
八. 决策树
决策树的应用
决策树
决策树与 if-then 规则
-
决策树可以看作一个 if-then 规则的集合
- 由决策树的根节点到叶节点的每一条路径,构建一条规则:路径上内部节点的特征对应着规则的条件(condition),叶节点对应规则的结论
- 决策树的 if-then 规则集合有一个重要性质:互斥并且完备。这就是说,每个实例都被一条规则(一条路径)所覆盖,并且只被这一条规则覆盖
决策树中的 Condition 是什么?
- Condition 的确定过程就是特征选择的过程;
决策树的目标:
- 决策树学习的本质,是从训练数据集中归纳出一组 if-then 分类规则
- 与训练集不相矛盾的决策树,可能有很多个,也可能一个也没有;所以我们需要选择一个与训练数据集矛盾较小的决策树
- 另一角度,我们可以把决策树看成一个条件概率模型,我们的目标是将实例分配到条件概率更大的那一类中去;
- 从所有可能的情况中选择最优决策树,是一个NP完全问题,所以我们通常采用启发式算法求解决策树,得到一个次最优解
- 采用的算法通常是递归地进行以下过程:选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集都有一个最好的分类
特征选择:
- 特征选择就是决定用哪个特征来划分特征空间

随机变量:
随机变量(random variable)的本质是一个函数,是从样本空间的子集到实数的映射,将事件转换成一个数值
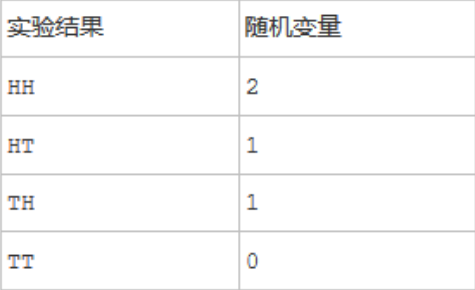
根据样本空间中的元素不同(即不同的实验结果),随机变量的值也将随机产生。可以说,随机变量是“数值化”的实验结果
在现实生活中,实验结果是描述性的词汇,比如 “硬币的正面”、“反面”。在数学家眼里,这些文字化的叙述太过繁琐,所以拿数字来代表它们
熵
熵(entropy)用来衡量随机变量的不确定性;变量的不确定性越大,熵也就越大
设X是一个取有限个值的离散随机变量,其概率分布为:
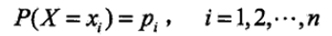
则随机变量X的熵定义为:
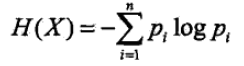
通常,上式中的对数以2为底或者以e为底(自然对数),这时熵的单位分别称为比特(bit)或纳特(nat)。
当随机变量只取两个值,例如 1,0 时,则 X 的分布为:

熵为: 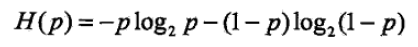
这时,熵H(p)随概率p变化的曲线如下图所示(单位为比特):
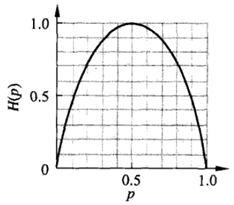
熵的示例
给三个球分类
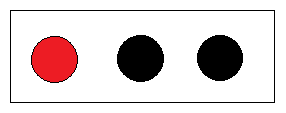
- 显然一眼就可以看出把红球独自一组,黑球一组;
- 那么从熵的观点来看,是什么情况呢?
初始状态的熵: E(三个球) = - 1/3 * log( 1/3 ) - 2/3 * log( 2/3 ) = 0.918
①第一种分类方法是一个红球、一个黑球一组,另一个黑球自己一组:
- 在红黑一组中有红球和黑球, 红黑球各自出现的概率是 1/2.
- 在另一组 100% 出现黑球, 红球的概率是 0
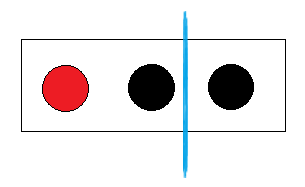
E(红黑|黑) = E(红黑) + E(黑) = - 1/2 * log( 1/2 ) - 1/2 * log ( 1/2 ) - 1 * log( 1 ) = 1; 可以看到,分类之后熵反而增大了
② 第二种分法就是红球自己一组,剩下两个黑球一组:
在红球组中出现黑球的概率是0, 在黑球组中出现红球的概率是0, 这样的分类已经“纯”了,也就是分类后子集中的随机变量已经变成确定性的了;
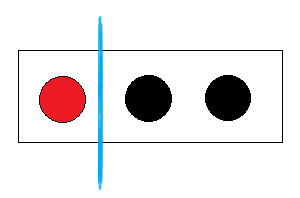
E(红|黑黑) = E(红) + E(黑黑) = - 1 * log( 1 ) - 1 * log( 1 ) = 0
决策树的目标
- 我们使用决策树模型的最终目的是利用决策树模型进行分类预测,预测我们给出的一组数据最终属于哪一种类别,这是一个由不确定到确定的过程;
- 最终理想的分类是,每一组数据,都能确定性地按照决策树分支找到对应的类别
- 所以我们就选择使数据信息熵下降最快的特征作为分类节点,使得决策树尽快地趋于确定
条件熵(conditional entropy)
条件熵 H( Y|X ) 表示在已知随机变量 X 的条件下随机变量 Y 的不确定性:
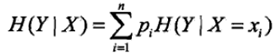 其中
其中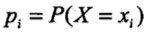
- 熵 H(D) 表示对数据集 D 进行分类的不确定性。
- 条件熵 H(D|A) 指在给定特征 A 的条件下数据集分类的不确定性
- 当熵和条件熵的概率由数据估计得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)
信息增益
特征A对训练数据集D的信息增益 g(D, A),定义为集合D的经验熵H(D)与特征A给定条件下D的条件熵 H(D|A)之差,即

- 决策树学习应用信息增益准则选择特征
- 经验熵H(D)表示对数据集D进行分类的不确定性。而经验条件熵H(D|A)表示在特征A给定的条件下对数据集D进行分类的不确定性。那么它们的差,即信息增益,就表示由于特征A而使得对数据集D的分类的不确定性减少的程度
- 对于数据集D而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益
- 信息增益大的特征具有更强的分类能力
决策树的生成算法
决策树(ID3)的训练过程就是找到信息增益最大的特征,然后按照此特征进行分类,然后再找到各类型子集中信息增益最大的特征,然后按照此特征进行分类,最终得到符合要求的模型;
C4.5算法在ID3基础上做了改进,用信息增益比来选择特征;
分类与回归树(CART): 由特征选择、树的生成和剪枝三部分组成,既可以用于分类也可以用于回归;
决策树在机器学习领域的地位很高,而且又是几个经典集成模型(随机森林,提升树)的基础。什么叫决策树呢?其实我们每天都在使用决策树,这是我们做日常决策的工具。比如,“明天如果下雨我就不出
门了。” 在这里我们用了一个决策条件: 是否下雨,然后基于这个条件会有不同的结果:出门和不出门。 这就是一个经典的决策树!
