Apache kylin中cube的构建过程及原理分析
一、 cube构建步骤
登录页面
创建Project
同步数据
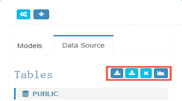
1) 加载Hive表
2) 从同步的目录中导入,即将上张图中左侧的数据库中的表导入
3) 上传Hive表
4) 添加流表。
创建Model
事实表关联其他表创建一个model
1) 填写基本信息
2) 选择事实表
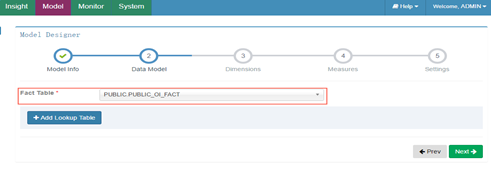
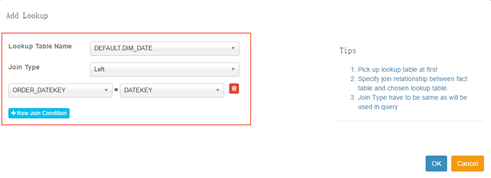
3) 填写关联表(lookup_table)及关联方式
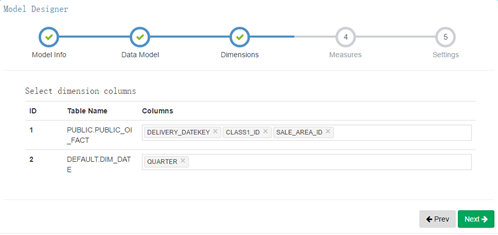
4) 选择维度
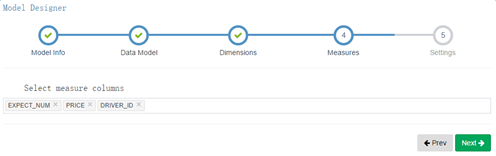
5) 选择统计值
创建cube
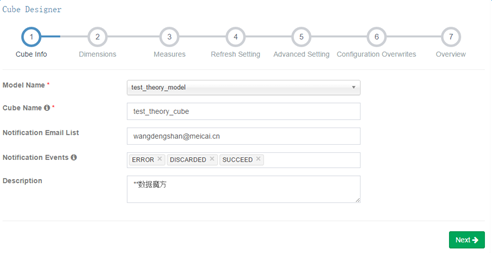
1) cube信息
2) 填写维度信息
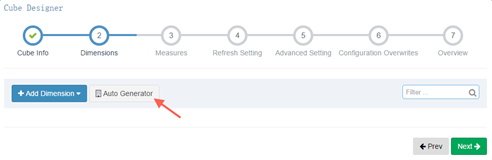
选择自动生成,全部勾选
两种维度说明:为了减少cuboid的数目
Normal,为最常见的类型,与所有其他的dimension组合构成cuboid。
Derived,指该dimensions与维表的primary key是一一对应关系,可以更有效地减少cuboid数量,并且derived dimension只能由lookup table的列生成。 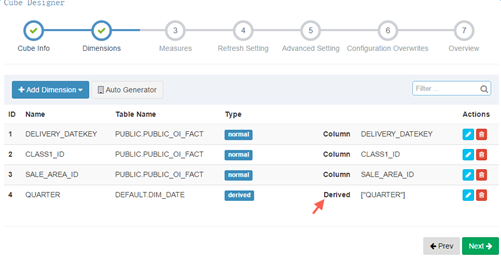
3) 度量信息
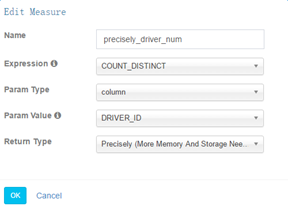
支持去重精确计算
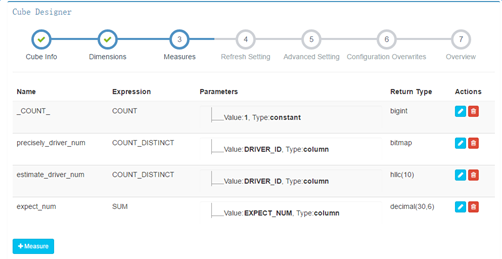
kylin会为每一个cube创建一个聚合函数为count(1)的度量,它不需要关联任何列,用户自定义的度量可以选择SUM、COUNT、DISTINCT COUNT、MIN、MAX,而每一个度量定义时还可以选择这些聚合函数的参数,可以选择常量或者事实表的某一列,一般情况下我们当然选择某一列。这里我们发现kylin并不提供AVG等相对较复杂的聚合函数(方差、平均差更没有了),主要是因为它需要基于缓存的cube做增量计算并且合并成新的cube,而这些复杂的聚合函数并不能简单的对两个值计算之后得到新的值,例如需要增量合并的两个cube中某一个key对应的sum值分别为A和B,那么合并之后的则为A+B,而如果此时的聚合函数是AVG,那么我们必须知道这个key的count和sum之后才能做聚合。这就要求使用者必须自己想办法自己计算了。
4) 更新设置
