往前找. 所以是没办法找到 4
换个角度想 知道 5 那 1 是 5 的 next, 9 是 5 的next 的next, 即 5 往后的节点都是拿得到
因此可以考虑直接让 5 换成 1 然后跳过 1, 直接指向 9, 这样形式上就相当于删除了 5
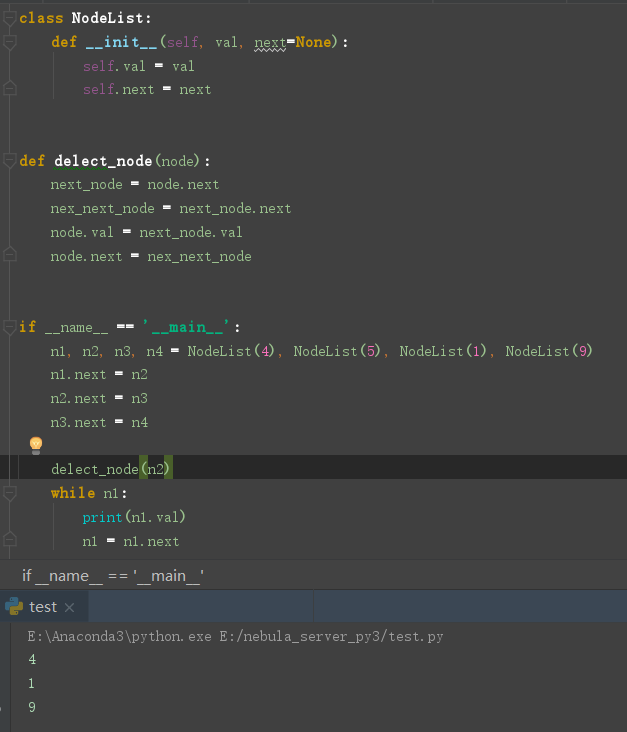
如何反转链表
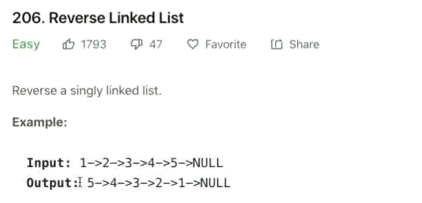
原理来说就是由 一个 cur 定义当前节点, 然后 pre 进行往前指向
第一个节点的指向为空, 依次往后移动
把操作节点的后节点保存, 然后后指向属性改成前指向
再将当前操作节点保存为下一个操作节点的前指向之后进行后一个节点的重复操作
终止条件是当前节点的后指向不存在时到达结尾结束
# -*- coding: utf-8 -*- class ListNode: def __init__(self, x): self.val = x self.next = None def reverse_list(head): # 定义一个前指向的属性 pre = None # 第一个进来让往前直到 None cur = head # cur 会从 1 -> 2 -> 3 -> 4 -> None 的顺序移动 while cur: nextnode = cur.next # 保存下来后指向的 next 值 cur.next = pre # 将 pre 覆盖 next pre = cur # 下一个的前指向为当前操作节点 cur = nextnode # 后移进行下一个的操作 return pre if __name__ == '__main__': # 1 - 2 - 3 - 4 ln = ListNode(1) ln.next = ListNode(2) ln.next.next = ListNode(3) ln.next.next.next = ListNode(4) ln = reverse_list(ln) print(ln.val, ln.next.val, ln.next.next.val, ln.next.next.next.val) # 4 3 2 1
合并两个有序列表
有两种方法可以实现, 一种是将 l1 插入到 l2 中
还有一种是创建一个 l3, 然后将 l1 l2 分别插入到 l3 中
以下为第二种方式, l1 和 l2 之间进行彼此比较从而决定谁来追加进入 l3, 每次被加入进去的指针往后移
同时 l3 每次追加后也要将指针后移, 最后将第一个节点之后的输出既可
# -*- coding: utf-8 -*- class ListNode: def __init__(self, x): self.val = x self.next = None def extend_list(l1, l2): if not l1 and not l2: return if not l1: return l2 if not l2: return l1 l3 = ListNode(0) # 头结点保存下来 l3_head_node = l3 while l1 and l2: if l1.val <= l2.val: l3.next = l1 l1 = l1.next # l1 后移 else: l3.next = l2 l2 = l2.next # l2 后移 l3 = l3.next # l3 后移 while l1 or l2: l3.next = l1 or l2 if l1: l1 = l1.next if l2: l2 = l2.next l3 = l3.next return l3_head_node.next if __name__ == '__main__': # 1 - 2 - 3 - 4 ln1 = ListNode(1) ln1.next = ListNode(2) ln1.next.next = ListNode(3) ln1.next.next.next = ListNode(4) # 2 - 3 - 4 - 5 ln2 = ListNode(2) ln2.next = ListNode(3) ln2.next.next = ListNode(4) ln2.next.next.next = ListNode(5) ret = extend_list(ln1, ln2) ln_list = [] while ret: ln_list.append(ret.val) ret = ret.next print(ln_list) # [1, 2, 2, 3, 3, 4, 4, 5]
队列
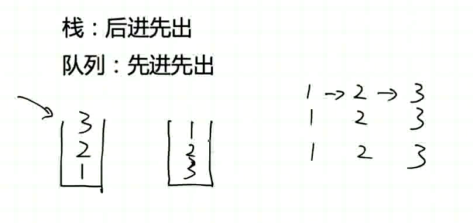
队列是先进先出的队列结构
如何使用 Python 实现队列
实现队列的 append 和 pop 操作, 如何做到先进先出
使用 Python 的 list 或者 collection.deque 实现队列
代码实现
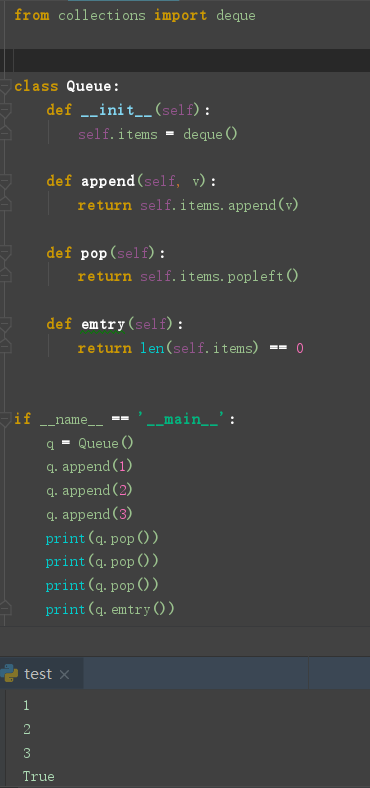
栈
栈 ( stack ) 是后进先出的结构
如何使用 Python 实现栈
实现栈的 push 和 pop 操作, 如何做到后进先出
同样可以用 Python list 或者 collection.deque 实现栈
代码实现
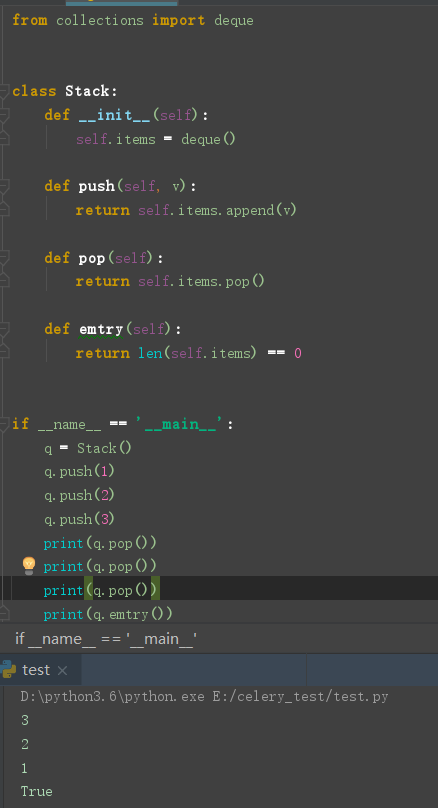
ps:
如何用两个栈实现一个队列?

from collections import deque
class Stack:
def __init__(self):
self.items = deque()
def push(self, v):
return self.items.append(v)
def pop(self):
return self.items.pop()
def len(self):
return len(self.items)
class Queue:
def __init__(self, q1, q2):
self.q1 = q1
self.q2 = q2
def append(self, v):
return self.q1.push(v)
def pop(self):
while self.q1.len():
self.q2.push(self.q1.pop())
return self.q2.pop()
if __name__ == '__main__':
q = Queue(Stack(), Stack())
q.append(1)
q.append(2)
q.append(3)
print(q.pop()) # 1
print(q.pop()) # 2
print(q.pop()) # 3
实现获取最小值的栈 MinStack
class MinStack(object):
def __init__(self):
self.stack = []
self.min_stack = []
def push(self, x):
self.stack.append(x)
if len(self.min_stack) == 0 or x <= self.min_stack[-1]:
self.min_stack.append(x)
def pop(self):
if not self.is_empty():
if self.stack.pop() == self.min_stack[-1]:
self.min_stack.pop()
return
def get_min(self):
if not self.is_empty():
return self.min_stack[-1]
def is_empty(self):
return len(self.stack) < 1
if __name__ == "__main__":
minstack = MinStack()
minstack.push(2)
minstack.push(0)
minstack.push(3)
minstack.push(0)
print(minstack.get_min())
minstack.pop()
print(minstack.get_min())
minstack.pop()
print(minstack.get_min())
minstack.pop()
print(minstack.get_min())
"""
0
0
0
2
"""
字典与集合
Python dict / set 底层都是哈希表
哈希表的实现原理, 底层就是一个数组
根据哈希函数快速定位一个元素, 平均查找 O(1) , 非常快
不断加入新的元素会引起哈希表重新开辟空间, 拷贝之前元素到新数组
哈希表如何解决冲突
元素 key 冲突之后使用一个链表填充相同 key 的元素 , 比如这里 5 冲突了. 就往外再次连接槽进行格外的存储
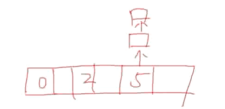 ( 正常一个元素只能存放一个元素, 存放链表既可填充多个冲突元素 )
( 正常一个元素只能存放一个元素, 存放链表既可填充多个冲突元素 )
开放寻址法是冲突之后根据某种方式 (二次探查) 寻找下一个可用的槽
( 二次是指使用的是一元二次方程进行计算 )
二叉树
二叉树很多操作都可以用递归非方式解决
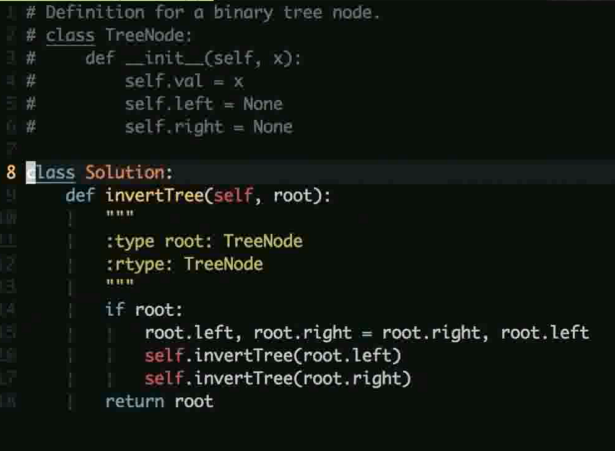
常考题: 二叉树的镜像, 层序遍历二叉树 (广度优先)
二叉树的镜像
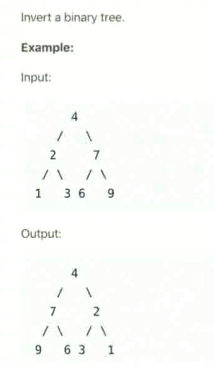
其实就是左右孩子的交换, 从根节点开始往下遍历
先序, 中序, 后序遍历的实现
- 先序: 先处理根, 之后左子树吗然后右子树
- 中序: 先处理左子树, 之后根, 然后右子树
- 后序: 先处理左子树, 然后右子树, 最后根
代码实现

