
实时--1.4 业务数据| 事实表与事实表的关联| 双流Join
订单明细实付金额分摊以及交易额统计
需求分析
主订单的应付金额【origin_total_amount】一般是由所有订单明细的商品单价 * 数量汇总【sku_price * sku_num】组成。
但是由于优惠、运费等都是以订单为单位进行计算的,所以减掉优惠、加上运费会得到一个最终实付金额【final_total_amount】。
但问题在于如果是以商品进行交易额分析,就需要把优惠、运费分摊到购买的每个商品中。

① 准备订单明细数据
已经将订单和用户、是否首单状态以及省份进行关联,并且将宽表保存到了ES中,但是订单表中缺少订单明细,通过订单明细我们才能与商品进行关联,所以我们需要先准备订单明细数据,再让订单明细
与商品进行关联。
② 双流合并
除了订单事实表与维表进行合并形成宽表,还需要订单事实表与订单明细事实表进行合并形成更大的宽表。
③ 订单明细实付金额分摊
计算出订单中每一笔商品分摊后的实付金额
④ 将订单及明细保存到ClickHouse
⑤ 发布数据接口(统计新增交易额)
从ClickHouse中,查询出订单和订单明细数据,并提供数据接口,方便其它使用者进行统计分析。
1. 准备订单明细数据
订单和订单明细,都是实时产生的业务数据,如果将订单明细也当作维表进行处理,不能保证订单明细肯定先存在于维表中,
所以订单明细也应该作为事实表进行处理。然后再用订单明细和商品维表进行关联,获取商品相关信息
读取订单明细数据的类 OrderDetailApp
测试
- 运行 OrderDetailApp、BaseDBMaxwellApp
- 运行模拟生成业务数据的jar包
- OrderDetailApp控制台查看输出效果
订单明细实时表和商品、品牌、spu等维表关联
关联方式
(1) 方法1:用明细表依次和每个维度表进行关联
订单明细和商品关联
order_detail --> sku_id
订单明细商品宽表和spu关联
订单明细宽表(spu_id) --> spu 得到spuname
订单明细商品和spu宽表和品牌关联
订单明细宽表(tm_id) --> tm 得到tm_name
订单明细商品、spu、品牌宽表和品类关联
订单明细宽表(category3_id) --> cate 得到cate_name
这种方式,订单明细事实表记录很多,每条记录都进行4次关联,效率较低。
(2) 方法2:维度退化
- Spu、品牌、品类维度表提前进行关联(维度退化)得到商品维度表gmall_sku_info ;(一个spu_id 会有多个sku_id)
- 订单明细和 --> gmall_sku_info 维度宽表
使用这种方式
在Hbase中创建表与维表对应
接收用户数据的新增和修改 保存到hbase
(1) 创建品牌表
create table gmall_base_trademark (id varchar primary key ,tm_name varchar);
(2) 创建分类表
create table gmall_base_category3 (id varchar primary key ,name varchar ,category2_id varchar);
(3) 创建SPU表
create table gmall_spu_info (id varchar primary key ,spu_name varchar);
(4) 创建商品表,从上面三个维表汇总得到商品表
create table gmall_sku_info (id varchar primary key , spu_id varchar, price varchar, sku_name varchar, tm_id varchar, category3_id varchar, create_time varchar, category3_name varchar, spu_name varchar,
tm_name varchar ) SALT_BUCKETS = 3;
创建对应的样例类
(1)品牌样例类
case class BaseTrademark(
tm_id:String ,
tm_name:String
)
(2)分类样例类
case class BaseCategory3(
id:String ,
name:String ,
category2_id:String
)
(3)Spu样例类
case class SpuInfo(
id:String ,
spu_name:String
)
(4)商品样例类
case class SkuInfo(
id:String ,
spu_id:String ,
price:String ,
sku_name:String ,
tm_id:String ,
category3_id:String ,
create_time:String,
var category3_name:String,
var spu_name:String,
var tm_name:String
)
采集Kafka中维表数据到Hbase对应的表中
(1) 采集Kafka中品牌数据到Hbase
读取商品品牌维度数据到Hbase BaseTrademarkApp
(2) 采集Kafka中分类数据到Hbase
读取商品分类维度数据到Hbase BaseCategory3App
(3) 采集Kafka中Spu数据到Hbase
读取商品Spu维度数据到Hbase SpuInfoApp