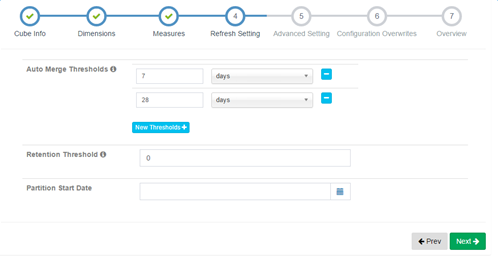
设置增量cube信息,首先需要选择事实表中的某一个时间类型的分区列(只能是按照天进行分区),然后再指定本次构建的cube的时间范围(起始时间点),这一步的结果会作为原始数据查询的where条件,保证本次构建的cube只包含这个闭区间时间内的数据,如果事实表没有时间类型的分区列或者没有选择任何分区则表示数据不会动态更新,也就不可以增量的创建cube了。
除了build这种每个时间区间向前或者向后的新数据计算,还存在两种对已完成计算数据的处理方式。第一种称之为Refresh,当某个数据区间的原始数据(hive中)发生变化时,预计算的结果就会出现不一致,因此需要对这个区间的segment进行刷新,即重新计算。第二种称之为Merge,由于每一个输入区间对应着一个Segment,结果存储在一个htable中,久而久之就会出现大量的htable,如果一次查询涉及的时间跨度比较久会导致对很多表的扫描,性能下降,因此可以通过将多个segment合并成一个大的segment优化。但是merge不会对现有数据进行任何改变。
在kylin中可以设置merge的时间区间,默认是7、28,表示每当build了前一天的数据就会自动进行一个merge,将这7天的数据放到一个segment中,当最近28天的数据计算完成之后再次merge,以减小扫描的htable数量。但是对于经常需要refresh的数据就不能这样设置了,因为一旦合并之后,刷新就需要将整个合并之后的segment进行刷新,这无疑是浪费的。
注意:kylin不支持删除某一天的数据,如果不希望这一天数据存在,可以在hive中删除并重新refresh这段数据
5) 高级设置
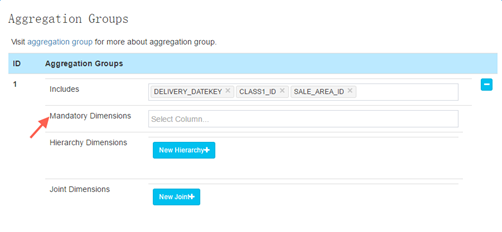
这里有一个可以修改的是mandatory dimension,如果一个维度需要在每次查询的时候都出现,那么可以设置这个dimension为mandatory,可以省去很多存储空间。
6) 覆盖配置设置
选默认
7) 保存
构建 cube
查看 cube 构建过程
双击job查看详细构建步骤
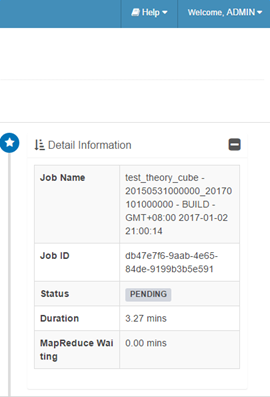
参考:http://www.jianshu.com/p/c49c61b654da
二、 cube构建原理
1. 计算cuboid文件
1) 生成原始数据(Create Intermediate Flat Hive Table)
根据cube的定义创建一个hive外部表,再根据cube中定义的星状模型,查询出维度(对于DERIVED类型的维度使用的是外键列)和度量的值插入到新创建的表中,然后通过hive -e的方式执行执行以下shell命令:
- drop TABLE IF EXISTS xxx.
