

Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理)
Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理)
http://xiguada.org/spark-shuffle-direct-buffer-oom/
问题描述
Spark-1.6.0已经在一月份release,为了验证一下它的性能,我使用了一些大的SQL验证其性能,其中部分SQL出现了Shuffle失败问题,详细的堆栈信息如下所示:
16/02/17 15:36:36 WARN server.TransportChannelHandler: Exception in connection from /10.196.134.220:7337
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306)
at io.netty.buffer.PoolArena$DirectArena.newChunk(PoolArena.java:645)
at io.netty.buffer.PoolArena.allocateNormal(PoolArena.java:228)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:212)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:132)
at io.netty.buffer.PooledByteBufAllocator.newDirectBuffer(PooledByteBufAllocator.java:271)
at io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:155)
at io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:146)
at io.netty.buffer.AbstractByteBufAllocator.ioBuffer(AbstractByteBufAllocator.java:107)
at io.netty.channel.AdaptiveRecvByteBufAllocator$HandleImpl.allocate(AdaptiveRecvByteBufAllocator.java:104)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:117)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:511)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:468)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:382)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111)
at java.lang.Thread.run(Thread.java:744)
从失败信息可以看出,是堆外内存溢出问题,为什么会出现堆外内存溢出呢?
Spark的shuffle部分使用了netty框架进行网络传输,但netty会申请堆外内存缓存(PooledByteBufAllocator ,AbstractByteBufAllocator);Shuffle时,每个Reduce都需要获取每个map对应的输出,当一个reduce需要获取的一个map数据比较大(比如1G),这时候就会申请一个1G的堆外内存,而堆外内存是有限制的,这时候就出现了堆外内存溢出。
Shuffle不使用堆外内存
为Executor增加配置-Dio.netty.noUnsafe=true,就可以让shuffle不使用堆外内存,但相同的作业还是出现了OOM,这种方式没办法解决问题。
java.lang.OutOfMemoryError: Java heap space
at io.netty.buffer.PoolArena$HeapArena.newUnpooledChunk(PoolArena.java:607)
at io.netty.buffer.PoolArena.allocateHuge(PoolArena.java:237)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:215)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:132)
at io.netty.buffer.PooledByteBufAllocator.newHeapBuffer(PooledByteBufAllocator.java:256)
at io.netty.buffer.AbstractByteBufAllocator.heapBuffer(AbstractByteBufAllocator.java:136)
at io.netty.buffer.AbstractByteBufAllocator.heapBuffer(AbstractByteBufAllocator.java:127)
at io.netty.buffer.CompositeByteBuf.allocBuffer(CompositeByteBuf.java:1347)
at io.netty.buffer.CompositeByteBuf.consolidateIfNeeded(CompositeByteBuf.java:276)
at io.netty.buffer.CompositeByteBuf.addComponent(CompositeByteBuf.java:116)
at org.apache.spark.network.util.TransportFrameDecoder.decodeNext(TransportFrameDecoder.java:148)
at org.apache.spark.network.util.TransportFrameDecoder.channelRead(TransportFrameDecoder.java:82)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:308)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:294)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:846)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:131)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:511)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:468)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:382)