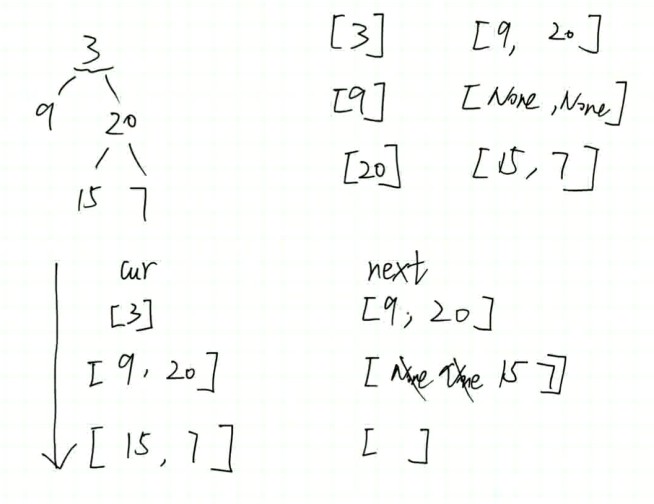
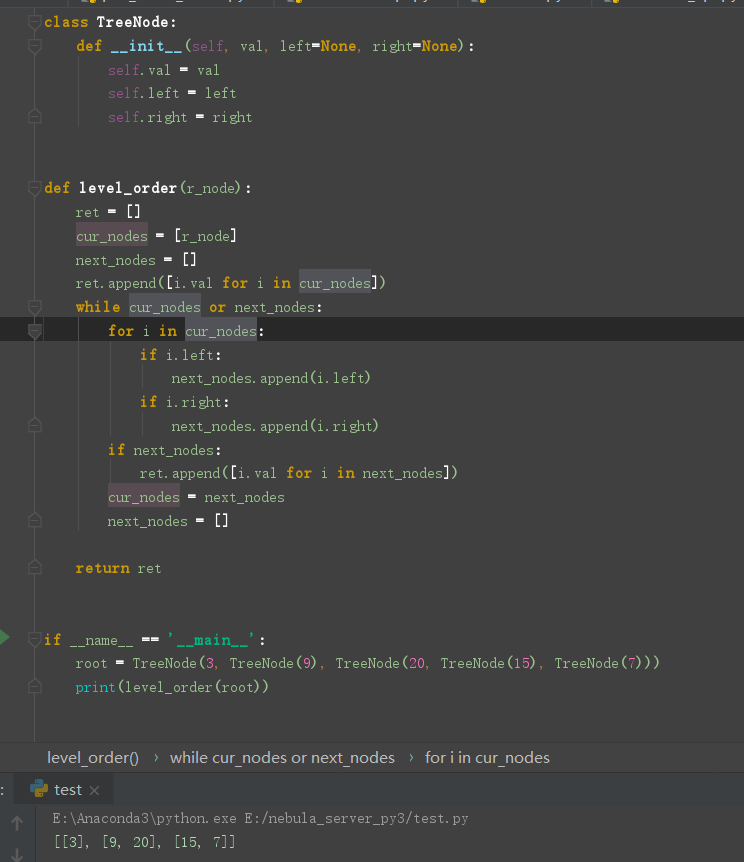
层序遍历二叉树 (广度优先)

定义两个 cur 当前层级节点 和 next 下一层节点 然后通过 移动 cur 来定义 next 再用 next 替换 cur 从而一层一层的往下延伸
结束条件 cur 或者 next 为空的时候就可以停止了, 表示当前没有节点或者当前层没有下一层节点了
堆
堆其实就是完全二叉树, 有最小堆和最大堆
- 最大堆: 对于每个非叶子节点V, V 的值都比他的两个孩子大
- 最小堆: 对于每个非叶子节点V, V 的值逗比他的两个孩子小
- 最大堆支持每次 pop 操作获取最大的元素, 最小堆获取最小元素 ( 堆顶 )
利用 堆来完成 topK 问题, 从海量数字中获取最大的 k 个元素
通常的场景是说有海量的数字, 但是很少的内存, 想要获取里面最大的10个元素
获取最大元素那就使用最小堆来处理, 取数据的前10个建立最小堆
然后遍历剩下的数字和堆顶进行比较, 如果小于堆顶那必然不是 top10
如果大于堆顶. 则调整堆纳入新数字作为堆顶重新调整堆
相关代码
import heapq class TopK: def __init__(self, items, k): self.min_hq = [] self.max_num = k self.items = items def push(self, v): if len(self.min_hq) >= self.max_num: min_v = self.min_hq[0] if v < min_v: pass else: heapq.heapreplace(self.min_hq, v) else: heapq.heappush(self.min_hq, v) def get_topk(self): for v in self.items: self.push(v) return self.min_hq if __name__ == '__main__': import random i = list(range(1000)) random.shuffle(i) _ = TopK(i, 10) print(_.get_topk()) # [990, 991, 992, 993, 994, 999, 995, 997, 996, 998]
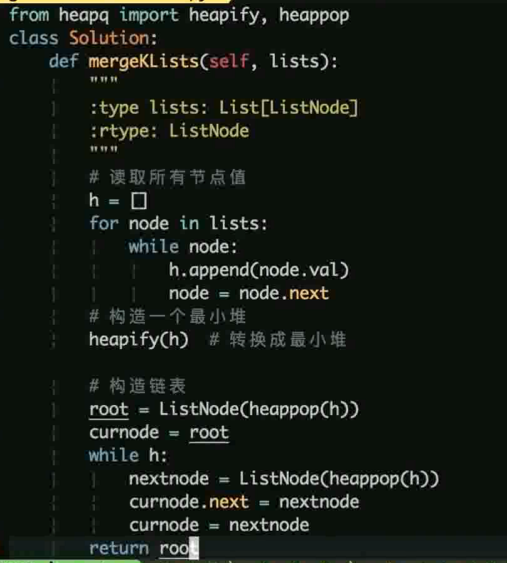
如何合并 k 个有序链表


输入的是一个列表, 里面存放的是每个序列的头结点
之前做过两个链表的合并, 这里当然也可以使用此方法, 两个链表合并之后再依次和后面的每个合并

但是这里使用堆会更加简单, 将所有的数据放进最小堆, 然后利用最小堆每次弹出堆顶在组成链表
即可实现一个从小到大排列的有序链表
利用 python 的 headq 就可以简单的实现
字符串
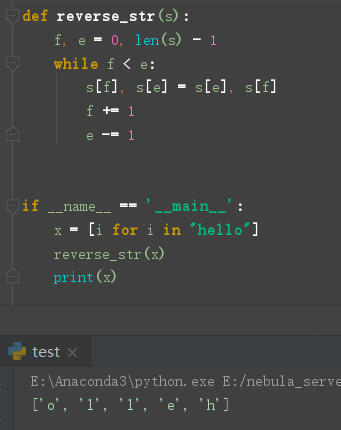
翻转一个字符串
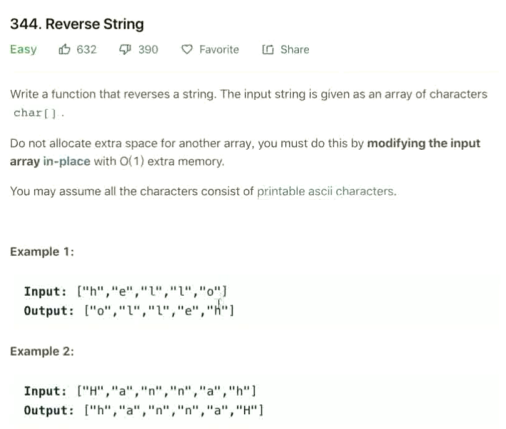
有个特殊要求, 不能使用额外的空间
输入的是 [""] , 这里使用 reversed 却无法修改这个数据本身, 做不到原地修改
当然 str 本身也有 reverse 方法而且是原地修改, 但是这样就没意思了
这里采用两个指针分别从两头彼此进行互换即可
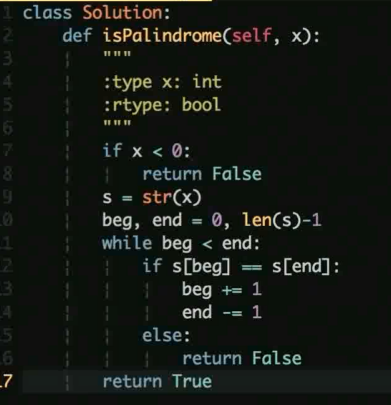
判断一个数字是否是回文数
首先负数肯定不会是回文数, 解题思路如上题类似, 也是双指针进行对比
判断是否一样即可, 不一样直接返回 False 即可
Python 面向对象相关考题
什么是面向对象编程
把对象作为基本单元, 把对象抽象成类 (Class), 包含成员和方法
数据封装, 继承, 多态
Python 中使用类来实现, 过程式编程( 函数 ), OPP (类)
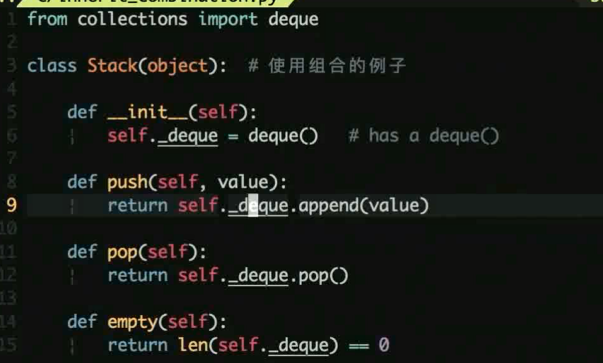
优先使用组合而非继承
组合是使用其他的类实例作为自己的一个属性 (Has-a 关系)
子类继承父类的属性和方法 (Is a 关系)
优先使用组合保持代码简单, 如下示例
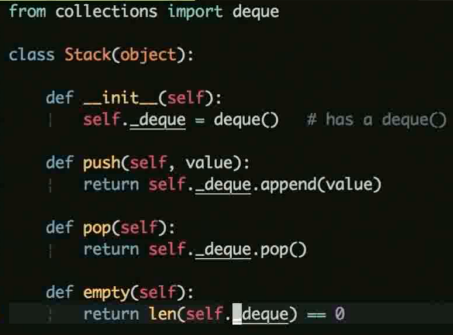
使用 deque 作为自己ide一个属性, 从而利用此属性的内部的方法进行操作
而非直接继承 deque 来使用 deque 的方法.
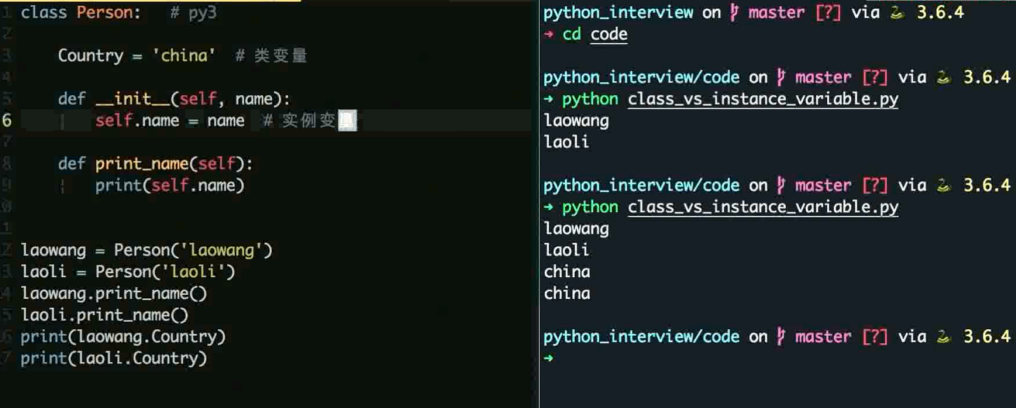
类变量和实例变量的区别
类变量由所有的实例共享 (类内的声明变量)
实例变量由实例单独享有, 不同实例之间不影响 (实例初始化声明的属性)
当我们需要在一个类的不同实例之间同享变量的时候可以使用类变量
classmethod / staticmethod 的区别
都可以使用 Class.method() 的方式使用
classmethod 第一个参数是 cls, 可以引用类变量
staticmethod 使用起来和普通的函数一样, 只不过放在类里面去组织
staticmethod 装饰的函数的第一个 self 参数可以忽略
就目的而言:
classmethod 是为了不实例化直接使用类变量
staticmethod 是为了组织美化代码强制面向对象
示例

