
ElasticSearch| Kibana | 安装和配置
1. ElasticSearch概述
Elasticsearch是一个高度可伸缩的 基于Apache Lucene(TM)的 开源全文搜索引擎。Elasticsearch让你可以快速、实时地存储、搜索和分析大量数据,它通常作为互联网应用的内部搜
索引擎,为需要复杂搜索功能的应用提供支持。
ElasticSearch是一个基于Lucene的搜索服务器(Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库)。它提供了一个分布式多用户能力的全文搜索引擎,基
于RESTful web接口(通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单)。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
使用场景
- 电商搜索引擎,使用Elasticsearch存储商品与品类信息,提供搜索和搜索建议功能(全文检索)。
- 日志系统,收集、分析日志数据,可以使用Logstash (Elasticsearch/Logstash/Kibana栈的一部分)来收集,然后将这些数据提供给Elasticsearch,通过搜索和聚合计算挖掘有价值的信息,最后通过Kibana进行可视化展示。
- 价格提醒平台,在价格变动时,让用户可以收到通知。抓取供应商的价格,推入Elasticsearch,并使用其反向搜索(Percolator)功能来匹配用户的价格通知设置,找到匹配后将提醒推送给用户。
- BI(商业智能),分析业务大数据,挖掘有价值的商务信息。可以使用Elasticsearch来存储数据,然后使用Kibana (Elasticsearch/Logstash/Kibana堆栈的一部分)构建自定义仪表板,该仪表板可以可视化显示数据。此外,还可以使用Elasticsearch聚合功能对数据执行复杂的业务智能分析。
ES能做什么?
全文检索(全部字段;值--->数据)、模糊查询(搜索)、数据分析(提供分析语法,例如聚合)
数仓--分析处理--hbase/mysql--es--(分析、检索、搜索、javaee前端可视化)
ES与其他数据存储的比较
|
|
redis |
mysql |
elasticsearch |
hbase |
hadoop/hive |
|
容量/容量扩展 |
低 |
中 |
较大 |
海量 |
海量 |
|
查询时效性 |
极高 |
中等 |
较高 |
中等 |
低 |
|
查询灵活性 |
较差 k-v模式 |
非常好,支持sql |
较好,关联查询较弱,但是可以全文检索,DSL语言可以处理过滤、匹配、排序、聚合等各种操作 |
较差,主要靠rowkey, scan的话性能不行,或者建立二级索引 |
非常好,支持sql |
|
写入速度 |
极快 |
中等 |
较快 |
较快 |
慢 |
|
一致性、事务 |
弱 |
强 |
弱 |
弱 |
弱 |
Solr、ES、Hermes的区别
Solr、ElasticSearch、 Hermes(腾讯开发;主要用于实时检索分析,处理数据量庞大)3者的区别
Solr、ES(都可以做全文检索、搜索、分析,基于lucene)
①. 源自搜索引擎,侧重搜索与全文检索。
②. 数据规模从几百万到千万不等,数据量过亿的集群特别少。
有可能存在个别系统数据量过亿,但这并不是普遍现象(就像Oracle的表里的数据规模有可能超过Hive里一样,但需要小型机)。
Solr、ES区别
①. Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
②. Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
③. Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
④. Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
Hermes
①. 一个基于大索引技术的海量数据实时检索分析平台。侧重数据分析。
②. 数据规模从几亿到万亿不等。最小的表也是千万级别。
在 腾讯17 台TS5机器,就可以处理每天450亿的数据(每条数据1kb左右),数据可以保存一个月之久。
Lucene、Nutch、Es
① Lucene是第一个提供全文文本搜索的函数库,提供了一个简单而强大的应用程序接口,是一个高性能、可伸缩的信息搜索库。
② Nutch是在Lucene基础上将开源思想继续深化,是一个真正的应用程序,建立在Lucene核心之上的Web搜索的实现,目的是减少使用过程中的复杂度,实现开箱即用的特性。
③ ES是一个开源的高扩展的分布式全文检索引擎,可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。ES使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
处理分词,构建倒排索引,等等,都是这个叫Lucene的做的。那么能不能说这个Lucene就是搜索引擎呢?