在所有的机器学习模型中,决策树是最贴近生活的!

张三和李四都是医生,曾经都被评为国家级专家,但他们的诊断逻辑还是不太一样的,具体如上图所示。虽然都去关注“肌肉疼痛”和“发烧”两个症状,张医生首先判断患者是否有发烧症状,李医生则先看
患者是否有肌肉疼痛感。
这个例子中涉及到了几个核心点。第一、两位医生都具有属于自己的决策树,而且他们在诊断过程中都会按照自己的决策树逻辑来诊断。第二、医生的能力也有好坏之分,在这里我们可以把这两个决策
树看作是两位医生的能力,而且这种能力是由大量的临床经验获得的。这样一来,哪一个决策树好就等同于哪一位医生的医术更加高明。我们把临床经验可以看作是历史样本数据。第三、为了判断哪位
医生的医术更高明,需要知道哪一个决策树更好,这就要求我们定义出一种评估决策树好坏的标准。
利用机器学习语言来描述的话,基于历史的诊断样本或者经验,我们可以构造出不同的决策树(也就是的不同医生),但只要我们定义出了一种评估方式则可以选出其中最好的那棵决策树,这其实就是决策
树的训练过程。
决策树与边界形态
决策树由节点和边组成;
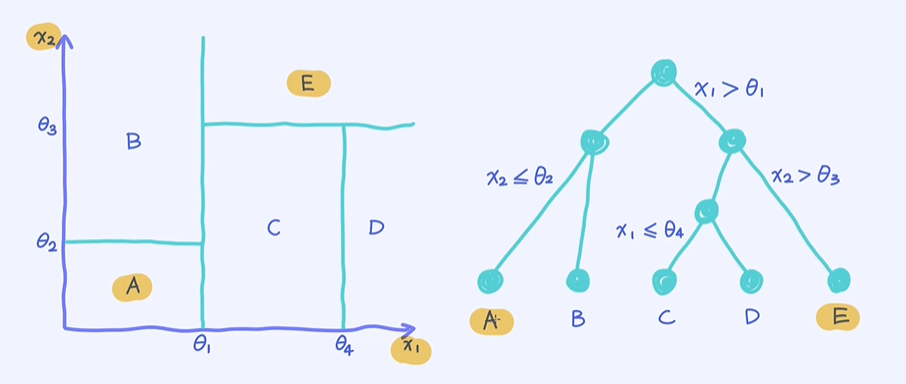
一颗决策树与对应的决策边界
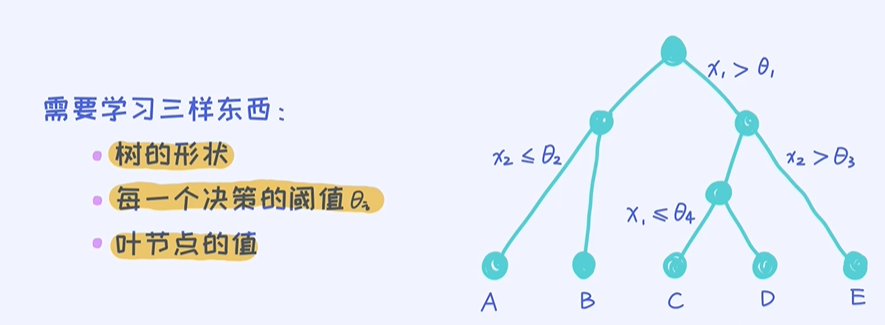
一棵决策树也拥有大量的参数,但树本身是具有一定结构的。结构的学习也叫作Structured Prediction,因为这种问题不像之前讨论的比如回归问题只需要预测一个值就可以了,而是同时也要学出树的结
构。结构的学习一般来说都很难,很多都是NP-hard问题。那具体什么叫NP-hard呢? 如果学过数据结构与算法,就应该有所了解。简单来讲NP-hard问题就是那些多项式时间复杂度内基本上解不出来的
问题,一般需要指数级复杂度。