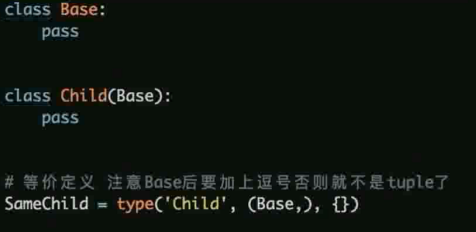
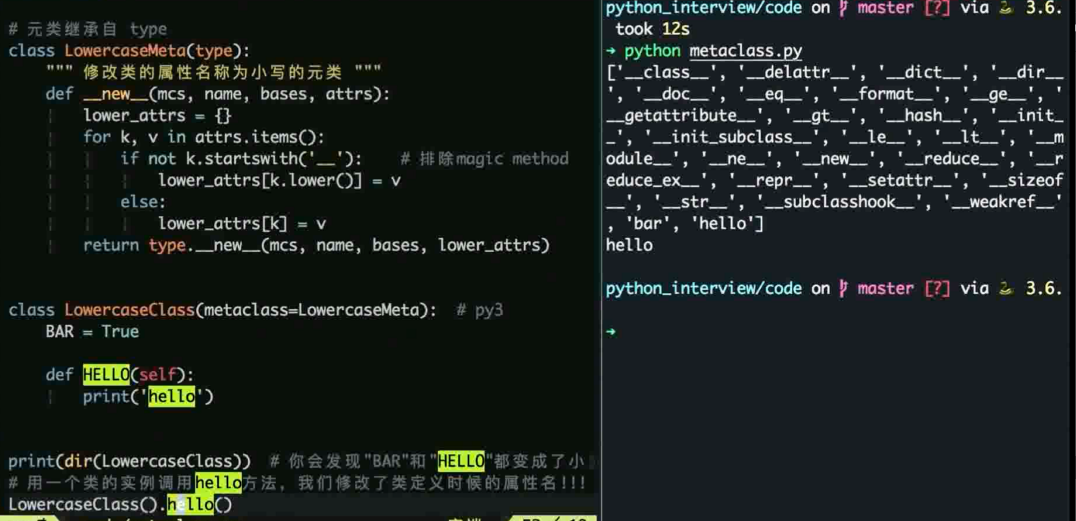
什么是元类, 使用场景
元类 (Meta Class) 是创建类的类
元类允许我们控制类的生成, 比如修改类的属性等
元类最常见的使用场景 ORM 框架
使用 type 来定义元类


带继承的示例
带方法的实例
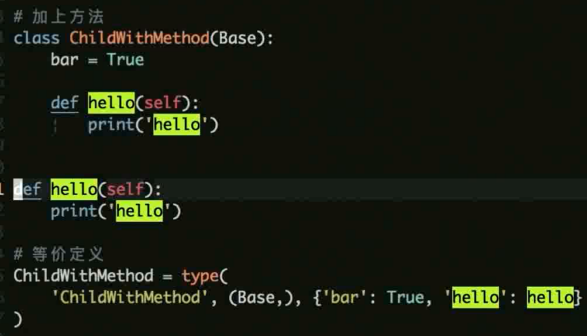
自我实现实例
Python 设计模式常考
设计模式分类
行为型, 创建型, 结构型 三大类
创建型
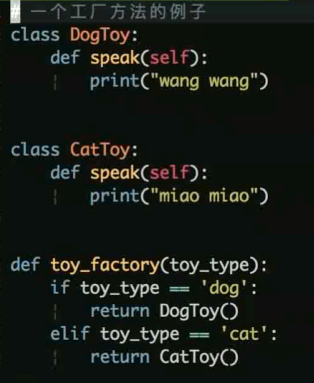
工厂模式: 解决对象创建问题
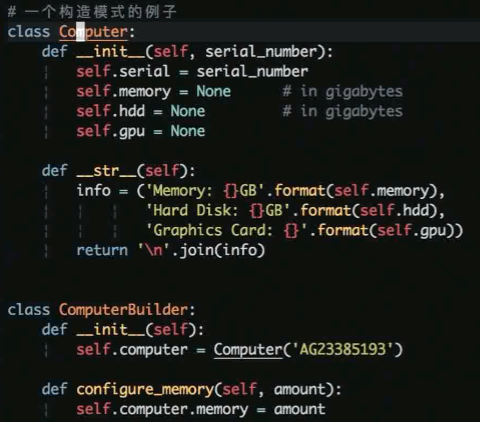
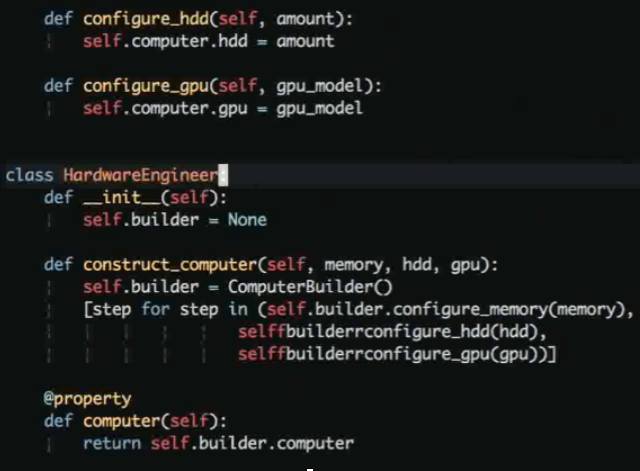
构造模式: 控制复杂对象的创建, 通常用于比较复杂的对象分布进行创建
原型模式: 通过原型的克隆创建新的实例, 对于一些创建实例开销较高的地方来使用
单例模式: 一个类只能创建同一个对象, 面试中较多问到, python的导入就是单例, 使用共享同一个实例的方式来创建
对象池模式: 预先分配同一类型的一组实例
惰性计算模式: 延迟计算 ( Python 的 property )
工厂模式 demo
构造模式 demo

单例模式 demo
# 单例模式 class SingLeton: def __new__(cls, *args, **kwargs): if not hasattr(cls, "_instance"): _instance = super().__new__(cls, *args, **kwargs) cls._instance = _instance return cls._instance class Myclass(SingLeton): pass if __name__ == '__main__': a = Myclass() b = Myclass() print(a is b) # True print(id(a), id(b)) # 2350011243712 2350011243712
结构型
装饰器模式: 无需子类化扩展对象功能
代理模式: 吧一个对象的操作代理到另一个对象,
适配器模式: 通过一个间接层适配统一接口
外观模式: 简化复杂对象的访问问题
享元模式: 通过对象复用(池) 改善资源利用, 比如连接池
MVC模式: 解耦展示逻辑和业务逻辑
适配器 demo
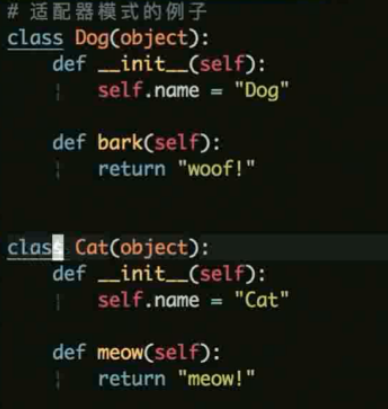
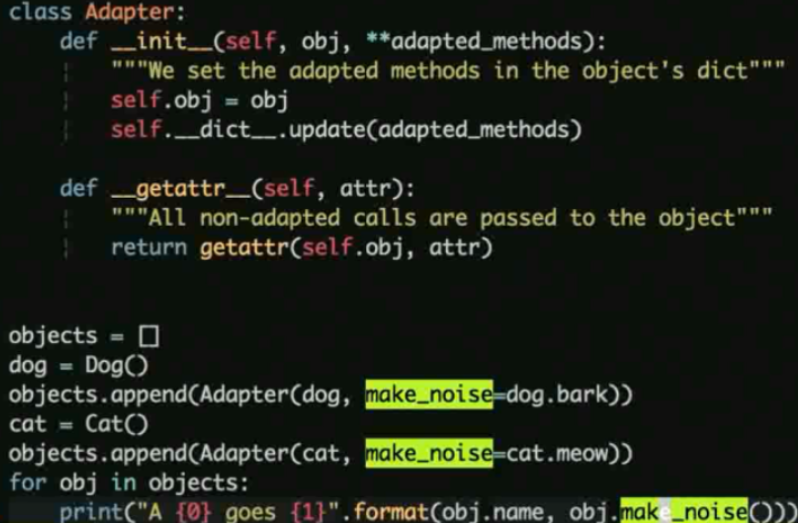
这里使用 make_noise 方法就可以统一的使用了不同类的不同方法了.
代理模式 demo
行为型
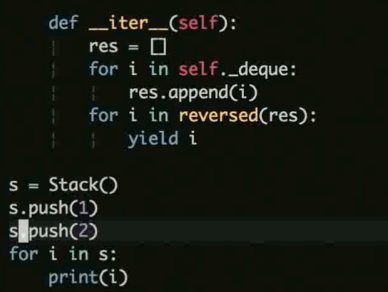
迭代器模式: 通过统一的接口迭代对象, python 内置迭代器 for 可以进行遍历, 可以用 __next__ , __iter__ 实现迭代器
观察者模式: 对象发生改变的时候, 观察者执行相应的动作, 比如发布订阅, 可以通过回调等方式实现
策略模式: 针对不同的规模的输入使用不同的策略, 一般可以用于打折优惠券之类的逻辑
迭代器 demo
观察者 demo
发布订阅系统

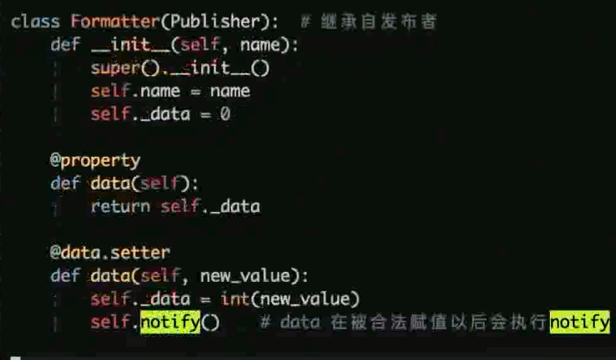

这里的 data 函数增加了 property 的装饰器, 而且增加了 setter 的操作以及在内部逻辑中 增加 self.notify()
从而每次被 set 更新 self._data 的时候进行触发. 触发每个观察者的 notify_by 方法
最终的打印结果