不能。Lucene只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来的应用。好比Lucene是类似于发动机,而搜索引擎软件(ES,Solr)就
是汽车。目前市面上流行的搜索引擎软件,主流的就两款,ElasticSearch和Solr,这两款都是基于Lucene的搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者
除了服务器安装、部署、管理、集群以外,对于数据的操作,修改、添加、保存、查询等等都十分类似。就好像都是支持sql语言的两种数据库软件。只要学会其中一个另一个很容易
上手。
ES特点
分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎库(可做不规则查询)
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
天然分片,天然集群
ES把数据分成多个shard,下图中的P0-P2,多个shard可以组成一份完整的数据,这些shard可以分布在集群中的各个机器节点中。随着数据的不断增加,集群可以增加多个分片,
把多个分片放到多个机子上,已达到负载均衡,横向扩展。
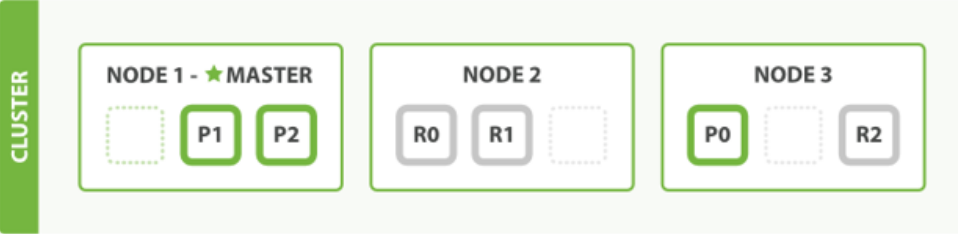
在实际运算过程中,每个查询任务提交到某一个节点,该节点必须负责将数据进行整理汇聚,再返回给客户端,也就是一个简单的节点上进行Map计算,在一个固定的节点上进行
Reduces得到最终结果向客户端返回。
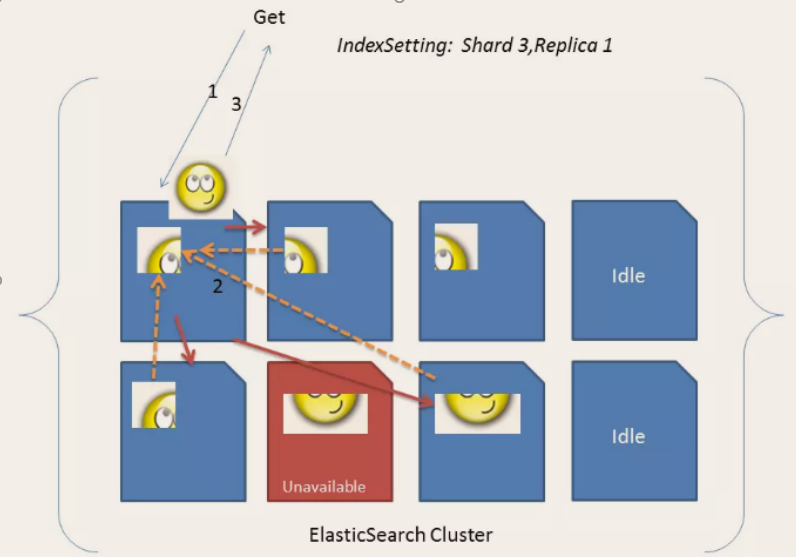
这种集群分片的机制造就了elasticsearch强大的数据容量及运算扩展性。
天然索引
ES 所有数据都是默认进行索引的,这点和MySQL正好相反,MySQL是默认不加索引,要加索引必须特别说明,ES只有不加索引才需要说明。
而ES使用的是倒排索引和MySQL的B+Tree索引不同。
传统关系性数据库

弊端
- 对于传统的关系性数据库对于关键词的查询,只能逐字逐行的匹配,性能非常差。
- 匹配方式不合理,比如搜索“小密手机”,如果用like进行匹配, 根本匹配不到。但是考虑使用者的用户体验的话,除了完全匹配的记录,还应该显示一部分近似匹配的记录,至少应该匹配到“手机”。
倒排索引是怎么处理的
全文搜索引擎目前主流的索引技术就是倒排索引的方式。 传统的保存数据的方式都是:记录→单词
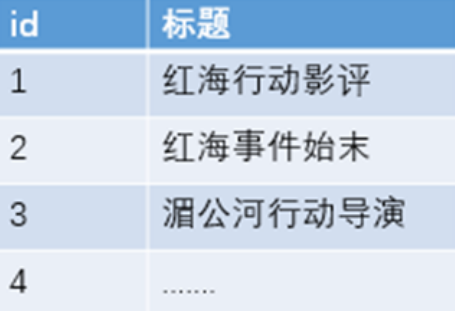
而倒排索引的保存数据的方式是:
单词→记录,基于分词技术构建倒排索引,每个记录保存数据时,都不会直接存入数据库。系统先会对数据进行分词,然后以倒排索引结构保存。如下:

搜索“红海行动”,搜索引擎是如何将两者匹配上的呢?
等到用户搜索的时候,会把搜索的关键词也进行分词,会把“红海行动”分词分成:红海和行动两个词。这样的话,先用红海进行匹配,得到id=1和id=2的记录编号,再用行动匹配可以
迅速定位id为1,3的记录。
那么全文索引通常,还会根据匹配程度进行打分,显然1号记录能匹配的次数更多。所以显示的时候以评分进行排序的话,1号记录会排到最前面。而2、3号记录也可以匹配到。
索引结构对比
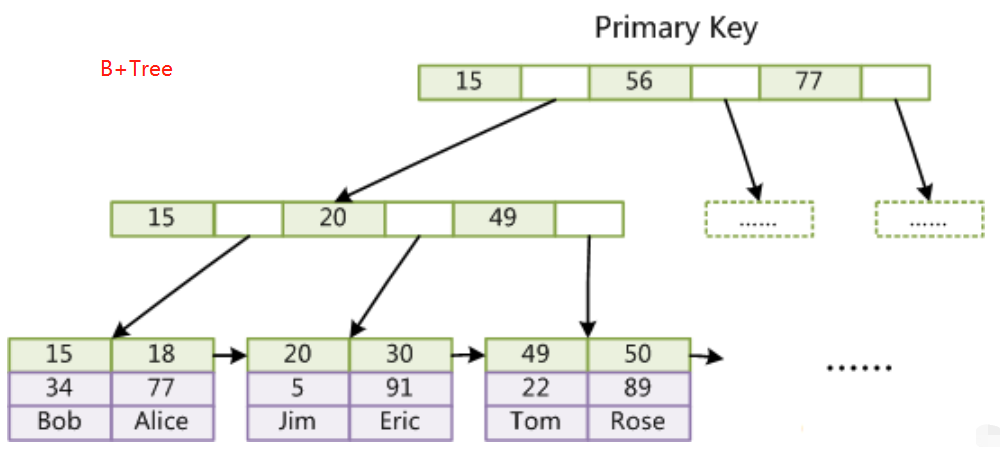
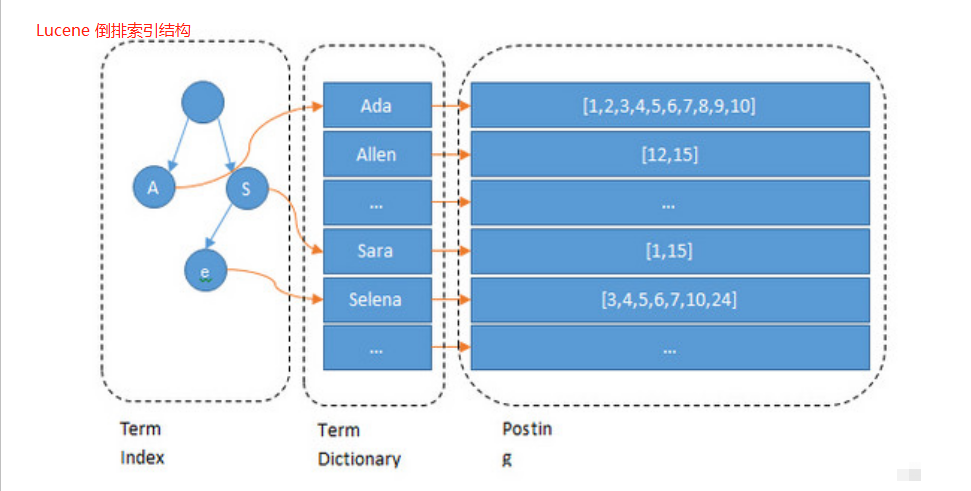
可以看到 Lucene为倒排索引(Term Dictionary)部分又增加一层Term Index结构,用于快速定位,而这Term Index是缓存在内存中的,但MySQL的B+tree不在内存中,所以整体来看ES
速度更快,但同时也更消耗资源(内存、磁盘)。
2. 安装和配置
Elasticsearch官网:
https://www.elastic.co/products/elasticsearch
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-6-0
ES是开箱即用的,即解压就可以使用
tar -zxvf elasticsearch-6.6.0.tar.gz -C /opt/module/
mv elasticsearch-6.6.0/ elasticsearch
修改ES配置文件
修改yml配置的注意事项:
每行必须顶格,不能有空格
“:”后面必须有一个空格
[kris@hadoop101 elasticsearch]$ vim config/elasticsearch.yml
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# 集群名称,同一集群名称必须相同
cluster.name: my-es
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 单个节点名称
node.name: node-1
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
# 把bootstrap自检程序关掉 bootstrap.system_call_filter: false
bootstrap.memory_lock: true
bootstrap.system_call_filter: false
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
# 网络部分 改为当前的ip地址 ,端口号保持默认9200就行
network.host: hadoop101
#
# Set a custom port for HTTP:
#
#http.port: 9200
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
# 自发现配置:新节点向集群报到的主机名
discovery.zen.ping.unicast.hosts: ["hadoop101", "hadoop102", "hadoop103"]