在计算机世界里存在大量的NP-hard问题等待我们去解决。一般对于这类的问题是没有一个很好的方式来求出全局最优解的。既然这样,我们通常会使用近似算法来找到“相对”最好的解。一个经典的近似
算法叫作“贪心算法”。这类的算法每次只考虑局部最好的情况,所以一般带来的是相对最好的解决方案。但在某些特定的情况下,也可以给出全局最优解。给定数据并学出最好的决策树本身也是很难的问
题。在这个问题上,我们也通常使用贪心算法来做每一步的决策,比如使用信息增益来判断下一个节点上需要放哪一个特征。
基于给定数据构造决策树
10个样本,预测变量逾期,属于分类问题; 两个特征:工作年限小于2年、信用卡没有按时换过,都属于类别型特征(Y和N)
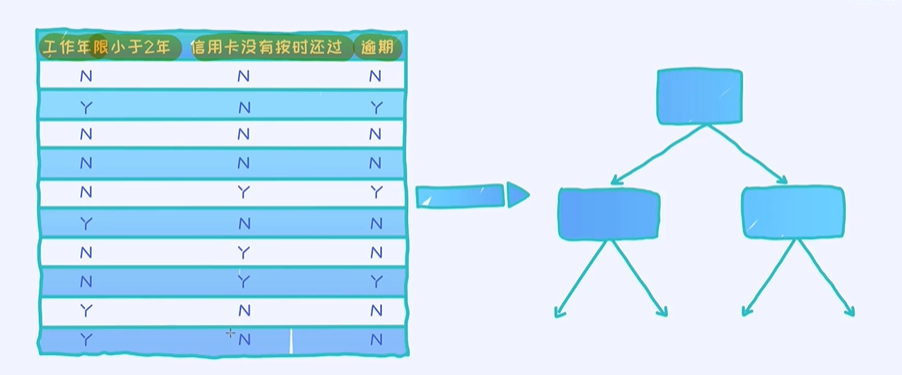
对于上述的样本数据,我们可以构造出两种不同的决策树。由于数据有两个特征, 而且每个特征都是类别型的,
- 第一种决策树就是以第一个特征为根节点的,
- 第二种决策树就是以第二个特征为根节点的,
但实际上这是源于数据的简单。我们平时遇到的问题基本都具有几百或者上千、上万个特征,对于这类数据来讲,可以构造的决策树种类会非常之多。但具体哪一棵决策树更好呢?
这取决于我们的评价标准。
决策树第一种方案
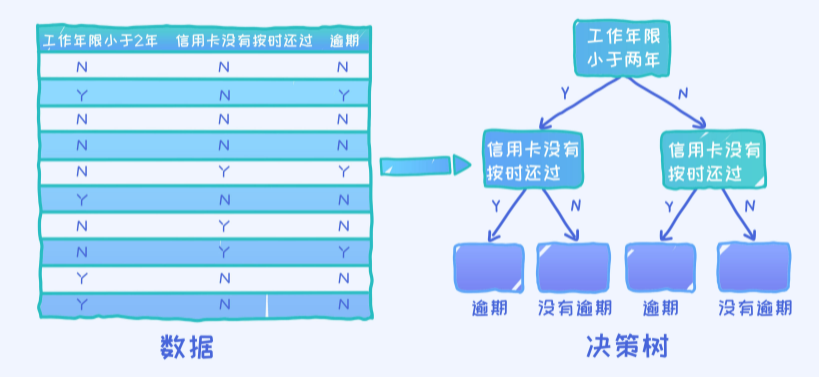
第一种决策树如上图所示。问题:这棵决策树在给定样本上的准确率是多少?
通过一个一个样本的测试, 最终可以得出0.8的准确率。(总共10个样本,犯了2个错误,所以准确率为0.8)
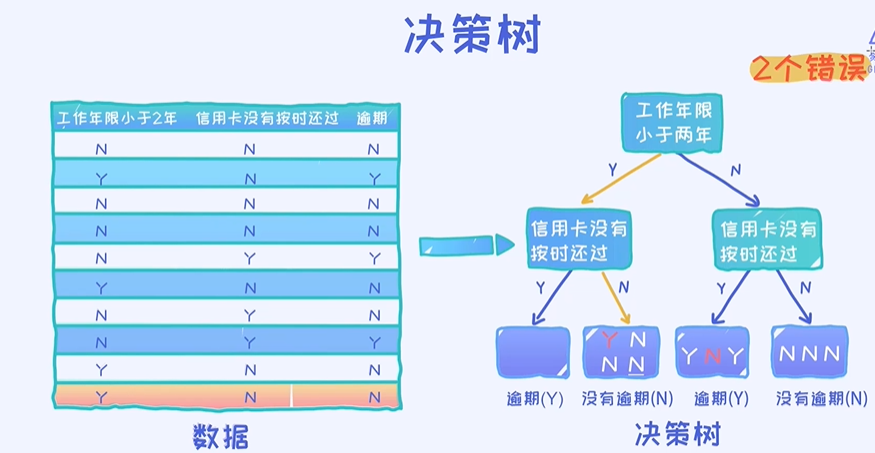
从第一种方案到第二种方案
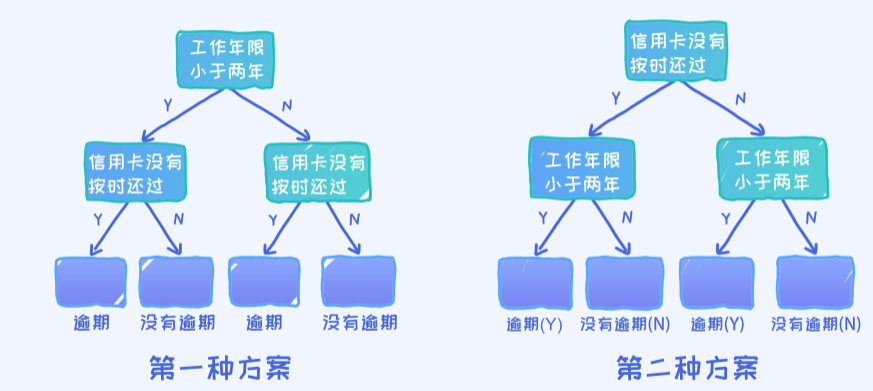
第二种决策树如上图所示。问题:这棵决策树在给定样本上的准确率是多少?
