


机器学习-Loss函数-Triplet loss&Circle loss
https://blog.csdn.net/u013082989/article/details/83537370
一、 Triplet loss
1、介绍
Triplet loss最初是在 FaceNet: A Unified Embedding for Face Recognition and Clustering 论文中提出的,可以学到较好的人脸的embedding- 为什么不适用
softmax函数呢,softmax最终的类别数是确定的,而Triplet loss学到的是一个好的embedding,相似的图像在embedding空间里是相近的,可以判断是否是同一个人脸。
2、原理
- 输入是一个三元组
<a, p, n>a: anchorp: positive, 与a是同一类别的样本n: negative, 与a是不同类别的样本

- 公式是:
![]()
- 所以最终的优化目标是拉近
a, p的距离, 拉远a, n的距离 easy triplets: L=0L = 0L=0 即 d(a,p)+margin<d(a,n)d(a, p) +margin < d(a, n)d(a,p)+margin<d(a,n),这种情况不需要优化,天然a, p的距离很近,a, n的距离远hard triplets: d(a,n)<d(a,p)d(a, n) < d(a, p)d(a,n)<d(a,p), 即a, p的距离远semi-hard triplets: d(a,p)<d(a,n)<d(a,p)+margind(a, p) < d(a, n) < d(a, p) + margind(a,p)<d(a,n)<d(a,p)+margin, 即a, n的距离靠的很近,但是有一个margin
- 所以最终的优化目标是拉近
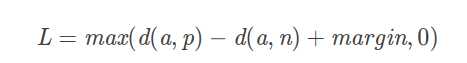

FaceNet中是随机选取semi-hard triplets进行训练的, (也可以选择hard triplets或者两者一起进行训练)
3、训练方法
3.1 offline
- 训练集所有数据经过计算得到对应的
embeddings, 可以得到 很多<i, j, k>的三元组,然后再计算triplet loss - 效率不高,因为需要过一遍所有的数据得到三元组,然后训练反向更新网络
3.2 online
- 从训练集中抽取
B个样本,然后计算B个embeddings,可以产生 B3B^3B3 个triplets(当然其中有不合法的,因为需要的是<a, p, n>)

- 实际使用中采用此方法,又分为两种策略 (是在一篇行人重识别的论文中提到的 In Defense of the Triplet Loss for Person Re-Identification),假设 B=PKB = PKB=PK, 其中
P个身份的人,每个身份的人K张图片(一般K取4)Batch All: 计算batch_size中所有valid的的hard triplet和semi-hard triplet, 然后取平均得到Loss- 注意因为很多
easy triplets的情况,所以平均会导致Loss很小,所以是对所有 valid 的所有求平均 (下面代码中会介绍) - 可以产生 PK(K−1)(PK−K)PK(K-1)(PK-K)PK(K−1)(PK−K)个
tripletsPK个anchorK-1个positivePK-K个negative
- 注意因为很多
Batch Hard: 对于每一个anchor, 选择距离最大的d(a, p)和 距离最大的d(a, n)- 所以公有 PKPKPK 个 三元组
triplets
- 所以公有 PKPKPK 个 三元组
二、 Tensorflow 中的实现



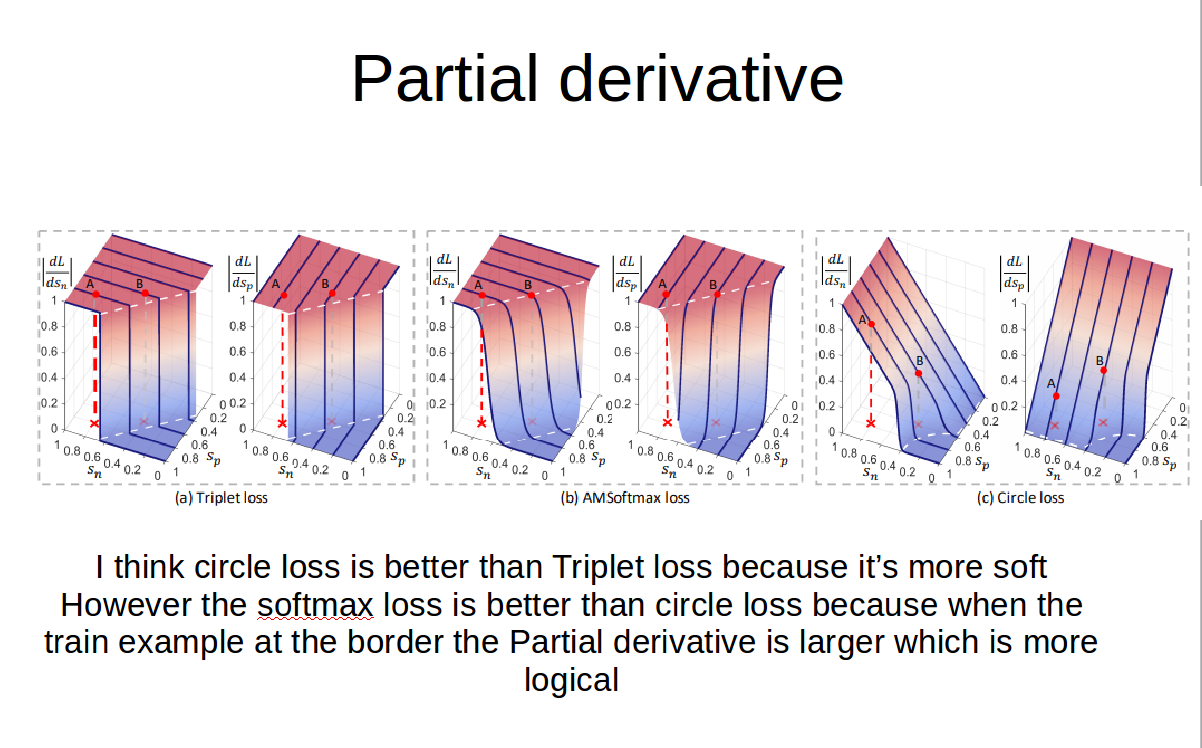
实际上这个损失函数不管K和L的差距有多大https://www.zhihu.com/question/382802283

 浙公网安备 33010602011771号
浙公网安备 33010602011771号