ES是用在Java虚拟机中运行的,虚拟机默认启动占用1G内存。但是如果是装在PC机学习用,实际用不了1个G。所以可以改小一点内存;但生产环境一般128G内存是标配,这个时候需要将这个内存调大。
vim /opt/module/elasticsearch/config/jvm.options
## JVM configuration
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms512m
-Xmx512m
分发ES到另外两台节点 xsync elasticsearch/
修改hadoop102和hadoop103上的节点名以及网络地址
hadoop102修改为:node.name: node-2 network.host: hadoop102
[kris@hadoop102 ~]$ cd /opt/module/elasticsearch/config/
[kris@hadoop102 config]$ vim elasticsearch.yml
hadoop103修改为:node.name: node-3 network.host: hadoop103
[kris@hadoop103 ~]$ cd /opt/module/elasticsearch/config/
[kris@hadoop103 config]$ vim elasticsearch.yml
单台启动测试,以及Linux解决常见问题
这时直接在hadoop101上单独启动ES,[kris@hadoop101 bin]$ ./elasticsearch
会报如下异常:

因为默认elasticsearch是单机访问模式,就是只能自己访问自己。但是上面我们已经设置成允许应用服务器通过网络方式访问,而且生产环境也是这种方式。这时,Elasticsearch就会
因为嫌弃单机版的低端默认配置而报错,甚至无法启动。所以我们在这里就要把服务器的一些限制打开,能支持更多并发。
问题1:
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] elasticsearch
原因:系统允许 Elasticsearch 打开的最大文件数需要修改成65536
解决 sudo vim /etc/security/limits.conf
添加内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 65536
注意:“*” 不要省略掉
分发文件
sudo /home/kris/bin/xsync /etc/security/limits.conf
问题2:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
原因:一个进程可以拥有的虚拟内存区域的数量。
解决: sudo vim /etc/sysctl.conf
在文件最后添加一行
vm.max_map_count=262144
即可永久修改
分发文件
sudo /home/kris/bin/xsync /etc/sysctl.conf
问题3:
max number of threads [1024] for user [judy2] likely too low, increase to at least [4096] (CentOS7.x 不用改)
原因: 允许最大线程数修该成4096
解决: sudo vim /etc/security/limits.d/20-nproc.conf
修改如下内容
* soft nproc 1024
修改为
* soft nproc 4096
分发文件
sudo /home/kris/bin/xsync /etc/security/limits.d/20-nproc.conf
重启linux使配置生效
再次单独启动hadoop101上的ES
[kris@hadoop101 bin]$ ./elasticsearch
测试方式1:curl http://hadoop101:9200/_cat/nodes?v

测试方式2:在浏览器中,输入http://hadoop101:9200/查看效果
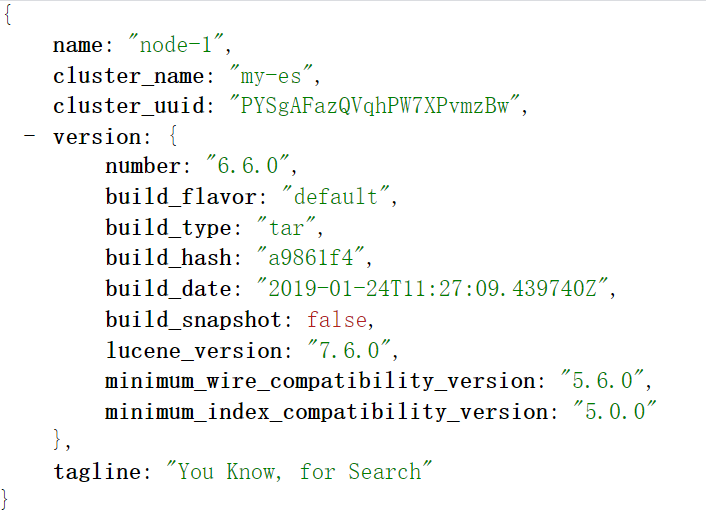
ES天然就是集群状态,就算是只有一个节点,也会当做集群处理,
默认节点name=主机名,cluster_name=my_es
集群启动脚本
在/home/kris/bin 目录下创建es.sh,并授予执行权限
根据自己的配置进行修改
#!/bin/bash
es_home=/opt/module/elasticsearch
case $1 in
"start") {
for i in hadoop101 hadoop102 hadoop103
do
echo "==============$i上ES启动=============="
ssh $i "source /etc/profile;${es_home}/bin/elasticsearch >/dev/null 2>&1 &"
done
};;
"stop") {
for i in hadoop101 hadoop102 hadoop103
do
echo "==============$i上ES停止=============="
ssh $i "ps -ef|grep $es_home |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac
如果启动未成功,查看相关日志 vim /opt/module/elasticsearch/logs/my-es.log
3. Kibana的安装
Elasticsearch提供了一套全面和强大的REST API,我们可以通过这套API与ES集群进行交互。例如:
我们可以通过 API: GET /_cat/nodes?v获取ES集群节点情况,要想访问这个API,我们需要使用curl命令工具来访问Elasticsearch服务
curl http://hadoop101:9200/_cat/nodes?v
也可以使用任何其他HTTP/REST调试工具,例如POSTMAN。