通过一个一个样本的测试,最终可以得出0.5的准确率。
第一种方案准确率更高
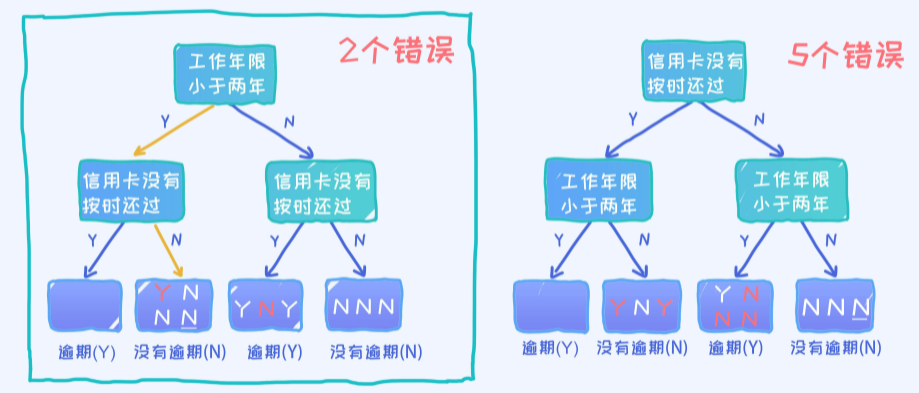
最后的结论就是第一个决策树要优于第二个决策树,因为它的准确率更高。由于这个问题本身及其简单,所以我们甚至都可以罗列出所有可能的决策树,然后再判断哪一个最好。但实际上,稍微复杂点
的问题就不太可能这么做了,因为所有可能的决策树数量太多,不可能一一罗列。
给定数据D,那么决策树的个数跟D是有指数级关系的;通过庞大的集合中选出最优的算法,使用的是贪心算法;
不确定性以及信息增益
好的特征
决策树算法本身是贪心算法。在决策树的训练上,每一步的最优选择局限在局部。
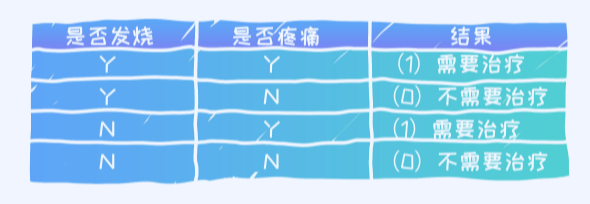
对于上面的数据, 我们接下来需要构建一棵决策树, 而且应该能猜到决策树构建的第一步就是要选择一个根节点(root)。
这里有两种选择
- 一种是“是否发烧”放在根节点上;
- 另外一种是“是否疼痛”放在根节点上。
问题: 那具体哪一个方法更好呢? 是否疼痛作为根节点,对于上述问题,我们希望得到的是分类效果好的。而且… 越简单越好!
好的特征有什么特点
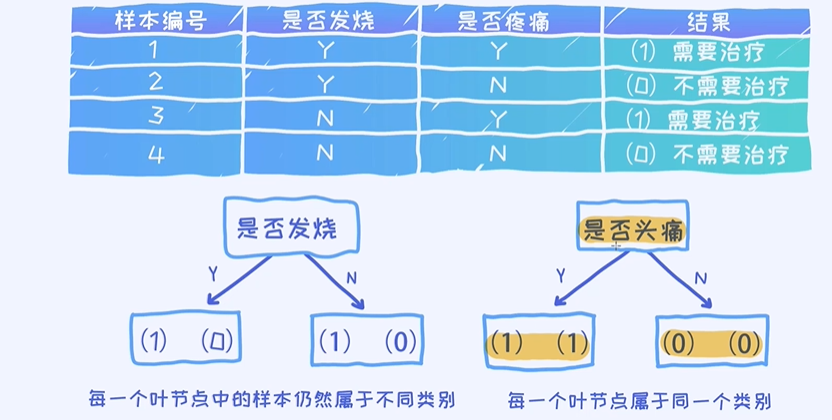
可以看出第二个特征更加有效,因为一下子可以把所有的样本分类得正确。那接下来的问题就来了: 有什么方式来决定哪一个特征更好呢? 或者说这些好的特征具备什么样的特点呢?
