

随机森林
一、随机森林分类器 关键词:决策树、随机森林分类、print标准格式、交叉验证、plot、scipy-comb、确保随机性、常用接口。
1.1导入库和数据集
from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_wine
wine = load_wine() print(wine.data) print(wine.target)
输出:

1.2决策树与RF对比
from sklearn.model_selection import train_test_split Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3) clf = DecisionTreeClassifier(random_state=0) rfc = RandomForestClassifier(random_state=0) clf.fit(Xtrain,Ytrain) rfc.fit(Xtrain,Ytrain) score_c = clf.score(Xtest,Ytest) score_r = rfc.score(Xtest,Ytest) print("Single Tree:{}".format(score_c) ,"Random Forest:{}".format(score_r))
输出:

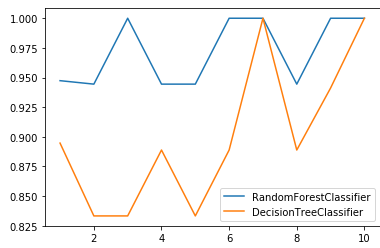
# 二者在交叉验证下的效果对比 from sklearn.model_selection import cross_val_score import matplotlib.pyplot as plt rfc = RandomForestClassifier(n_estimators=25) rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10) clf = DecisionTreeClassifier() clf_s = cross_val_score(clf,wine.data,wine.target,cv=10) plt.plot(range(1,11),rfc_s,label='RandomForestClassifier') plt.plot(range(1,11),clf_s,label='DecisionTreeClassifier') plt.legend() plt.show()
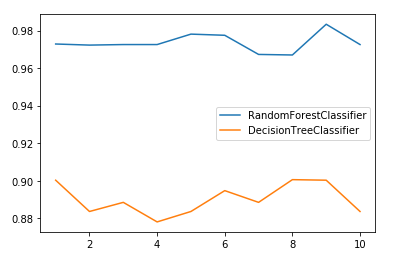
# 二者在10组交叉验证下的对比 rfc_l = [] clf_l = [] for i in range(1,11): rfc = RandomForestClassifier(n_estimators=25) rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean() rfc_l.append(rfc_s) clf = DecisionTreeClassifier() clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean() clf_l.append(clf_s) plt.plot(range(1,11), rfc_l, label='RandomForestClassifier') plt.plot(range(1,11), clf_l, label='DecisionTreeClassifier') plt.legend() plt.show()
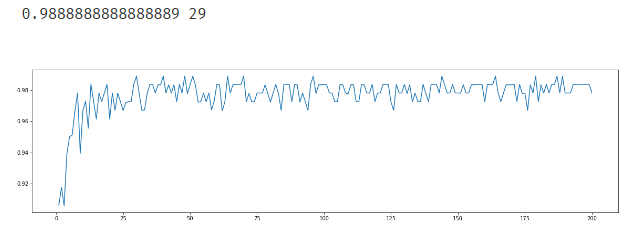
1.3n_estimators的学习曲线
# n_estimators的学习曲线 # n_jobs=-1 设定cpu里的所有core进行工作 nlr = [] for i in range(200): rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1) rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean() nlr.append(rfc_s) print(max(nlr),nlr.index(max(nlr))) plt.figure(figsize=[20,5]) plt.plot(range(1,201),nlr) plt.show()
1.4计算验证RF错误率
# 计算0.2的错误率下 n=25时rf判断错误的概率 # scipy中组合计算comb import numpy as np from scipy.special import comb np.array([comb(25,i)*(0.2**i)*((1-0.2)**(25-i)) for i in range(13,26)]).sum()

1.5RF的随机性
random_state,bootstrap,oob_score
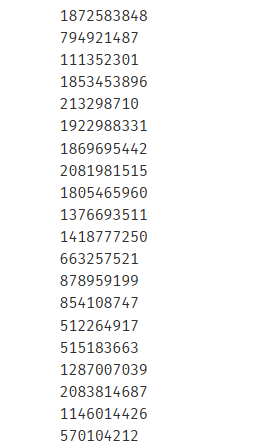
rfc = RandomForestClassifier(n_estimators=20,random_state=2) rfc = rfc.fit(Xtrain,Ytrain) #随机森林的重要属性之一:estimators,查看森林中树的状况 rfc.estimators_[0].random_state #1872583848 for i in range(len(rfc.estimators_)): print(rfc.estimators_[i].random_state)
# 除了random_state之外的其他随机性
# 使用不同的训练集:bootstrap控制抽样技术的参数,有放回随机抽样,默认为True
# 不足之处:样本数n足够大时,会有约37%的训练数据被浪费掉,没有参与建模,这些数据
#被称为oob-out of bag data.可以直接使用oob来作为测试集。
# 实例化时,oob_score=True 对应属性:oob_score_ rfc = RandomForestClassifier(n_estimators=25, oob_score=True) rfc = rfc.fit(wine.data,wine.target) rfc.oob_score_