Kibana 是为 Elasticsearch设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视
化,以图表的形式展现出来。
解压并重命名
tar -zxvf kibana-6.6.0-linux-x86_64.tar.gz -C /opt/module/
mv kibana-6.6.0-linux-x86_64/ kibana
修改Kibana配置文件
[kris@hadoop101 kibana]$ vim config/kibana.yml
# To allow connections from remote users, set this parameter to a non-loopback address.
# 授权远程访问
server.host: "0.0.0.0"
# The URLs of the Elasticsearch instances to use for all your queries.
# 指定ElasticSearch地址(可以指定多个,多个地之间用逗号分隔)
elasticsearch.hosts:
["http://hadoop101:9200","http://hadoop102:9200","http://hadoop103:9200"]
启动、测试
Kibana本身只是一个工具,不需要分发,不涉及集群,访问并发量也不会很大
启动Kinana [kris@hadoop101 kibana]$ bin/kibana
浏览器访问 http://hadoop101:5601/
在6.7版本之后,支持中文国际化
最终集群脚本
在es.sh中,对ES和Kibana同时进行操作
在/opt/module/kibana目录下执行mkdir logs
vim /home/kris/bin/es.sh # 启动 和 停止 ES、 kibana的脚本。
#!/bin/bash
es_home=/opt/module/elasticsearch
kibana_home=/opt/module/kibana
case $1 in
"start") {
for i in hadoop101 hadoop102 hadoop103
do
echo "==============$i上ES启动=============="
ssh $i "source /etc/profile;${es_home}/bin/elasticsearch >/dev/null 2>&1 &"
done
nohup ${kibana_home}/bin/kibana >${kibana_home}/logs/kibana.log 2>&1 &
};;
"stop") {
ps -ef|grep ${kibana_home} |grep -v grep|awk '{print $2}'|xargs kill
for i in hadoop101 hadoop102 hadoop103
do
echo "==============$i上ES停止=============="
ssh $i "ps -ef|grep $es_home |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac
4. 基本概念
开发视角: 索引、文档, 逻辑上的概念
运维视角: 节点、分片, 物理上的概念
① 文档(Document)
Elasticsearch 是面向文档的,文档是所有课搜索数据的最小单位;
- 日志文件中的日志项;
- 一本电影的具体信息/ 一张唱片的详细信息;
- MP3播放器里的一首歌/ 一篇PDF文档中的具体内容
文档会被序列化成JSON格式,保存在ES中
- JSON对象由字段组成,
- 每个字段都有对应的字段类型(字符串、数值、布尔、日期、二进制、范围类型)
每个文档都有一个Unique ID
- 可以自己制定ID
- 或者通过ES自动生成
GET /movie_index/movie/3, 默认情况下,返回结果是按相关性倒序排列的。
文档的元数据,用于标识文档的相关信息
- _index: 文档所在索引名称;
- _type: 文档所在类型名称;
- _id: 文档唯一id
- _source:文档的原始Json数据,包括每个字段的内容
- _all: 将所有字段内容整合起来,默认禁用被废弃(用于对所有字段内容检索)
- _version: 文档的版本信息。
- _score:每个文档都有相关性评分,
_score的评分越高,相关性越高
version乐观锁---控制版本号;每次更新数据时,version数值会不一样;
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "3",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"id" : 300,
"name" : "incident red sea",
"doubanScore" : 5.0,
"actorList" : [
{
"id" : 4,
"name" : "zhang san feng"
}
]
}
}
② 索引
索引名词:类文档的集合;索引动词:把一个文档写入ES的过程。(抛开ES,索引可能是指一个B树索引,一个倒排索引)
GET /movie_index ,索引是文档的容器,是一类文档的结合;
- Index体现了逻辑空间的概念: 每个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型。
- Shard体现了物理空间的概念: 索引中的数据分散在Shard分片上。
索引的Mapping与Settings
- Mapping定义索引中所有文档字段名和类型;
- Setting定义不同的数据分布,指定要用多少个分片;

③ Type
- 在7.0之前,一个index可以设置多个Type(每个Type底下会相同结构的文档)
- 6.0开始,Type已经被Deprecated废除。
- 7.0开始一个索引只能创建一个Type-"_doc"
抽象与类比
| RDBMS关系型数据库 | ES |
