

Spark架构与作业执行流程简介
Spark架构与作业执行流程简介
Local模式
运行Spark最简单的方法是通过Local模式(即伪分布式模式)。
运行命令为:./bin/run-example org.apache.spark.examples.SparkPi local
基于standalone的Spark架构与作业执行流程
Standalone模式下,集群启动时包括Master与Worker,其中Master负责接收客户端提交的作业,管理Worker。提供了Web展示集群与作业信息。
名词解释:
1. Standalone模式下存在的角色。
Client:客户端进程,负责提交作业到Master。
Master:Standalone模式中主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
Worker:Standalone模式中slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
Driver: 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
Executor:即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
2.作业相关的名词解释
Stage:一个Spark作业一般包含一到多个Stage。
Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。
DAGScheduler: 实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
TaskScheduler:实现Task分配到Executor上执行。
提交作业有两种方式,分别是Driver(作业的master,负责作业的解析、生成stage并调度task到,包含DAGScheduler)运行在Worker上,Driver运行在客户端。接下来分别介绍两种方式的作业运行原理。
Driver运行在Worker上
通过org.apache.spark.deploy.Client类执行作业,作业运行命令如下:
./bin/spark-class org.apache.spark.deploy.Client launch spark://host:port file:///jar_url org.apache.spark.examples.SparkPi spark://host:port
作业执行流如图1所示。

图1
作业执行流程描述:
-
客户端提交作业给Master
-
Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。
-
另外Master还会让其余Worker启动Exeuctor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
-
ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序,生成执行计划,并调度执行。对于每个stage的task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报的时候把TaskScheduler中的task调度到ExecutorBackend执行。
-
所有stage都完成后作业结束。
Driver运行在客户端
直接执行Spark作业,作业运行命令如下(示例):
./bin/run-example org.apache.spark.examples.SparkPi spark://host:port
作业执行流如图2所示。
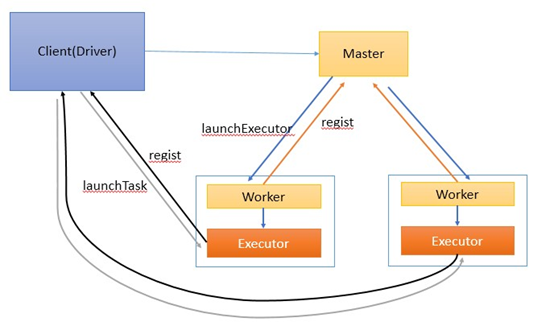
图2
作业执行流程描述:
-
客户端启动后直接运行用户程序,启动Driver相关的工作:DAGScheduler和BlockManagerMaster等。
-
客户端的Driver向Master注册。
-
Master还会让Worker启动Exeuctor。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
-
ExecutorBackend启动后会向Driver的SchedulerBackend注册。Driver的DAGScheduler解析作业并生成相应的Stage,每个Stage包含的Task通过TaskScheduler分配给Executor执行。
-
所有stage都完成后作业结束。
基于Yarn的Spark架构与作业执行流程

这里Spark AppMaster相当于Standalone模式下的SchedulerBackend,Executor相当于standalone的ExecutorBackend,spark AppMaster中包括DAGScheduler和YarnClusterScheduler。
Spark on Yarn的执行流程可以参考http://www.csdn.net/article/2013-12-04/2817706--YARN spark on Yarn部分。
这里主要介绍一下Spark ApplicationMaster的主要工作。代码参考Apache Spark 0.9.0版本ApplicationMaster.scala中的run()方法。
步骤如下:
- 设置环境变量spark.local.dir和spark.ui.port。NodeManager启动ApplicationMaster的时候会传递LOCAL_DIRS(YARN_LOCAL_DIRS)变量,这个变量会被设置为spark.local.dir的值。后续临时文件会存放在此目录下。
- 获取NodeManager传递给ApplicationMaster的appAttemptId。
- 创建AMRMClient,即ApplicationMaster与ResourceManager的通信连接。
- 启动用户程序,startUserClass(),使用一个线程通过发射调用用户程序的main方法。这时候,用户程序中会初始化SparkContext,它包含DAGScheduler和TaskScheduler。
- 向ResourceManager注册。
- 向ResourceManager申请containers,它根据输入数据和请求的资源,调度Executor到相应的NodeManager上,这里的调度算法会考虑输入数据的locality。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号