
Livy原理详解
概述
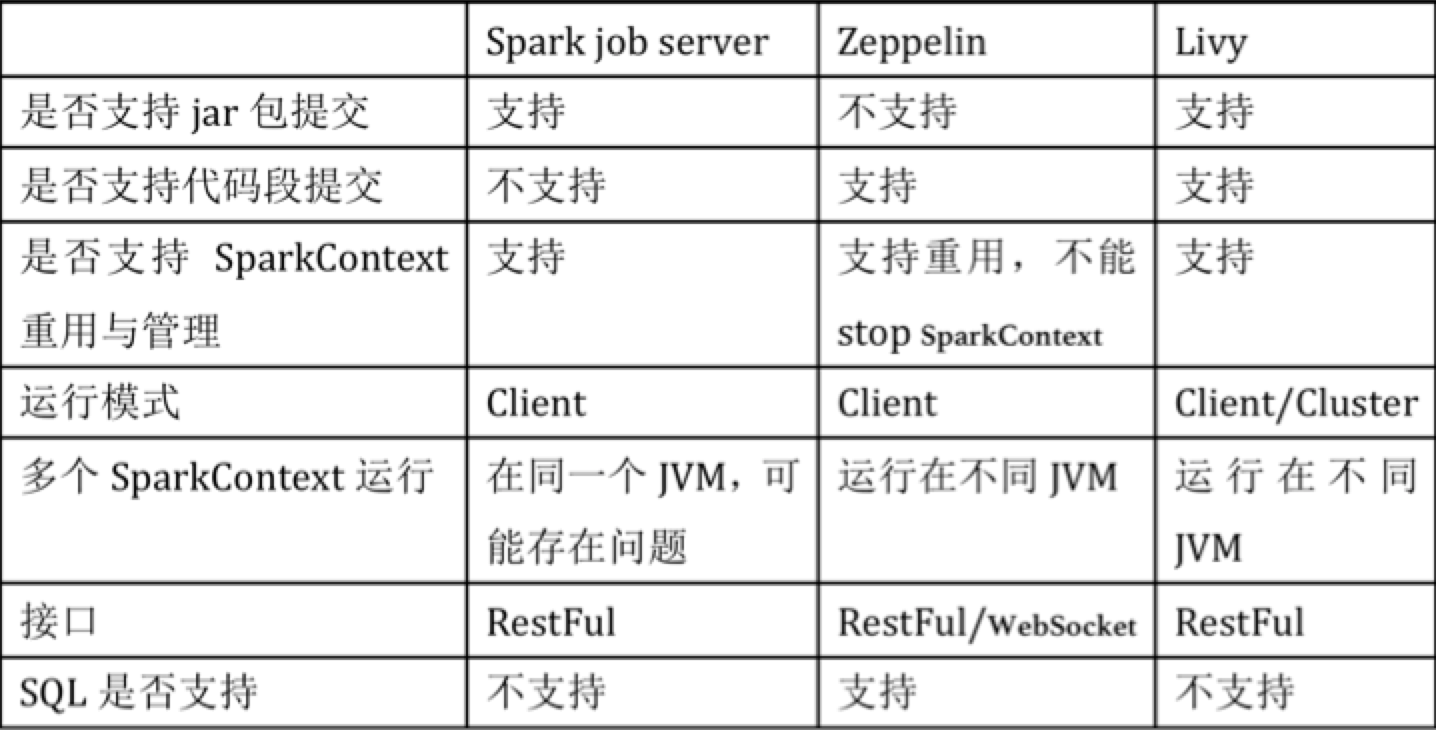
当前spark上的管控平台有spark job server,zeppelin,由于spark job server和zeppelin都存在一些缺陷,比如spark job server不支持提交sql,zeppelin不支持jar包方式提交,并且它们都不支持yarn cluster模式,只能以client的模式运行,这会严重影响扩展性。针对这些问题,cloudera研发了Livy,Livy结合了spark job server和Zeppelin的优点,并解决了spark job server和Zeppelin的缺点,下面是他们的对比。
Livy的三套接口
Livy提供三套管理任务的接口分别是:
(1) 使用Using the Programmatic API,通过程序接口提交作业。
a) 需要继承com.cloudera.livy.Job接口编程,通过LivyClient提交
(2) 使用RestAPI的session接口提交代码段方式运行
(3) 使用RestAPI的batch接口提交jar包方式运行
更详细的API文档可以参考链接:https://github.com/cloudera/livy#prerequisites
Livy执行作业流程
下面这幅图片是Livy的基本原理,客户端提交任务到Livy server后,Livy server启动相应的session,然后提交作业到Yarn集群,当Yarn拉起ApplicationMaster进程后启动SparkContext,并连接到Livy Server进行通信。后续执行的代码会通过Livy server发送到Application进程执行。

(图片摘自livy社区)
下面是源码级别的详细的执行流程:
a.live-server启动,启动BatchSessionManager, InteractiveSessionManager。
b.初始化WebServer,通过ServletContextListener启动InteractiveSessionServlet和BatchSessionServlet。
c.通过http调用SessionServlet的createSession接口,创建session并注册到sessionManager,InteractiveSession和BatchSession会创建SparkYarnApp,SparkYarnApp负责启动Spark作业,并维护yarnclient,获取作业信息、状态或kill作业。
d. BatchSession是以jar包的方式提交作业,运行结束后session作业就结束。
e. InteractiveSession会启动com.cloudera.livy.repl.ReplDriver,ReplDriver继承RSCDriver,初始化期间会通过RPC连接到livy-server,并启动RpcServer;其次会初始化Interpreter(支持PythonInterpreter,SparkInterpreter,SparkRInterpreter)。接收来自livy-server,并启动RpcServer;其次会初始化Interpreter(支持PythonInterpreter,SparkInterpreter,SparkRInterpreter)。接收来自livy-server的信息(代码),然后通过Interpreter执行,livy-server通过RPC请求作业结果。
Livy 还存在的问题
Livy是当前spark上最好的管控平台, 即使不使用Livy,也可以借鉴Livy的设计思路。当然Livy当前还没完全成熟,下面列举了几个待完善的点,社区也在开发过程中,希望Livy后续变得更加完善。
1. 不支持提交SQL https://issues.cloudera.org/browse/LIVY-19
2. session,app信息都维护在livy-server,livy-server挂掉信息丢失,需要HA。
3. livy-server的性能如何,能并行多少session。
4. 多个livy-server如何管理?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号