装饰器模式相关原理以及不同方法实现
什么是闭包
闭包: 引用了外部自由变量的函数
自由变量: 不在当前函数定义的变量
特性: 自由变量会和闭包函数同时存在
常见应用: 装饰器就是最常见的闭包
实例
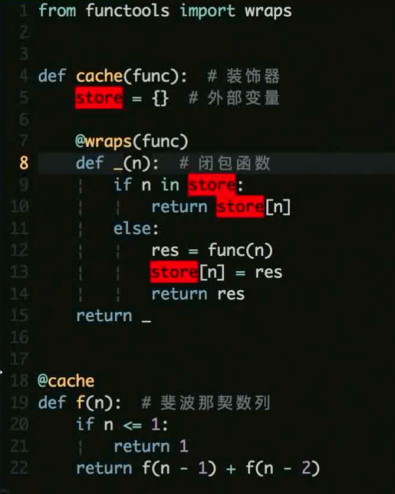
简单来说就是一个函数的内部函数使用了外部函数的变量就是闭包
而且外部函数哪怕结束了, 但是如果内部函数还在使用这个外部的变量
那这个变量就会一直存在
Decorator 定义
Python 中一切皆对象, 函数可以作为参数进行传递
装饰器是接受函数作为关键字, 添加功能后返回一个新函数的函数 (类)
Python 中通过 @ 使用装饰器
property 语法糖
class Dog: def __init__(self): self.__age = 13 def get_age(self): return self.__age def set_age(self, v): self.__age = v return @property def age(self): return self.__age @age.deleter def age(self): del self.__age @age.setter def age(self, v): self.__age = v if __name__ == '__main__': d = Dog() # 正常的获取方式 # print(d.__age) # 双下划线私有属性是无法直接访问会报错 print(d.get_age()) # 只能通过写一个方法来获取到, 正常方式获取 print(d.age) # 13 # 利用 property 装饰器可以更方便的获取 d.set_age(5) # 正常方式的赋值操作 d.age = 5 # age.setter 装饰器可以允许使用直接赋值操作 print(d.age) # 5 del d.age # age.deleter 装饰器可以允许使用直接赋值操作
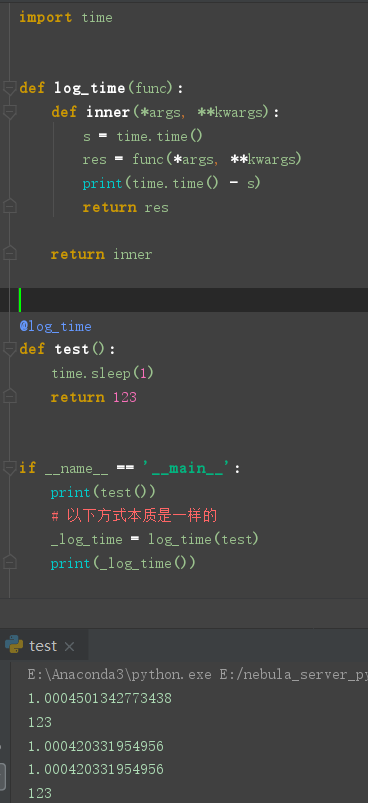
编写一个记录函数耗时的装饰器
函数方法实现
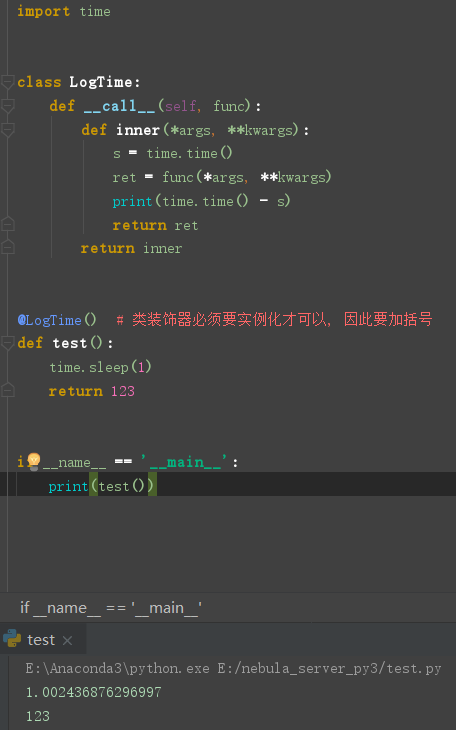
类方法实现
利用装饰器给函数加参数
使用类装饰器的方法可以很方便的添加装饰器的参数
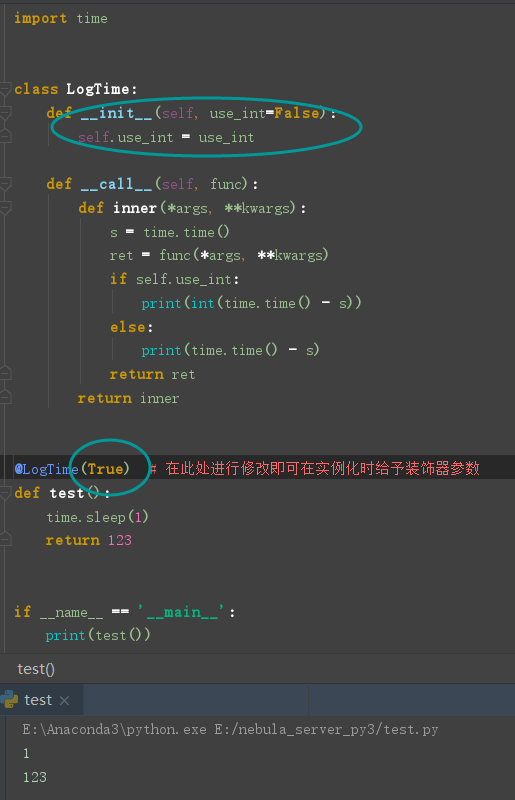
Python 函数式编程常考题
- lambda 演算
- 高阶函数 map, reduce, filter
- 函数是编程无副作用, 相同的参数调用始终产生同样的结果
map 的使用
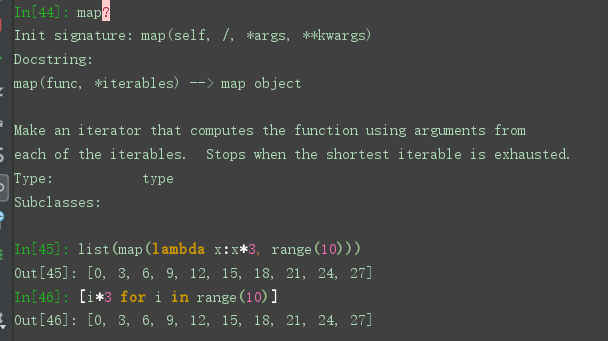
map 是将一个序列按照前一个方法中的逻辑进行统一处理
通常来说更推荐使用列表推导来实现, 但是map可以传入 远比lambda 更复杂的函数进行复杂运算
以此列表推导是实现不了的. 但是map 的用法更适用于函数式编程. 会影响代码可读性
reduce 的使用
python 2 中是自带的., 在 python 3 中需要导入

reduce 是将前面的结果往后继续操作, 比如这里的 0+1+2+3+4

filter 的使用

filter 则是进行了每个元素的判断是否进行保留
Linux 操作系统相关问题
- 熟练在 Linux 服务器上操作
- 了解 Linux 工作原理和常用工具
- 需要了解查看文件, 进程, 内存相关的一些命令, 用以调试和排查
如何知道一个命令的用法
man 命令查询用法, 但是 man 手册较为复杂
工具自带的 help 比如 pip -- help
man 的替代品 tldr pip install tldr 此工具较为简单且提供实例
文件 / 目录相关操作命令
chown / chmod / cdgrp
ls / rm / cd / cp / mv / rouch / rename / ln ( 软连接和硬链接) 等
locate / find / grep 定位查找和搜索
编辑器 vi / nano
cat / head / tail 查看文件
more / less 交互式查看文件
进程相关的命令
ps 查看进程
kill 杀死进程 常用 kill -9 进程号
top / htop 监控进程
内存操作相关工具命令
free 查看可用内存
了解每一列的具体含义
排查内存泄露问题
网络操作命令
ifconfig 查看网卡信息
lsof / netstat 查看端口信息
ssh / scp 远程登录 / 复制
tcpdump 抓包
常见用户和组操作
useradd / usermod
groupadd / groupmod
软连接和硬链接的区别
简单来说
软连接类似于 Windows 里面的快捷方式
原理来说
软链接是个文本文件, 里面保存了指向的绝对路径
软连接在访问的时候回替换为保存的路径进行指向
linux 里面的文件保存在磁盘上通过 Inode 值进行访问
所有的文件的访问都是通过各种连接到这个 Inode 值上的区块进行访问
硬链接是允许一个文件有多个链接到此区块, 即真实的访问
这样如果用户误删某一个链接时, 其他的链接依旧可以访问到此区块
而软连接如果源文件不在的话, 软链接将会无意义失效 ( Windows 也是一样)
进程和线程的区别
进程是运行程序的封装, 是操作系统的一种并行机制, 用于调度的基本单位
线程是进程的子任务, cpu 调度的基本单位, 实现是的进程内的并发
进程可以包含多个线程, 但是线程依赖进程的存在, 并共享进程的内存
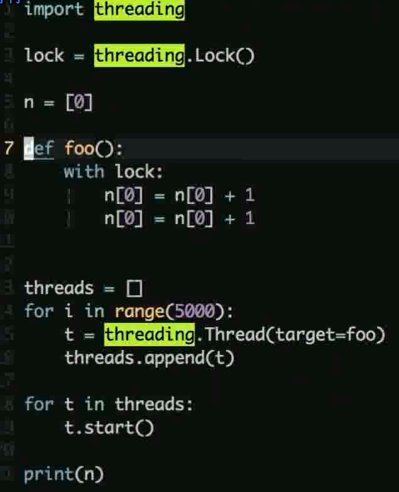
什么是线程安全
一个线程的修改被另一个线程的修改抢先或者覆盖的时候导致数据偏差
可以通过上锁的机制进行保护, 让同一份数据同时间内只能一个线程来访问
即顺序执行而非并发执行, 一般如果是读取数据的时候不需要考虑线程安全问题
写操作的时候则需要考虑
线程同步的方式
互斥量 (锁) : 利用互斥锁让防止多个线程同时访问公共资源
信号量 : 控制同一个时刻多个线程访问同一个资源的线程数
事件: 通过互相通知的方式保持多个线程同步
进程间通信方式
管道 / 匿名管道 / 有名管道
信号 : 比如 Ctrl + c 产生 SIGINT 程序终止信号
消息队列
共享内存
信号量
套接字 ( socket ): 最常见的方式, web 应用
Python 如何实现多线程

示例
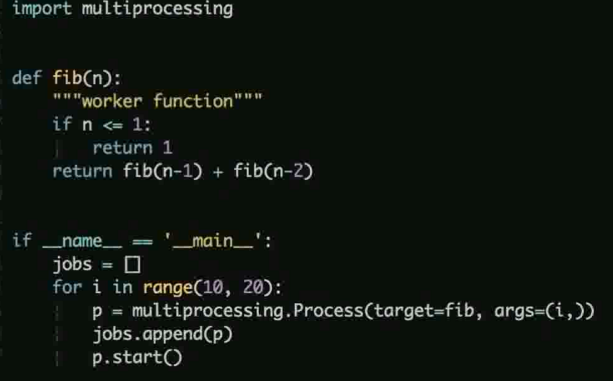
Python 如何实现多进程

示例
系统内存管理机制常见考题
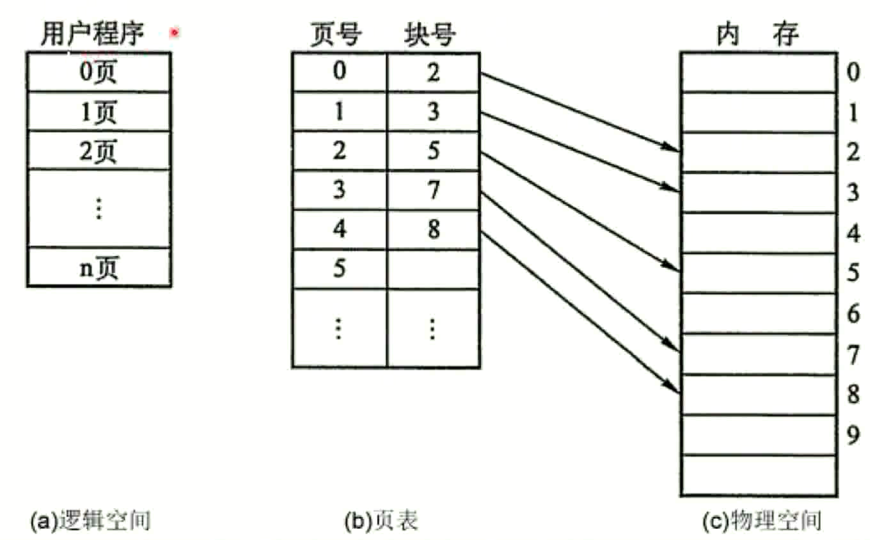
什么是分页机制
操作系统为了方便管理内存以及减少内存采用分页机制
逻辑地址与物理地址分离的内存分配管理方案
程序的逻辑地址划分为固定大小的页 (Page)
物理地址划分为同样大小的帧 (Frame)
通过页表对应逻辑地址和物理地址
什么是分段机制
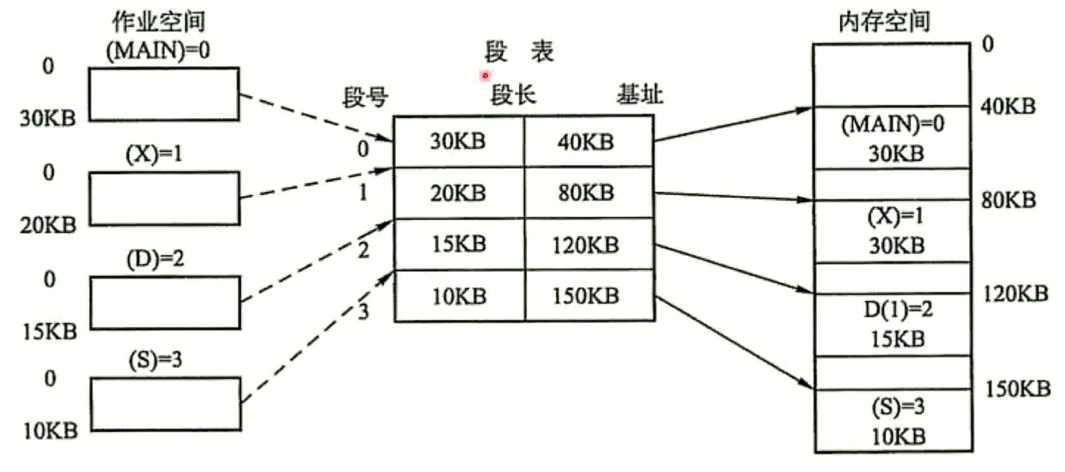
分段是为了满足代码的一些逻辑需求
数据共享, 数据保护, 动态链接等
通过段表实现逻辑地址和物理地址的映射关系
每个段内都是连续的内存分配, 段和段之间是离散的分配
分页和分段的区别
页是出于内存利用率的角度提出的离散的分配机制
段是处于用户的角度用于数据保护, 数据隔离等用途的管理机制
页的大小是固定的, 操作系统来决定, 段的大小不定, 由用户程序决定
什么是虚拟内存
通过把一部分暂时不用的内存信息放在硬盘上, 系统似乎提供比实际内存更大的容量, 称之为虚拟内存
局部性原理: 时间 / 空间局部性
一段内存被访问的时候, 不远的未来可能还会被访问
一段内存被访问的时候, 他周围的内存可能也会被访问
因此只将程序运行时候的只有部分必要的信息装入内存, 不必要的放在硬盘
什么是内存抖动 (颠簸)
本质是频繁的页调度行为导致进程不断产生缺页终端
通常是使用了不当的置换策略 , 常见的置换策略 (先入先出, LRU, LFU 等等)
刚刚置换了一个页, 有不断的在次需要这个页
运行程序太多, 页面替换策略不好, 终止进程或者增加物理内存等可以解决
Python 垃圾回收机制的原理
引用计数为主 (缺点: 循环引用无法解决)
引用标记清除和分代回收解决引用计数的问题 (为辅)
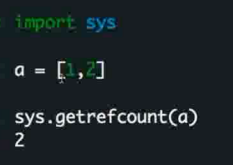
引用计数的示例
a = [1] a-> [1] [1] 的 ref 为 1
在创建 b = a a-> [1]<-b [1] 的 ref 为 2
b = None a-> [1] b->None [1] 的 ref 为 1
def a [1] 的 ref 为 0 此时 [1] 被回收, del 的原理就是清除掉 a 的引用
即 有多少个变量在引用这块内存, ref 为 0 的时候进行回收

