
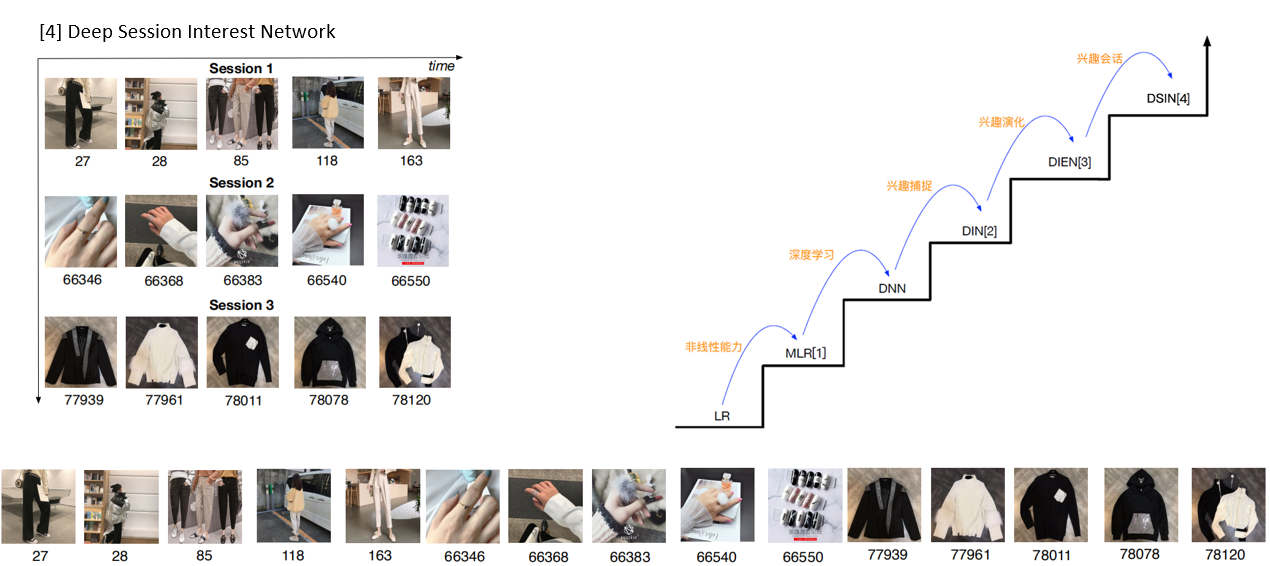
深度兴趣网络DIN| DIEN| DSIN| 注意力机制attention
淘宝定向广告演化
电商定向广告(给不同人看不同广告 - 广告推荐) VS 搜索广告
- 用户没有很明显的意图(主动的Query查询)
- 用户来到淘宝之前,自己也没有特别明确的目标(利用以往的历史行为 => item推荐)
- p(y=1 | ad, context, user); ad 表示广告候选集; user 表示用户特征,年龄、性别; context 表示上下文场景,设备,时间
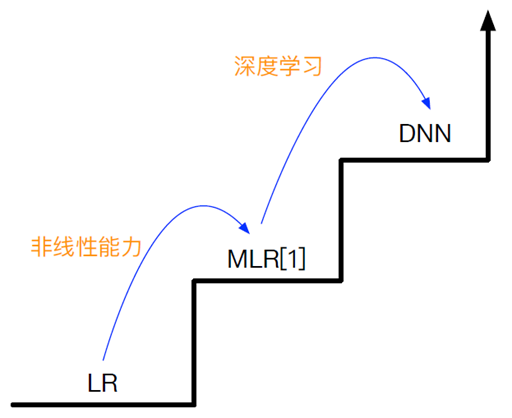
LR模型(线性模型)
- LR模型 + 人工特征,LR模型不能处理非线性特征,所以需要特征工程去加入非线性特征
[1] MLR模型(非线性模型)
- Mixed Logistic Regression,混合逻辑回归,
- 采用分而治之的策略,用分段线性+级联,拟合高维空间的非线性分类面,相比于人工来说提升了效率和精度
- https://arxiv.org/abs/1704.05194v1
DNN模型(深度学习)
- 能使用GPU,处理复杂模型和大数据量
DNN适用的场景:数据量 大于百万千万,内在特征的逻辑是否清晰;
DNN模型
DNN需要考虑用户特征属性,Pooling池化 统一维度(不管你看了多少个商品都把它看作一个,可理解为降维); DNN(x1, x2....x100) = y' ; Softmax 作归一化处理 二分类任务;
Sum Pooling 做加和处理
优势:处理复杂模型和大数据量
不足:试图用定长embedding表达用户多种多样的兴趣
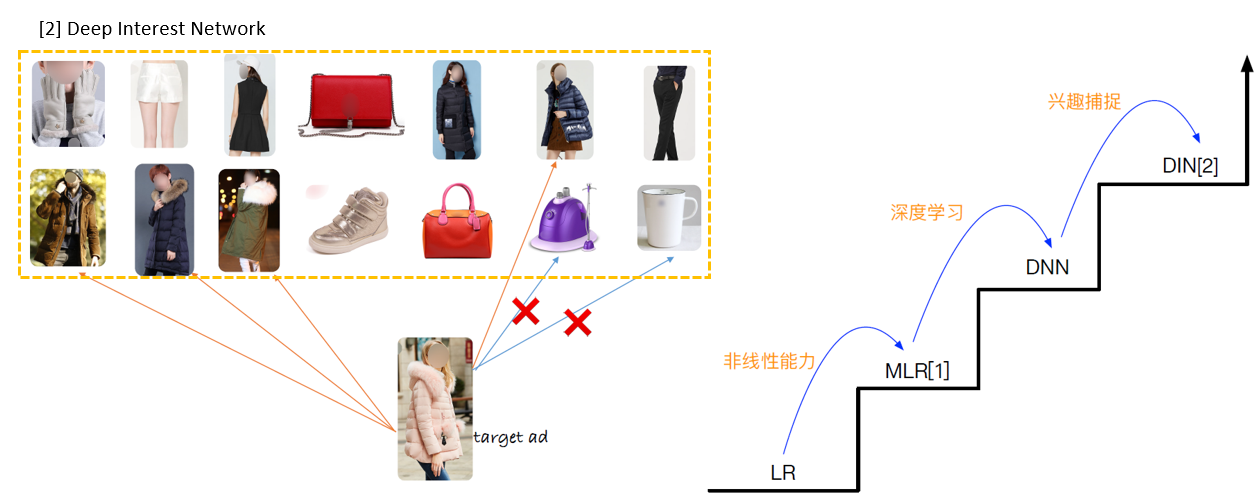
对用户历史行为的洞察:
- Diversity,多样性,一个用户可以对多种品类的东西感兴趣
- Local Activation,局部激活,只有部分历史行为对目前的点击预测有帮助
attention 找到以前看过哪些商品,根据这些商品来决定是否喜欢;
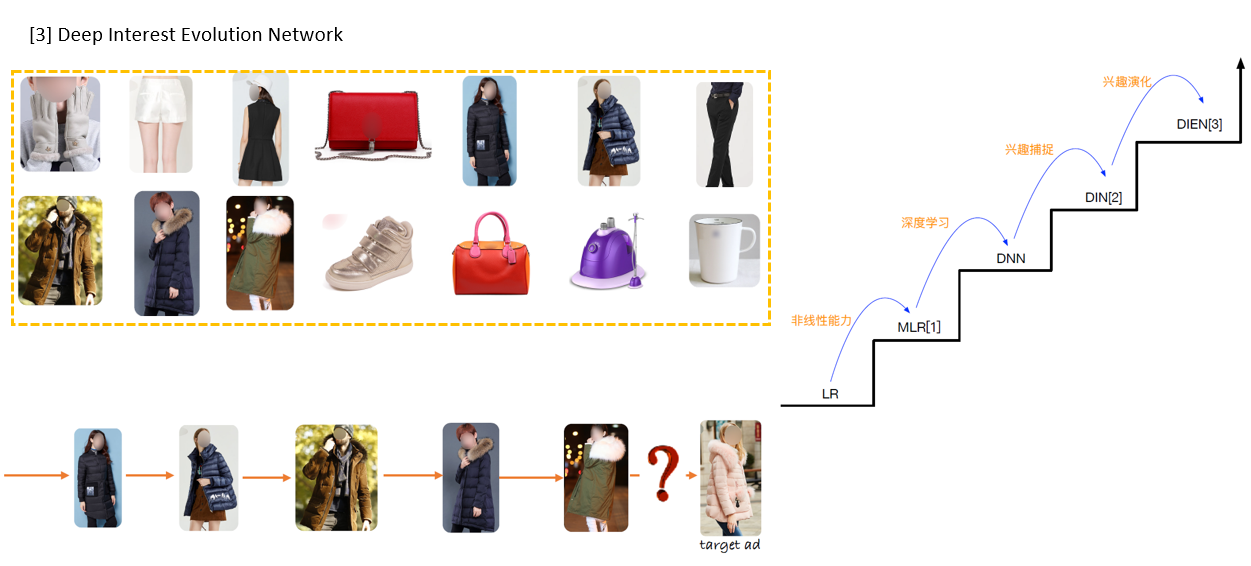
Motivation:
- 综合序列随机跳转多,没有规律,噪音大
- 具体到某个兴趣,存在随时间逐渐演化的趋势
兴趣也会发生变化,DIEN加了兴趣演化;
Motivation:
- 将用户行为序列看成多个会话
- 会话内相近,会话与会话之间差别大
DSIN 用户兴趣session的切分;断句,把相同的放在一块;
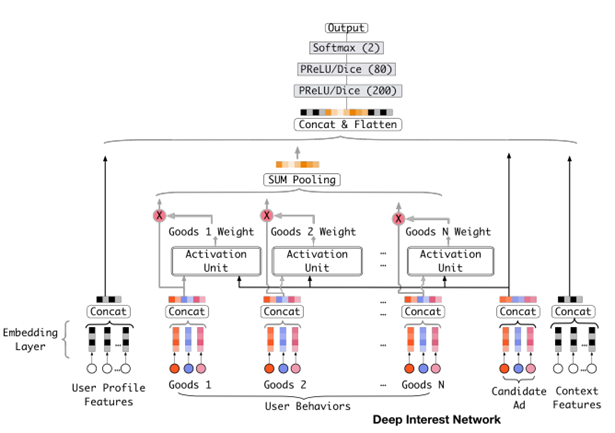
深度兴趣网络DIN
阿里深度兴趣网络DIN
- Deep Interest Network for Click-Through Rate Prediction,2018
- DIN论文: https://arxiv.org/abs/1706.06978
解决的问题:
- CTR预估,根据给定广告、用户和上下文情况等信息,对每次广告的点击情况做出预测
对用户历史行为的洞察:
- Diversity,多样性,一个用户可以对多种品类的东西感兴趣
- Local Activation,局部激活,只有一部分的历史数据对目前的点击预测有帮助,比如系统向用户推荐泳镜时会和用户点击过的泳衣产生关联,和用户买的书关系不大
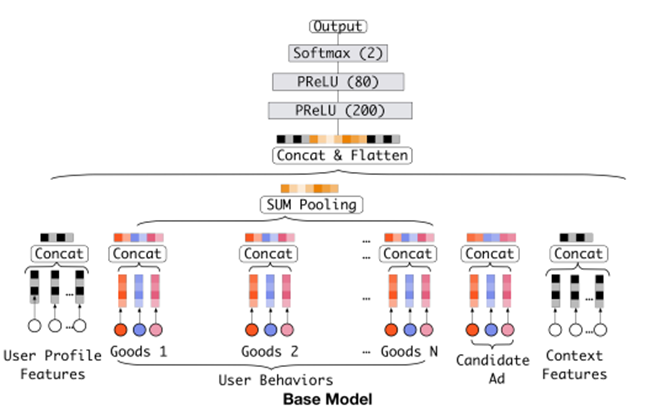
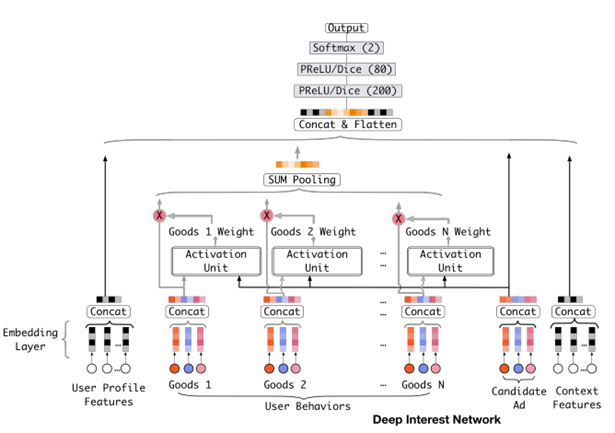
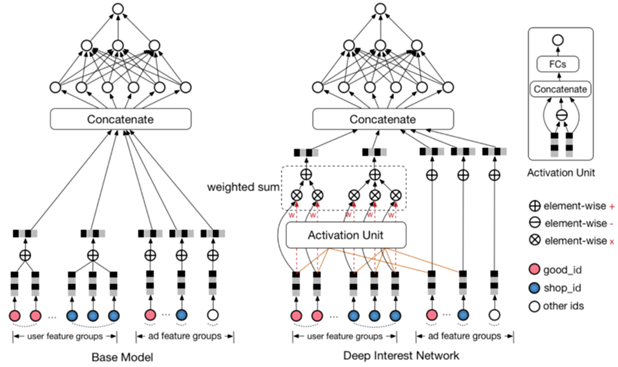
Base Model(传统的DNN模型):
- embedding+MLP
- Step1,将不同的特征转换为对应的embedding表示
- Step2,将所有特征的embedding做拼接
- Step3,输入到多层感知机MLP(DNN),计算结果
特征表示:
- user profile、user behavior、ad 以及 context
- 每个特征类别包括多个feature field