1.6RF的常用接口
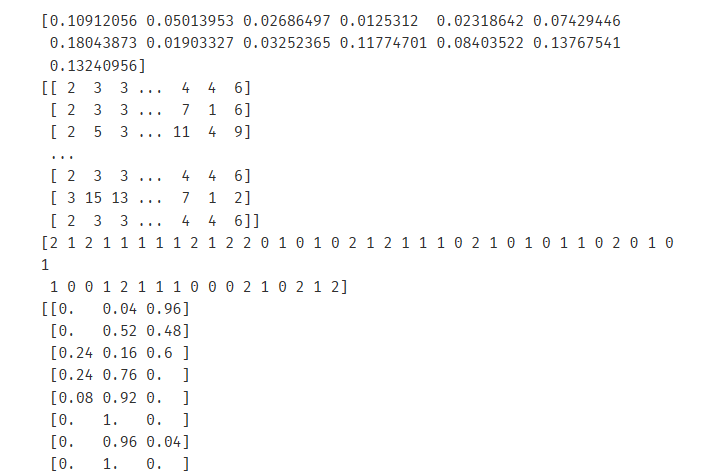
# 常用接口(与决策树一致) rfc = RandomForestClassifier(n_estimators=25) rfc = rfc.fit(Xtrain, Ytrain) rfc.score(Xtest,Ytest) print(rfc.feature_importances_) # 所有特征的重要性数值 print(rfc.apply(Xtest)) # 返回测试集中每个样本在所在树的叶子节点的索引 print(rfc.predict(Xtest)) # 预测标签 print(rfc.predict_proba(Xtest)) # 分配到每个标签的概率
1.7对比基分类器和rf的错误率
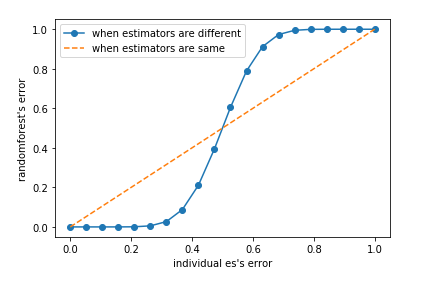
# 基分类器的准确率要大于0.5的原因 x = np.linspace(0,1,20) y = [] for e in np.linspace(0,1,20): E = np.array([comb(25,i)*(e**i)*((1-e)**(25-i)) for i in range(13,26)]).sum() y.append(E) plt.plot(x,y,'o-',label='when estimators are different') plt.plot(x,x,'--',label='when estimators are same') plt.xlabel("individual es's error") plt.ylabel("randomforest's error") plt.legend() plt.show()
二、随机森林回归器
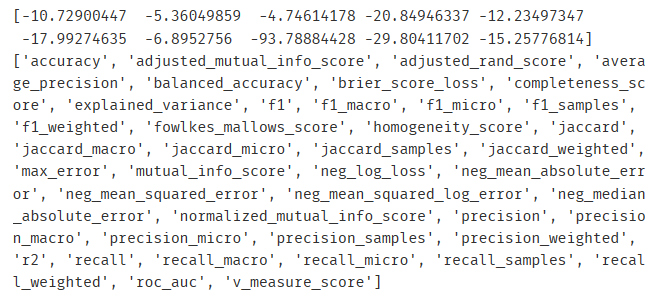
from sklearn.datasets import load_boston from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestRegressor import sklearn boston = load_boston() reger = RandomForestRegressor(n_estimators=100,random_state=0) cvs = cross_val_score(reger,boston.data,boston.target,cv=10 ,scoring='neg_mean_squared_error') print(cvs) print(sorted(sklearn.metrics.SCORERS.keys())) # 打印出可以作为scoring参数的选项

 浙公网安备 33010602011771号
浙公网安备 33010602011771号