
深度学习| word2vec
word2vec
单词向量化表示
word2vec 下分为两个模型CBOW与Skip-gram ,分别包含Hierarchical Softmax和 Negative Sampling两个方法;
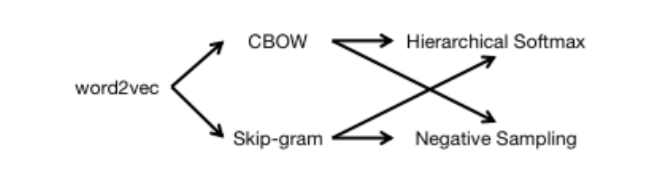
1. 连续词袋模型(CBOW)与跳字模型(Skip-gram)
- 单词W;
- 词典D = {W1, W2, ..., WN },由单词组成的集合;(无序的,由下标即可找到这个单词,键值对)
- 语料库C, 由单词组成的文本序列;(强调有顺序性,可以是重复的)
- 单词Wt的上下文是语料库中由单词Wt的前c个单词和后c个单词组成的文本序列,Wt称为中心词; (是语料库的真子集)
Context(Wt) = (Wt-c, ..., Wt-2, Wt-1, Wt+1, Wt+2, ..., Wt+c)

连续词袋模型(CBOW,Continuous Bag-of-words Model)假设中心词由该词在文本序列中的上下文来生成。(上图中是前两个和后两个组成的上下文来决定Wt中心词)
跳字模型(Skip-gram)假设中心词生成该词在文本序列中的上下文。(由Wt来决定它所对应的上下文)
2. 基于层序softmax(Hierarchical softmax)方法的连续词袋模型训练
基于层序softmax方法的连续词袋模型网络结构:

Context(W)1是W这个单词的上下文,相当于之前所说的Wt-c,W2c相当于Wt+c ;中心词由前c个后c个决定;
投影层,进行遍历累加得到Xw;
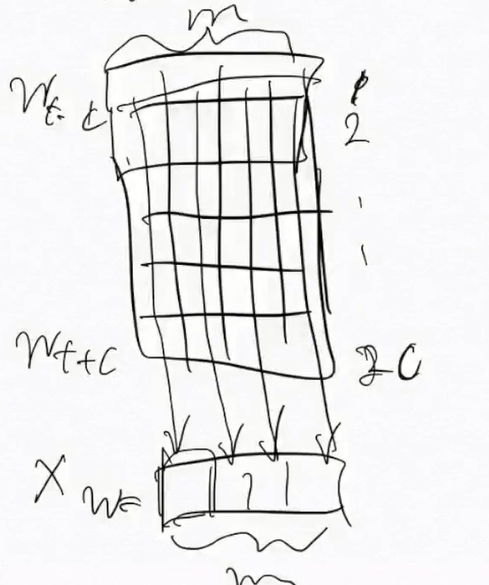
输出层 哪个单词是我可以决定的,哪个是决定不了的;N个单词,每个单词的概率;采用哈夫曼树近似计算,从输入向叶子节点的映射关系,从1~N个叶子节点,这样子就不需要每个叶子节点都去遍历了,只需要从根结点向它所对应的叶子节点路径的计算过程,哈夫曼树是个二叉树 全路径最短二叉树,时间复杂度从O(n)到n个叶子节点组成的二叉树,最短堆二叉树 时间复杂度为O(log2n-1);数量级会少很多; 权职越高的单词离根结点最近,哈夫曼编码越短;

theta一开始是初始化的;

带概率的损失函数,交叉熵一般是处理多分类问题的;二分类一般用负的对数损失(对数损失的极小化等价于似然函数的最大化);
条件概率是指:给出上下文找出中心词,从根结点到叶子节点的这么多次连续的二分类,概率相乘即概率值;
似然函数是遍历整个语料库的每个单词的概率值;

3. 基于层序softmax(Hierachical softmax)方法的跳字模型训练
基于层序softmax方法的跳字模型网络结构:
给出中心词决定上下文,只有2层;它的投影层就是输入层;V(W)中心词的向量化表示;
输出层同样是哈夫曼树,一个中心词向哈夫曼树当中N个叶子节点当中的上下文里边的每个单词的搜索;
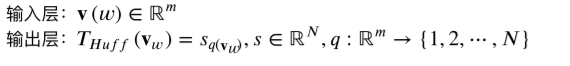
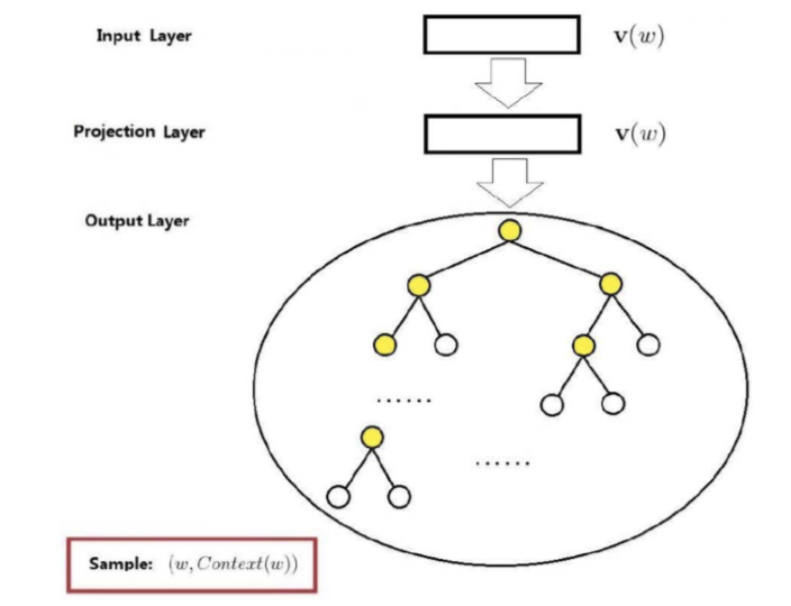
它的条件概率是给出中心词,要得到整个上下文(2c个单词)出现的概率;


4. 基于负采样(Negative Sampling)方法的连续词袋模型训练
正样本W和 采用之后的负样本构成D的一个子集;


5. 基于负采样(Negative Samplint)方法的跳字模型训练


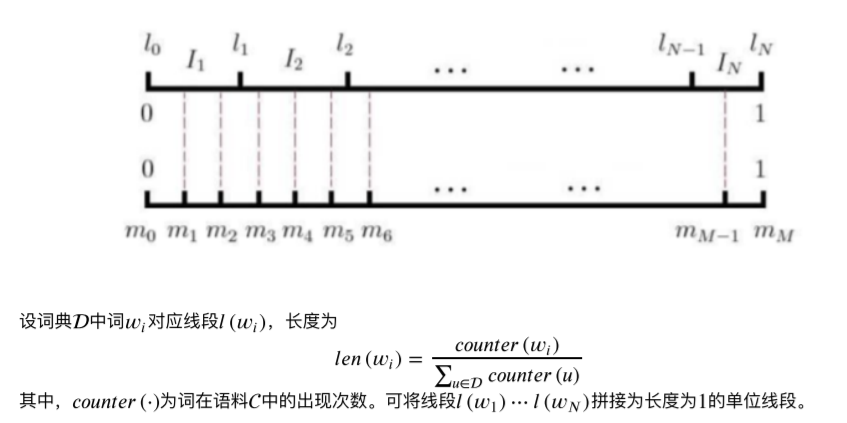
6. 负采样算法
权重大的负采样的概率大点,权重小的负采样概率小点;根据词频的大小;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号