- feature field是单值特征 => one-hot编码 (标签特征唯一的编码)
- feature field是多值特征 => multi-hot编码
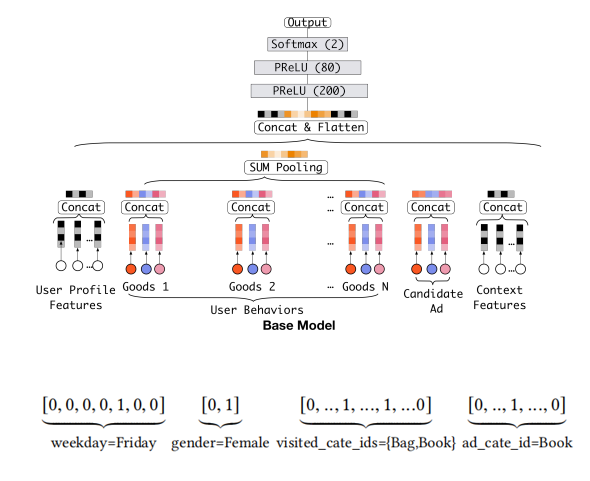
Base Model(传统的DNN模型):
- Embedding Layer,将高维稀疏向量转换为低维稠密向量
- Pooling Layer + Concat Layer,使用Pooling解决每个用户行为 的维度不同的问题,并与其他三个类别中的embedding结果进行拼接,作为MLP Layer的输入
- MLP Layer,学习给到的拼接embedding,自动学习高阶特征之间的组合
- Loss,损失函数采用negative log-likelihood loss
-
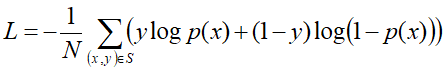
S代表训练样本的个数,x是网络的输入,y是{0, 1}样本标签,
p(x)代表输入x的预估点击概率
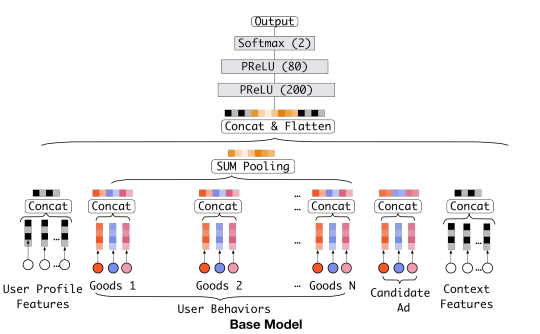
Base Model的不足:
针对电商场景中,用户的兴趣是多样的,可能在一段时间内点击过衣服,电子产品,鞋子等。
对于不同的candidate来说,浏览过的相关商品对于预测帮助更大,不相关的商品对于CTR预估并不起作用,比如用户看过的iphone,鞋子对于衣服的预测没有帮助
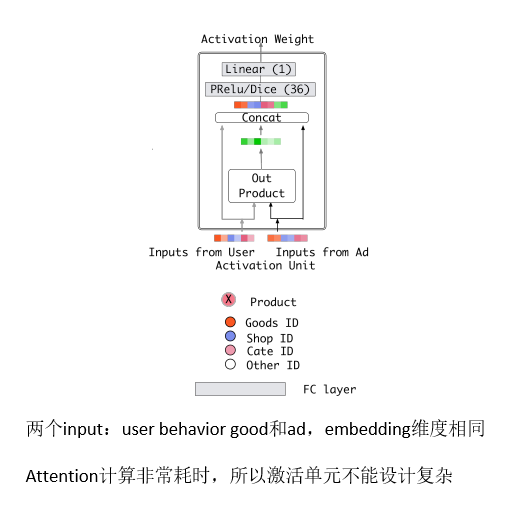
Attention机制
在对用户行为的embedding计算上引入了attention network (也称为Activation Unit)
把用户历史行为特征进行embedding操作,视为对用户兴趣的表示,之后通过Attention Unit,对每个兴趣表示赋予不同的权值
Attention Weight是由用户历史行为和候选广告进行匹配计算得到的,对应着洞察(用户兴趣的Diversity,以及Local Activation)
Condidate Ad 和 Goods 1 结合 组成 Activation Unit 激活单元, 注意力 Goods 1 Weight ,也就是计算它的相似度;
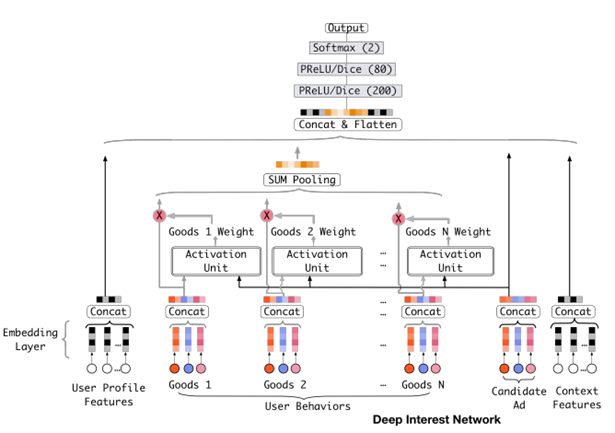
Attention机制:
- Attention思想:在pooling的时候,与 candidate Ad 相关的商品权重大一些,与candidate Ad 不相关的商品权重小一些
- Attention分数,将candidate Ad与历史行为的每个商品发生交互来计算
- Activation Unit输出Activation Weight,输入包括用户行为embedding和候选广告embedding以外,还考虑了他们两个的外积。对于不同的candidate ad,得到的用户行为表示向量也不同
- {e1, e2, ..., eH}表示用户U的行为embedding向量, 表示候选广告A的embedding向量, 对于不同的广告得到的表示向量不同
-
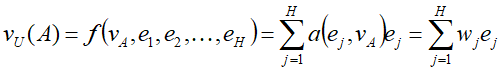
a(.) 是前馈神经网络,得到的结果是激活权重(activation weight)
用户输入和 商品,
Attention机制:
- α(.) 不对点击序列的Attention分数做归一化,直接将分数与对应商品的embedding向量做加权和,目的在于保留用户的兴趣强度
- 比如,用户的点击序列中90%是衣服,10%是电子产品,有两个候选ad(T恤和手机),T恤的候选ad 激活属于衣服和衣服的大部分历史行为会比手机获得更大的兴趣强度
- 用SoftMax不能体现用户的行为强度,比如90%时间看衣服,10%看电子产品
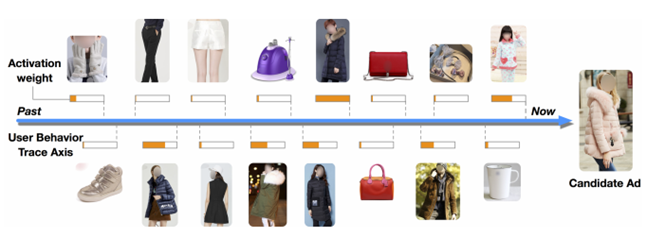
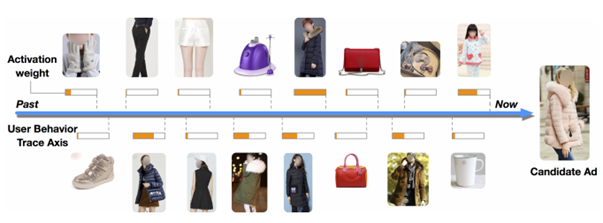
Attention Weight可视化结果:
评价指标