- CREATE EXTERNAL TABLE IF NOT EXISTS xxx() ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\177’ STORED AS SEQUENCEFILE LOCATION xxxx
- INSERT OVERWRITE TABLE xxx SELECT xxxx
这一步执行完成之后location指定的目录下就有了原始数据的文件,为接下来的任务提供了输入。
2) 创建事实表distinct column文件(Extract Fact Table Distinct Columns)
根据上一步生成的hive表计算出原表中的每一个出现在事实表中的度量的distinct值
根据上一步生成的hive表计算出每一个出现在事实表中的度量的distinct值写入到文件中。它是启动一个MR任务完成的,MR任务的输入是HCatInputFormat,它关联的表就是上一步创建的临时表,这个MR任务的map阶段首先在setup函数中得到所有度量中出现在事实表的度量在临时表的index,根据每一个index得到该列在临时表中在每一行的值value,然后将<index, value>作为mapper的输出,该任务还启动了一个combiner,它所做的只是对同一个key的值进行去重(同一个mapper的结果),reducer所做的事情也是进行去重(所有mapper的结果),然后将每一个index对应的值一行行的写入到以列名命名的文件中。如果某一个维度列的distinct值比较大,那么可能导致MR任务执行过程中的OOM。
3) 创建维度词典(Build Dimension Dictionary)
创建所有维度的dictionary
如果是事实表上的维度则可以从上一步生成的文件中读取该列的distinct成员值(FileTable),否则则需要从原始的hive表中读取每一列的信息(HiveTable)。获取所有的列去重之后的成员列表生成dictionary并作为cube的元数据存储到kylin元数据库。
计算维度表的snapshotTable
从原始的hive维度表中顺序得读取每一行每一列的值,将每一列的值使用编码之后的id进行替换得到了一个只有id的维度表的snapshotTable并存储到kylin的元数据库中。
4) 计算生成BaseCuboid文件(Build Base Cuboid Data)
这一步也是通过一个MR任务完成的,输入是临时表的路径和分隔符,map对于每一行首先进行split,然后获取每一个维度列的值并替换为dictionary中的id组合成rowKey,combiner和reducer中根据cube定义中度量的函数按rowKey分组计算每个度量的值。
5) 计算第N层cuboid文件(Build N-Dimension Cuboid Data)
由于最底层的cuboid(base)已经计算完成,下一层cuboid计算的输出是上一层cuboid执行MR任务的输入。 mapper的过程只需要根据这一行输入的key(例如A、B、C、D中四个成员的组合)获取可能的下一层的的组合(例如只有A、B、C和B、C、D),那么只需要将这些可能的组合提取出来作为新的key,value不变进行输出就可以了。它的reducer和base cuboid的reducer过程基本一样的(相同rowkey的measure执行聚合运算)。
如果有N个维度,那么就需要有N +1层cuboid,每一层cuboid可能是由多个维度的组合,但是它包含的维度个数相同。
2. 输出到hbase
1) 计算分组
计算的全部的cuboid文件作为输入。mapper阶段按照cuboid文件的顺序(层次的顺序)一次读取每一个key-value,每当统计到1GB的数据将当前的这个key和当前数据量总和输出。在reducer阶段根据用户创建cube时指定的cube大小(SMALL,MEDIUM和LARGE)和总的大小计算出实际需要划分为多少分区。再根据实际数据量大小和分区数计算出每一个分区的边界key,为下一步创建htable做准备。
2) 创建HTable