信息熵 - 表示不确定性
好的特征减少不确定性
不确定性:信息熵(entropy)
信息熵越大不确定性越大,信息熵越小不确定性越小;
Po表示为0的占比;P1表示为1的占比; 例子2的值 < 例子1的值,例2中只有一个1,其他全部是0,它的不确定性是比较小的;例3 极端情况下所有数都是0,整个信息熵为0;

信息增益 - 不确定性的减少
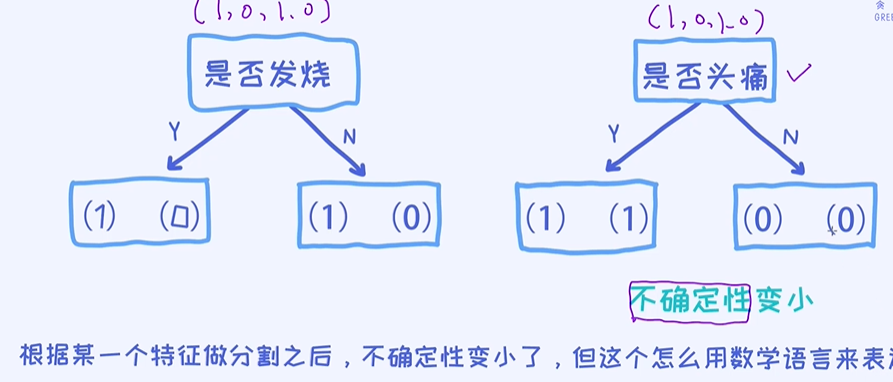
已经知道如何用数学来表示不确定性了。 接下来,我们再回到决策树的问题上。那又如何表示不确定性的减少呢? 无非就是原来的不确定性减去现在的不确定性!下面我们试图分别对”是否发烧“和“是否疼
痛”两个特征,分别计算一下不确定性的减少。
不确定性的减少怎么用数学方法来表达
越大说明当前的特征越好;

信息增益
不确定性的减少也称作信息增益(information gain)
IG(T, a) = H(T) - H(T| a)
这种不确定性的减少也叫作信息增益(information gain)。构建决策树的过程无 非是每一步通过信息增益来选择最好的特征作为当前的根节点,以此类推,持续把树构造起来。通过一个稍微复杂一点的例
子来说明一棵决策树的构建的完整过程。
构建决策树 16个样本(11F,5N)
4个类别型变量,且都是离散型的;outcome二分类问题;
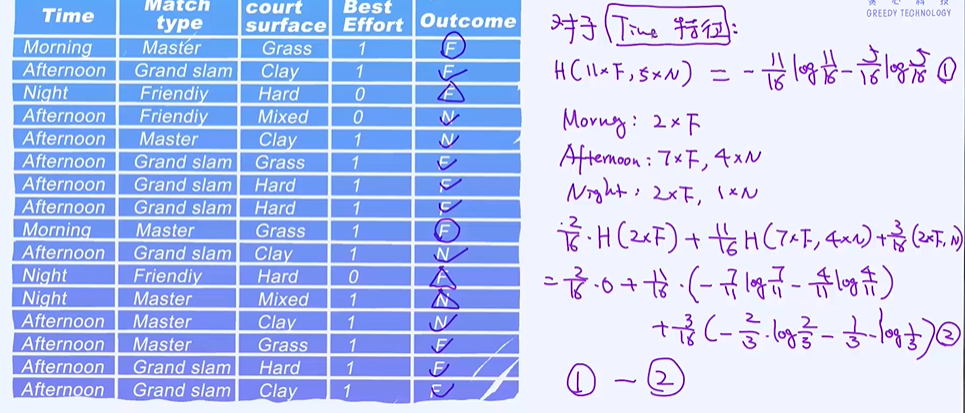
以Time作为根结点计算它的信息增益
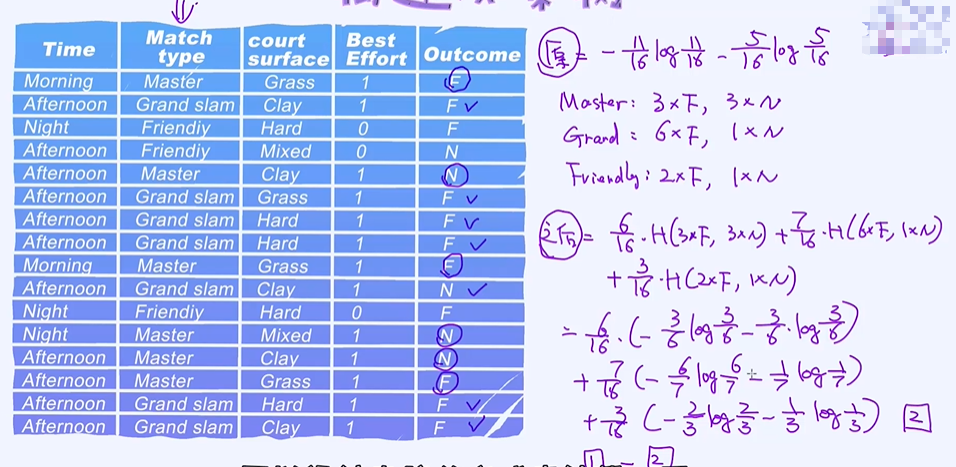
以Match type作为根结点计算它的信息增益
以count surface作为根结点计算它的信息增益