- 对评价指标AUC进行改进
- AUC广泛在CTR场景中使用,含义是正样本得分比负样本得分高的概率,以往的评价指标是对样本不区分用户地进行AUC计算
- 改进的AUC,不是将所有用户的正负样本在一起计算,而是对于每个用户单独计算自身的AUC,并根据其自身的行为数量(如点击)进行加权处理
-
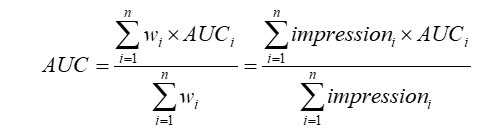
计算了用户级别的AUC,按展示次数进行加权,消除了用户偏差对模型评价的影响,更准确地描述了模型对于每个用户的表现效果;
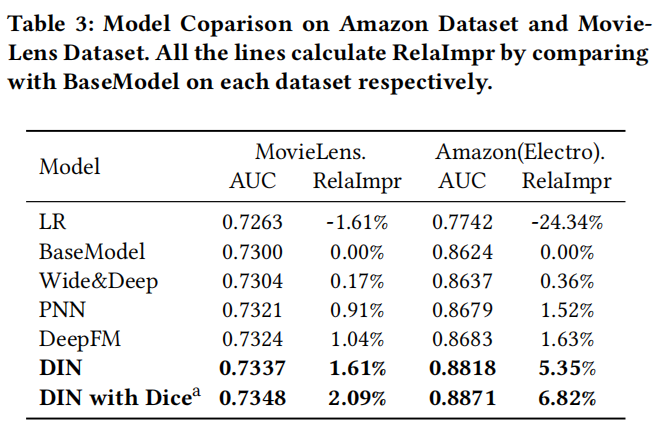
评价指标:
- 评价指标RelaImpr 相对提升度;

RelaImpr代表相对于based model的相对改进指标,对于随机猜测的话,值AUC是0.5
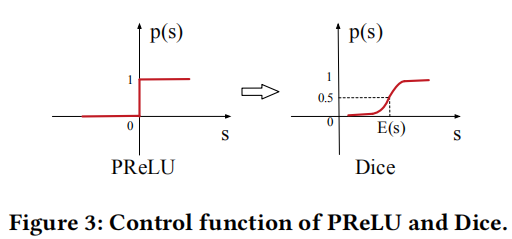
激活函数Dice
- 激活函数PReLU,Data Adaptive Activation Function(基于数据的自适应激活函数)
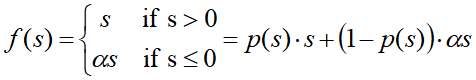
- Dice函数是对PReLU进行改进,应用于阿里妈妈
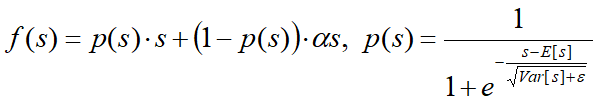
Dice函数引入了输入数据的统计信息;
E[s]和 Var[s] 表示输入数据的每一个mini-batch的平均值和方差;
在工程中,设置 ε = 10-8 ,Dice是PReLU的一种泛化形式,根据输入数据分布的不同,自适应变化。当E[s]=0, Var[s]=0的时候,Dice退化为PReLU
L2正则的问题
- 在淘宝中有很多商品,大约有6亿ID,Embedding layer参数量巨大
- 直接使用L2 norm计算量过大,每一步迭代都需要更新所有参数
MBA-Reg正则:
- 自适应正则,mini-batch aware regularization
- MBA-Reg 不是新的正则,为了工业场景专门定制
- MBA-Reg将L2-norm 推广到样本层面,每一步迭代只计算样本相关参数
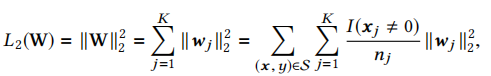
样本有K个特征,wj 代表第 j 个向量,I(xj<>0)代表了样本有 j 这个特征的个数,nj 代表了在整个样本中 j 特征的出现次数
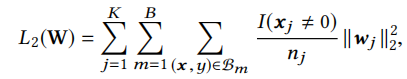
样本分成了B个batch,在每个mini-batch上看I(xj<>0)的个数,然后累加
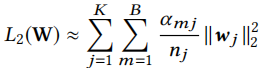
αmj= max(x,y)∈Bm,不需要求具体个数,只看有没有
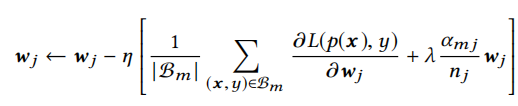
nj代表了特征 j 出现的频率,该正则项惩罚了出现频率低的item,取得了不错的效果
使用不同正则方式后的效果
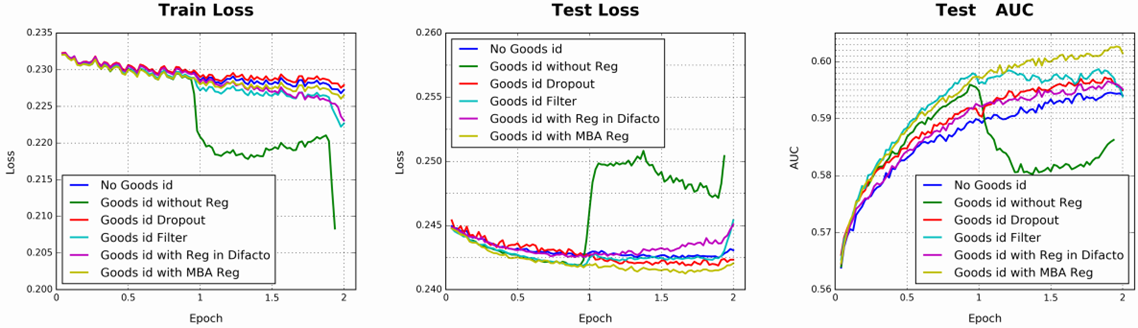
阿里巴巴数据集中,使用BaseModel采用不同的正则方式,取得的效果对比,采用自适应正则,MBA Reg(mini-batch aware regularization)效果最好

DIN 分析结果
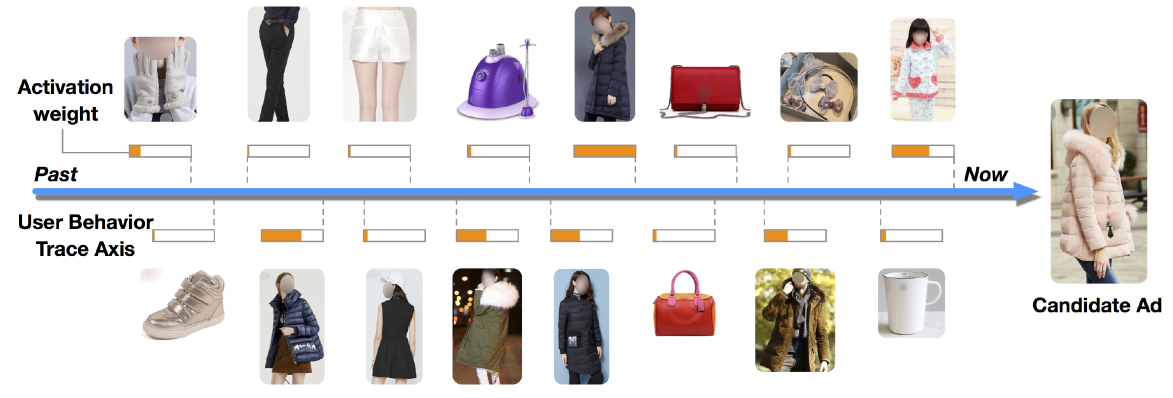
- 局部激活效果:与候选广告越相关的行为的attention分数越高
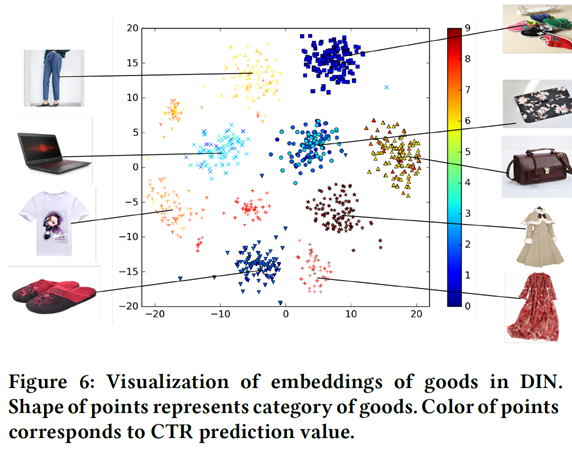
特征编码:针对年轻的妈妈提供9类商品,每类有100件,聚类效果明显,同时能捕捉用户的多维度兴趣分布(红色CTR最高,蓝色最低)
线上A/B Test效果
- CTR : 点击率
- CVR : 展示广告购买情况,商家关注的指标
- GPM : 平均1000次展示,平均成交金额的比例

DIN Summary
基于用户历史行为的数据洞察 => Diversity 和 Local Activation