| Table表 | Index(Type) |
| Row每条记录 | Doucment |
| Column每个字段 | Filed |
| Schema表定义 | Mapping |
| SQL查询 | DSL |
在7.0之前,一个index可以设置多个Types
目前Type已经被Deprecated,7.0开始,一个索引只能创建一个Type - "_doc"
传统关系型数据库和ES的区别
- Elasticsearch-Schemaless /相关性/高性能全文检索
- RDMS - 事务性/ Join
REST-API很容易被各种语言调用,发起HTTP请求就可以得到结果。

一些基本的API
Indices
创建Index
Put Movies
查看所有Index
_cat/indices
5. Elasticsearch的交互方式
1、基于HTTP协议,以JSON为数据交互格式的RESTful API(请求方式:GET/POST/PUT/DELETE/HEAD)
# 状态查看命令
语法:ip:post/_cat/[args](?v|?format=json&pretty)
(?v表示显示字段说明,?format=json&pretty表示显示成json格式)
1、查看所有索引
GET _cat/indices?v
2、查看es集群状态
GET _cat/health?v
http://192.168.1.101:9200/_cat 在浏览器中输入可以看到它的一些命令
http://192.168.1.101:9200/_cat/health 查看健康状态;
2、Elasticsearch官方提供了多种程序语言的客户端—java,Javascript,.NET,PHP,Perl,Python,以及 Ruby——还有很多由社区提供的客户端和插件
Elasticsearch操作工具(用浏览器测试手动只能完成GET,其他的需要借助工具完成PUT/POST等)
- 浏览器(postman)
- Linux命令行
- Kibana的Dev Tools
linux命令行
CURL命令是在命令行下访问url的一个工具
curl是利用URL语法在命令行方式下工作的开源文件传输工具,使用curl可以简单实现常见的get/post请求。
curl -i -XGET hadoop102:9200/movie_index/movie/3?pretty
curl
- -X 指定http请求的方法, HEAD GET POST PUT DELETE
- -d 指定要传输的数据
HEAD使用
如果只想检查一下文档是否存在,你可以使用HEAD来替代GET方法,这样就只会返回HTTP头文件
curl -i -XHEAD hadoop102:9200/movie_index/movie/3?pretty
PUT 和 POST 用法
PUT是幂等方法,POST不是。所以PUT用于更新、POST用于新增比较合适。 PUT,DELETE 操作是幂等的。所谓幂等是指不管进行多少次操作,结果都一样。
POST操作不是幂等的,如常见的POST重复加载问题:当我们多次发出同样的POST请求后,其结果是创建出了若干的资源。
创建操作可以使用POST,也可以使用PUT,区别在于:
POST是作用在一个集合资源之上的/articles),
PUT操作是作用在一个具体资源之上的(/articles/123),
比如说很多资源使用数据库自增主键作为标识信息,而创建的资源的标识信息到底是什么只能由服务端提供,这个时候就必须使用POST。
如果没有明确指定索引数据的ID,那么es会自动生成一个随机的ID,需要使用POST参数
https://blog.csdn.net/u013063153/article/details/74108023
GET 索引 _mapping 是查看字段的结构类型,ES可以自动推断出来,但这种是很不讲究的;
ES文本字段类型有:
- text(分词,占据很大资源,用空间换取时间;text还有一个局限性就是分词字段是不能聚合的,groupBy后边的字段,如果有这种字段就要设置成不分词)
- keyword(不分词,比如订单状态、手机号等);本质上这两个都是加索引的,只是一个分词一个不分词;
要不要索引:
与mysql正好相反,ES只要是插入默认都是会加索引的;过滤、聚合、搜索、匹配、排序等这些字段是需要索引,有些字段是不需要索引的,如电话脱敏的不需要索引;
加索引也是会浪费很大空间,如果不加索引得加上:“index”:false
6. Elasticsearch检索 URI查询没有请求体
GET/my_*/_search 可匹配所有的月份
2019-03-xx
2019-04-xx
检索文档
Mysql : select * from user where id = 1;
ES : GET /kris/doc/1 ;可以把/kris/doc理解为表名user,检索id=1的;
简单检索
Mysql : select * from user;
ES : GET /kris/doc/_search GET /megacorp/employee/_search
全文检索
ES : GET /megacorp/employee/_search?q=haha (查询字段中带有haha的数据,q相当于关键字,haha为值); 指定字段查询q=user:kris或q=kris;
查询出所有文档字段值为haha的文档;
q="want to"组合查询,没有""是单个和组合都会查询到
GET /my_index/_search?q=alfred&df=user&sort=age:asc&from=4&size=10&timeout=1s #from, size是用于分页;
q : 指定查询的语句,例如q=aa或q=user:aa
df:q中不指定字段默认查询的字段,如果不指定,es会查询所有字段
Sort:排序,asc升序,desc降序
timeout:指定超时时间,默认不超时
from,size:用于分页;from从第 页查询 size页
搜索
ES : GET /megacorp/employee/_search?q=hello (只要字段中包含hello,不管前边后边有什么值都可以查询到)