可以通过 sys 的相关方法进行查看
当然这里也有一些误导
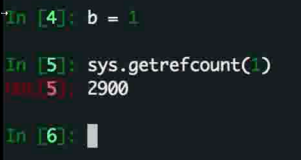
1 在未被 b 引用之前就已经被 python 的底层很多地方引用了
所以是这么大的数字
循环引用的问题
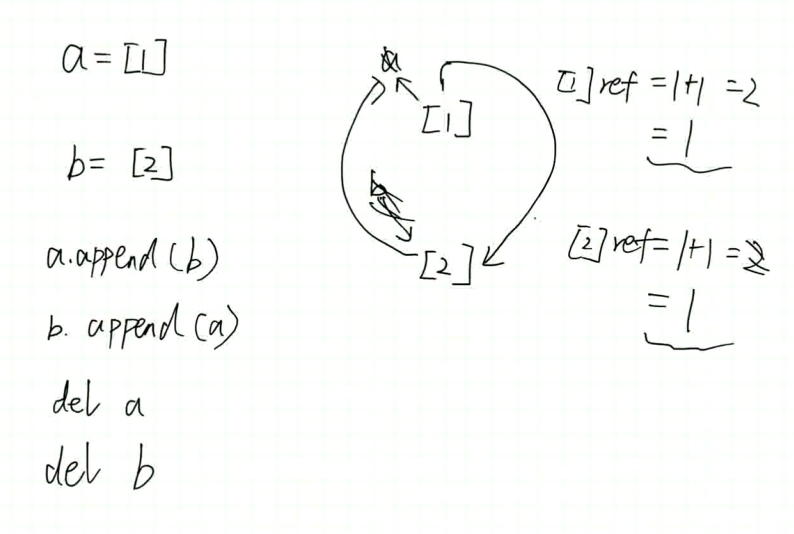
循环引用的时候会导致 被循环引用的对象的 ref 始终无法清0 从而无法被清理最终导致内存溢出
标记清除
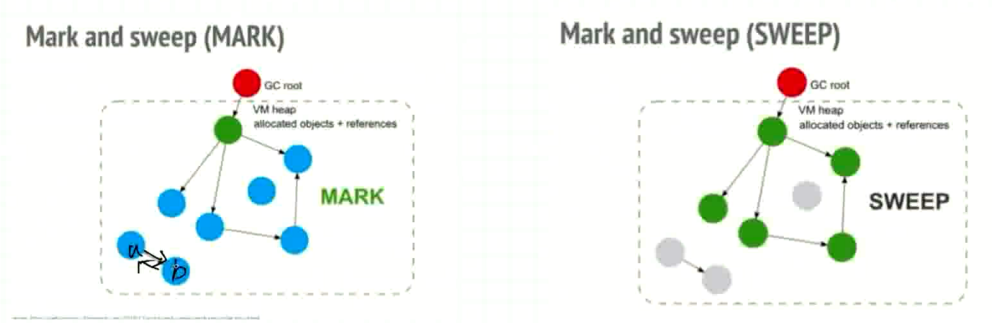
使用引用图的形式, 从根对象进行往下找, 只对可达对象进行保留
不可达对象进行清除, 根对象是值栈内的对象
分代回收
python 将所有的对象的生命周期氛围 0 , 1 , 2 三代
使用双端链表进行保存, 然后对每一代进行标记清除
比如 对第 0 代清除之后还存活的移入第 1 代, 以此类推
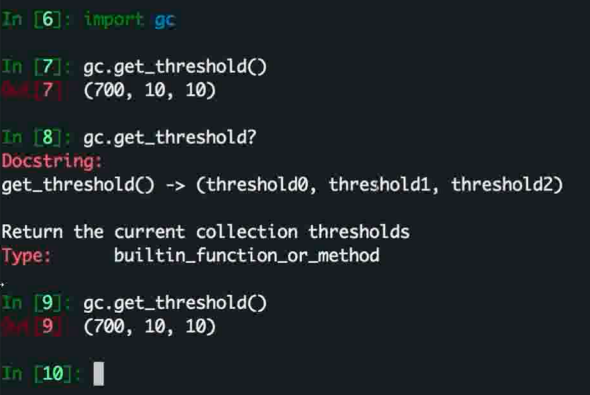
gc 模块中可以进行这方面的操作比如这里看到第0代保存在第700 的时候进行第0代的回收
网络协议相关
浏览器输入一个 url 中间经历的过程

- 中间都都涉及了哪些过程
- 包含了哪些网络协议
- 每个协议都干了什么
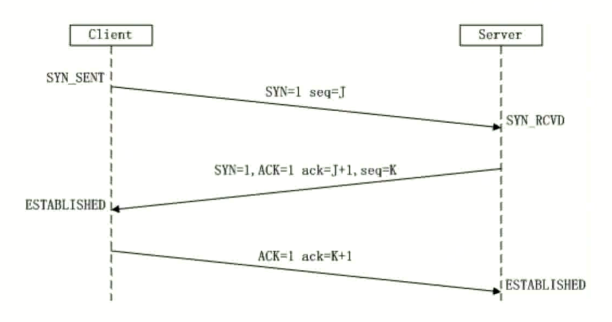
TCP / UDP 相关考题 - 三次 / 四次 / 区别 / 实现
TCP 的三次握手过程
TCP 的四次挥手过程
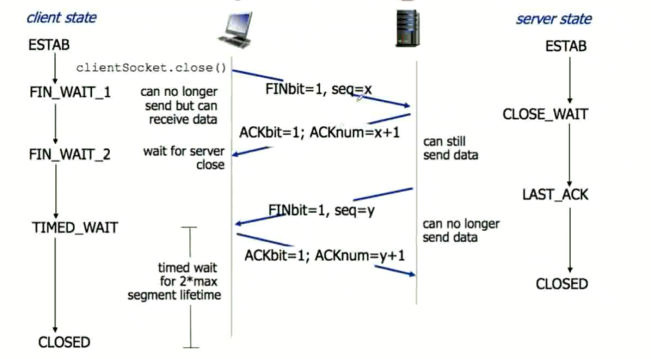
TCP 和 UDP 的区别

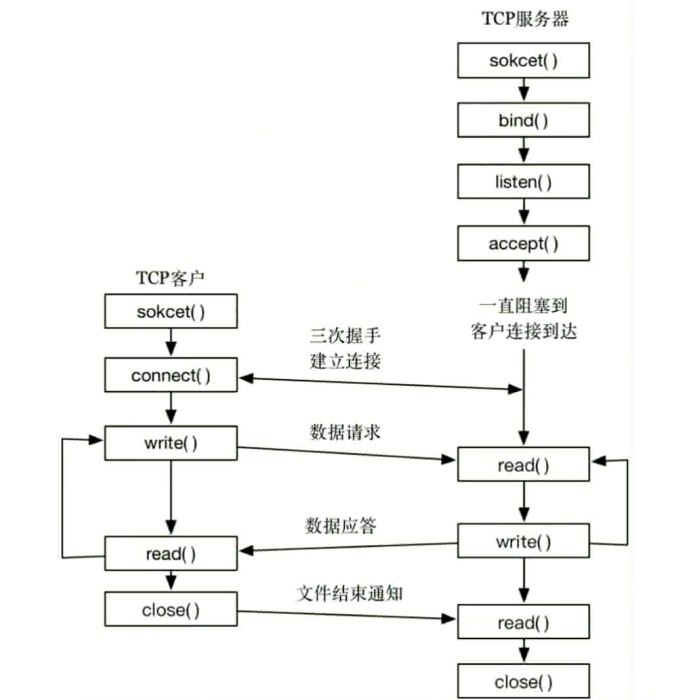
TCP / UDP socket 编程
使用 socket 模块. 建立 tcp / udp 客户端和服务端, 实现客户端和服务端之间的通信
TCP 实例
server 端
import socket import time s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind(('', 8888)) s.listen() while True: conn, addr = s.accept() print(conn) timestr = time.ctime(time.time()) + '\r\n' conn.send(timestr.encode()) # send 参数 encode('utf8') conn.close()
client 端
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect(('127.0.0.1', 8888)) s.sendall(b"Hello World") data = s.recv(1024) print(data) s.close()
打印结果
server 端

client 端
HTTP 协议常考题 - 请求方式 / 报文格式 / 状态码 / 长连接 / 用户识别 / 实现
代码请求发起方式
常用如使用 curl
python 更直观的展示可以安装 httppie pip install httpie 在命令行发起,

加参数 -v 可以打印整个过程
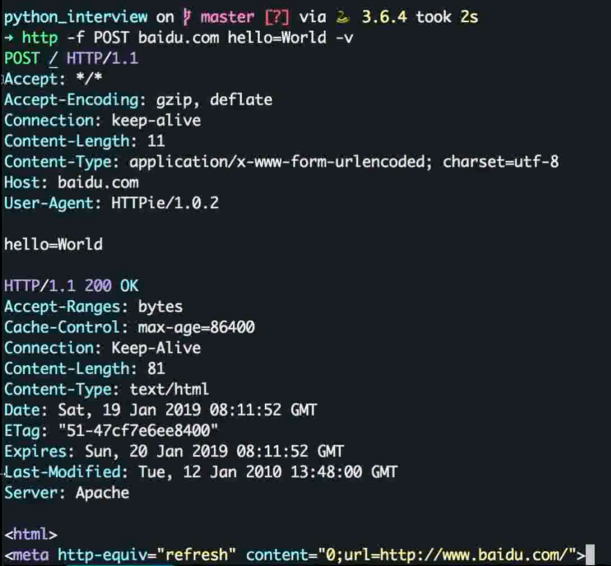
HTTP 请求的组成
状态行 , 请求头, 消息主体
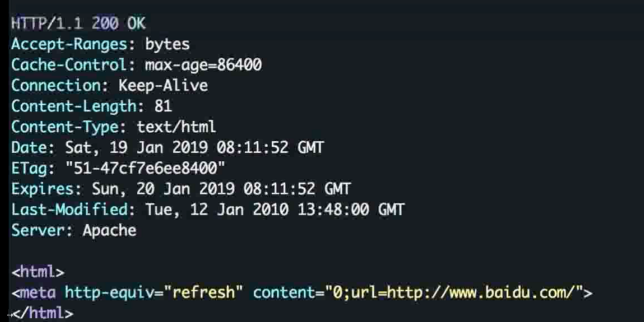
HTTP 响应的组成
状态行 , 响应头, 响应正文
HTTP 常见状态码