主要思想是在对用户兴趣的表示上引入了attention机制,即对用户的每个兴趣表示赋予不同的权值,这个权值是由用户的兴趣和待估算的广告进行匹配计算得到的
DIN模型在工程上进行了改进,Dice激活函数,自适应正则,以及改进的AUC评价指标,为模型效果和评估带来了提升
深度兴趣进化网络DIEN
- Deep Interest Evolution Network for Click-Through Rate Prediction,2018
- https://arxiv.org/abs/1809.03672
DIN的不足:
- 利用用户行为序列特征,直接把用户历史行为当做兴趣
- 直接用行为表示兴趣可能存在问题。因为行为是序列化产生的,行为之间存在依赖关系,比如当前时刻的兴趣往往直接导致了下一行为的发生
- 用户的兴趣是不断进化的,而DIN抽取的用户兴趣之间是独立无关联的,没有捕获到兴趣的动态进化性,比如用户对衣服的喜好,会随季节、时尚风潮以及个人品味的变化而变化,呈现一种连续的变迁趋势。
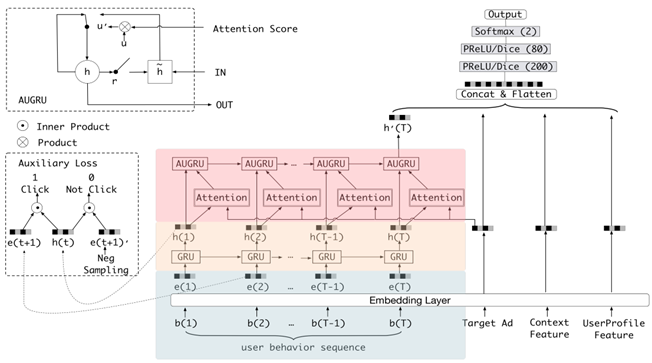
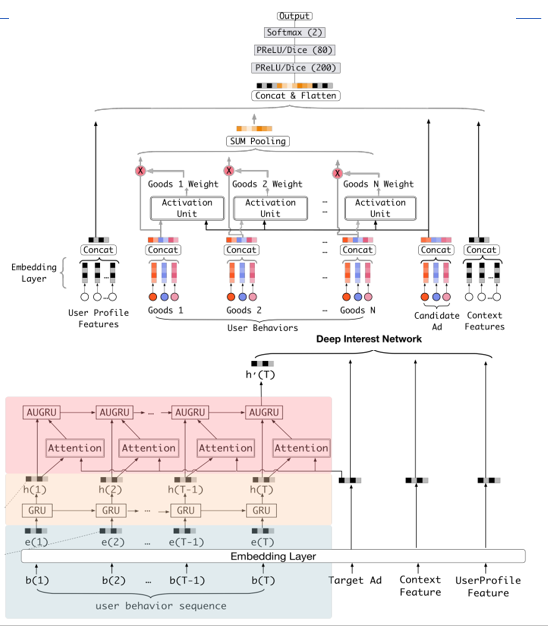
DIEN结构:
- 输入层,user profile,ad,context这三类特征的低维嵌入向量的学习(与base model处理相同)
- 使用behavior layer,interest extractor layer 以及 interest evolving layer从用户历史行为中挖掘用户与目标商品相关的兴趣及演变
- 目标损失函数,采用负对数似然(negative log-likelihood loss )
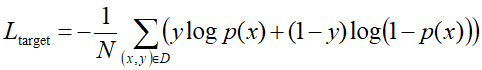
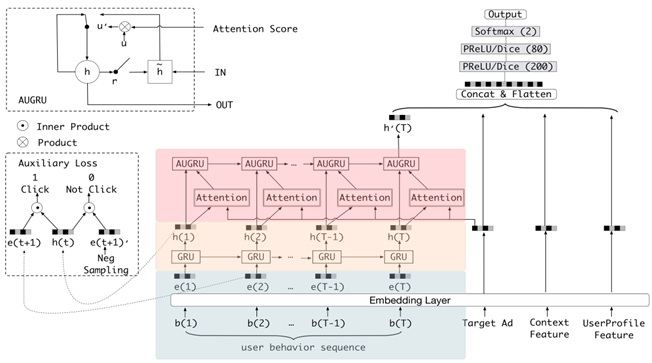
P(x)对应的是网络的输出
DIEN结构:
- 通过引入序列模型 AUGRU 模拟了用户兴趣进化的过程
- 在 Embedding layer 和 Concatenate layer 之间加入了生成兴趣的 Interest Extractor Layer 和模拟兴趣演化的 Interest Evolving layer
- Interest Extractor Layer 使用了GRU的结构抽取了每一个时间片内用户的兴趣
- Interest Evolving layer 利用序列模型 AUGRU 的结构将不同时间的用户兴趣串联起来,形成兴趣进化的链条
- 最终把当前时刻的“兴趣向量”输入上层的多层全连接网络,与其他特征一起进行最终的 CTR 预估
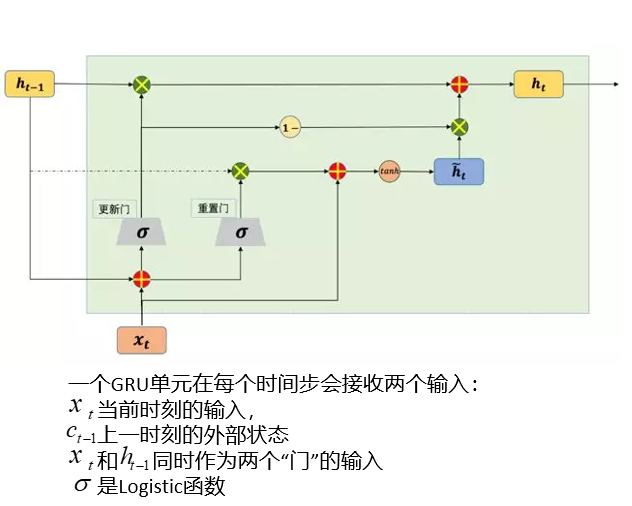
初识GRU:
- Gated Recurrent Unit,门控循环单元
- GRU模型,只有两个门即更新门和重置门
- 将LSTM中的输入门和遗忘门合并成了一个门,称为更新门(update gate)
- 没有LSTM中的内部状态和外部状态的划分,而是通过直接在当前网络的状态和上一时刻网络的状态之间添加一个线性的依赖关系,来解决梯度消失和梯度爆炸的问题
- GRU是LSTM的一种变体,相比于LSTM网络结构更加简单,速度快,能避免 RNN 中的梯度消失,解决RNN网络中的长依赖问题
初识LSTM
- LSTM,Long Short-Term Memory,长短记忆网络
- 可以避免常规RNN的梯度消失,在工业界有广泛应用
- 引入了三个门函数:输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)来控制输入值、记忆值和输出值
- 输入门决定了当前时刻网络的状态有多少信息需要保存到内部状态中,遗忘门决定了过去的状态信息有多少需要丢弃 => 输入门和遗忘门是LSTM能够记忆长期依赖的关键
- 输出门决定当前时刻的内部状态有多少信息需要输出给外部状态。
GRU和LSTM的作用:
- 使用GRU/LSTM对用户行为依赖进行建模,GRU的输入是当前时刻的顺序行为
- LSTM和GRU都能通过各种Gate将重要特征保留,保证其在long-term 传播时也不会被丢失