(4) 采集Kafka中商品Sku数据到Hbase
读取商品维度数据,并关联品牌、分类、Spu,保存到Hbase SkuInfoApp
订单明细事实表和Sku维度关联
OrderDetailApp
测试
(1) 启动Hdfs、ZK、Kafka、Redis、Hbase、Maxwell
(2) 运行BaseDBMaxwellApp
(3) 运行BaseTrademarkApp,初始化品牌数据,在Hbase品牌表中查看效果
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop102 --database gmall --table base_trademark --client_id maxwell_1
(4) 运行BaseCategory3App,初始化分类数据,在Hbase分类表中查看效果
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop102 --database gmall --table base_category3 --client_id maxwell_1
(5) 运行SpuInfoApp,初始化SPU数据,在Hbase的SPU表中查看效果
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop102 --database gmall --table spu_info --client_id maxwell_1
(6) 运行SkuInfoApp,初始化商品数据,在Hbase商品表中查看效果
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop102 --database gmall --table sku_info --client_id maxwell_1
(7) 运行 OrderDetailApp,运行模拟生成业务数据的jar包,查看控制台输出
订单明细写入Kafka(DWD层)
OrderDetailApp
订单写入Kafka(DWD层)
OrderInfoApp
2. 双流合并实现
除了事实表与维表进行合并形成宽表,还需要事实表与事实表进行合并形成更大的宽表。
双流合并的问题
由于订单流和订单明细流,两个流的数据是独立保存,独立消费,很有可能同一业务的数据,分布在不同的批次。因为join算子只join同一批次的数据。如果只用简单的join流方式,会丢失掉不同批次的数据。
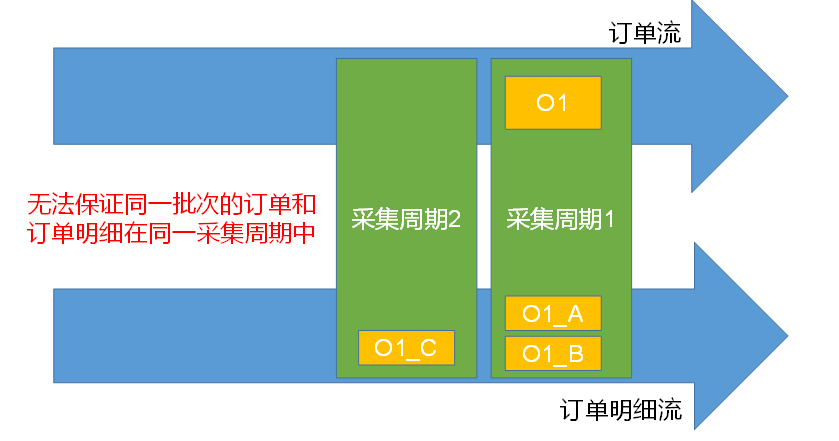
解决策略
① 通过缓存
两个流做满外连接因为网络延迟等关系,不能保证每个窗口中的数据key都能匹配上,这样势必会出现三种情况:(Some,Some),(None,Some),(Some,None),根据这三种情况,下面做一下详细解析:
- (Some,Some)
1号流和2号流中key能正常进行逻辑运算,但是考虑到2号流后续可能会有剩下的数据到来,所以需要将1号流中的key保存到redis,以等待接下来的数据
- (None,Some)
找不到1号流中对应key的数据,需要去redis中查找1号流的缓存,如果找不到,则缓存起来,等待1号流
- (Some,None)
找不到2号流中的数据,需要将key保存到redis,以等待接下来的数据,并且去reids中找2号流的缓存,如果有,则join,然后删除2号流的缓存
优点 不会造成数据重复
缺点 缓存处理代码编写复杂,尤其是流join比较多的情况。
② 通过滑动窗口+数据去重
优点处理代码相对简单
缺点会造成数据重复,需要对重复数据进行处理
注意:必须是滑动窗口,如果是滚动的话,也没有解决join问题。

双流Join处理代码
创建OrderWide样例类,用于封装订单以及订单明细信息
订单和订单明细样例类


/** * 订单和订单明细样例类 * @param order_detail_id * @param order_id * @param order_status * @param create_time * @param user_id * @param sku_id * @param sku_price * @param sku_num * @param sku_name * @param benefit_reduce_amount * @param feight_fee * @param original_total_amount * @param final_total_amount * @param final_detail_amount * @param if_first_order * @param province_name * @param province_area_code * @param user_age_group * @param user_gender * @param dt * @param spu_id * @param tm_id * @param category3_id * @param spu_name * @param tm_name * @param category3_name */ case class OrderWide( var order_detail_id: Long = 0L, var order_id: Long = 0L, var order_status: String = null, var create_time: String = null, var user_id: Long = 0L, var sku_id: Long = 0L, var sku_price: Double = 0D, var sku_num: Long = 0L, var sku_name: String = null, var benefit_reduce_amount: Double = 0D, var feight_fee: Double = 0D, var original_total_amount: Double = 0D, //原始总金额 = 明细 Σ 个数*单价 var final_total_amount: Double = 0D, //实际付款金额 = 原始购买金额-优惠减免金额+运费 //分摊金额 var final_detail_amount: Double = 0D, //首单 var if_first_order: String = null, //主表维度 : 省市 , 年龄段 性别 var province_name: String = null, var province_area_code: String = null, var user_age_group: String = null, var user_gender: String = null, var dt: String = null, // 从表的维度 spu,品牌,品类 var spu_id: Long = 0L, var tm_id: Long = 0L, var category3_id: Long = 0L, var spu_name: String = null, var tm_name: String = null, var category3_name: String = null ) //构造器, 上主构造器, this为辅构造器 { def this(orderInfo: OrderInfo, orderDetail: OrderDetail) { this mergeOrderInfo(orderInfo) mergeOrderInfo(orderDetail) } def mergeOrderInfo(orderInfo: OrderInfo): Unit = { if (orderInfo != null) { this.order_id = orderInfo.id this.order_status = orderInfo.order_status this.create_time = orderInfo.create_time this.dt = orderInfo.create_date this.benefit_reduce_amount = orderInfo.benefit_reduce_amount this.original_total_amount = orderInfo.original_total_amount this.feight_fee = orderInfo.feight_fee this.final_total_amount = orderInfo.final_total_amount this.province_name = orderInfo.province_name this.province_area_code = orderInfo.province_area_code this.user_age_group = orderInfo.user_age_group this.user_gender = orderInfo.user_gender this.if_first_order = orderInfo.if_first_order this.user_id = orderInfo.user_id } } def mergeOrderInfo(orderDetail: OrderDetail): Unit = { if (orderDetail != null) { this.order_detail_id = orderDetail.id this.sku_id = orderDetail.sku_id this.sku_name = orderDetail.sku_name this.sku_price = orderDetail.order_price this.sku_num = orderDetail.sku_num this.spu_id = orderDetail.spu_id this.tm_id = orderDetail.tm_id this.category3_id = orderDetail.category3_id this.spu_name = orderDetail.spu_name this.tm_name = orderDetail.tm_name this.category3_name = orderDetail.category3_name } } }
3. 订单明细实付金额分摊实现
需求分析
主订单的应付金额【origin_total_amount】一般是由所有订单明细的商品单价*数量汇总【order_price*sku_num】组成。
但是由于优惠、运费等都是以订单为单位进行计算的,所以减掉优惠、加上运费会得到一个最终实付金额【final_total_amount】。
但问题在于如果是以商品进行交易额分析,就需要把优惠、运费分摊到购买的每个商品中。
