pandas 操作mysql详解
Pandas读写MySQL数据库
要实现 pandas 对 mysql 的读写需要三个库
- pandas
- sqlalchemy
- pymysql
可能有的同学会问,单独用 pymysql 或 sqlalchemy 来读写数据库不香么,为什么要同时用三个库?主要是使用场景不同,个人觉得就大数据处理而言,用 pandas 读写数据库更加便捷。
1、read_sql 读取 mysql
read_sql_query 或 read_sql 方法传入参数为 sql 语句,读取数据库后,返回内容是 dateframe 对象,read_sql 方法相当于 read_sql_query + read_sql_query,所以一般推荐 read_sql。普及一下:dateframe 其实也是一种数据结构,类似 excel 表格一样。
import pandas from sqlalchemy import create_engine class mysqlconn: def __init__(self): mysql_username = 'root' mysql_password = '123456' # 填写真实数库ip mysql_ip = 'x.x.x.x' port = 3306 db = 'work' # 初始化数据库连接,使用pymysql库 self.engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(mysql_username, mysql_password, mysql_ip, port,db)) # 查询mysql数据库 def query(self,sql): df = pandas.read_sql(sql,self.engine) # df = pandas.read_sql_query(sql,self.engine) 这种读取方式也可以 # 返回dateframe格式 return df if __name__ =='__main__': # 查询的 sql 语句 SQL = '''select * from working_time order by id desc ''' # 调用 mysqlconn 类的 query() 方法 df_data = mysqlconn().query(sql=SQL)
2、read_sql + ORM 读取 mysql
如果不写sql语句,也可以通过 ORM(对象关系映射)读取,这种方式需要花点时间学习下 ORM 。例如查找 working 表中 name、nickname、department、groupName:
...
sql_orm = db.session.query(worktime.name,worktime.nickname,worktime.department,worktime.groupName).order_by(worktime.date.desc()).limit(5).statement
df_data = pandas.read_sql(sql = sql_orm,con = db.get_engine())
...3、to_sql 写入数据库
使用 to_sql 方法写入数据库之前,先把数据转化成 dateframe 。
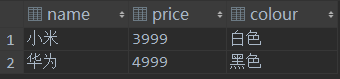
import pandas from sqlalchemy import create_engine class mysqlconn: def __init__(self): mysql_username = 'root' mysql_password = '123456' # 填写真实数库ip mysql_ip = 'mysql.mall.svc.test.local' port = 3306 db = 'work' # 初始化数据库连接,使用pymysql库 self.engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(mysql_username, mysql_password, mysql_ip, port,db)) # 查询mysql数据库 def query(self,sql): df = pandas.read_sql_query(sql,self.engine) # df = pandas.read_sql(sql,self.engine) # 返回dateframe格式 return df # 写入mysql数据库 def to_sql(self,table,df): # 第一个参数是表名 # if_exists:有三个值 fail、replace、append # 1.fail:如果表存在,啥也不做 # 2.replace:如果表存在,删了表,再建立一个新表,把数据插入 # 3.append:如果表存在,把数据插入,如果表不存在创建一个表!! # index 是否储存index列 df.to_sql(table, con=self.engine, if_exists='append', index=False) if __name__ =='__main__': # 创建 dateframe 对象 df = pandas.DataFrame([{'name':'小米','price':'3999','colour':'白色'},{'name':'华为','price':'4999','colour':'黑色'}]) # 调用 mysqlconn 类的 to_sql() 方法 mysqlconn().to_sql('phonetest',df)
插入数据库的数据:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号