- LSTM算法性能稍优于GRU算法,但是GRU模型的参数比LSTM更少,因此训练速度更快,更适合用于电子商务系统
- Step1,user behavior sequence => Embedding {e1, e2, ... eT}
- Step2,对于每一个时刻e(i)通过GRU对用户行为序列进行建模,得到interest state h(i)
- Step3,将h(i)传给兴趣抽取层(Interest Extractor Layer)
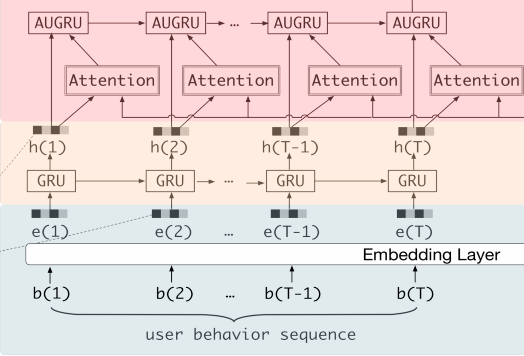
兴趣抽取层(Interest Extractor Layer):
- 用来从历史行为序列中捕获用户的短期兴趣点,同时增加了辅助损失函数auxiliary loss,用来监督学习每一步的兴趣点抽取
- 使用GRU比LSTM速度快,避免了RNN梯度消失问题,适合电子商务系统
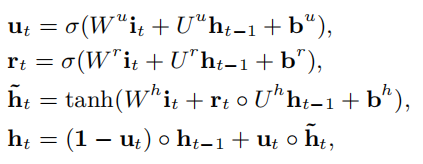
- interest extractor layer 用 GRU时间产生的序列行为建模,捕捉行为之间的依赖,生成的 interest state h(i)作为 Interest Evolving Layer 的输入
浅蓝色为原始数据,黄色层通过GRU做了兴趣的抽取,粉色层做了兴趣的演化,
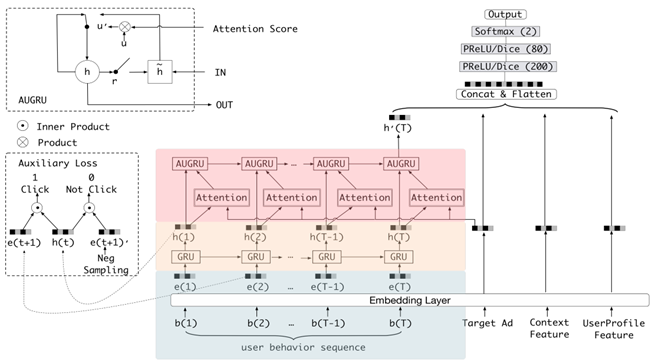
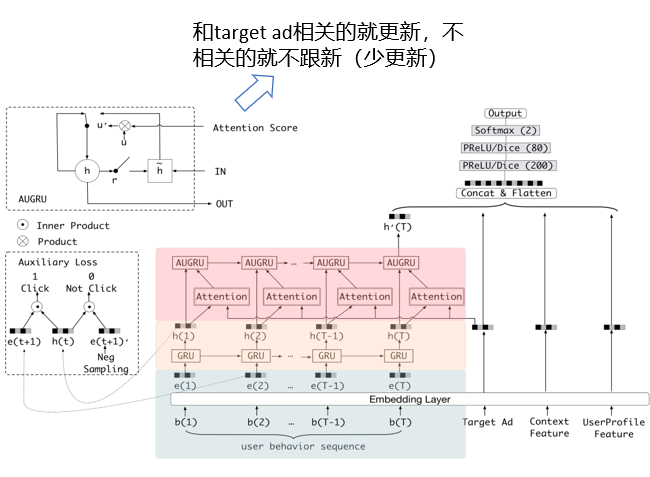
工程中的 auxiliary loss(辅助损失函数):
- 使用auxiliary loss 进行额外的监督,用下一时刻的行为监督当前时刻兴趣的学习,促使GRU在提炼兴趣表达上更高效
- 当前时刻的兴趣直接影响了下一时刻行为的发生(下一个行为就是当前行为的预估的正例)
-
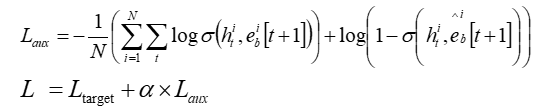
- loss采用负对数似然,负例的选择从用户未交互过的商品中随机抽取,或者从已展示给用户但没有点击的商品中随机抽取
- α用来平衡 interest representation 和 CTR prediction
- 使用辅助损失函数,更好的预测下一步用户会做什么 => 让每一个 hidden state进行充分的训练,更好的表达interest
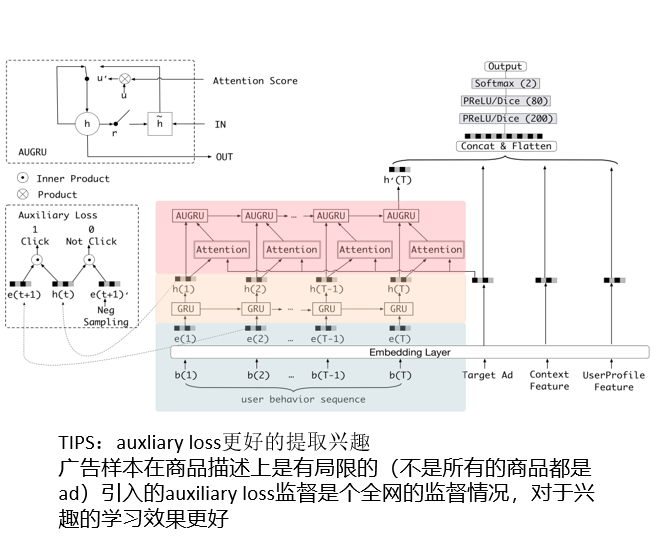
兴趣进化层(Interest Evolving Layer):
- 兴趣是不断变化的,以衣服为例,随着潮流趋势和用户口味的变化,用户对于衣服的兴趣也在发生变化(这个变化对于不同衣服候选集的CTR预测来说会重要)
- 用户在某一段时间的喜好具有一定的集中性。比如用户可能在一段时间内不断买书,在另一段时间内不断买衣服
- 每种兴趣都有自己的演变趋势,不同种类的兴趣之间很少相互影响,例如买书和买衣服的兴趣基本互不相关
采用兴趣进化模型的优势
- 基于用户历史行为表达出最终的用户兴趣
- 根据兴趣进化趋势更好的预估目标item的CTR
兴趣进化层(Interest Evolving Layer):
- 用来捕捉与目标item相关的兴趣及其进化
- 采用AUGRU(Attentional Update GRU),利用了Attention机制中的Local Activation能力,以及GRU的序列学习能力
- 通过兴趣抽取层,得到了兴趣序列{h1, h2, ..., hT},都有能力表达用户在当前时间点的兴趣,在此基础上再做一次演化,然后通过AUGRU输入兴趣状态(抽取层的输出)与目标item(下一个点击目标)
- 来计算两者的相关性,从而强化相关兴趣,弱化无关兴趣,刻画兴趣的真实进化
- Attention计算
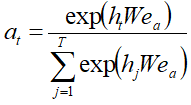
能够反映目标item 和输入 之间的关系,关系强会导致Attention分数高,最终输出的h'(T)代表用户兴趣
DIEN表现结果:
- 公共数据集,Amazon Dataset
- 工业数据集,淘宝在线广告展示系统