查询出所有文档字段值分词后包含hello的文档;mysql中的模糊查询(会影响性能,索引就不能使用了;)不规则匹配查询;搜索;
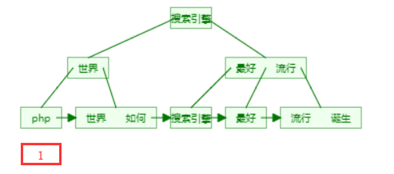
7. 正排索引和倒排索引
正排索引
记录文档Id到文档内容、单词的关联关系。例如一本书的目录:

倒排索引

图书和搜索引擎的类比
图书
- 正排索引 - 目录页
- 倒排索引 - 索引页
搜索引擎
- 正排索引 - 文档Id到文档内容和单词的关联;
- 倒排索引 - 单词到文件Id的关系。

倒排索引的核心组成:
倒排索引包含两个部分
① 单词词典(Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系;
- 单词词典一般比较大,可以通过B+树或哈希拉链法(去存储单词的词典)实现,以满足高性能的插入与查询。
② 倒排列表(Posting List)- 记录了单词对应的文档结合,由倒排索引项组成;
- 倒排索引项(Posting)
-
- 文档ID;
- 词频TF - 该单词在文档中出现的次数,用于相关性评分(评分,想把搜索内容靠前些,即可把评分高点就会靠前了;);
- 位置(Position)- 单词在文档中分词的位置,用于语句搜索(phrase query);记录Field分词后,单词所在的位置,从0开始;北京 是 最 漂亮 的,北京在0位;
- 偏移(Offset) - 记录单词的开始结束位置,实现高亮显示。
-
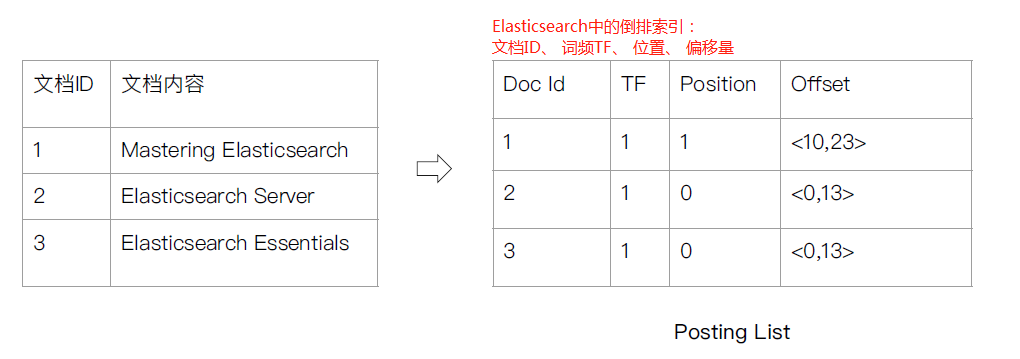
Elasticsearch的倒排索引
ES中的JSON文档中的每个字段,都有自己的倒排索引;
可以指定堆某些字段不做索引,优点是节省存储空间,缺点是字段无法被搜索。
search: 关键字;对关键字分词;
分词-->在资源库(比如百度,对分词在资源库中进行批评)中做一个全文搜索;
在资源库中也会有一个分词(每个字段都会进行分词);
倒排索引:(值---关键字(文档id的集合等)去匹配倒排索引---->数据文档(得到每一个具体的文档的ID));用值去找文档ID即倒排索引;
分词:
k1: v1,
k1: v1,v2,
k1: v3
倒排索引:每个词对应的id会形成 索引
v1:1, 2
v2:2 (只有第二个中有这个值)
v3:3
分词后(通过B+Tree)就可以高效查询;
8. 内存结构--B+Tree
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
每个文档字段都有自己的倒排索引
比如:北京 是 最 漂亮 的

每个值都会通过算法计算出一个值,那句话中某个值去搜索,它会先去顶点,如果比这个值(最)大就看左边(是),比它大就在左边(北京);
通过北京这个词就可以看到倒排索引,id、TF、Position、Offset等; B+Tree每个单元最多2个
它的所有数据都保存在最后一层的节点上,每两个节点之间会有一个链表(一个指向);可以递归获取这个值;
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
https://www.cs.usfca.edu/~galles/visualization/ComparisonSort.html
Elasticsearch集群
分布式系统的可用性与扩展性
高可用性
服务可用性-允许有节点停止服务
数据可用性-部分节点丢失,不会丢失数据
可扩展性
请求量提升/数据的不断增长(将数据分布到所有节点上)
分布式特性
① ES的分布式架构好处
- 存储的水平扩容
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
② ES的分布式架构
- 不同的集群通过不同的名字来区分,默认名字"elasticsearch"
- 默认配置文件修改,或者在命令行中-E cluster.name=mycluster 进行设定
- 一个集群可以有一个或者多个节点
节点
节点是一个Elasticsearch的实例,本质上就是一个JAVA进程,一台机器上可以运行多个Elasticsearch进程,但生产环境一般一台机器上只运行一个Elasticsearch实例。
每一个节点都有名字,通过配置文件配置,或者启动的时候 -E node.name=node1指定。
每一个节点在启动之后,会分配一个UID,保存在date目录。
Master-eligible nodes和 Master Node 节点
每个节点启动,默认就是一个Master eligible节点,可以设置node.name:false禁止;
Master-eligible节点可以参加选主流程,成为Master节点;
当第一个节点启动时候,它会将自己选举成Master节点;
每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息。
集群状态信息(cluster state),维护了一个集群中,必要的信息:
-
-
- 所有的节点信息;
- 所有的索引和其相关的Mapping 与Setting信息;
- 分片的路由信息。
-
任意节点都能修改信息会导致数据的不一致性。
Data Node & Coordinating Node
Data Node,可以保存数据的节点,叫做Data Node,负责保存分片数据。在数据扩展上起到了至关重要的作用。
Coordinating Node 负责接受Client的请求,将请求分发到合适的节点,最终把结果汇聚到一起;每个节点默认都起到了Coordinating Node的职责。
其他的节点类型
Hot & Warm Node,不同硬件配置的Data Node,用来实现 Hot & Warm架构,降低集群部署的成本;
Machine Learning Node,负责机器学习的Job,用来做异常检测;
Tribe Node (5.3开始使用Cross Cluster Search)Tribe Node 连接到不同的Elasticsearch集群,并且支持将这些集群当成一个单独的集群处理。