比如 220(成功) , 301(永久重定向), 302(临时重定向) , 400(请求错误), 403, 500等
HTTP 方法
常见的 HTTP 方法
GET 获取
POST 创建
PUT 更新
DELETE 删除
HTTP GET / POST 区别
Restful 语义上一个是获取, 一个是创建
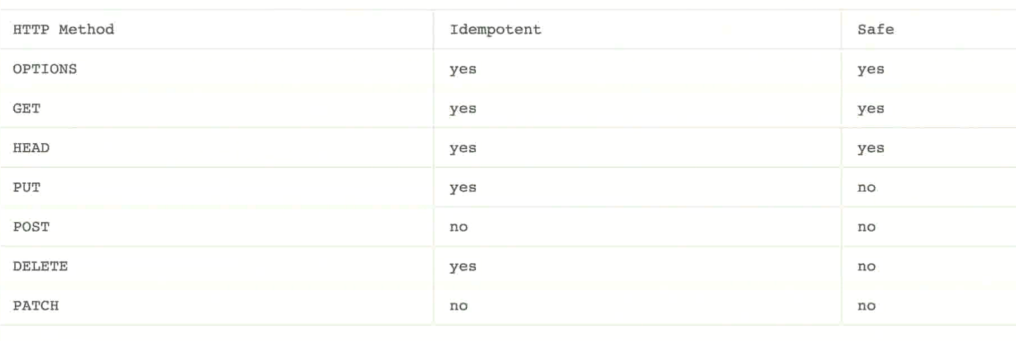
GET 是幂等的, POST是非幂等的 (a=4 是幂等, a+=4 是非幂等的, 幂等可以安全的重发请求)
GET 请求参数放在 url (明文), 存在长度限制, POST 放在请求体, 更安全
幂等方法
什么是 HTTP 长连接
短连接: 建立链接 - 数据传输 - 关闭链接 (链接的建立和关闭的开销都很大)
长连接 : 保持 TCP 链接不断开
HTTP 1.1 的时候实现了长连接 在请求头中 Connection: keep-alive 即可实现长连接
在接受完毕请求之后不会马上关闭链接. 而是继续等待下一个请求的到来
因此也出现了一个问题, HTTP 如何在长连接中识别每一次的请求
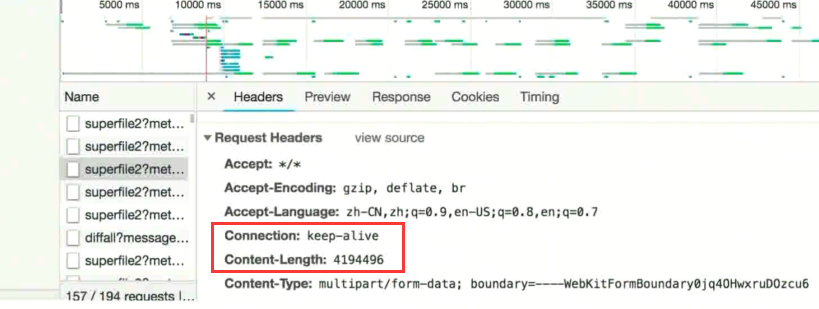
客户端告诉服务端发生的请求长度即可, 可通过 Content-Length 指定长度
但是不定长的动态报文的时候则可以通过 Transfer-Encoding 分段发送请求
cookie 和 session 的区别
HTTP 是无状态的, 无法对每一次请求的客户进行识别
Cookie : 实现 session 的一种机制, 通过 HTTP 的 cookie 字段实现
Session : 在服务端给用户生成一个标识, 每次让客户端带过去 (通过 url 参数, 或者 cookie ) 给后端让后端去识别
ps:
Session 通过服务器保存 sessionid 识别用户, Cookie 存储在客户端
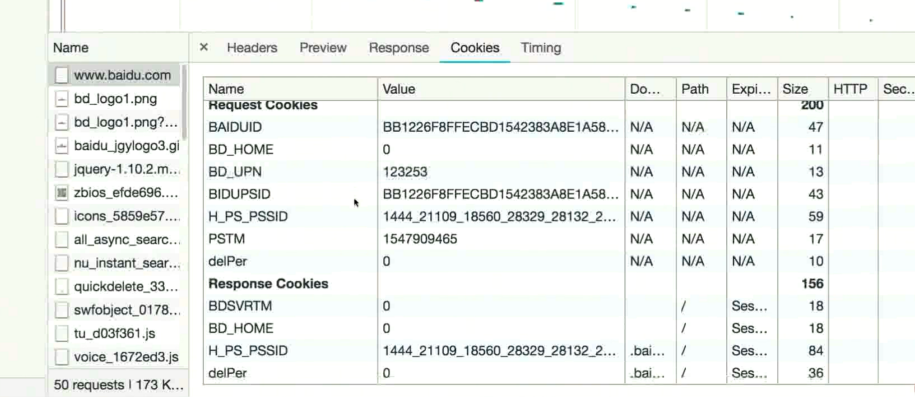
如何使用 socket 发送 HTTP 请求
利用 socket 建立 TCP 链接 (HTTP 建立在 TCP 基础之上)
然后发送 HTTP 格式的报文 (HTTP 是基于文本的协议)
import socket s = socket.socket() s.connect(("www.baidu.com", 80)) http = b"GET / HTTP/1.1\r\nHost: www.baidu.com\r\n\r\n" s.sendall(http) buf = s.recv(1024) print(buf) s.close()
返回结果
b'HTTP/1.1 200 OK\r\nBdpagetype: 1\r\nBdqid: 0x966f65a400058cc7\r\nCache-Control: private\r\nContent-Type: text/html;charset=utf-8\r\nDate: Thu, 25 Mar 2021 07:37:06 GMT\r\nExpires: Thu, 25 Mar 2021 07:36:36 GMT\r\nP3p: CP=" OTI DSP COR IVA OUR IND COM "\r\nP3p: CP=" OTI DSP COR IVA OUR IND COM "\r\nServer: BWS/1.1\r\nSet-Cookie: BAIDUID=D837E597D6078C0CC6FAB4602D1FB524:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com\r\nSet-Cookie: BIDUPSID=D837E597D6078C0CC6FAB4602D1FB524; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com\r\nSet-Cookie: PSTM=1616657826; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com\r\nSet-Cookie: BAIDUID=D837E597D6078C0C5A5B2B3EAA2B99C7:FG=1; max-age=31536000; expires=Fri, 25-Mar-22 07:37:06 GMT; domain=.baidu.com; path=/; version=1; comment=bd\r\nSet-Cookie: BDSVRTM=0; path=/\r\nSet-Cookie: BD_HOME=1; path=/\r\nSet-Cookie: H_PS_PSSID=33742_33273_33693_33759_33676_33392_26350; path=/; domain=.baidu.com\r\nTraceid: 161'
IO 多路复用
五种 IO 模型


常见的并发请求处理
多线程和多进程可以处理
但是多线程进程的创建开销对服务器的资源消耗较大
而使用 IO 多路复用可以在单进程下处理多个请求
什么是 IO 多路复用
操作系统提供的同时监听多个 socket 的机制
Linux 下常见的是 select / poll / epoll
常用的代码格式

select / poll / epoll 的区别
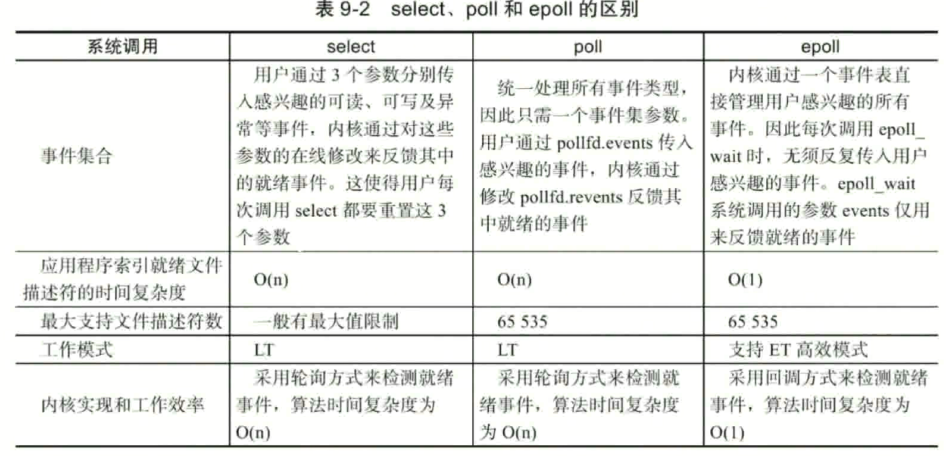
epoll 的时间复杂度最小, 大多数时间都是选择使用 epoll
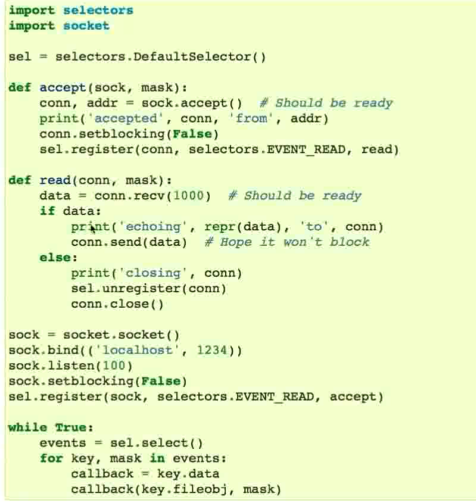
Python 如何实现 IO 多路复用
select / poll / epoll 模块
py2 select 模块
py3 selectors 模块

官方的示例
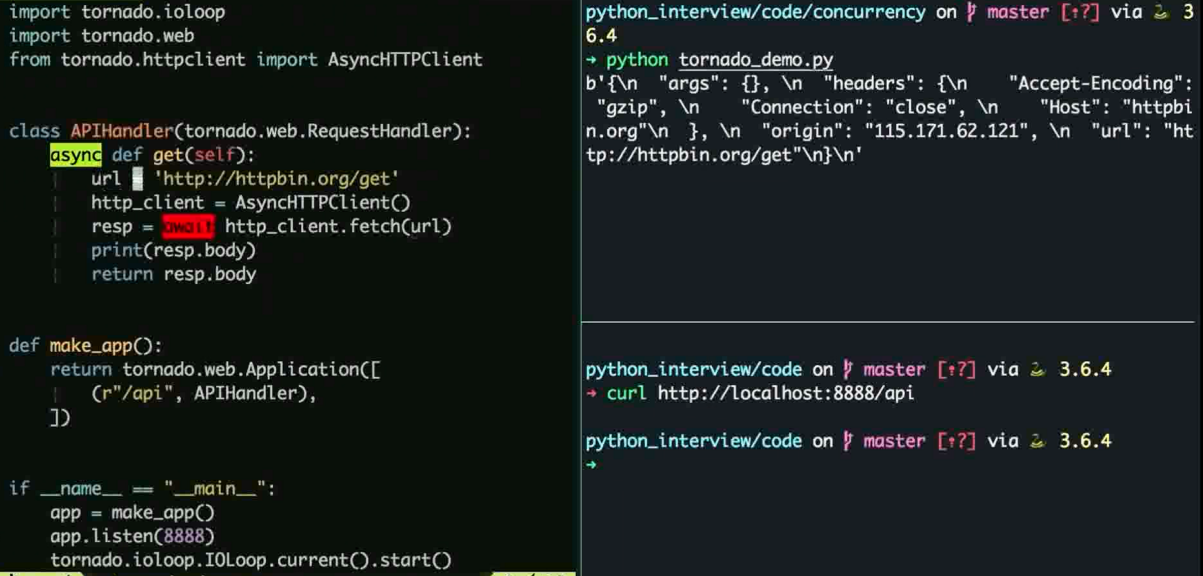
Python 并发网络库
Tornado
适用于微服务, 实现Restful 接口
底层基于 Linux 的多路复用
可以通过协程或者回调实现异步编程
可以作为一个轻量级的 web 框架
不过生态不完善, 相应的异步框架比如 ORM 不完善
简单示例
Gevent
基于greenliet 实现并发
猴子补丁修改内置 socket 改为非阻塞
配合 gunicorn 作为 wsgi server
简单示例
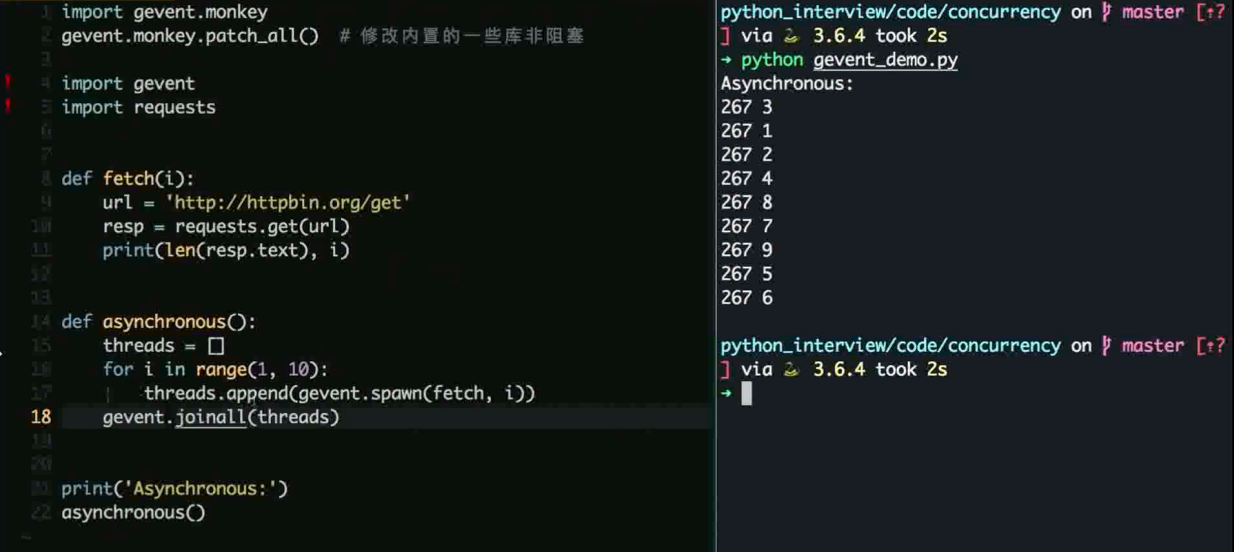
Asyncio
在 python3 引入, 协程 + 时间循环实现
生态不够完善, 没有大规模的生产环境检验
目前影响不够广泛, 基于 Aiohttp 可以实现一些小的服务
代码示例
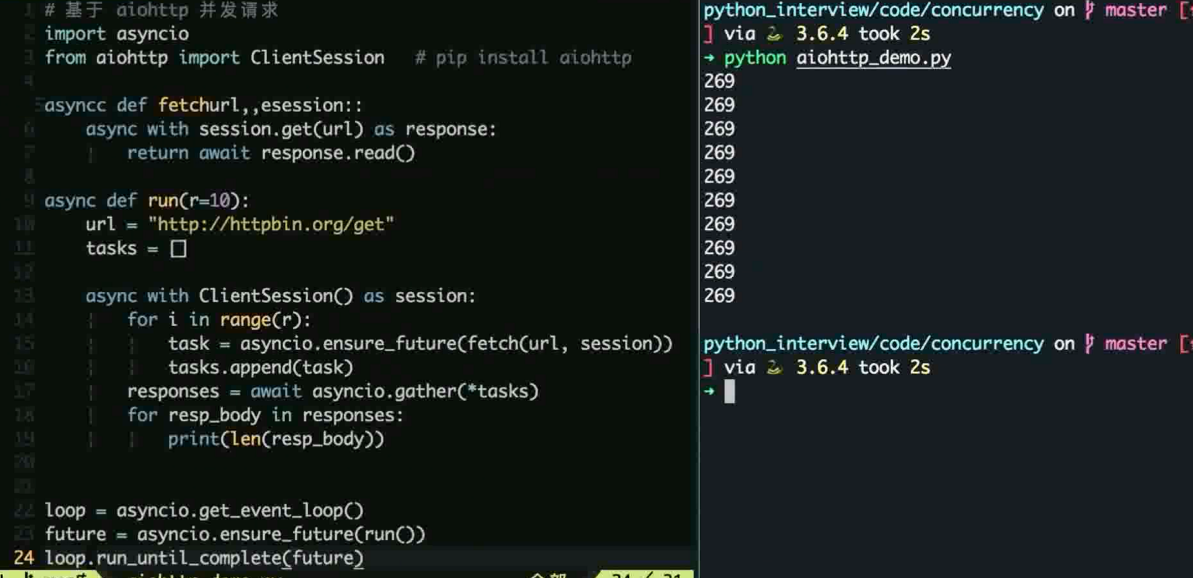
Mysql 基础常考题
基础考题
事务的原理, 特性, 并发控制
常用字段, 含义的区别
常用的数据库引擎的区别
事务
数据库并发控制的基本单位, 是一些列 sql 语句 的集和
事务必须全部成功, 要不全部执行失败( 回滚 )
最常见的操作是转账操作
简单示例