以Best Effort作为根结点计算它的信息增益
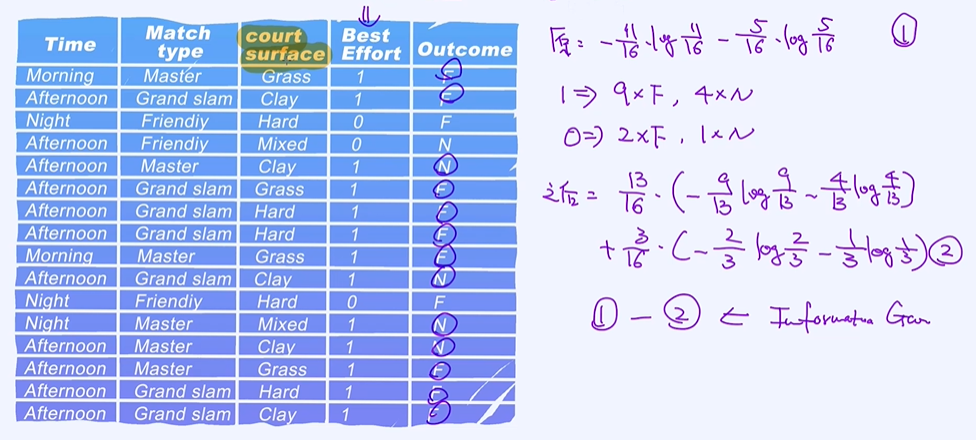
哪个特征的信息增益越大就选择哪个节点作为根结点;发现court surface的信息增益最大,作为根结点;
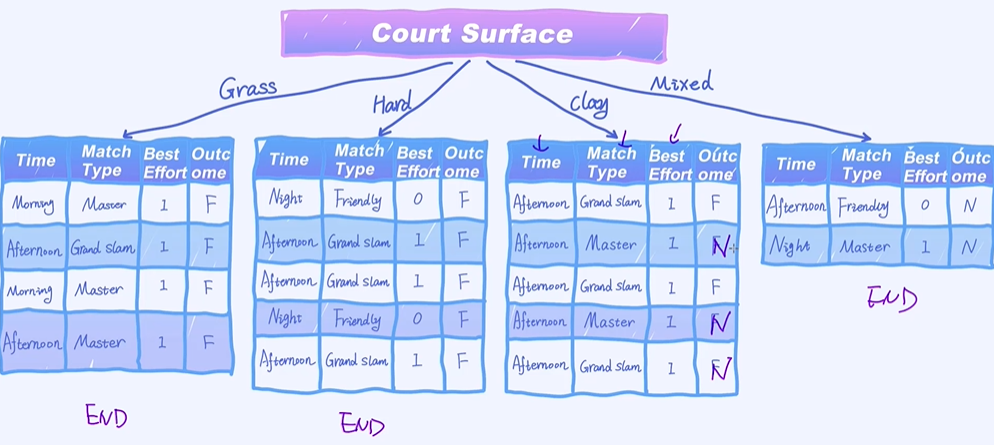
2个F和3个N,Time都是Afternoon没办法把它持续分裂出去的,因为只有一个选项,只会到一个分支;

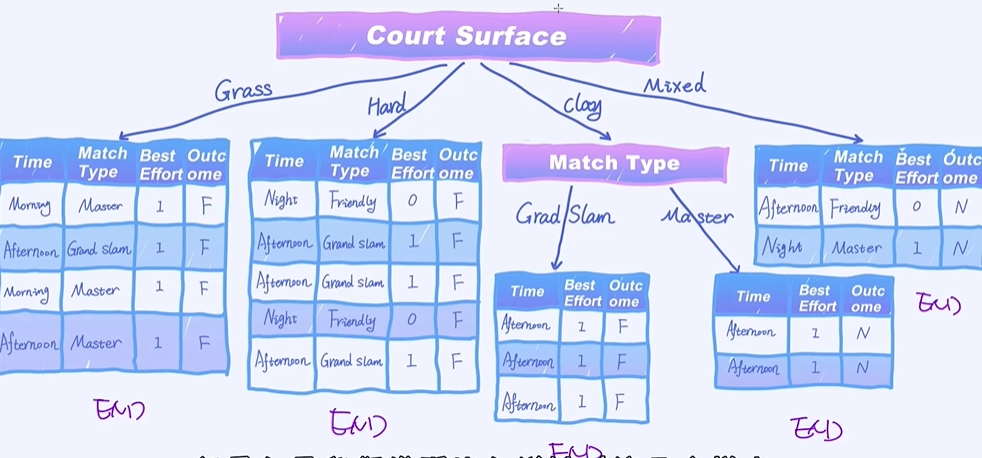
以上是决策树的构建过程。总结一下,每一步的构建其实就是选择当前最好的特征作为根节点。然后持续地重复以上过程把整棵树构建起来。其中,信息增益充当着每次选择特征的标准。当然,除了信
息增益,我们也可以选择其他的指标作为选择特征的标准。到此为止,决策树的构建过程已经说完了。除了这些其实还有几个重要问题需要考虑,比如如何让决策树避免过拟合、如何处理连续型特征、
如何使用决策树来解决回归问题等。
决策树的过拟合
决策树表现与节点数目之间的关系
什么时候可以停止分裂(splitting)
- 当一个叶节点(leaf node)里包含的所有的样本都属于同一个类别时可以停止分裂;
- 当一个叶节点(leaf node)里包含的所有样本的特征都一样时可以停止分裂;
决策树的节点数目
简单来讲,如满足以上两个条件我们就可以停止继续构建决策树了。首先,当所有的样本属于同一类别时就可以停下来,因为已经达成了我们最终的目的。另外,所有的特征都一样的时候其实也没办法
继续了。所以,满足上面的条件就说明我们已经构建了完整的决策树。但这里有一点非常重要:决策树很容易过拟合!