配置节点类型
开发环境中一个节点可以承担多种角色; 生产环境中,应该设置单一的角色节点(dedicated node)

分片(Primary Shard & Replica Shard)
主分片,用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上。
- 一个分片是一个运行的Lucene的实例;
- 主分片树在索引创建时指定,后序不运行修改,除非Reindex;
副本,用以解决数据高可用的问题,分片是主分片的拷贝
- 副本分片树,可以动态调整;
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
一个三个节点的集群中,blogs索引的分片分布情况:
思考增加一个节点或者改大主分片数对系统的影响。

分片的设定
对于生产环境中分片的设定,需要提前做好容量规划:
分片数设置过小,导致后序无法增加节点实现水平扩展;单个分片的数据量太大,导致数据重新分配耗时。
分片数设置过大(7.0开始,默认主分片设置成1个,解决了over-sharding的问题),
影响搜索结果的相关性打分,影响统计结果的准确性; 单个节点上过多的分片,会导致资源浪费,同时会影响性能。
集群的健康状况
查看集群的健康状况:
GET _cluster/health { "cluster_name" : "my-es", "status" : "green", #Green - 主分片与副本都正常分配,Yellow-主分片全部正常分配,有副本分片未能正常分配,Red-有主分片未能分配 "timed_out" : false, "number_of_nodes" : 3, #一共3个节点 "number_of_data_nodes" : 3, #这3个节点都承担了data_node的角色 "active_primary_shards" : 37, #一共37个主分片 "active_shards" : 74, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
GET _cat/nodes 192.168.1.102 67 76 0 0.13 0.08 0.07 mdi * node-1 192.168.1.104 59 55 0 0.00 0.01 0.05 mdi - node-3 192.168.1.103 42 55 0 0.00 0.01 0.05 mdi - node-2
GET _cat/shards


movie_index 3 r STARTED 1 5kb 192.168.1.102 node-1 movie_index 3 p STARTED 1 5kb 192.168.1.104 node-3 movie_index 4 r STARTED 1 4.9kb 192.168.1.102 node-1 movie_index 4 p STARTED 1 4.9kb 192.168.1.104 node-3 movie_index 1 r STARTED 0 261b 192.168.1.103 node-2 movie_index 1 p STARTED 0 261b 192.168.1.104 node-3 movie_index 2 r STARTED 1 4.9kb 192.168.1.103 node-2 movie_index 2 p STARTED 1 4.9kb 192.168.1.104 node-3 movie_index 0 p STARTED 0 261b 192.168.1.103 node-2 movie_index 0 r STARTED 0 261b 192.168.1.102 node-1 website 3 p STARTED 1 4.5kb 192.168.1.102 node-1 website 3 r STARTED 1 4.5kb 192.168.1.104 node-3 website 4 r STARTED 0 261b 192.168.1.102 node-1 website 4 p STARTED 0 261b 192.168.1.104 node-3 website 1 r STARTED 0 261b 192.168.1.103 node-2 website 1 p STARTED 0 261b 192.168.1.104 node-3 website 2 p STARTED 0 261b 192.168.1.103 node-2 website 2 r STARTED 0 261b 192.168.1.104 node-3 website 0 r STARTED 0 261b 192.168.1.103 node-2 website 0 p STARTED 0 261b 192.168.1.102 node-1 gmall_dau_info_2021-01-09 3 p STARTED 16 30.5kb 192.168.1.103 node-2 gmall_dau_info_2021-01-09 3 r STARTED 16 30.4kb 192.168.1.102 node-1 gmall_dau_info_2021-01-09 4 p STARTED 9 22.6kb 192.168.1.103 node-2 gmall_dau_info_2021-01-09 4 r STARTED 9 43.5kb 192.168.1.102 node-1 gmall_dau_info_2021-01-09 1 r STARTED 7 22.2kb 192.168.1.102 node-1 gmall_dau_info_2021-01-09 1 p STARTED 7 22.2kb 192.168.1.104 node-3 gmall_dau_info_2021-01-09 2 p STARTED 11 22.9kb 192.168.1.103 node-2 gmall_dau_info_2021-01-09 2 r STARTED 11 22.9kb 192.168.1.104 node-3 