- A/B Testing,相比于BaseModel提升了20.7%的CTR
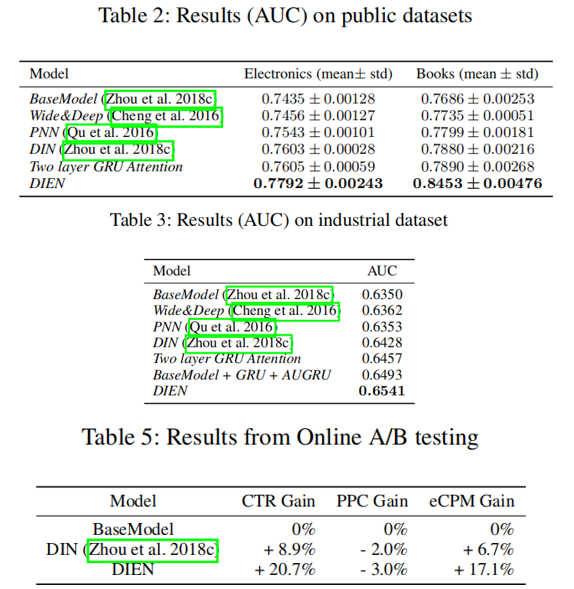
线上效果:
- 1个月的A/B Test,显著线上效果
- 双十一期间,猜你喜欢全量服务
指标:
- CTR : Click / impressions
- eCPM : Cost / impressions * 1000
- GPM : GMV / impressions * 1000(平均1000次展示,平均成交金额的比例)
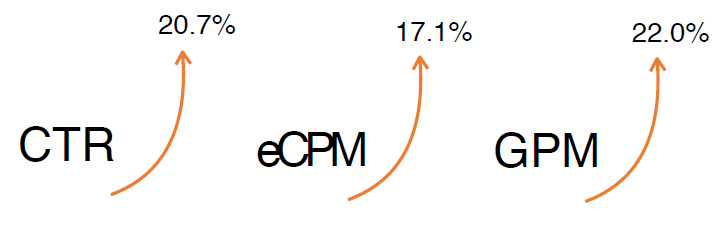
DIEN Summary:
- DIEN和DIN最底层都有Embedding Layer,User profile, target AD和context feature,处理方式一样
- Interest Extractor Layer从embedding数据中提取出interest。但用户在某一时间的interest不仅与当前的behavior有关,也与之前的behavior相关,所以使用GRU单元来提取interest
- Interest Extractor Layer,通过辅助loss,提升兴趣表达的准确性
- Interest Evolution Layer,更准确的表达用户兴趣的动态变化性,在GRU基础上增加Attention机制,找到与target AD相关的interest
- DIN中简单的使用外积完成的activation unit => 使用attention-based GRU网络,更好的挖掘序列数据中的兴趣及演化
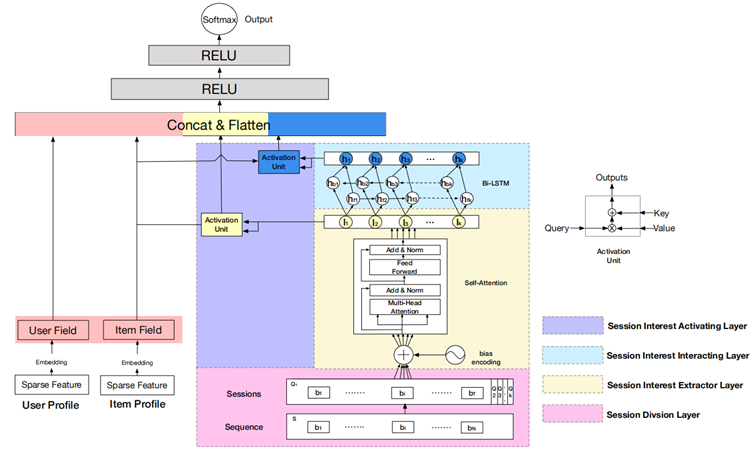
深度会话兴趣网络DSIN
- Deep Session Interest Network for Click-Through Rate Prediction, IJCAI 2019
- https://arxiv.org/abs/1905.06482
- DIEN利用用户行为序列,挖掘用户兴趣的动态演化,但忽视用户行为序列是会话
- 利用用户的行为序列中的多个历史会话,一个session是在给定的时间范围内发生的交互列表(用户行为列表)

用户行为洞察:
- Sequence视角,同样可以看到user interest的变化
- Session视角,每个Session中的行为是相近的,而在不同会话之间差别是很大的(类似聚类)
- Session的划分和airbnb一样,即将用户的点击行为按照时间排序,前后的时间间隔大于30min,算成另一个session

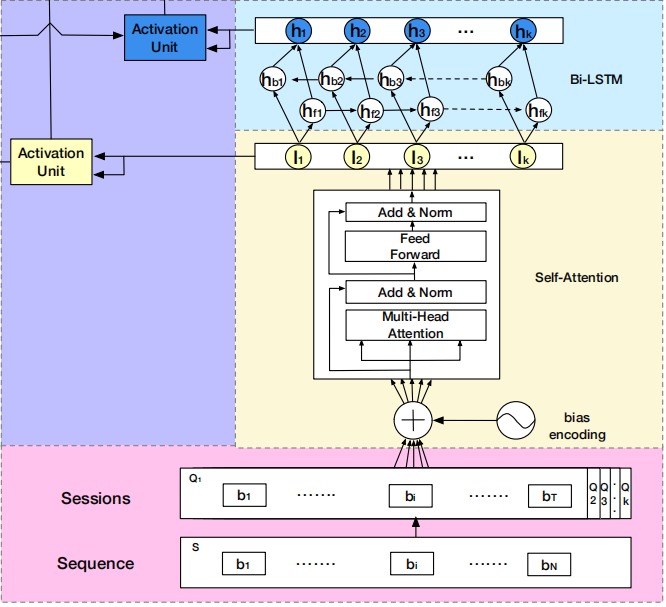
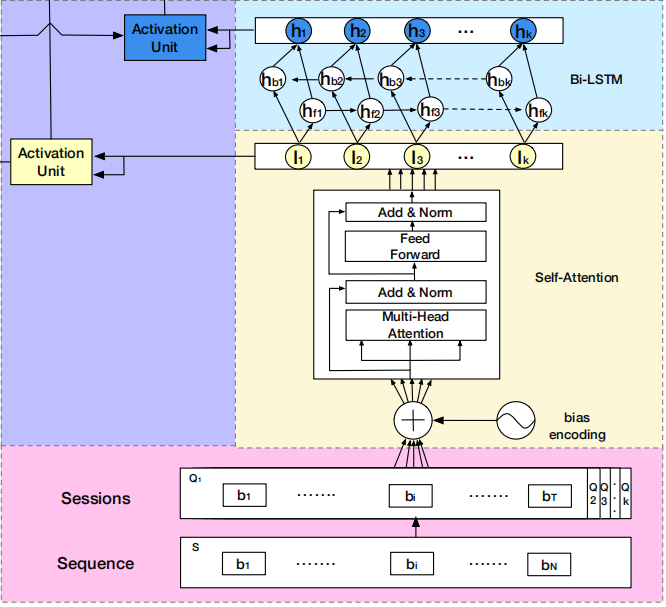
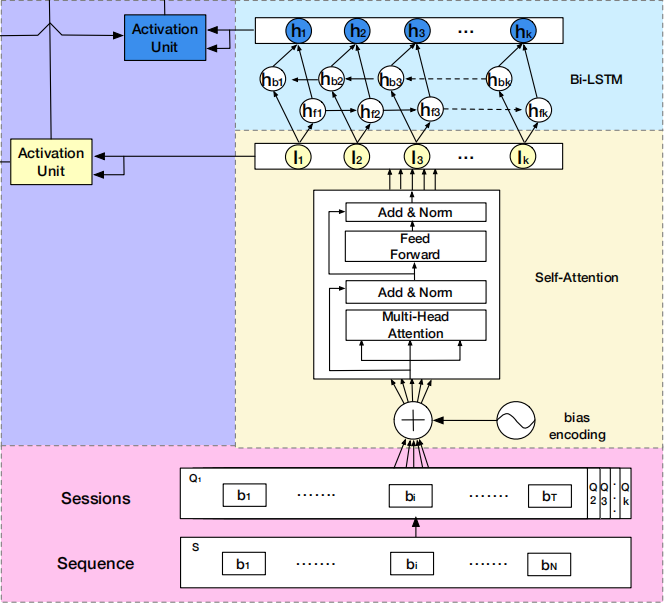
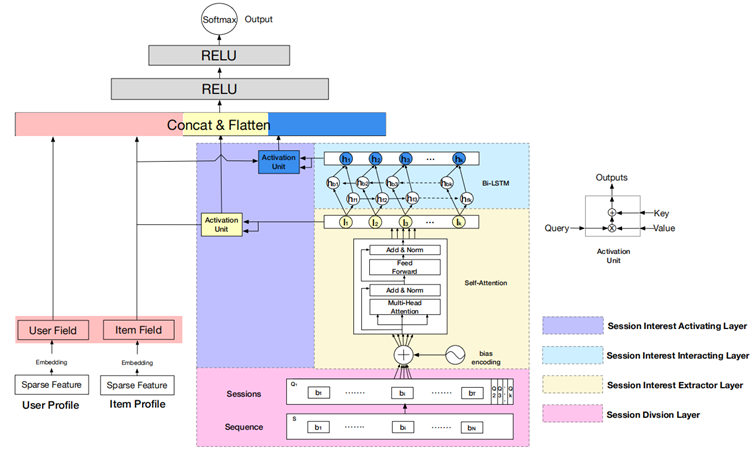
DSIN在全连接层之前,分成了两部分:
- 左边部分,将用户特征和物品特征转换对应的向量表示,主要是embedding层
- 右边部分,是对用户行为序列进行处理,从下到上分为四层:
- session division layer,序列切分层
- session interest extractor layer,会话兴趣抽取层
- session interest interacting layer,会话间兴趣交互层
- session interest activating layer,会话兴趣激活层
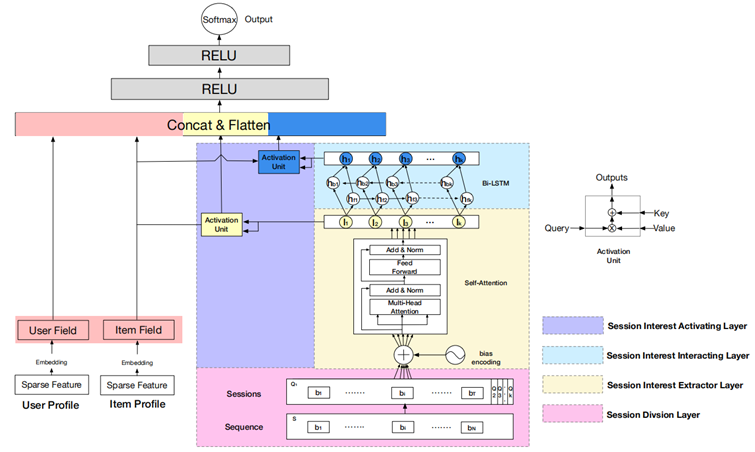
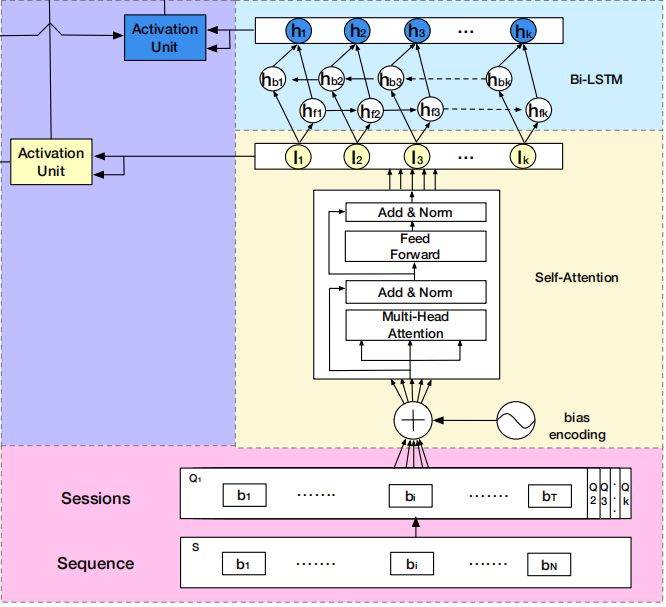
DSIN模型流程:
- 首先使用带有Bias Encoding(偏置编码)的Self-Attention(自我注意力)机制 => 提取用户的Session兴趣向量
- 然后利用Bi-LSTM 对用户的Session之间的交互进行建模 => 带有上下文信息的Session兴趣向量