如何分摊
一般是由订单明细每种商品的消费占总订单的比重进行分摊,比如总价1000元的商品,由600元和400元的A、B两种商品组成, 但是经过打折和加运费后,实际付款金额变为810,那么A的分摊实付金额为486元和B的分摊实付金额为324元。
麻烦的情况
由于明细的分摊是由占比而得,那就会进行除法,除法就有可能出现除不尽的情况。
比如:原价90元 ,三种商品每件30元。没有优惠但有10元运费,总实付金额为100元。按占比分摊各三分之一,就会出现三个33.33元。加起来就会出现99.99元。就会出现差一分钱的情况。
而我们要求所有订单明细的实付分摊加总必须和订单的总实付相等。
所以我们要的是100=33.33+33.33+33.34
解决思路
- 核心思路:就是需要用两种算法来计算金额
算法一:如果计算时该明细不是最后一笔
使用乘除法公式:实付分摊金额 / 实付总金额 = (数量*单价)/原始总金额
调整移项可得 实付分摊金额 = 实付总金额 * (数量 * 单价) / 原始总金额
算法二: 如果计算时该明细是最后一笔
使用减法公式:
实付分摊金额= 实付总金额 - (其他明细已经计算好的【实付分摊金额】的合计)
- 判断是否是最后一笔
判断公式:
如果 该条明细 (数量*单价) == 原始总金额 -(其他明细 【数量*单价】的合计)
- 整个计算中需要的两个合计值:
其他明细已经计算好的【实付分摊金额】的合计
订单的已经计算完的明细的【数量*单价】的合计
如何保存这两个合计?保存在redis中。
|
type |
Key |
说明 |
|
String |
order_origin_sum:[order_id] |
订单的已经计算完的明细的【数量*单价】的合计 |
|
String |
order_split_sum: [order_id] |
其他明细已经计算好的【实付分摊金额】的合计 |
4. 将订单及明细保存到ClickHouse实现
ClickHouse入门参照ClickHouse文档
在hadoop102的ClickHouse中建表
表结构和程序中OrderWide类的字段对应
create table t_order_wide ( order_detail_id UInt64, order_id UInt64, order_status String, create_time DateTime, user_id UInt64, sku_id UInt64, sku_price Decimal64(2), sku_num UInt64, sku_name String, benefit_reduce_amount Decimal64(2), original_total_amount Decimal64(2), feight_fee Decimal64(2), final_total_amount Decimal64(2), final_detail_amount Decimal64(2), if_first_order String, province_name String, province_area_code String, user_age_group String, user_gender String, dt Date, spu_id UInt64, tm_id UInt64, category3_id UInt64, spu_name String, tm_name String, category3_name String )engine =ReplacingMergeTree(create_time) partition by dt primary key (order_detail_id) order by (order_detail_id );
Idea中编写程序
OrderWideApp添加写到ClickHouse代码
测试
(1) 启动Hdfs、ZK、Kafka、Redis、Hbase、Maxwell、ES
(2) 运行BaseDBMaxwellApp、OrderInfoApp、OrderDetailApp、OrderWideApp,运行模拟生成业务数据jar包,查询ClickHouse表
5. 发布数据接口(统计新增交易额)实现
从ClickHouse或者其它支持JDBC协议的数据中,查询出订单和订单明细数据,并提供数据接口,方便其它使用者进行统计分析
spark错误
* Null value appeared in non-nullable field
java.lang.NullPointerException: Null value appeared in non-nullable field: top level row object
If the schema is inferred from a Scala tuple/case class, or a Java bean, please try to use scala.Option[_] or other nullable types (e.g. java.lang.Integer instead of int/scala.Int).
解决:在dataframe中增加过滤row==null的Row
df.filter(row -> row != null)
-Dspark.sql.shufle.partitions=1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号