gmall_dau_info_2021-01-09 0 p STARTED 7 29.2kb 192.168.1.103 node-2 gmall_dau_info_2021-01-09 0 r STARTED 7 29.3kb 192.168.1.104 node-3 movie_chn_2 3 r STARTED 1 4.3kb 192.168.1.103 node-2 movie_chn_2 3 p STARTED 1 4.3kb 192.168.1.104 node-3 movie_chn_2 4 r STARTED 1 4.2kb 192.168.1.102 node-1 movie_chn_2 4 p STARTED 1 4.2kb 192.168.1.104 node-3 movie_chn_2 1 p STARTED 0 261b 192.168.1.103 node-2 movie_chn_2 1 r STARTED 0 261b 192.168.1.102 node-1 movie_chn_2 2 p STARTED 1 4.2kb 192.168.1.103 node-2 movie_chn_2 2 r STARTED 1 4.2kb 192.168.1.104 node-3 movie_chn_2 0 p STARTED 0 261b 192.168.1.103 node-2 movie_chn_2 0 r STARTED 0 261b 192.168.1.102 node-1 movie_test_202011 0 r STARTED 1 3.9kb 192.168.1.103 node-2 movie_test_202011 0 p STARTED 1 3.9kb 192.168.1.102 node-1 gmall_dau_info_2021-01-08 3 p STARTED 16 37.4kb 192.168.1.103 node-2 gmall_dau_info_2021-01-08 3 r STARTED 16 51.4kb 192.168.1.104 node-3 gmall_dau_info_2021-01-08 4 r STARTED 9 29.6kb 192.168.1.103 node-2 gmall_dau_info_2021-01-08 4 p STARTED 9 43.5kb 192.168.1.102 node-1 gmall_dau_info_2021-01-08 1 r STARTED 7 22.1kb 192.168.1.102 node-1 gmall_dau_info_2021-01-08 1 p STARTED 7 29.2kb 192.168.1.104 node-3 gmall_dau_info_2021-01-08 2 r STARTED 11 43.7kb 192.168.1.102 node-1 gmall_dau_info_2021-01-08 2 p STARTED 11 43.7kb 192.168.1.104 node-3 gmall_dau_info_2021-01-08 0 r STARTED 7 29.3kb 192.168.1.103 node-2 gmall_dau_info_2021-01-08 0 p STARTED 7 29.3kb 192.168.1.104 node-3 .kibana_1 0 r STARTED 3 12kb 192.168.1.103 node-2 .kibana_1 0 p STARTED 3 12kb 192.168.1.102 node-1 movie_chn_1 3 r STARTED 1 5kb 192.168.1.103 node-2 movie_chn_1 3 p STARTED 1 5kb 192.168.1.102 node-1 movie_chn_1 4 r STARTED 1 4.8kb 192.168.1.103 node-2 movie_chn_1 4 p STARTED 1 4.8kb 192.168.1.102 node-1 movie_chn_1 1 p STARTED 0 261b 192.168.1.103 node-2 movie_chn_1 1 r STARTED 0 261b 192.168.1.104 node-3 movie_chn_1 2 p STARTED 1 4.8kb 192.168.1.102 node-1 movie_chn_1 2 r STARTED 1 4.8kb 192.168.1.104 node-3 movie_chn_1 0 p STARTED 0 261b 192.168.1.102 node-1 movie_chn_1 0 r STARTED 0 261b 192.168.1.104 node-3 movie_chn_3 3 r STARTED 0 261b 192.168.1.102 node-1 movie_chn_3 3 p STARTED 0 261b 192.168.1.104 node-3 movie_chn_3 4 p STARTED 0 261b 192.168.1.102 node-1 movie_chn_3 4 r STARTED 0 261b 192.168.1.104 node-3 movie_chn_3 1 p STARTED 0 261b 192.168.1.103 node-2 movie_chn_3 1 r STARTED 0 261b 192.168.1.104 node-3 movie_chn_3 2 p STARTED 0 261b 192.168.1.103 node-2 movie_chn_3 2 r STARTED 0 261b 192.168.1.104 node-3 movie_chn_3 0 p STARTED 0 261b 192.168.1.103 node-2 movie_chn_3 0 r STARTED 0 261b 192.168.1.102 node-1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号