- 最后利用Activation Unit(局部激活单元)自适应地学习各种会话兴趣对目标item的影响
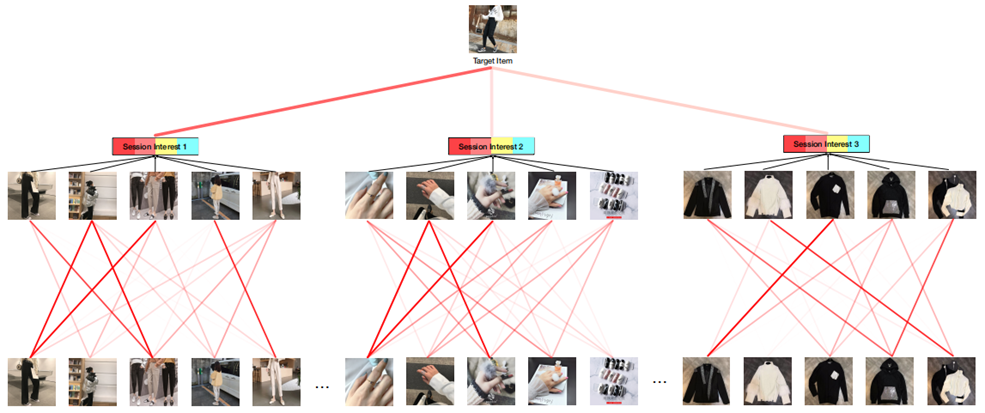
Attention Weight可视化:
Self-Attention(自注意力机制)中的Attention权重(黄色框) => 黄色向量
Local Activation Unit(局部激活单元)中的Attention权重(蓝色框)=> 蓝色向量
序列切分层(Session Division Layer):
- 将用户的点击行为按照时间排序,前后的时间间隔大于30min,就进行切分
- 将用户的行为序列S切分成多个会话序列Q
- 第k个会话
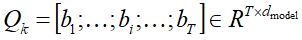
T是会话的长度,bi是会话中第i个行为(d_model维embedding向量)Qk是T * d维,会话序列Q是K * T * d维
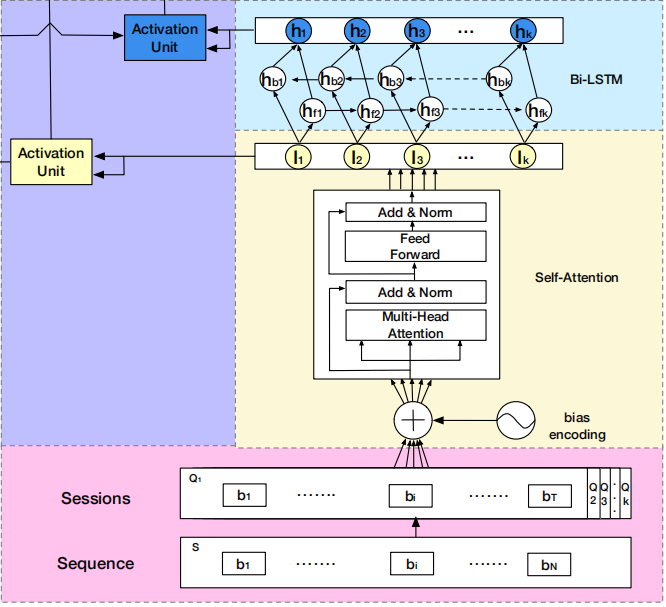
会话兴趣抽取层(Session Interest Extractor Layer):
- 目的是寻找session内部的行为之间关系,进一步提取session interest(使用transformer对Session行为进行处理)
- 对每个Session用multi-head self-attention(多头自注意力)机制捕获行为之间内部关系,减少不相关行为的影响
- 自注意力模块用bias encoding来捕获序列中行为的位置信息
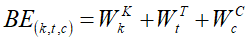
BE(k,t,c)是第k个session中,第t个behavior的嵌入向量的第c个位置的偏置项,即每个会话、会话中的每个商品有偏置项外,每个商品对应的embedding的每个位置,都加入了偏置项
- 增加偏差编码后,用户行为会话Q就更新为 Q=Q+BE
- 通过Self-Attention将每个session兴趣转换成一个d维向量
会话兴趣抽取层(Session Interest Extractor Layer):
- Self-Attention可以捕捉sequence中的场以来关系,同时可以并行计算
- Add代表了Residual Connection,为了解决多层神经网络训练困难的问题,通过将前一层的信息无差的传递到下一层,可以有效的只关注差异部分(ResNet中常用到)
- Norm代表了Layer Normalization,对Layer的激活值的归一化 => 加速模型的训练过程,更快收敛
- 因为用户的点击行为会受各种因素影响,比如颜色、款式和价格,那么这些因素就是所谓的head。可以将某个session Q根据H个head划分为H份,即:
-
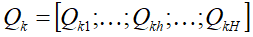 ,Qkh 是QK的第h 个head, H表示head的个数;
,Qkh 是QK的第h 个head, H表示head的个数;
-
会话兴趣交互层(Session Interest Interacting Layer):
- 将会话兴趣抽取层的输出作为该层的输入,用Bi-LSTM模拟不同会话的兴趣动态改变
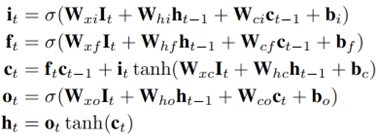
- 这里的 σ 是Logistic函数,i,f,o和c是输入门、遗忘门、输出门和与It 有相同的维度
- 双向的LSTM,每个时刻的hidden state Ht:
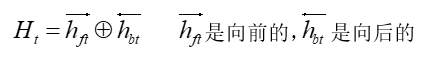
相加前向和反向传播对应的时刻t的hidden state
会话兴趣激活层(Session Interest Activating Layer):
- 和DIN的Local Activation Unit作用类似
- 用户的Session兴趣与目标物品越相近,那么应该赋予更大的权重,使用注意力机制
-
- 对于混合了上下文信息的Session兴趣,一样也使用注意力机制,兴趣交互自适应表示