事务 ACID 特性
原子性 (Atomicity) : 一个事务中所有操作全部完成或失败
一致性 (Consistency) : 事务开始和结束之后数据完整性没有被破坏
隔离性 (Isolation) : 允许多个事务同时对数据库修改和读写
持久性 (Durabitlity) : 事务结束后, 修改是永久的不会丢失
事务的并发控制
事并发可能出现的问题
幻读: 一个事务第二次查看出现第一次没有的结果
非重复读: 一个事务重复读取两次得到不同的结果
脏读:一个事务读取到另一个事务没有提交的修改
丢失修改: 并发写入造成其中的一些修改丢失
为了解决以上的问题定义了四种事务隔离级别
读未提交: 别的事务可以读取到未提交的改变
读已提交: 只能读取已经提交的数据
可重复读: 同一个事务先后查询结果一样 (Mysql InnoDB 默认实现此级别)
串行化: 事务完全串行化执行, 隔离级别最高, 执行效率最低
如何解决高并发下的数据插入重复
使用数据库的唯一索引, 但是如果分库分表此方法则无效
使用队列异步写入, 或者使用redis 等实现分布式锁
乐观锁 / 悲观锁
悲观锁就是先获取锁在进行操作, 先锁再查再更新 (假设肯定有人在操作) 可通过 select for update 实现
乐观锁就是先修改, 更新的时候发现数据变了就回滚 (假设没人操作) 可以通过版本号或者时间戳 check and set 实现
按照 响应速度, 冲突频率, 重试代价 来判断使用哪一种
比如悲观锁强制上锁的行为是肯定会效率低一些
但是乐观锁冲突回滚的代价如果过大或者回滚频率很高也很难受
Mysql 常用的数据类型 - 字符串 (文本)

char 定长,varchar 不定长 , text 过长文本
Mysql 常用的数据类型 - 数值
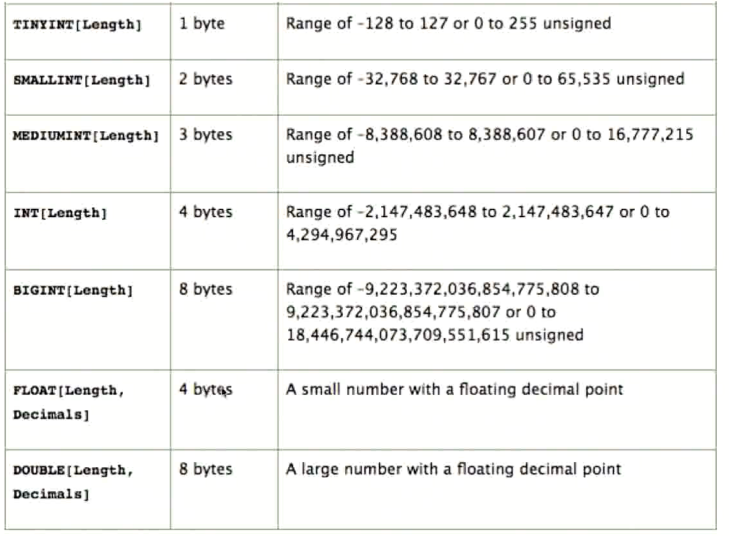
整数用 int, 大整数用 bigint, 定义时的长度并非指字节的长度, 而是指在数据库显示的时候的字符宽度
Mysql 常用的数据类型 - 日期时间

注意时间戳只能存储到 2038年 如果有更远的时间要求则需要用其他来代替
InnoDB 和 MyISAM 引擎的区别
MyISAM 不支持事务, InnoDB 支持事务
MyISAM 不支持外键, InnoDB 支持外键
MyISAM 只支持表锁, InnoDB 支持行锁 + 表锁
MyISAM 支持全文索引, InnoDB 不支持
Mysql 索引原理, 类型, 结构
为什么需要索引?
索引是数据表中一个或者多个列进行排序的数据结构
索引可以大幅度提高检索速度, 创建和更新索引本身也需要成本
常见的查找结构
线性查找: 一个一个找, 实现简单, 太慢
二分查找: 要求有序, 实现简单, 插入很慢 (需要保持有序)
HASH: 查询快, 但是占用空间大, 不适合大量数据存储
二叉查找树: 插入和查询很快 (log(n)), 无法存大规模数据, 存在复杂度退化的情况 (单边增长, 退化成线性结构)
平衡树: 解决二叉查找树复杂度退化的问题 (左右两边均衡, 不会退化), 无法解决大量数据时的节点太多, 树高度深的问题
多路查找树: 一个父亲可以多个孩子节点 (度), 从而降低树高
多路平衡查找树: 多路查找树的丰富版 - B-tree
什么是 B-Tree ?
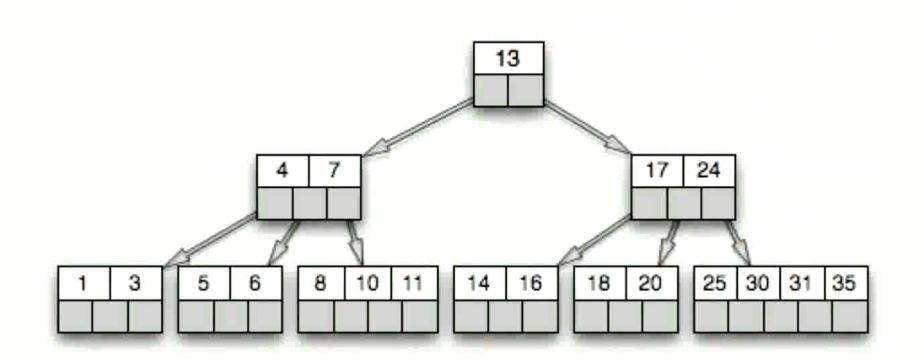
多路平衡查找树 (每个节点最多 m(m>=2)) 个孩子, 称为m 阶或者度)
叶节点具有相同的深度
节点中的数据 key 从左到右是递增的
但是 B-Tree 实现范围查找比较麻烦
什么是 B+Tree ?
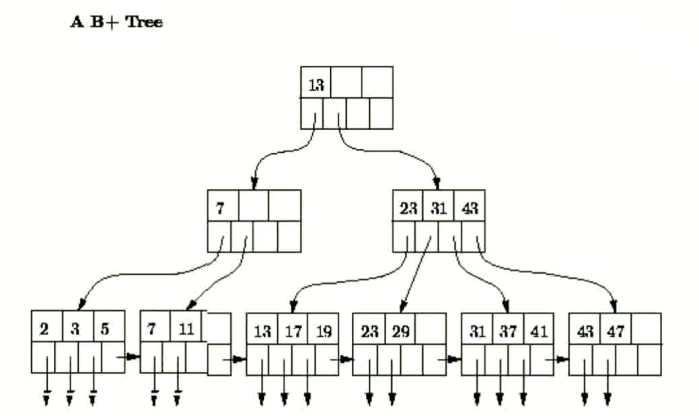
B+ 树是 B-Tree 的变形
Mysql 使用 B+Tree 作为索引的数据结构
只在叶子节点带有指向记录的指针
这样不需要存储真实数据把更多的空间来让树更多的度
叶子节点通过指针相连, 可以实现范围查询
Mysql 索引类型
普通索引 CREATE INDEX
唯一索引 索引列的值必须唯一 CREATE UNIQUE INDEX
多列索引 多个列一共组成索引
主键索引 一个表只能有一个 PRIMARY KEY
全文索引 InnoDB 不支持 FULLTEXT INDEX
什么时候创建索引
根据查询的需求来创建索引
经常用作查询条件的字段 (where)
经常用作表连接的字段 (join)
经常用在排序(order by) , 分组(group by) 的字段
创建索引的注意点
非空字段 NOT NULL , mysql 很难对空值做查询优化 - 对索引字段要求有默认值
区分度较高, 离散度较大, 尽可能不要有大量相同值
索引的长度不要太长 (比较费时间)
索引什么时候会失效
B+树的 key 没办法直接比较的时候就会失效
常见的有: 模糊匹配, 类型隐转, 最左匹配
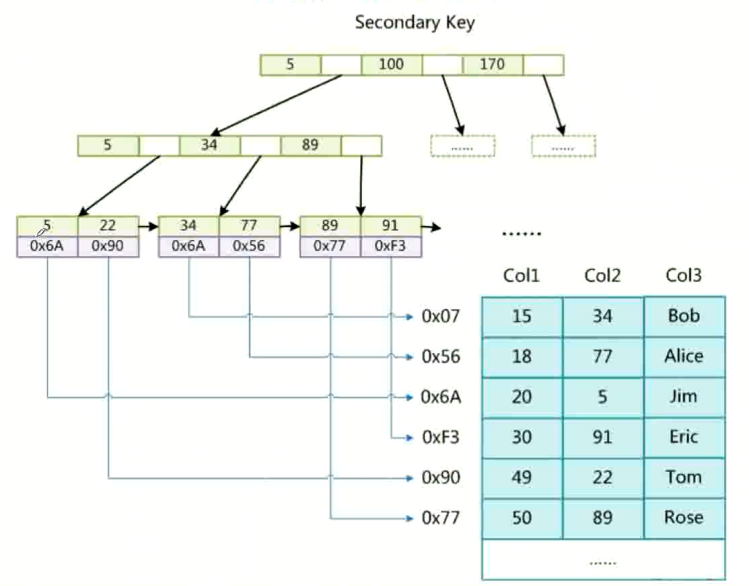
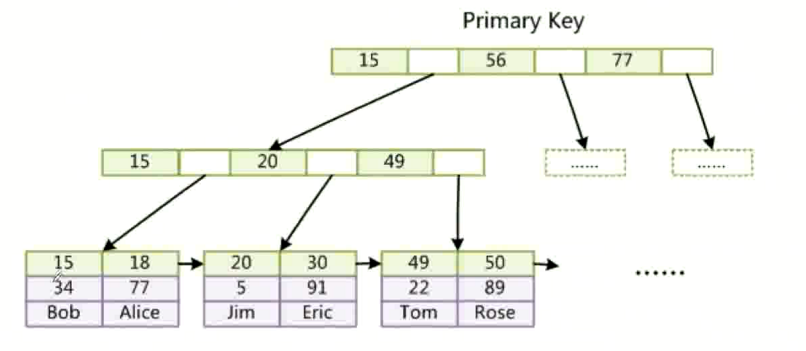
什么是聚集索引, 和非聚集索引