当数据量大时能否直接写磁盘
MapReduce中Shuffle数据量大时,会把Shuffle数据写到磁盘。
Spark Shuffle通信机制
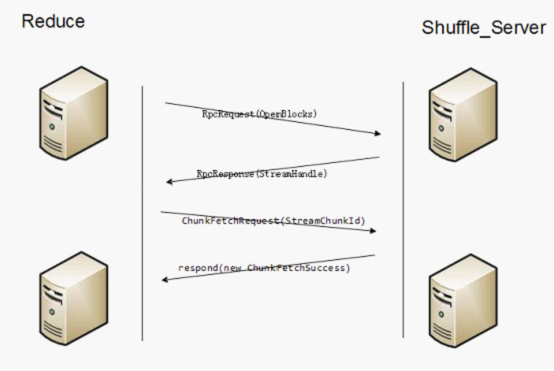
上图显示了Shuffle的通信原理。
服务端会启动Shuffle_Service。
(1)客户端代码调用堆栈
BlockStoreShuffleReader.read
ShuffleBlockFetcherIterator.sendRequest
ExternalShuffleClient.fetchBlocks
OneForOneBlockFetcher.start
TransportClient.sendRpc
发送RpcRequest(OpenBlocks)信息
(2)服务端代码调用堆栈
TransportRequestHandler.processRpcRequest
ExternalShuffleBlockHandler.receive
ExternalShuffleBlockHandler.handleMessage
ExternalShuffleBlockResolver.getBlockData(shuffle_ShuffleId_MapId_ReduceId)
ExternalShuffleBlockResolver.getSortBasedShuffleBlockData
FileSegmentManagedBuffer
handleMessage会把所需的appid的一个executor需要被fetch的block全部封装成List<ManagedBuffer>,然后注册为一个Stream,然后把streamId和blockid的个数返回给客户端,最后返回给客户端的信息为RpcResponse(StreamHandle(streamId, msg.blockIds.length))。
(3)客户端
客户端接收到RpcResponse后,会为每个blockid调用:
TransportClient.fetchChunk
Send ChunkFetchRequest(StreamChunkId(streamId, chunkIndex))
(4)服务端
TransportRequestHandler.processFetchRequest
OneForOneStreamManager.getChunk
返回respond(new ChunkFetchSuccess(req.streamChunkId, buf))给客户端,buf就是某一个blockid的FileSegmentManagedBuffer。
(5)客户端
OneForOneBlockFetcher.ChunkCallback.onSuccess
listener.onBlockFetchSuccess(blockIds[chunkIndex], buffer)
ShuffleBlockFetcherIterator.sendRequest.BlockFetchingListener.onBlockFetchSuccess
results.put(new SuccessFetchResult(BlockId(blockId), address, sizeMap(blockId), buf))
客户端的另外一个线程
ShuffleBlockFetcherIterator.next
(result.blockId, new BufferReleasingInputStream(buf.createInputStream(), this))
Download文件的通信原理
另外还有一个stream通信协议,客户端首先需要构造StreamRequest请求,StreamRequest中包含待下载文件的URL。
(1)客户端调用堆栈
Executor.updateDependencies...
org.apache.spark.util.Utils.fetchFile
org.apache.spark.util.Utils.doFetchFile
NettyRpcEnv.openChannel
TransportClient.stream
Send StreamRequest(streamId) streamId为文件的目录。
(2)服务端处理流程
TransportRequestHandler.handle
TransportRequestHandler.processStreamRequest
OneForOneStreamManager.openStream
返回new StreamResponse(req.streamId, buf.size(), buf)
(3)客户端处理流程
TransportResponseHandler.handle
TransportFrameDecoder.channelRead
TransportFrameDecoder.feedInterceptor
StreamInterceptor.handle
callback.onData即NettyRpcEnv.FileDownloadCallback.onData
然后返回client.stream(parsedUri.getPath(), callback)给Utils.doFetchFile,最后org.apache.spark.util.Utils.downloadFile
问题分析:
当前spark shuffle时使用Fetch协议,由于使用堆外内存存储Fetch的数据,当Fetch某个map的数据特别大时,容易出现堆外内存的OOM。而申请内存部分在Netty自带的代码中,我们无法修改。
另外一方面,Stream是下载文件的协议,需要提供文件的URL,而Shuffle只会获取文件中的一段数据,并且也不知道URL,因此不能直接使用Stream接口。
解决方案:
新增一个FetchStream通信协议,在OneForOneBlockFetcher中,如果一个block小于100M(spark.shuffle.max.block.size.inmemory)时,使用原有的方式Fetch数据,如果大于100M时,则使用新增的FetchStream协议,服务端在处理FetchStreamRequest和FetchRequest的区别在于,FetchStreamRequest返回数据流,客户端根据返回的数据量写到本地临时文件,然后构造FileSegmentManagedBuffer给后续处理流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号