根据上一步计算出的rowKey分布情况(split数组)创建HTable,创建一个HTable的时候还需要考虑一下几个事情:1、列簇的设置,2、每一个列簇的压缩方式,3、部署coprocessor,4、HTable中每一个region的大小。在hbase中存储的数据key是维度成员的组合,value是对应聚合函数的结果,列组针对的是value的,一般情况下在创建cube的时候只会设置一个列组,该列包含所有的聚合函数的结果;在创建HTable时默认使用LZO压缩;kylin强依赖于hbase的coprocessor,所以需要在创建HTable为该表部署coprocessor,这个文件会首先上传到HBase所在的HDFS上,然后在表的元信息中关联。
参考:http://blog.csdn.net/hljlzc2007/article/details/12652243
3) 构建hfile文件
将cuboid文件转换成HTable格式的Hfile文件, 通过bulkLoad的方式将文件和HTable进行关联。
创建完了HTable之后一般会通过插入接口将数据插入到表中,但是由于cuboid中的数据量巨大,频繁的插入会对Hbase的性能有非常大的影响,所以kylin采取了首先将cuboid文件转换成HTable格式的Hfile文件,然后在通过bulkLoad的方式将文件和HTable进行关联,这样可以大大降低Hbase的负载,这个过程通过一个MR任务完成。
所有的cuboid文件作为mapper阶段的输入,reducer按照行排序输出。
4) BulkLoad文件
参考:https://my.oschina.net/leejun2005/blog/187309
3. 收尾工作
- 更新状态
这一步主要是更新cube的状态,其中需要更新的包括cube是否可用、以及本次构建的数据统计,包括构建完成的时间,输入的record数目,输入数据的大小,保存到Hbase中数据的大小等,并将这些信息持久到元数据库中。
- 垃圾文件回收
这一步是否成功对正确性不会有任何影响,因为经过上一步之后这个segment就可以在这个cube中被查找到了,但是在整个执行过程中产生了很多的垃圾文件,其中包括:1、临时的hive表,2、因为hive表是一个外部表,存储该表的文件也需要额外删除,3、fact distinct 这一步将数据写入到HDFS上为建立词典做准备,这时候也可以删除了,4、rowKey统计的时候会生成一个文件,此时可以删除。5、生成HFile时文件存储的路径和hbase真正存储的路径不同,虽然load是一个remove操作,但是上层的目录还是存在的,也需要删除。这一步kylin做的比较简单,并没有完全删除所有的临时文件,其实在整个计算过程中,真正还需要保留的数据只有多个cuboid文件(需要增量build的cube),这个因为在不同segment进行merge的时候是基于cuboid文件的,而不是根据HTable的。
参考:http://blog.csdn.net/yu616568/article/details/50365240
4. 基本概念
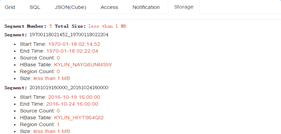
- Cube Segment
每个Cube Segment是对特定时间范围的数据计算而成的Cube。每个Segment对应一张HBase表。
- Mandotary - 必需的维度:这种类型用于对Cube生成树做剪枝:如果一个维度被标记为“Mandatory”,会认为所有的查询都会包含此维度,故所有不含此维度的组合,在Cube构建时都会被剪枝(不计算).
- Hierarchy 维度
Hierarchy - 层级维度:如果多个维度之间有层级(或包含)的关系,通过设置为“Hierarchy”,那些不满足层级的组合会被剪枝。如果A, B, C是层级,并且A>B>C,那么只需要计算组合A, AB, ABC; 其它组合如B, C, BC, AC将不做预计算。
- Derived 维度
Derived - 衍生维度:维度表的列值,可以从它的主键值衍生而来,那么通过将这些列定义为衍生维度,可以仅将主键加入到Cube的预计算来,而在运行时通过使用维度表的快照,衍生出非PK列的值,从而起到降维的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号