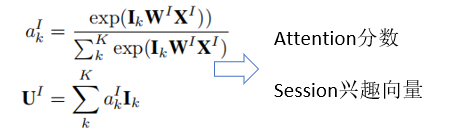

用户特征embedding向量、产品特征embedding以及 拼接起来,扁平化,然后feed给MLP层
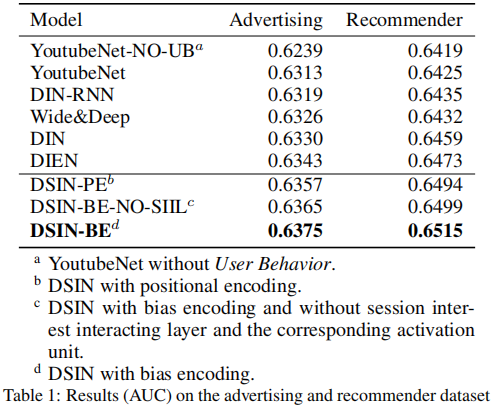
DSIN结果对比:
- Advertising Dataset,阿里妈妈广告公开数据集
- Recommender Dataset,阿里巴巴推荐数据集
- 60亿展示/点击日志,1亿用户,7000万商品
- 训练时间2018-12-13到2018-12-19(8天)
- 测试时间 2018-12-20
- 记录用户最近的200个行为
DSIN Summary:
- 将用户的连续行为自然地划分为Session,通过带有偏置编码的self attention网络对每个会话进行建模
- 使用BI-LSTM捕捉用户不同历史会话兴趣的交互和演变
- 设计了两个Activation Unit,将它们与目标item聚合起来,形成行为序列的最终表示形式(黄色,蓝色)

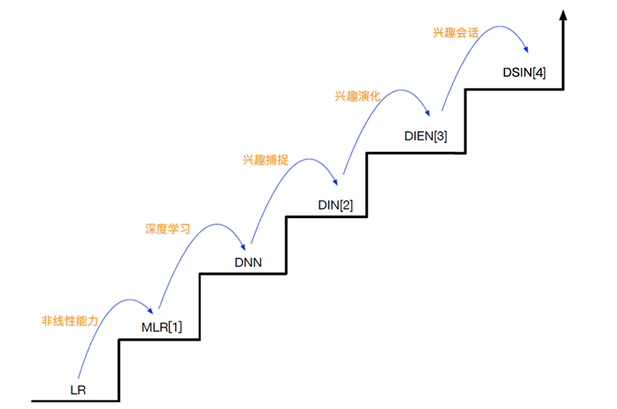
演化规律:
- 降低信息损失
- 先有洞察,再有拟合
- 模型是为了更好的拟合洞察
- 工程中提出Dice,Mini-Batch Aware Regularization,auxiliary loss
- 随着模型越来越复杂,越需要并行计算(GPU)
天猫复购用户预测Challenge
Challenge背景:
https://tianchi.aliyun.com/competition/entrance/231576/information
电商经常会做大促,比如打折或者发放优惠券,尤其是在特殊的节日,比如黑色星期五,双十一等,目的是为了吸引大量的新用户。然而,许多吸引过来的购买者只是一次性交易,这些促销对于转换为
长期的顾客来说可能收效甚微
为了解决这个问题,对于复购用户的预测就尤为重要,因为关注潜在的忠诚消费者,对于商家来说可以降低促销成本,增加投资回报率ROI
在线广告领域,客户定位是非常有挑战的,尤其是对于新购买者来说。但是对于天猫来说,已经积累了大量用户行为日志,可以解决这个问题
Challenge目标:
提供了双十一促销期间的商家和新用户数据,目标是对于给定的商家,预测新用户是否能成为忠诚用户,即未来6个月内会购买这个商家的商品
数据格式:
双十一以及前6个月的数据,label标签表明了用户是否为重复购买者。训练和测试文件见data_format2.zip

阿里数据银行后台:https://databank.tmall.com/promotion?path=ems/databankLogin/centerAbility
Step1,采样少量样本数据,更快的跑通实验,数据导入MySQL => 采样导出;使用Python 进行采样导出,注意user_id, merchant_id对应关系
Step2,数据加载
Step3,特征工程;User特征,商家特征,用户商家交互行为特征;构造更多特征更好的进行拟合(用户购买的商品数,购买的品类数,购买过的商家数,品牌数,时间跨度)
Step4,使用机器学习方法进行训练
Step5,使用测试集得出prediction.csv
Step1,采样少量样本数据
Step2,数据加载
Step3,特征工程,User特征,商家特征,用户商家交互行为特征; 构造更多特征更好的进行拟合(用户购买的商品数,购买的品类数,购买过的商家数,品牌数,时间跨度)
Step4,使用机器学习方法进行训练
Step5,使用测试集得出prediction.csv
Tips:训练的过程中,可以保存特征文件,调试不同算法模型
train_X.to_csv('train_x.csv', index=False)
train_y.to_csv('train_y.csv', index=False)
To Do:
使用全量样本进行训练和预测,提交结果 score:0.6524805
使用深度学习模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号