非聚集索引
聚集索引
如何排查慢查询
慢查询通常是缺少索引或者索引不合理或者业务代码实现导致
slow_query_log_file 开启并且查询慢查询日志
通过 explain 排查索引问题
调整数据修改索引; 业务层限制不合理访问
为什么 Mysql 数据库的主键使用自增的正数比较好
自增表示是有序的增长, 便于 B+tree 的key 的排序
使用数字存储的更小, 更容易操作
SQL 语句常考

内连接

INNER JOIN 两个表都存在匹配时, 返回匹配行
外连接

LEFT/RIGHT JOIN 返回一个表的行, 及时另一个没有匹配
全连接
FULL JOIN 只要某一个表存在匹配就返回左右两个表的全部
Redis 缓存相关问题
什么是缓存, 什么要使用缓存

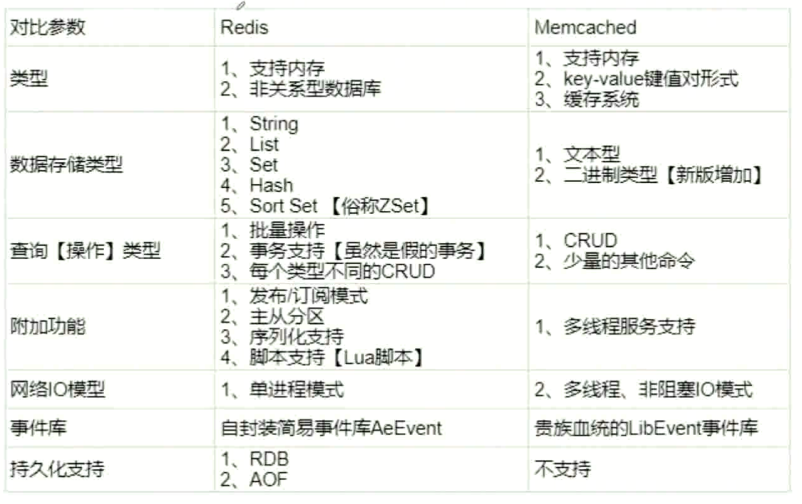
Redis 和 Memcached 的主要区别
常用的数据类型和使用场景


Redis 支持哪些持久化方式

Redis 的事务

Redis 如何实现分布式锁

大体思路, 多台机器上的多线程或者多进程同时访问一个 Redis 服务器, 有人用就设置一个键值对. 用完了就删除这个键值
这样每个程序来的时候如果发现是有这个键值对, 那就说明有人再用这个锁. 可以进行重试或者等待这个键值对被删除为止.
然后自己用的时候在设置这个键值对, 让别人知道你在用
使用缓存的模式

缓存穿透问题

缓存击穿问题

缓存雪崩问题

分布式系统下如何生成数据库的自增 ID ?
利用分布式锁的原理, 设置一个数字进行增长更新
Redis 单机进行分布式锁如果宕机怎么办?
可以使用类似 Redlock 之类的算法进行重启, 或者多台 Redis 服务器进行串联
宕机时进行主从选取重新上线之类的方案来缓解. 但是依旧存在一些问题
比如主从设备的数据异步同步可能存在延时导致脏数据之类的
没实际使用过就随便扯两句意思到了就行
Python WSGI 与 web 框架相关
什么是WSGI
背景
q:
经常使用 uwsgi / gunicorn 部署 django / flask 应用
为什么 flask / django 都可以在 gunicorn 上运行?
a:
在此之前存在 python web server 不规范的乱象
需要一个标准协议定义让网络框架以相同的规范对接
Python Wwb Server Gateway Interface (pep3333)
描述了 Web Server (uwsgi / gunicorn) 如何于 web 框架 (flask / django) 交互吗 Web 框架如何处理请求
由此可以让任意的 web 框架部署在任意的 web server 上
实现
实现的框架函数如图

具体实现

常用的 Python Web 框架的对比
Django / Flask / Tornado
Django 大而全, 自带orm, Admin 组件, 第三方插件较多
Flask 微框架, 插件机制, 非常灵活. 但是没有统一规范会导致后续的维护存在阻碍 (可以使用 cookiecutter-flask 生成统一的项目模板解决)
Tornado 异步支持的微框架和异步网络库, 轮子比较少. 相关支持不多
什么 MVC
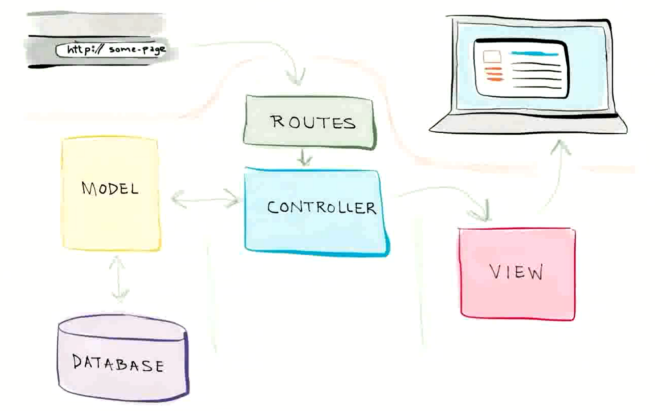
MVC : 模型(Model), 视图(View ), 控制器 (Controller)
Model: 负责业务对象和数据库的交互 (ORM)
View: 负责与用户的交互展示
Controller: 接受参数调用模型和视图完成请求
什么是 ORM
Object Relational Mapping 对象关系映射
用于实现业务对象与数据表中字段映射
常见如 Sqlalchemy , Django ORM , Peewee
优势: 代码更加面向对象, 代码更少, 灵活性更高, 提升开发效率
Web 安全问题
SQL 注入
原理
通过特殊构造的输入参数传入 Web 应用, 导致后端执行了恶意SQL
通常由于程序员未对输入进行过滤, 直接动态拼接SQL 产生
可以使用 开源工具 sqlmap, SQLninja 检测
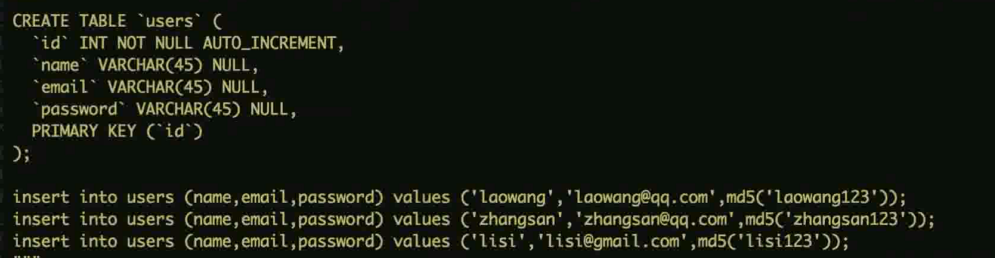
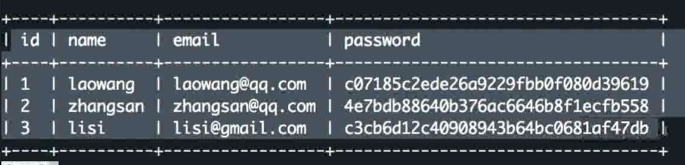
示例
正确的密码验证

错误的密码验证

注入式攻击输入
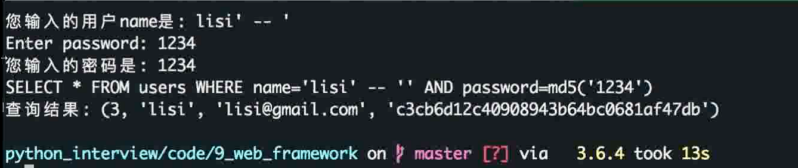
通过输入 '-- 注释 将后面的 sql 注释掉从而无法执行让 where 的条件失效, 从而绕过密码的检查
修复后示例

不要自己手动拼接。 拼接时使用占位符使用 sql 模块的内置方法自动拼接即可避免

解决方式
永远不要相信用户的任何输入
对输入的参数做好检查 (类型和范围), 过滤和转义特殊字符
不要手动拼接 sql , 使用 ORM 即可降低风险
数据库底层: 做好权限管理配置, 不要明文存储敏感信息
XSS 跨站脚本攻击
恶意用户将代码植入到提供给其他用户使用的页面中, 未经转义的恶意代码输出到其他用户的浏览器中被执行
用户浏览页面的时候嵌入页面中的脚本 (js) 会被执行, 攻击用户
主要分为两类: 反射型(非持久性), 存储型 (持久性)
示例

评论中评论信息中输入的是 js 代码. 从而每次对这段评论渲染的时候都会执行这段脚本
非存储型的比如在 url 里面插入一段代码
![]()
解绝方式
CSRF 跨站请求伪造
原理
本质依旧是获取用户的 cookie 从而进行操作
cookie 都是在浏览器保存, 诱导用户在钓鱼网站进行恶性操作
示例

解决方式
get 请求的伪造成本是比 post 低很多的, 使用 post 请求方式可以一定程度避免
但是 post 请求也可以被伪造
用户操作限制——验证码机制
方法:添加验证码来识别是不是用户主动去发起这个请求,由于一定强度的验证码机器无法识别,因此危险网站不能伪造一个完整的请求
优点:简单粗暴,低成本,可靠,最安全的方式
缺点:对用户极不友好
请求来源限制——验证 HTTP Referer 字段
方法:在HTTP请求头 Referer 字段用以记录请求源地址, 服务器可验证源地址是否合法从而判定是否拒绝响应
优点:零成本,简单易实现
缺点:由于这个方法严重依赖浏览器自身,因此安全性全看浏览器
- 兼容性不好:各浏览器对于
Referer有差异化实现 - 并不一定可靠:在一些古老的垃圾浏览器中,
Referer可以被篡改 - 对用户不友好:
- 记录用户的访问来源,部分用户认为这样会侵犯到他们自己的隐私权
- 浏览器具有防止跟踪功能,开启后会取消此字段, 从而导致正常用户请求被拒绝
额外验证机制——token的使用
方法:使用token来代替验证码验证。由于黑客并不能拿到和看到cookie里的内容,所以无法伪造一个完整的请求。基本思路如下:
- 服务器随机产生
token,存在session中,放在cookie中或者以ajax的形式交给前端 - 前端发请求的时候,解析
cookie中的token,放到请求url里或者请求头中 - 服务器验证
token,由于黑客无法得到或者伪造token,所以能防范csrf
更进一步的加强手段(不需要session):
- 服务器随机产生
token,然后以token为密钥散列生成一段密文 - 把
token和密文都随cookie交给前端 - 前端发起请求时把密文和
token都交给后端 - 后端对
token和密文进行正向散列验证,看token能不能生成同样的密文 - 这样即使黑客拿到了
token也无法拿到密文
优点:
- 安全性:极大地提高了破解成本
- 易用性:非常容易实现
- 友好性:对用户来说十分友好
缺点:
- 性能担忧:需要
hash计算,增加性能上的成本 cookie臃肿:更加依赖网络的情况- 对于POST请求,难以将
token附在请求中。(可以通过框架和库解决)
曲线救国——在HTTP头中自定义属性并验证
方法:将 token 放在 HTTP头的自定义属性中
优点:
- 这样解决了上种方法在请求中加入 token 的不便
- 通过 XMLHttpRequest 请求的地址不会被记录到浏览器的地址栏,安全性较高
缺点:
- 局限性大:XMLHttpRequest请求通常用于Ajax,并非所有的请求都适合用这个类来发起,请求后的页面无法被浏览器记录,造成不便。
- 旧网站改造需全部改为XMLHttpRequest请求, 代价过大
前后端分离与RESTful 常见面试题
什么是前后端分离, 好处是什么

什么是 RESTful


RESTful 的准则

什么是 RESTful API


示例

系统设计相关
什么是系统设计

设计难点

设计要素



延伸考点

施工完毕---------------------------------------
本文来自博客园,作者:羊驼之歌,转载请注明原文链接:https://www.cnblogs.com/shijieli/p/14520355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号