那什么叫过拟合呢? 就是在训练数据上表现特别好,但放到测试数据就表现很糟糕。在逻辑回归里,我们可以使用加入正则的方式来减少过拟合现象。加入正则相当于限制了参数的大小,小的参数会有效
防止过拟合现象。对于决策树我们如何减少过拟合现象? 答案就是:决策树越简单越好! 什么叫更简单的决策树呢? 一个重要标准是来判断决策树中节点的个数,节点个数越少说明这棵决策树就越简单。
决策树性能与节点之间的关系
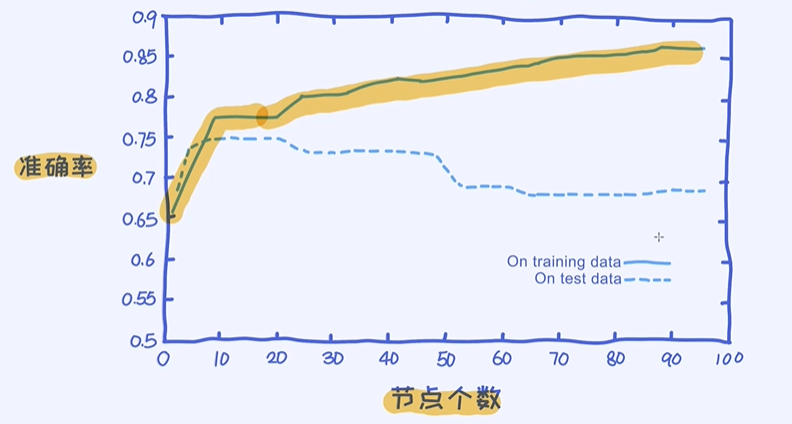
所以,决策树里的节点个数跟过拟合有着很大的关系。因为节点个数越多,可以理解成模型的复杂度越高。通过调参找出最好的节点数;
用于防止过拟合的方案
但直接减少节点个数在实际操作中不太容易实现,因为决策树的构建过程其实是递归的过程。实际上,我们也可以通过限制其他的方式来调节节点个数比如树的深度。树的深度越深,一般来讲节点个数
也会越多,所以都是有一定的关系的。所以,只要是跟节点个数相关的变量,其实都可以用来控制决策树的复杂度。总体来讲,有以下几种方法可以用来减少决策树的过拟合。
- 设置树的最大深度(maximum depth);
- 当叶节点里的样本个数少于阈值时停止分裂;
- 具体阈值选择多少取决于交叉验证的结果;
对决策树调参的时候,无非主要来调整树的深度、每一个叶节点样本的个数等等(通过交叉验证的方式)。具体最优的参数一般通过交叉验证的方式来获得,这一点跟其他模型是一样的。
对于连续型变量和回归问题处理
处理连续型变量
如何处理连续型特征以及用决策树来解决回归问题。如果一个特征是离散型特征,处理方式是比较直观的,无非就是针对每一个特征创建一个分支。但对于连续型特征倒是没有那么直观,感觉有点没有
头绪。连续型特征的处理上其实有很多种方法。对于连续型特征,我们可能会有“如果一个年龄大于20”,则怎么怎么样,不到20再怎么怎么样。所以这里的核心问题是数字“20”,也叫作阈值。那这个阈值
又是怎么算出来的呢? 对于这个问题其实有很多种答案。其中最简单的答案是每个阈值都尝试一遍 !
如何处理连续性(real- valued)特征
年龄为连续型特征,把它映射到二分类的变量中;
可以提取出不同的规则,相当于是把每个规则都需要去计算一遍它的信息增益,选出其中最好的再跟其他的去做比较;
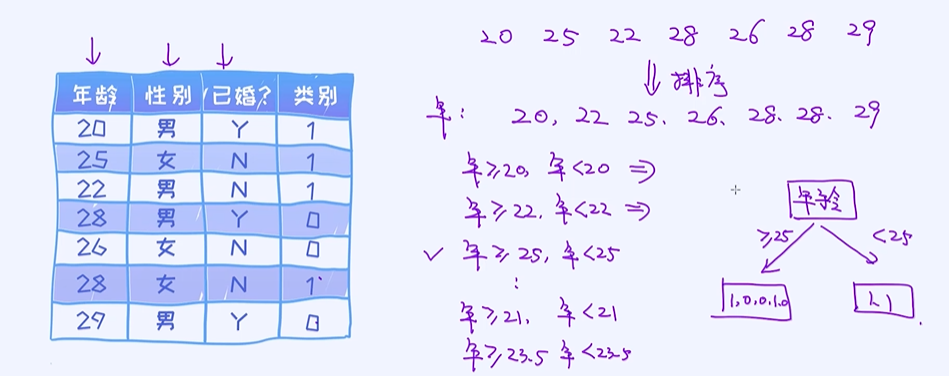
除此之外,处理方式跟类别型特征一模一样。 这里需要注意的一点是,连续型特征是可以重复使用的,比如在一个节点上有“年龄”特征,则在子树上我们可以仍然使用“年龄”这个特征。
训练用于回归的决策树
决策树应用在回归问题上
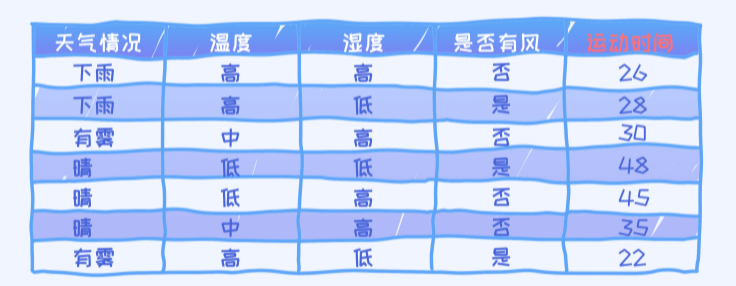
如上图所示,我们希望根据前面四个特征去预测运动时间。这里给出的四个特征都是类别型特征,如果是连续型特征就可以使用上面提到的方法。
利用如下的决策树预测运动时间
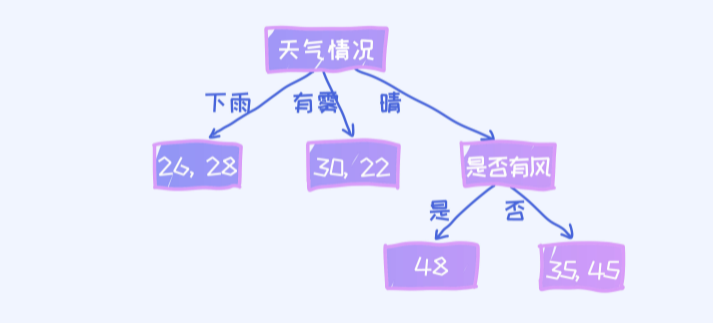
假如上面的这棵决策树是针对于刚才的回归问题。 那我们又如何使用这棵决策树来预测呢? 问题: 对于一个新的样本: (有雾,低,低,否), 它的预测值是多少?
决策树里的根节点是“天气情况”, 所以新的样本我们首先要看一下“天气情况”特征值为多少。对于新样本,它的值为“有雾”, 所以直接到达了(30, 22)这个叶节点上。那具体预测成30呢,还是22呢? 很显然,一个
简单的方法是取平均, 所以答案是26。
还有一个问题是,当我们使用决策树解决分类问题时,可以计算准确率来评估一个决策树的好坏。但对于回归问题则需要使用不同的指标,其中一个常用的指标叫作MSE(mean square error),也是线性
回归模型所使用的评估标准。
对于回归问题,需要评估MSE
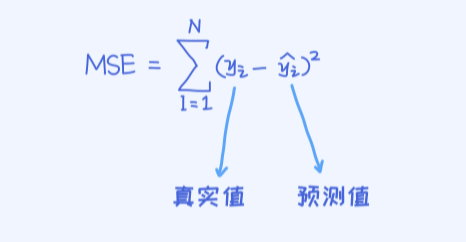
由于回归问题里实际值和真实值都是数值型的,所以需要计算出它俩之间的差异,这就是MSE的精髓。最后,我们还没有解决的问题是如何构造一棵决策树来做预测,或者说如何构造一棵回归树?
回想一下之前的决策树是如何构造的。之前做分类任务时,每次使用信息增益来选取当前最好的特征并作为根节点。信息增益的基础又是信息熵,它是用来表示不确定性的。对于回归问题,我们无非需
要定义的是如何表示不确定性。分类时使用的是信息熵,那回归问题上具体使用什么计算方法呢? 对于连续型变量,方差或者标准差是表示不确定性的重要指标! 不确定性已经知
道如何表示了。自然而然地,连续型变量的“信息增益”或者“不确定性的减少”无非就是前后标准差的变化! 如果一个特征能让一个标准差前后变化很大,即可以认为大大地降低不确定性,是好的特征!
构建回归决策树
回归问题中量化不确定性 = 标准差
||
寻找一个特征,分割前后标准差的差异最大
以上是针对于回归问题的总结。唯一的区别是把分类问题里的信息熵替换成了变量的标准差。
① 分裂前的标准差
计算均值u,再去计算标准差
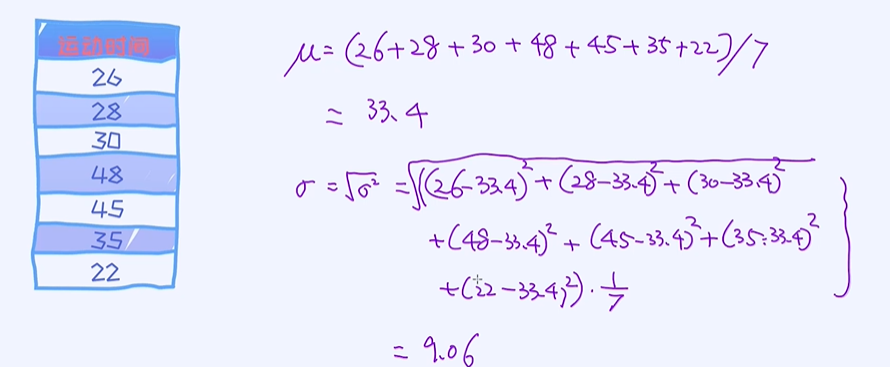
② 第一个特征,候选分裂特征:天气情况
之前的标准差9.06,之后的加权平均标准差,

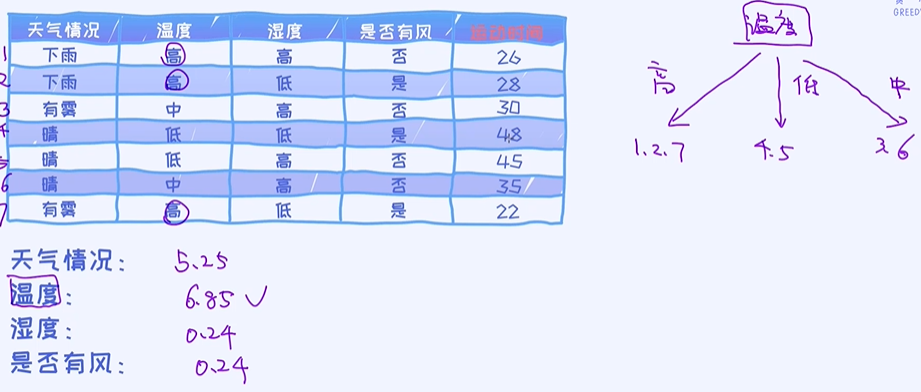
③ 第二个特征 候选分裂特征:温度

④ 第三个特征 候选分裂特征:湿度
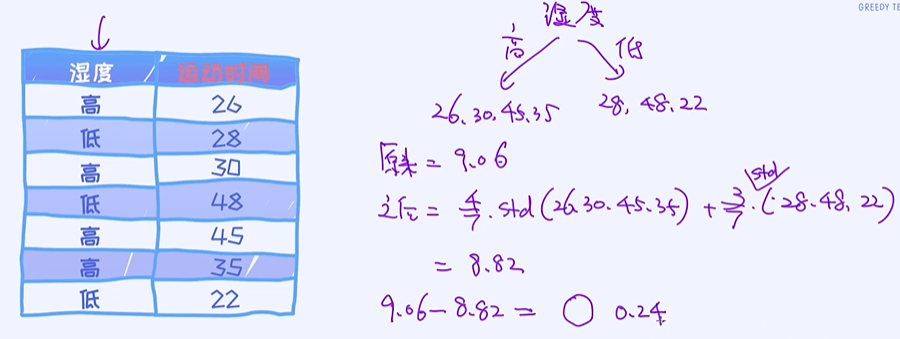
⑤ 第四个特征 候选分裂特征:是否有风

第一次分裂之后
可以看到温度是最好的特征

 浙公网安备 33010602011771号
浙公网安备 33010602011771号